IMS Hierarchical Access Methods
| You can use different IMS access methods to organize and store data segments and records. Choose an access method after you carefully analyze the access requirements of the applications, for example, the functionality available to the application, the order in which segments are returned to the application, and database performance considerations. Some access methods provide a better solution to your business needs than others. For optimal processing cost, the order for selecting a database type should be:
In general, you can change access methods (VSAM or OSAM) during reorganization without affecting application programs. Choose the access method carefully because the access method is one of the most critical performance factors. You might not be able to change database types (HIDAM, HDAM, HISAM) during reorganization without affecting the application. Table 8-1 describes the most commonly used IMS database organizations.
Related Reading: All the types of the IMS database organizations are described in IMS Version 9: Administration Guide: Database Manager. The three most common IMS access methods are:
The HD and HS databases are full-function databases, and DEDB databases are referred to as Fast Path databases. In addition to the three most common access methods, there are two more IMS access methods that provide additional functionality:
Exceptions: Most types of application regions can access the majority of the database organization types. The exceptions are:
HDAM Access MethodAn HDAM database normally consists of one VSAM entry-sequenced data set (ESDS) or OSAM data set. The information in this section is illustrated in Figure 8-4 on page 90. Figure 8-4. Physical Layout of Records in an HDAM Database Data Set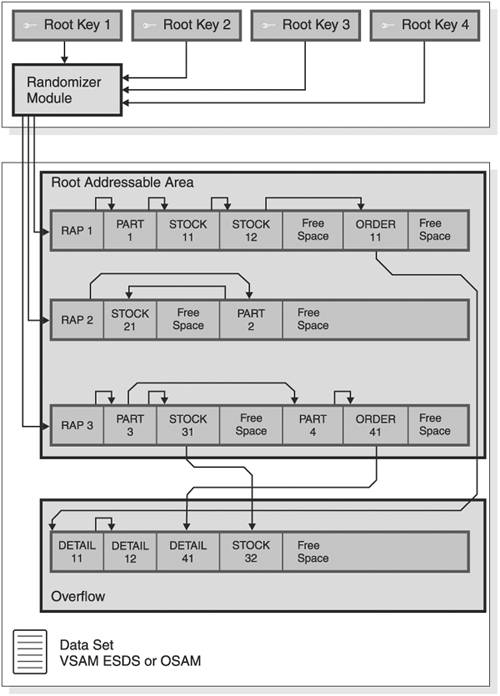 To access the data in an HDAM database, IMS uses a randomizing module, which computes the address for the root segment of a record in the database. This address consists of the relative number of a VSAM control interval (CI) or OSAM block within the data set and the number of a root anchor point (RAP) within that CI or block. Root anchor points are located at the beginning of each CI or block and are used for the chaining of root segments that randomize to that CI or block. All chaining of segments is done using a 4-byte address. This 4-byte address, the relative-byte address (RBA), is the byte that the segment starts at relative to the start of the data set. IMS supplies a general randomizing module, DFSHDC40, which is suitable for most applications. The IMS Version 9: Customization Guide describes this module and also provides details about how to modify this module or develop your own randomizing routines. In an HDAM database, the VSAM ESDS or OSAM data set is divided into two areas:
IMS uses the root addressable area as the primary storage area for segments in each database record. IMS always attempts to put new and updated segments in the root addressable area. The overflow area is used when IMS is unable to find enough space for a segment that is inserted in the root addressable area. IMS uses a number of techniques to distribute free space within the root addressable area to allow future segments to be inserted in the most desirable block. Because database records vary in length, you can use the bytes parameter in the RMNAME= keyword (in the DBD) to control the amount of space used for each database record in the root addressable area. The bytes parameter limits the number of segments of a database record that can be consecutively inserted into the root addressable area. Note that this limitation only applies if the segments in the record are inserted at the same time. When consecutively inserting a root and its dependents, each segment is stored in the root addressable area until the next segment to be stored causes the total space used to exceed the specified number of bytes. Consecutive inserts are inserts to one database record without an intervening call to process a segment in a different database record. The total space used for a segment is the combined lengths of the prefix and data portions of the segment. When exceeded, that segment and all remaining segments in the database record are stored in the overflow area. It should be noted that the value of the bytes parameter controls only segments that are consecutively inserted in one database record. When you load HDAM databases initially, you can specify that a percentage of the space in each block should be left for subsequent segments to be inserted. This free space allows subsequent segments to be inserted close to the database record they belong to. This free space percentage is specified on the DBD. You can also specify in the DBD that a percentage of blocks in the data set are left empty, but you should not do this with HDAM databases because doing so will result in IMS randomizing segments to a free block, and then placing them in another block. This would result in additional I/O (the block they randomize to, plus the block they are in) each time the segment is retrieved. Analyze the potential growth of the database to determine a percentage amount for this free space. When IMS inserts segments, it uses the HD space search algorithm to determine which CI or block to put the segment in. By doing so, IMS attempts to minimize physical I/Os while accessing segments in a database record by placing the segment in a CI or block as physically close as possible to other segments in the database record. Related Reading: For more information about the HD space search algorithm, see the chapter "Designing Full-Function Databases" in IMS Version 9: Administration Guide: Database Manager. In addition to organizing the application data segments in an HDAM database, IMS also manages the free space in the data set. As segments are inserted and deleted, areas in the CI or blocks become free (in addition to the free space defined when the database is initially loaded). IMS space management allows this free space to be reused for subsequent segment insertion. To enable IMS to quickly determine which CI or blocks have space available, IMS maintains a table (a bitmap) that indicates which CI or blocks have a large enough area of contiguous free space to contain the largest segment type in the database. Note that if a database has segment types with widely varying segment sizes, even if the CI or block has room for the smaller segment types, it is marked as having no free space if it cannot contain the largest segment type. The bitmap consists of one bit for each CI or block, which is set on (1) if space is available in the CI or block or set off (0) if space is not available. The bitmap is in the first (OSAM) or second (VSAM) CI or block of the data set and occupies the whole of that CI or block. Figure 8-5 illustrates the HDAM database free space management. Figure 8-5. HDAM Database Free Space Management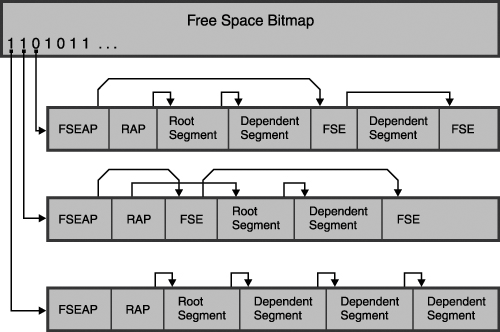 Within the CI or block itself, IMS maintains a chain of pointers to the areas of free space. These are anchored off a Free Space Element Anchor Point (FSEAP). The FSEAP contains the offset, in bytes, from the start of the CI or block to the first Free Space Element (FSE), if free space exists. Each area of free space that is greater than 8 bytes contains an FSE containing the length of the free space, together with the offset from the start of the CI or block to the next FSE. All management of free space and application segments in the data sets is done automatically by IMS and is transparent to the application. You need to be aware of how IMS manages free space only because of the performance and space usage implications. Related Reading: See "Choosing a Database Type" in IMS Version 9: Administration Guide: Database Manager for a full description of the HDAM internal organization. Advantages and Disadvantages of the HDAM Access MethodThe principle advantages of the HDAM access method are:
The principle disadvantages of the HDAM access method are:
When to Choose HDAMConsider using HDAM first because it is recognized as the most efficient storage organization of the IMS HD databases. First, examine the level of access required to the database. If there are no requirements to process a large section of the database in key sequence, you should choose HDAM. If sequential access of the root keys is required, the process can retrieve the data in physical sequence and sort the output. In many cases, the disadvantages for HDAM do not apply or can be circumvented. Weigh the effort necessary to circumvent the disadvantages against the savings in terms of main storage and CPU usage. There is no doubt, however, that an application with only HDAM databases is the most compact one. Some possible solutions for the HDAM disadvantages are:
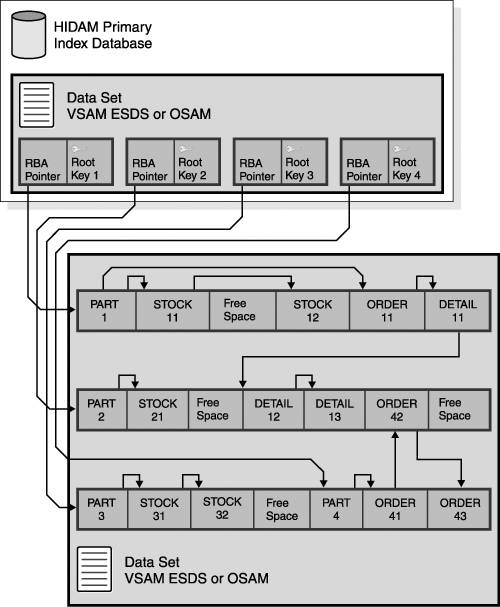
HIDAM Access MethodA HIDAM database on DASD is comprised of two physical databases that are normally referred to collectively as a HIDAM database. Figure 8-6 on page 95 illustrates these two databases. When you define each of the databases through the database description (DBD), one is defined as the HIDAM primary index database and the other is defined as the main HIDAM database. In this section, the term "HIDAM database" refers to the main HIDAM database that you define through the DBD. Figure 8-6. HIDAM Database in Physical Storage A HIDAM database is similar to an HDAM database. The main difference is in the way root segments are accessed. In HIDAM, there is no randomizing module, and normally that are no RAPs. Instead, the HIDAM primary index database takes the place of the randomizing module in providing access to the root segments. The HIDAM primary index is a VSAM key-sequenced data set (KSDS) that contains one record for each root segment, keyed on the root key. This record also contains the pointer (RBA) to the root segment in the main HIDAM database. The HIDAM primary index database is used to locate the database records stored in a HIDAM database. When a HIDAM database is defined through the DBD, a unique sequence field must be defined for the root segment type. The value of this sequence field is used by IMS to create an index segment for each root segment (record in the KSDS). This segment in the HIDAM primary index database contains, in its prefix, a pointer to the root segment in the main HIDAM database. The main HIDAM database can be OSAM or ESDS, but the primary index must be KSDS. When the HIDAM database is initially loaded, the database records are loaded into the data set in root key sequence. If root anchor points are not specified, reading the database in root key sequence will also read through the database in the physical sequence that the records are stored in on DASD. If you are processing the databases in key sequence and regularly inserting segments and new database records, you should specify sufficient free space when the database is initially loaded so that the new segments and records can be physically inserted adjacent to other records in the key sequence. Related Reading: See the chapter on "Choosing a Database Type" in IMS Version 9: Administration Guide: Database Manager for a full description of the HIDAM internal organization. Free space in the main HIDAM database is managed in the same way as in an HDAM database. IMS keeps track of the free space using free space elements queued off free space element anchor points. When segments are inserted, the HD free space search algorithm is used to locate space for the segment. The HIDAM primary index database is processed as a normal VSAM KSDS. Consequently, a high level of insert or delete activity results in CI or CA splits, which might require the index to be reorganized. When the HIDAM database is initially loaded, free space can be specified as a percentage of the total CIs or blocks to be left free, and as a percentage of each CI or block to be left free. This is specified on the DBD. Advantages and Disadvantages of the HIDAM Access MethodThe principle advantages of the HIDAM access method are:
The principle disadvantages of the HIDAM access method are:
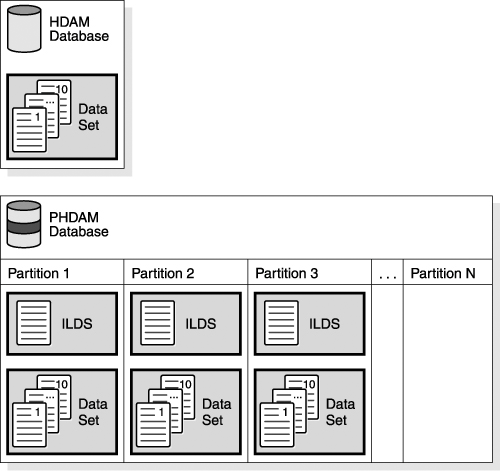
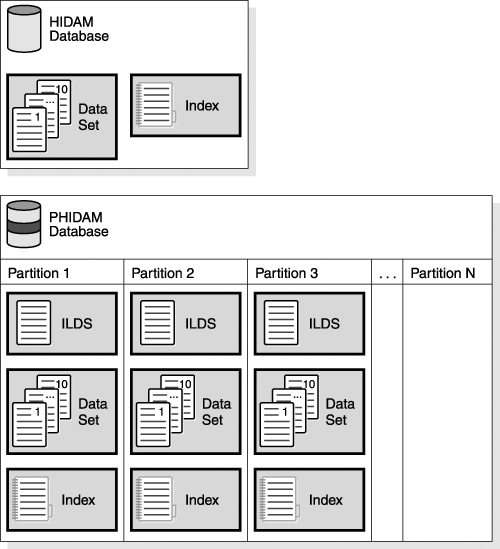
When to Choose HIDAMHIDAM is the most common type of database organization. HIDAM has the same advantages of space usage as HDAM, but also keeps the root keys available in sequence. These days, with the speed of DASD, the extra read of the primary index database can be incurred without much overhead by specifying specific buffer pools for the primary index database to use, thus reducing the actual I/O to use the index pointer segments. Choose HIDAM only if you need to regularly process the database in root segment key sequence. If you also need fast random access to roots from online systems, look at alternatives for the sequential access, such as unload and sort or secondary indexes. HIDAM does not need to be monitored as closely as HDAM. PHDAM and PHIDAM Access MethodsPHDAM databases are partitioned HDAM databases, and PHIDAM databases are partitioned HIDAM databases. PHDAM and PHIDAM databases are two of the HALDB-type databases. Figure 8-7 on page 98 illustrates a logical view of an HDAM database and a PHDAM database. Figure 8-7. Logical View of an HDAM Database and a PHDAM Database HDAM and HIDAM databases are limited in size because segments of the same type must be in the same data set and the maximum data set size is limited to 4 GB for VSAM and 8 GB for OSAM. HALDBs allows IMS databases to grow much larger. Partitioning a database allows the use of smaller elements that are easier to manage. Multiple partitions decrease the amount of unavailable data if a partition fails or is taken offline. Each partition must have an indirect list data set (ILDS). The ILDS is a VSAM KSDS and is the repository for indirect pointers (called self-healing pointers). These pointers eliminate the need to update logical relationships or secondary index pointers after a reorganization. An ILDS contains indirect list entries (ILEs), which are composed of keys and data. The data parts of ILEs contain direct pointers to the target segments. Like the other HD databases, PHDAM and PHIDAM databases are stored on direct-access devices in either a VSAM ESDS or an OSAM data set. The storage organization in HDAM and HIDAM or PHDAM and PHIDAM is basically the same. Their primary difference is in the way their root segments are accessed: HDAM or PHDAM databases
HIDAM or PHIDAM databases
For HIDAM databases, the primary index is a database that IMS loads and maintains. For PHIDAM databases, the primary index is a data set that is in the partition it serves. The advantage of using the randomizing module versus the primary index for finding the root segment is that the I/O operations required to search an index are eliminated. Figure 8-8 on page 100 illustrates a logical view of a HIDAM and a PHIDAM database. Figure 8-8. A Logical View of a HIDAM and a PHIDAM Related Reading: For more information about HALDBs, see IMS Version 9: Administration Guide: Database Manager and the IBM Redbook, The Complete IMS HALDB Guide All You Need to Know to Manage HALDBs. HALDB Partition NamesEach HALDB partition name is 1 to 7 bytes in length and must be unique among the database names, DEDB names, area names, and partition names that are contained in one RECON data set. The HALDB partition names are used to represent specific partitions and are used interchangeably with database names in commands. HALDB Data Definition NamesIMS constructs the data definition names (ddnames) for each partition by adding a 1-byte suffix to the partition name for the data sets in that partition. The suffix:
For a partitioned secondary index (PSINDEX, see "Index Databases" on page 101) database, there is only one data set per partition, so only one ddname with a suffix of A is required. The ddname suffix naming convention described in the previous paragraph is extended to M through V and Y when a HALDB is reorganized online. Related Reading: For more information about reorganizing all types of databases, see Chapter 10, "The Database Reorganization Process," on page 123. When to Choose PHDAM or PHIDAMThe reasons for choosing PHDAM or PHIDAM are the same as described in "When to Choose HDAM" on page 93 and "When to Choose HIDAM" on page 97. The differences are the size of the data store and some administrative considerations. You might not need to change any of your application programs when you migrate HDAM or HIDAM databases to HALDBs, but there might be exceptions. Exceptions include the initial loading of logically related databases and the processing of secondary indexes as databases. You might also want to change applications to take advantage of some HALDB capabilities. These capabilities include processing partitions in parallel, processing individual partitions, and handling unavailable partitions. Index DatabasesIndex databases are used to implement secondary indexes and the primary index of HIDAM and PHIDAM databases. An index database is always associated with another HD database and cannot exist by itself. An index database can, however, be processed separately by an application program. An index database consists of a single VSAM KSDS. Unlike the VSAM ESDSs used by IMS, which are processed at the block or control interval level, the index database is processed as a normal indexed file. IMS uses the normal VSAM access method macros to process it. The records in the KSDS contain the fields that make up the key, and a pointer to the target segment. For a secondary index, the pointer can be direct (relative byte address of the target segment) or symbolic (the complete, concatenated key of the target segment). For a HIDAM primary index, the pointer is always direct. Because the indexes are a normal VSAM KSDS (and relative byte addresses are not used for data in the index database), they can be processed using the normal VSAM Access Method Services (IDCAMS). For example, you could use the z/OS REPRO function to copy the data set and remove CI or CA splits or resize the data set, without having to perform any other IMS reorganization. Another type of HALDB is a partitioned secondary Index (PSINDEX) database. A PSINDEX database is the partitioned version of the HD secondary index database discussed in "Secondary Index Databases" on page 77. All the concepts that apply to the HD secondary index databases apply to PSINDEX databases. The only real difference is that PSINDEX pointer segments can point only to target segments that reside in HALDBs. Fast Path DEDBsThe DEDB implementation of the IMS hierarchical database model is broadly the same as the IMS HDAM access method. However, there are important differences:
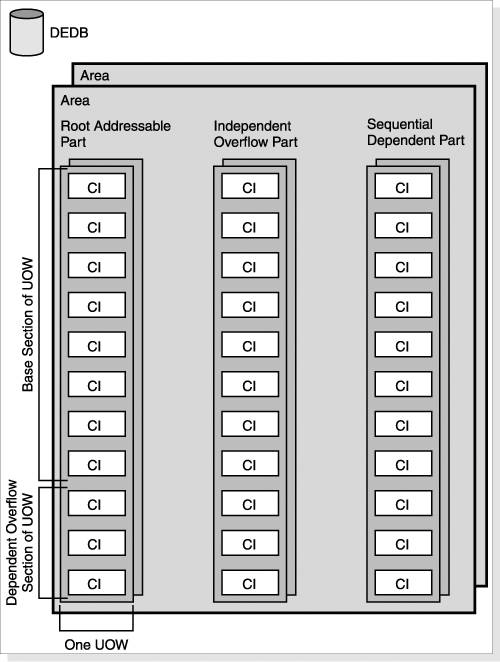
The hierarchical structure of a database record within a DEDB is the same as HDAM, except for an additional dependent segment type. Each database record contains one root segment and from 0 to 126 dependent segment types. One of these segment types can, optionally, be a sequential dependent segment type. As with HDAM, a randomizing module is used to provide initial access to the database data sets that contain the DEDB database. The highest level in the structure used to implement a DEDB is the area. A DEDB can consist of from 1 to 2048 areas. Each area is implemented as one VSAM ESDS. Each DEDB area data set is divided into:
The root addressable part is further subdivided into units of work (UOWs). These should not be confused with the unit of work that encompasses an application's minimum set of updates to maintain application consistency. The DEDB UOW is similar, however, because it is the smallest unit that some Fast Path utilities (for example, reorganization) work with, and lock, which prevents other transactions from accessing them. Each unit of work consists of from 2 to 32,767 CIs, divided into a base section of 1 or more CIs, and a dependent overflow section consisting of the remaining CIs. Figure 8-9 on page 103 shows the structure of a DEDB. Figure 8-9. Overall Structure of a Fast Path DEDB Note: When a DEDB data set is initialized by the DEDB Initialization utility (DBFUMIN0), additional CIs are created for IMS to use internally, so the DEDB area will physically contain more CIs than are shown in Figure 8-9. These extra CIs were used for the DEDB Direct Reorganization utility (DBFUMDR0), which went out of service with IMS Version 5 and was replaced by the High-Speed DEDB Direct Reorganization Utility (DBFUHDR0). Although IMS does not use the extra CIs, DBFUMIN0 creates them for compatibility purposes. The randomizing module works in a similar way to an HDAM database. The randomizing module takes the key value of the root segment and performs calculations on it to arrive at a value for a root anchor point. However, for a DEDB this is the root anchor point within the area data set. The randomizing module must also provide the value of the area data set that contains the RAP. Although a sample randomizing module is provided with IMS (DBFHDC44), due to the unique characteristics of DEDBs, you should determine whether you need to code your own. The randomizing module produces the value of a root anchor point in the base section of a unit of work. IMS attempts to store all dependent segments of the root (except sequential dependents) in the same UOW as the root. If more than one root randomizes to the same RAP, then they are chained off the RAP in key sequence. If there is insufficient space in that base section CI, then root and non-sequential dependent segments are placed in the dependent overflow section of that UOW. If there is no space in the dependent overflow section in the UOW, a CI in the independent overflow part of the DEDB area is allocated to that UOW and the segment is stored there. This CI in the independent overflow part is then used exclusively by that UOW, and is processed with that UOW by the High-Speed DEDB Direct Reorganization utility (DBFUHDR0). The free space between the data segments in the CIs in the root addressable part and independent overflow part of a DEDB area data set are managed in the same way as in an HDAM data set: a free space element anchor point is at the start of the CI pointing to a chain of free space elements. As with HDAM, space from deleted segments is automatically reused, and the UOW can be reorganized to consolidate fragmented free space (without making the database unavailable). Unlike an HDAM database, there is no free space map. The segments for a database record can be allocated only in the same UOW (or attached segments in dependent overflow) as the root segment. An out of space condition results if insufficient free space is available in the UOW or independent overflow. You can use the following optional features with a DEDB: Virtual Storage Option (VSO)
Shared VSO
Multiple Area Data Sets (MADS)
High Speed Sequential Processing (HSSP)
Sequential Dependent Segments (SDEPs)
Related Reading:
Advantages and Disadvantages of Fast Path DEDBsFast Path DEDBs provide advantages when:
The principal disadvantages of Fast Path DEDBs are:
When to Choose DEDBThe art of knowing when to use a DEDB depends on understanding the differences between DEDBs and other database types. The following list describes some reasons and considerations for choosing DEDBs. Advantages of areas
When to use VSO
When to use MADS
When to use HSSP
When to use SDEPs
GSAM Access MethodGeneralized sequential access method (GSAM) databases are sequentially organized databases designed to be compatible with z/OS data sets. However, the normal concepts of hierarchical structures do not apply to GSAM because the GSAM database contains only the normal data records, but no IMS information. The files in a GSAM database can be z/OS sequential files or VSAM ESDSs. Before or after the IMS application processes them, other applications can process them using the normal BSAM, queued sequential access method (QSAM), and VSAM access methods. When IMS uses the GSAM access method for sequential input and output files, IMS controls the physical access and position of those files. This control is necessary for the repositioning of such files in case of a program restart. When the program uses GSAM at restart time, IMS repositions the GSAM files in synchronization with the database contents in your application program's working storage. To control this, the application program should use the restart (XRST) and checkpoint (CHKP) DL/I calls, which are discussed in "Using Batch Checkpoint/Restart" on page 275. Note that IMS cannot reposition VSAM ESDS files on restart. Other restrictions on restarting are detailed in the chapter "Designing Full-Function Databases" in IMS Version 9: Administration Guide: Database Manager. If you want your program to be restartable, you should use GSAM for its sequential input and output files. There are two reasons you might want to make your program restartable:
HSAM and HISAM Access MethodsThe two hierarchical sequential (HS) databases, HSAM and HISAM, use the sequential method of accessing data. All database records and segments within each database record are physically adjacent in storage. Unlike HSAM, however, each HISAM database record is indexed, allowing direct access to a database record. The HSAM and HISAM access methods have now been superseded by the HD access methods. The HD access methods have a number of features that almost always make them a better choice. The HSAM access method does not allow updates to a database after it is initially loaded, and the database can be read only sequentially. In the past, the HSAM access method was used to process operating system sequential files, but the GSAM access method is now a better choice. The HISAM access method offers similar functionality to the HIDAM access method, but has poorer internal space management than the HD access methods (that would normally result in more I/O to retrieve data) and, therefore, must be reorganized much more frequently. A simple HSAM (SHSAM) database is an HSAM database that contains only one type of segment, a root segment. An SHSAM database is a z/OS physical sequential data set. Similarly, a simple HISAM (SHISAM) database is a HISAM database that contains only one type of segment, a root segment. A SHISAM database is a KSDS. Both SHSAM and SHISAM databases can be processed with the native z/OS access methods outside IMS, as well as with DL/I. Related Reading: For additional details about the HS access methods, see IMS Version 9: Administration Guide: Database Manager. Applications That Are Suitable for HSAM and HISAMHSAM is one of the original database access methods and has been superseded. It is rarely used today. HISAM is not an efficient database organization type. You can easily convert HISAM databases to HIDAM. Applications should receive significant performance improvements as a result. The only situation where HISAM might be preferable to HIDAM is when the database is a root-segment-only database. An example of the inefficiency of HSAM and HISAM is that segments are not completely deleted and free space is not reclaimed after a segment is deleted until the next database reorganization. |
EAN: 2147483647
Pages: 226