8.9. The Berkeley Fast Filesystem A traditional UNIX filesystem is described by its superblock, which contains the basic parameters of the filesystem. These parameters include the number of data blocks in the filesystem, a count of the maximum number of files, and a pointer to the free list, which is a list of all the free blocks in the filesystem. A 150-Mbyte traditional UNIX filesystem consists of 4 Mbyte of inodes followed by 146 Mbyte of data. That organization segregates the inode information from the data; thus, accessing a file normally incurs a long seek from the file's inode to its data. Files in a single directory typically are not allocated consecutive slots in the 4 Mbyte of inodes, causing many nonconsecutive disk blocks to be read when many inodes in a single directory are accessed. The allocation of data blocks to files also is suboptimal. The traditional filesystem implementation uses a 512-byte physical block size. But the next sequential data block often is not on the same cylinder, so seeks between 512-byte data transfers are required frequently. This combination of small block size and scattered placement severely limits filesystem throughput. The first work on the UNIX filesystem at Berkeley attempted to improve both the reliability and the throughput of the filesystem. The developers improved reliability by staging modifications to critical filesystem information so that the modifications could be either completed or repaired cleanly by a program after a crash [McKusick & Kowalski, 1994]. Doubling the block size of the filesystem improved the performance of the 4.0BSD filesystem by a factor of more than 2 when compared with the 3BSD filesystem. This doubling caused each disk transfer to access twice as many data blocks and eliminated the need for indirect blocks for many files. In the remainder of this section, we shall refer to the filesystem with these changes as the 3BSD filesystem. The performance improvement in the 3BSD filesystem gave a strong indication that increasing the block size was a good method for improving throughput. Although the throughput had doubled, the 3BSD filesystem was still using only about 4 percent of the maximum disk throughput. The main problem was that the order of blocks on the free list quickly became scrambled as files were created and removed. Eventually, the free-list order became entirely random, causing files to have their blocks allocated randomly over the disk. This randomness forced a seek before every block access. Although the 3BSD filesystem provided transfer rates of up to 175 Kbyte per second when it was first created, the scrambling of the free list caused this rate to deteriorate to an average of 30 Kbyte per second after a few weeks of moderate use. There was no way of restoring the performance of a 3BSD filesystem except to recreate the system. Organization of the Berkeley Fast Filesystem The first version of the current BSD filesystem appeared in 4.2BSD [McKusick et al., 1984]. This version is still in use today as UFS1. In the FreeBSD filesystem organization (as in the 3BSD filesystem organization), each disk drive contains one or more filesystems. A FreeBSD filesystem is described by its superblock, located at the beginning of the filesystem's disk partition. Because the superblock contains critical data, it is replicated to protect against catastrophic loss. This replication is done when the filesystem is created. Since most of the superblock data do not change, the copies do not need to be referenced unless a disk failure causes the default superblock to be corrupted. The data in the superblock that does change include a few flags and some summary information that can easily be recreated if an alternative superblock needs to be used. To allow support for filesystem fragments as small as a single 512-byte disk sector, the minimum size of a filesystem block is 4096 bytes. The block size can be any power of 2 greater than or equal to 4096. The block size is recorded in the filesystem's superblock, so it is possible for filesystems with different block sizes to be accessed simultaneously on the same system. The block size must be selected at the time that the filesystem is created; it cannot be changed subsequently without the filesystem being rebuilt. The BSD filesystem organization divides a disk partition into one or more areas, each of which is called a cylinder group. Historically, a cylinder group comprised one or more consecutive cylinders on a disk. Although FreeBSD still uses the same data structure to describe cylinder groups, the practical definition of them has changed. When the filesystem was first designed, it could get an accurate view of the disk geometry including the cylinder and track boundaries and could accurately compute the rotational location of every sector. Modern disks hide this information, providing fictitious numbers of blocks per track, tracks per cylinder, and cylinders per disk. Indeed, in modern RAID arrays, the "disk" that is presented to the filesystem may really be composed from a collection of disks in the RAID array. While some research has been done to figure out the true geometry of a disk [Griffin et al., 2002; Lumb et al., 2002; Schindler et al., 2002], the complexity of using such information effectively is high. Modern disks have greater numbers of sectors per track on the outer part of the disk than the inner part that makes calculation of the rotational position of any given sector complex to calculate. So when the design for UFS2 was drawn up, we decided to get rid of all the rotational layout code found in UFS1 and simply assume that laying out files with numerically close block numbers (sequential being viewed as optimal) would give the best performance. Thus, the cylinder group structure is retained in UFS2, but it is used only as a convenient way to manage logically close groups of blocks. The rotational layout code had been disabled in UFS1 since the late 1980s, so as part of the code base cleanup it was removed entirely. Each cylinder group must fit into a single filesystem block. When creating a new filesystem, the newfs utility calculates the maximum number of blocks that can be packed into a cylinder group map based on the filesystem block size. It then allocates the minimum number of cylinder groups needed to describe the filesystem. A filesystem with 16 Kbyte blocks typically has six cylinder groups per Gbyte. Each cylinder group contains bookkeeping information that includes a redundant copy of the superblock, space for inodes, a bitmap describing available blocks in the cylinder group, and summary information describing the usage of data blocks within the cylinder group. The bitmap of available blocks in the cylinder group replaces the traditional filesystem's free list. For each cylinder group in UFS1, a static number of inodes is allocated at filesystem-creation time. The default policy is to allocate one inode per four filesystem fragments, with the expectation that this amount will be far more than will ever be needed. For each cylinder group in UFS2, the default is to reserve bitmap space to describe one inode per two filesystem fragments. In either type of filesystem, the default may be changed only at the time that the filesystem is created. The rationale for using cylinder groups is to create clusters of inodes that are spread over the disk close to the blocks that they reference, instead of them all being located at the beginning of the disk. The filesystem attempts to allocate file blocks close to the inodes that describe them to avoid long seeks between getting the inodc and getting its associated data. Also, when the inodes are spread out, there is less chance of losing all of them in a single disk failure. Although we decided to come up with a new on-disk inode format for UFS2, we chose not to change the format of the superblock, the cylinder group maps, or the directories. Additional information needed for the UFS2 superblock and cylinder groups is stored in spare fields of the UFS1 superblock and cylinder groups. Maintaining the same format for these data structures allows a single code base to be used for both UFS1 and UFS2. Because the only difference between the two filesystems is in the format of their inodes, code can dereference pointers to superblocks, cylinder groups, and directory entries without need of checking what type of filesystem is being accessed. To minimize conditional checking of code that references inodes, the on-disk inode is converted to a common in-core format when the inode is first read in from the disk and converted back to its on-disk format when it is written back. The effect of this decision is that there are only nine out of several hundred routines that are specific to UFS1 versus UFS2. The benefit of having a single code base for both filesystems is that it dramatically reduces the maintenance cost. Outside the nine filesystem format specific functions, fixing a bug in the code fixes it for both filesystem types. A common code base also means that as the symmetric multiprocessing support gets added, it only needs to be done once for the UFS family of filesystems. Boot Blocks The UFS1 filesystem reserved an 8-Kbyte space at the beginning of the filesystem in which to put a boot block. While this space seemed huge compared to the 1-Kbyte boot block that it replaced, over time it has gotten increasingly difficult to cram the needed boot code into this space. Consequently we decided to revisit the boot block size in UFS2. The boot code has a list of locations to check for boot blocks. A boot block can be defined to start at any 8-Kbyte boundary. We set up an initial list with four possible boot block sizes: none, 8 Kbytes, 64 Kbytes, and 256 Kbytes. Each of these locations was selected for a particular purpose. Filesystems other than the root filesystem do not need to be bootable, so they can use a boot block size of zero. Also, filesystems on tiny media that need every block that they can get, such as floppy disks, can use a zero-size boot block. For architectures with simple boot blocks, the traditional UFS1 8-Kbyte boot block can be used. More typically the 64-Kbyte boot block is used (for example, on the PC architecture with its need to support booting from a myriad of busses and disk drivers). We added the 256-Kbyte boot block in case some future architecture or application needs to set aside a particularly large boot area. This space reservation is not strictly necessary, since new sizes can be added to the list at any time, but it can take a long time before the updated list gets propagated to all the boot programs and loaders out on the existing systems. By adding the option for a huge boot area now, we can ensure it will be readily available should it be needed on short notice in the future. An unexpected side effect of using a 64-Kbyte boot block for UFS2 is that if the partition had previously had a UFS1 filesystem on it, the superblock for the former UFS1 filesystem may not be overwritten. If an old version of fsck that does not first look for a UFS2 filesystem is run and finds the UFS1 superblock, it can incorrectly try to rebuild the UFS1 filesystem destroying the UFS2 filesystem in the process. So when building UFS2 filesystems, the newfs utility looks for old UFS1 superblocks and zeros them out. Optimization of Storage Utilization Data are laid out such that large blocks can be transferred in a single disk operation, greatly increasing filesystem throughput. A file in the new filesystem might be composed of 8192-byte data blocks, as compared to the 1024-byte blocks of the 3BSD filesystem; disk accesses would thus transfer up to 8 times as much information per disk transaction. In large files, several blocks can be allocated consecutively, so even larger data transfers are possible before a seek is required. The main problem with larger blocks is that most BSD filesystems contain primarily small files. A uniformly large block size will waste space. Table 8.12 shows the effect of filesystem block size on the amount of wasted space in the filesystem. The measurements used to compute this table were collected from a survey of the Internet conducted in 1993 [Irlam, 1993]. The survey covered 12 million files residing on 1000 filesystems, with a total size of 250 Gbytes. The investigators found that the median file size was under 2048 bytes; the average file size was 22 Kbytes. The space wasted is calculated to be the percentage of disk space not containing user data. As the block size increases, the amount of space reserved for inodes decreases, but the amount of unused data space at the end of blocks rises quickly to an intolerable 29.4 percent waste, with a minimum allocation of 8192-byte filesystem blocks. More recent (proprietary) studies find similar results. Table 8.12. Amount of space wasted as a function of block size.Percentage Total Waste | Percentage Data Waste | Percentage Inode Waste | Organization |
|---|
0.0 | 0.0 | 0.0 | data only, no separation between files | 1.1 | 1.1 | 0.0 | data only, files start on 512-byte boundary | 7.4 | 1.1 | 6.3 | data + inodes, 512-byte block | 8.8 | 2.5 | 6.3 | data + inodes, 1024-byte block | 11.7 | 5.4 | 6.3 | data + inodes, 2048-byte block | 15.4 | 12.3 | 3.1 | data + inodes, 4096-byte block | 29.4 | 27.8 | 1.6 | data + inodes, 8192-byte block | 62.0 | 61.2 | 0.8 | data + inodes, 16,384-byte block |
For large blocks to be used without significant waste, small files must be stored more efficiently. To increase space efficiency, the filesystem allows the division of a single filesystem block into one or more fragments. The fragment size is specified at the time that the filesystem is created; each filesystem block optionally can be broken into two, four, or eight fragments, each of which is addressable. The lower bound on the fragment size is constrained by the disk-sector size, which is typically 512 bytes. The block map associated with each cylinder group records the space available in a cylinder group in fragments; to determine whether a block is available, the system examines aligned fragments. Figure 8.31 shows a piece of a block map from a filesystem with 4096-byte blocks and 1024-byte fragments, hereinafter referred to as a 4096/1024 filesystem. Figure 8.31. Example of the layout of blocks and fragments in a 4096/1024 filesystem. Each bit in the map records the status of a fragment; a "-" means that the fragment is in use, whereas a "1" means that the fragment is available for allocation. In this example, fragments 0 through 5, 10, and 11 are in use, whereas fragments 6 through 9 and 12 through 15 are free. Fragments of adjacent blocks cannot be used as a full block, even if they are large enough. In this example, fragments 6 through 9 cannot be allocated as a full block; only fragments 12 through 15 can be coalesced into a full block. 
On a 4096/1024 filesystem, a file is represented by zero or more 4096-byte blocks of data, possibly plus a single fragmented block. If the system must fragment a block to obtain space for a few data, it makes the remaining fragments of the block available for allocation to other files. As an example, consider an 11,000-byte file stored on a 4096/1024 filesystem. This file would use two full-sized blocks and one three-fragment portion of another block. If no block with three aligned fragments were available at the time that the file was created, a full-sized block would be split, yielding the necessary fragments and a single unused fragment. This remaining fragment could be allocated to another file as needed. Reading and Writing to a File Having opened a file, a process can do reads or writes on it. The procedural path through the kernel is shown in Figure 8.32 (on page 368). If a read is requested, it is channeled through the ffs_read() routine. Ffs_read() is responsible for converting the read into one or more reads of logical file blocks. A logical block request is then handed off to ufs_bmap(). Ufs_bmap() is responsible for converting a logical block number to a physical block number by interpreting the direct and indirect block pointers in an inode. Ffs_read() requests the block I/O system to return a buffer filled with the contents of the disk block. If two or more logically sequential blocks are read from a file, the process is assumed to be reading the file sequentially. Here, ufs_bmap () returns two values: first, the disk address of the requested block and then the number of contiguous blocks that follow that block on disk. The requested block and the number of contiguous blocks that follow it are passed to the cluster() routine. If the file is being accessed sequentially, the cluster() routine will do a single large I/O on the entire range of sequential blocks. If the file is not being accessed sequentially (as determined by a seek to a different part of the file preceding the read), only the requested block or a subset of the cluster will be read. If the file has had a long series of sequential reads, or if the number of contiguous blocks is small, the system will issue one or more requests for read-ahead blocks in anticipation that the process will soon want those blocks. The details of block clustering are described at the end of this section. Figure 8.32. Procedural interface to reading and writing. 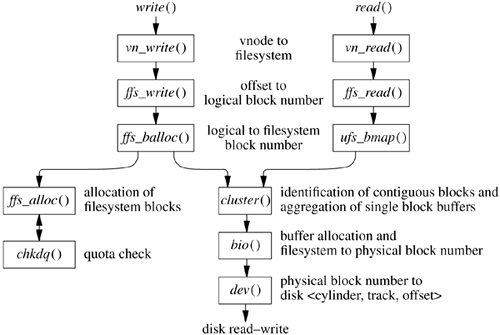
Each time that a process does a write system call, the system checks to see whether the size of the file has increased. A process may overwrite data in the middle of an existing file in which case space would usually have been allocated already (unless the file contains a hole in that location). If the file needs to be extended, the request is rounded up to the next fragment size, and only that much space is allocated (see "Allocation Mechanisms" later in this section for the details of space allocation). The write system call is channeled through the ffs_write () routine. Ffs_write() is responsible for converting the write into one or more writes of logical file blocks. A logical block request is then handed off to ffs_balloc(). Ffs_balloc() is responsible for interpreting the direct and indirect block pointers in an inodc to find the location for the associated physical block pointer. If a disk block does not already exist, the ffs_alloc() routine is called to request a new block of the appropriate size. After calling chkdq() to ensure that the user has not exceeded his quota, the block is allocated, and the address of the new block is stored in the inode or indirect block. The address of the new or already-existing block is returned. Ffs_write() allocates a buffer to hold the contents of the block. The user's data are copied into the returned buffer, and the buffer is marked as dirty. If the buffer has been filled completely, it is passed to the cluster() routine. When a maximally sized cluster has been accumulated, a noncontiguous block is allocated, or a seek is done to another part of the file, and the accumulated blocks are grouped together into a single I/O operation that is queued to be written to the disk. If the buffer has not been filled completely, it is not considered immediately for writing. Instead, the buffer is held in the expectation that the process will soon want to add more data to it. It is not released until it is needed for some other block that is, until it has reached the head of the free list or until a user process does an fsync system call. When a file acquires its first dirty block, it is placed on a 30-second timer queue. If it still has dirty blocks when the timer expires, all its dirty buffers are written. If it subsequently is written again, it will be returned to the 30-second timer queue. Repeated small write requests may expand the file one fragment at a time. The problem with expanding a file one fragment at a time is that data may be copied many times as a fragmented block expands to a full block. Fragment reallocation can be minimized if the user process writes a full block at a time, except for a partial block at the end of the file. Since filesystems with different block sizes may reside on the same system, the filesystem interface provides application programs with the optimal size for a read or write. This facility is used by the standard I/O library that many application programs use and by certain system utilities, such as archivers and loaders, that do their own I/O management. If the layout policies (described at the end of this section) are to be effective, a filesystem cannot be kept completely full. A parameter, termed the free-space reserve, gives the minimum percentage of filesystem blocks that should be kept free. If the number of free blocks drops below this level, only the superuser is allowed to allocate blocks. This parameter can be changed any time that the filesystem is unmounted. When the number of free blocks approaches zero, the filesystem throughput tends to be cut in half because the filesystem is unable to localize blocks in a file. If a filesystem's throughput drops because of overfilling, it can be restored by removal of files until the amount of free space once again reaches the minimum acceptable level. Users can restore locality to get faster access rates for files created during periods of little free space by copying the file to a new one and removing the original one when enough space is available. Layout Policies Each filesystem is parameterized so that it can be adapted to the characteristics of the application environment in which it is being used. These parameters are summarized in Table 8.13. In most situations, the default parameters work well, but in an environment with only a few large files or an environment with just a few huge directories, the performance can be enhanced by adjusting the layout parameters accordingly. Table 8.13. Important parameters maintained by the filesystem.Name | Default | Meaning |
|---|
minfree | 8% | minimum percentage of free space | avgfilesize | 16K | expected average file size | filesperdir | 64 | expected number of files per directory | maxbpg | 2048 | maximum blocks per file in a cylinder group | maxcontig | 8 | maximum contiguous blocks that can be transfered in one I/O request |
The filesystem layout policies are divided into two distinct parts. At the top level are global policies that use summary information to make decisions regarding the placement of new inodes and data blocks. These routines are responsible for deciding the placement of new directories and files. They also build contiguous block layouts and decide when to force a long seek to a new cylinder group because there is insufficient space left in the current cylinder group to do reasonable layouts. Below the global-policy routines are the local-allocation routines. These routines use a locally optimal scheme to lay out data blocks. The original intention was to bring out these decisions to user level so that they could be ignored or replaced by user processes. Thus, they are policies, rather than simple mechanisms. Two methods for improving filesystem performance are to increase the locality of reference to minimize seek latency [Trivedi, 1980] and to improve the layout of data to make larger transfers possible [Nevalainen & Vesterinen, 1977]. The global layout policies try to improve performance by clustering related information. They cannot attempt to localize all data references but must instead try to spread unrelated data among different cylinder groups. If too much localization is attempted, the local cylinder group may run out of space, forcing further related data to be scattered to nonlocal cylinder groups. Taken to an extreme, total localization can result in a single huge cluster of data resembling the 3BSD filesystem. The global policies try to balance the two conflicting goals of localizing data that are concurrently accessed while spreading out unrelated data. One allocatable resource is inodes. Inodes of files in the same directory frequently are accessed together. For example, the list-directory command, ls, may access the inode for each file in a directory. The inode layout policy tries to place all the inodes of files in a directory in the same cylinder group. To ensure that files are distributed throughout the filesystem, the system uses a different policy to allocate directory inodes. When a directory is being created in the root of the filesystem, it is placed in a cylinder group with a greater-than-average number of free blocks and inodes and with the smallest number of directories. The intent of this policy is to allow inode clustering to succeed most of the time. When a directory is created lower in the tree, it is placed in a cylinder group with with a greater-than-average number of free blocks and inodes near its parent directory. The intent of this policy is to reduce the distance tree-walking applications must seek as they move from directory to directory in a depth first search while still allowing inode clustering to succeed most of the time. The filesystem allocates inodes within a cylinder group using a first-free strategy. Although this method allocates the inodes randomly within a cylinder group, it keeps the allocation down to the smallest number of inode blocks possible. Even when all the possible inodes in a cylinder group are allocated, they can be accessed with 10 to 20 disk transfers. This allocation strategy puts a small and constant upper bound on the number of disk transfers required to access the inodes for all the files in a directory. In contrast, the 3BSD filesystem typically requires one disk transfer to fetch the inode for each file in a directory. The other major resource is the data blocks. Data blocks for a file typically are accessed together. The policy routines try to place data blocks for a file in the same cylinder group, preferably laid out contiguously. The problem with allocating all the data blocks in the same cylinder group is that large files quickly use up the available space, forcing a spillover to other areas. Further, using all the space causes future allocations for any file in the cylinder group also to spill to other areas. Ideally, none of the cylinder groups should ever become completely full. The heuristic chosen is to redirect block allocation to a different cylinder group after every few Mbyte of allocation. The spillover points are intended to force block allocation to be redirected when any file has used about 25 percent of the data blocks in a cylinder group. In day-to-day use, the heuristics appear to work well in minimizing the number of completely filled cylinder groups. Although this heuristic appears to benefit small files at the expense of the larger files, it really aids both file sizes. The small files are helped because there are nearly always blocks available in the cylinder group for them to use. The large files benefit because they are able to use the contiguous space available in the cylinder group and then to move on, leaving behind the blocks scattered around the cylinder group. Although these scattered blocks are fine for small files that need only a block or two, they slow down big files that are best stored on a single large group of blocks that can be read in a few disk revolutions. The newly chosen cylinder group for block allocation is the next cylinder group that has a greater-than-average number of free blocks left. Although big files tend to be spread out over the disk, several Mbyte of data typically are accessible before a seek to a new cylinder group is necessary. Thus, the time to do one long seek is small compared to the time spent in the new cylinder group doing the I/O. Allocation Mechanisms The global-policy routines call local-allocation routines with requests for specific blocks. The local-allocation routines will always allocate the requested block if it is free; otherwise, they will allocate a free block of the requested size that is closest to the requested block. If the global layout policies had complete information, they could always request unused blocks, and the allocation routines would be reduced to simple bookkeeping. However, maintaining complete information is costly; thus, the global layout policy uses heuristics based on the partial information that is available. If a requested block is not available, the local allocator uses a three-level allocation strategy: Use the next available block closest to the requested block in the same cylinder group. If the cylinder group is full, quadratically hash the cylinder-group number to choose another cylinder group in which to look for a free block. Quadratic hash is used because of its speed in finding unused slots in nearly full hash tables [Knuth, 1975]. Filesystems that are parameterized to maintain at least 8 percent free space rarely need to use this strategy. Filesystems used without free space typically have so few free blocks available that almost any allocation is random; the most important characteristic of the strategy used under such conditions is that it be fast. Apply an exhaustive search to all cylinder groups. This search is necessary because the quadratic rehash may not check all cylinder groups.
The task of managing block and fragment allocation is done by ffs_balloc(). If the file is being written and a block pointer is zero or points to a fragment that is too small to hold the additional data, ffs_balloc() calls the allocation routines to obtain a new block. If the file needs to be extended, one of two conditions exists: The file contains no fragmented blocks (and the final block in the file contains insufficient space to hold the new data). If space exists in a block already allocated, the space is filled with new data. If the remainder of the new data consists of more than a full block, a full block is allocated and the first full block of new data are written there. This process is repeated until less than a full block of new data remains. If the remaining new data to be written will fit in less than a full block, a block with the necessary number of fragments is located; otherwise, a full block is located. The remaining new data are written into the located space. However, to avoid excessive copying for slowly growing files, the filesystem allows only direct blocks of files to refer to fragments. The file contains one or more fragments (and the fragments contain insufficient space to hold the new data). If the size of the new data plus the size of the data already in the fragments exceeds the size of a full block, a new block is allocated. The contents of the fragments are copied to the beginning of the block, and the remainder of the block is filled with new data. The process then continues as in step 1. Otherwise, a set of fragments big enough to hold the data is located; if enough of the rest of the current block is free, the filesystem can avoid a copy by using that block. The contents of the existing fragments, appended with the new data, are written into the allocated space.
Ffs_balloc() is also responsible for allocating blocks to hold indirect pointers. It must also deal with the special case in which a process seeks past the end of a file and begins writing. Because of the constraint that only the final block of a file may be a fragment, ffs_balloc() must first ensure that any previous fragment has been upgraded to a full-sized block. On completing a successful allocation, the allocation routines return the block or fragment number to be used; ffs_balloc() then updates the appropriate block pointer in the inode. Having allocated a block, the system is ready to allocate a buffer to hold the block's contents so that the block can be written to disk. The procedural description of the allocation process is shown in Figure 8.33. Ffs_balloc() is the routine responsible for determining when a new block must be allocated. It first calls the layout-policy routine ffs_blkpref() to select the most desirable block based on the preference from the global-policy routines that were described earlier in this section. If a fragment has already been allocated and needs to be extended, ffs_balloc() calls ffs_realloccg(). If nothing has been allocated yet, ffs_balloc() calls ffs_alloc(). Figure 8.33. Procedural interface to block allocation. 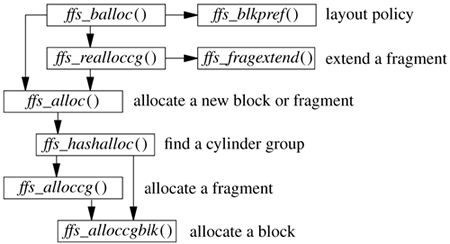
Ffs_realloccg() first tries to extend the current fragment in place. Consider the sample block of an allocation map with two fragments allocated from it, shown in Figure 8.34 (on page 374). The first fragment can be extended from a size 2 fragment to a size 3 or a size 4 fragment, since the two adjacent fragments are unused. The second fragment cannot be extended, as it occupies the end of the block, and fragments are not allowed to span blocks. If ffs_realloccg() is able to expand the current fragment in place, the map is updated appropriately and it returns. If the fragment cannot be extended, ffs_realloccg() calls the ffs_alloc() routine to get a new fragment. The old fragment is copied to the beginning of the new fragment, and the old fragment is freed. Figure 8.34. Sample block with two allocated fragments. 
The bookkeeping tasks of allocation are handled by ffs_alloc(). It first verifies that a block is available in the desired cylinder group by checking the filesystem summary information. If the summary information shows that the cylinder group is full, ffs_alloc() quadratically rehashes through the summary information looking for a cylinder group with free space. Having found a cylinder group with space, ffs_alloc() calls either the fragment-allocation routine or the block-allocation routine to acquire a fragment or block. The block-allocation routine is given a preferred block. If that block is available, it is returned. If the block is unavailable, the allocation routine tries to find another block in the same cylinder group that is close to the requested block. It looks for an available block by scanning forward through the free-block map, starting from the requested location until it finds an available block. The fragment-allocation routine is given a preferred fragment. If that fragment is available, it is returned. If the requested fragment is not available, and the filesystem is configured to optimize for space utilization, the filesystem uses a best-fit strategy for fragment allocation. The fragment-allocation routine checks the cylinder-group summary information, starting with the entry for the desired size, and scanning larger sizes until an available fragment is found. If there are no fragments of the appropriate size or larger, then a full-sized block is allocated and is broken up. If an appropriate-sized fragment is listed in the fragment summary, then the allocation routine expects to find it in the allocation map. To speed up the process of scanning the potentially large allocation map, the filesystem uses a table-driven algorithm. Each byte in the map is treated as an index into a fragment-descriptor table. Each entry in the fragment-descriptor table describes the fragments that are free for that corresponding map entry. Thus, by doing a logical AND with the bit corresponding to the desired fragment size, the allocator can determine quickly whether the desired fragment is contained within a given allocation-map entry. As an example, consider the entry from an allocation map for the 8192/1024 filesystem shown in Figure 8.35. The map entry shown has already been fragmented, with a single fragment allocated at the beginning and a size 2 fragment allocated in the middle. Remaining unused is another size 2 fragment and a size 3 fragment. Thus, if we lookup entry 115 in the fragment table, we find the entry shown in Figure 8.36. If we were looking for a size 3 fragment, we would inspect the third bit and find that we had been successful; if we were looking for a size 4 fragment, we would inspect the fourth bit and find that we needed to continue. The C code that implements this algorithm is as follows: for (i = 0; i < MAPSIZE; i++) if (fragtbl [allocmap[i] ] & (1 << (size - 1)) ) break;
Figure 8.35. Map entry for an 8192/1024 filesystem. 
Figure 8.36. Fragment-table entry for entry 115. 
Using a best-fit policy has the benefit of minimizing disk fragmentation; however, it has the undesirable property that it maximizes the number of fragment-to-fragment copies that must be made when a process writes a file in many small pieces. To avoid this behavior, the system can configure filesystems to optimize for time rather than for space. The first time that a process does a small write on a filesystem configured for time optimization, it is allocated a best-fit fragment. On the second small write, however, a full-sized block is allocated, with the unused portion being freed. Later small writes are able to extend the fragment in place, rather than requiring additional copy operations. Under certain circumstances, this policy can cause the disk to become heavily fragmented. The system tracks this condition and automatically reverts to optimizing for space if the percentage of fragmentation reaches one-half of the minimum free-space limit. Block Clustering Most machines running FreeBSD do not have separate I/O processors. The main CPU must take an interrupt after each disk I/O operation; if there is more disk I/O to be done, it must select the next buffer to be transferred and must start the operation on that buffer. Before the advent of track-caching controllers, the filesystem obtained its highest throughput by leaving a gap after each block to allow time for the next I/O operation to be scheduled. If the blocks were laid out without a gap, the throughput would suffer because the disk would have to rotate nearly an entire revolution to pick up the start of the next block. Track-caching controllers have a large buffer in the controller that continues to accumulate the data coming in from the disk even after the requested data have been received. If the next request is for the immediately following block, the controller will already have most of the block in its buffer, so it will not have to wait a revolution to pick up the block. Thus, for the purposes of reading, it is possible to nearly double the throughput of the filesystem by laying out the files contiguously rather than leaving gaps after each block. Unfortunately, the track cache is less useful for writing. Because the kernel does not provide the next data block until the previous one completes, there is still a delay during which the controller does not have the data to write, and it ends up waiting a revolution to get back to the beginning of the next block. One solution to this problem is to have the controller give its completion interrupt after it has copied the data into its cache, but before it has finished writing them. This early interrupt gives the CPU time to request the next I/O before the previous one completes, thus providing a continuous stream of data to write to the disk. This approach has one seriously negative side effect. When the I/O completion interrupt is delivered, the kernel expects the data to be on stable store. Filesystem integrity and user applications using the fsync system call depend on these semantics. These semantics will be violated if the power fails after the I/O completion interrupt but before the data are written to disk. Some vendors eliminate this problem by using nonvolatile memory for the controller cache and providing microcode restart after power fail to determine which operations need to be completed. Because this option is expensive, few controllers provide this functionality. Newer disks resolve this problem with a technique called tag queueing. With tag queueing, each request passed to the disk driver is assigned a unique numeric tag. Most disk controllers supporting tag queueing will accept at least 16 pending I/O requests. After each request is finished, the tag of the completed request is returned as part of the completion interrupt. If several contiguous blocks are presented to the disk controller, it can begin work on the next one while the tag for the previous one is being returned. Thus, tag queueing allows applications to be accurately notified when their data has reached stable store without incurring the penalty of lost disk revolutions when writing contiguous blocks. To maximize throughput on systems without tag queueing or nonvolatile controller memory, the FreeBSD system implements I/O clustering. Clustering helps improve performance on all systems by reducing the number of I/O requests through the aggregation of many small requests into a smaller number of big ones. Clustering was first done by Santa Cruz Operations [Peacock, 1988] and Sun Microsystems [McVoy & Kleiman, 1991]; the idea was later adapted to 4.4BSD and thus to FreeBSD [Seltzer et al., 1993]. As a file is being written, the allocation routines try to allocate up to maxcontig (typically 128 Kbyte) of data in contiguous disk blocks. Instead of the buffers holding these blocks being written as they are filled, their output is delayed. The cluster is completed when the limit of maxcontig of data is reached, the file is closed, or the cluster cannot grow because the next sequential block on the disk is already in use by another file. If the cluster size is limited by a previous allocation to another file, the filesystem is notified and is given the opportunity to find a larger set of contiguous blocks into which the cluster may be placed. If the reallocation is successful, the cluster continues to grow. When the cluster is complete, the buffers making up the cluster of blocks are aggregated and passed to the disk controller as a single I/O request. The data can then be streamed out to the disk in a single uninterrupted transfer. A similar scheme is used for reading. If the ffs_read() discovers that a file is being read sequentially, it inspects the number of contiguous blocks returned by ufs_bmap() to look for clusters of contiguously allocated blocks. It then allocates a set of buffers big enough to hold the contiguous set of blocks and passes them to the disk controller as a single I/O request. The I/O can then be done in one operation. Although read clustering is not needed when track-caching controllers are available, it reduces the interrupt load from systems that have them, and it speeds low-cost systems that do not have them. For clustering to be effective, the filesystem must be able to allocate large clusters of contiguous blocks to files. If the filesystem always tried to begin allocation for a file at the beginning of a large set of contiguous blocks, it would soon use up its contiguous space. Instead, it uses an algorithm similar to that used for the management of fragments. Initially, file blocks are allocated via the standard algorithm described in the previous two subsections. Reallocation is invoked when the standard algorithm does not result in a contiguous allocation. The reallocation code searches a cluster map that summarizes the available clusters of blocks in the cylinder group. It allocates the first free cluster that is large enough to hold the file and then moves the file to this contiguous space. This process continues until the current allocation has grown to a size equal to the maximum permissible I/O operation (maxcontig). At that point, the I/O is done, and the process of allocating space begins again. Unlike fragment reallocation, block reallocation to different clusters of blocks does not require extra I/O or memory-to-memory copying. The data to be written are held in delayed write buffers. Within that buffer is the disk location to which the data are to be written. When the block cluster is relocated, it takes little time to walk the list of buffers in the cluster and to change the disk addresses to which they are to be written. When the I/O occurs, the final destination has been selected and will not change. To speed the operation of finding clusters of blocks, the filesystem maintains a cluster map with 1 bit per block (in addition to the map with 1 bit per fragment). It also has summary information showing how many sets of blocks there are for each possible cluster size. The summary information allows it to avoid looking for cluster sizes that do not exist. The cluster map is used because it is faster to scan than is the much larger fragment bitmap. The size of the map is important because the map must be scanned bit by bit. Unlike fragments, clusters of blocks are not constrained to be aligned within the map. Thus, the table-lookup optimization done for fragments cannot be used for lookup of clusters. The filesystem relies on the allocation of contiguous blocks to achieve high levels of performance. The fragmentation of free space may increase with time or with filesystem utilization. This fragmentation can degrade performance as the filesystem ages. The effects of utilization and aging were measured on over 50 filesystems at Harvard University. The measured filesystems ranged in age since initial creation from one to three years. The fragmentation of free space on most of the measured filesystems caused performance to degrade no more than 10 percent from that of a newly created empty filesystem. The most severe degradation measured was 30 percent on a highly active filesystem that had many small files and was used to spool USENET news [Seltzer et al., 1995]. Extent-based Allocation Figure 8.37. Alternative file metadata representations. 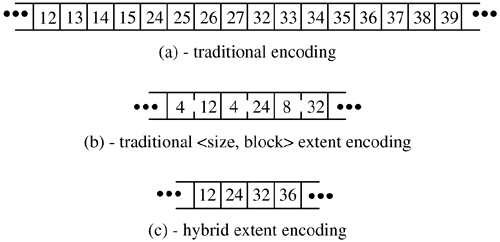
With the addition of dynamic block reallocation in the early 1990s [Seltzer & Smith, 1996], the UFS1 filesystem has had the ability to allocate most files contiguously on the disk. The metadata describing a large file consists of indirect blocks with long runs of sequential block numbers, see Figure 8.37(a). For quick access while a file is active, the kernel tries to keep all a file's metadata in memory. With UFS2 the space required to hold the metadata for a file is doubled as every block pointer grows from 32 bits to 64 bits. To provide a more compact representation, many filesystems use an extent-based representation. A typical extent-based representation uses pairs of block numbers and lengths. Figure 8.37(b) represents the same set of block numbers as Figure 8.37(a) in an extent-based format. If the file can be laid out nearly contiguously, this representation provides a compact description. However, randomly or slowly written files can end up with many noncontiguous block allocations, which will produce a representation that requires more space than the one used by UFS1. This representation also has the drawback that it can require much computation to do random access to the file, since the block number needs to be computed by adding up the sizes starting from the beginning of the file until the desired seek offset is reached. To gain most of the efficiencies of extents without the random access inefficiencies, UFS2 has added a field to the inode that will allow that inode to use a larger block size. Small, slowly growing, or sparse files set this value to the regular filesystem block size and represent their data in the traditional way shown in Figure 8.37(a). However, when the filesystem detects a large, dense file, it can set this inode-block-size field to a value 2 to 16 times the filesystem block size. Figure 8.37(c) represents the same set of block numbers as Figure 8.37(a), with the inode-block-size field set to 4 times the filesystem block size. Each block pointer references a piece of disk storage that is four times larger, which reduces the metadata storage requirement by 75 percent. Since every block pointer other than possibly the last one references an equal-sized block, computation of random access offsets is just as fast as in the traditional metadata representation. Unlike the traditional extent-based representation that can double the metadata space requirement for certain datasets, this representation will always result in less space dedicated to metadata. The drawback to this approach is that once a file has committed to using a larger block size, it can only use blocks of that size. If the filesystem runs out of big blocks, then the file can no longer grow, and either the application will get an "out-of-space" error or the filesystem has to recreate the metadata with the standard filesystem block size. The current plan is to write the code to recreate the metadata. While recreating the metadata usually will cause a long pause, we expect that condition to be rare and not a noticeable problem in real use. |