Section 19.4. The Cyclic Subsystem
19.4. The Cyclic SubsystemHistorically, most computer architectures have specified interval-based timer parts (for example, the SPARCstation counter/timer; the Intel i8254). While these parts deal in relative (that is, not absolute) time values, they are typically used by the operating system to implement the abstraction of absolute time. As a result, these parts cannot typically be reprogrammed without introducing error in the system's notion of time. Starting in about 1994, chip architectures began specifying high-resolution timestamp registers. As of this writing (2006), all major chip families (UltraSPARC, PentiumPro, MIPS, PowerPC, Alpha) have high-resolution timestamp registers, and two (UltraSPARC and MIPS) have added the capacity to interrupt according to timestamp values. These timestamp-compare registers present a time-based interrupt source that can be reprogrammed arbitrarily often without introducing error. Given the low cost of implementing such a timestamp-compare register (and the tangible benefit of eliminating discrete timer parts), it is reasonable to expect that future chip architectures will adopt this feature. The cyclic subsystem takes advantage of chip architectures with the capacity to interrupt on the basis of absolute, high-resolution time values. The cyclic subsystem is a low-level kernel subsystem that provides arbitrarily high resolution, per-CPU interval timers (to avoid colliding with existing terms, we dub such an interval timer a "cyclic"). Cyclics can be specified to fire at high, lock, or low interrupt level and can be optionally bound to a CPU or CPU partition. A cyclic's CPU or CPU partition binding can be changed dynamically; the cyclic will be "juggled" to a CPU that satisfies the new binding. Alternatively, a cyclic can be specified to be "omnipresent," denoting firing on all online CPUs. 19.4.1. Cyclic Subsystem Interface OverviewThe cyclic subsystem has interfaces with the kernel at-large, with other kernel subsystems (for example, the processor management subsystem, the checkpoint-resume subsystem) and with the platform (the cyclic back end). Each of these interfaces is synopsized here and is described in full in Section 19.4.4 and Section 19.4.6. Figure 19.4 displays the cyclic subsystem's interfaces to other kernel components. The arrows denote a "calls" relationship, with the large arrow indicating the cyclic subsystem's consumer interface. Figure 19.4. Cyclic Subsystem Overview 19.4.2. Cyclic Subsystem Implementation OverviewThe cyclic subsystem minimizes interference between cyclics on different CPUs. Thus, all the cyclic subsystem's data structures hang off of a per-CPU structure, cyc_cpu. Each cyc_cpu has a power-of-2 sized array of cyclic structures (the cyp_cyclics member of the cyc_cpu structure). If cyclic_add() is called and the cyp_cyclics array has no free slot, the size of the array is doubled. The array will never shrink. Cyclics are referred to by their index in the cyp_cyclics array, which is of type cyc_index_t. The cyclics are kept sorted by expiration time in the cyc_cpu's heap. The heap is keyed by cyclic expiration time, with parents expiring earlier than their children. 19.4.2.1. Heap ManagementThe heap is managed primarily by cyclic_fire(). Upon entry, cyclic_fire() compares the root cyclic's expiration time to the current time. If the expiration time is in the past, cyclic_expire() is called on the root cyclic. Upon return from cyclic_expire(), the cyclic's new expiration time is derived by adding its interval to its old expiration time, and a downheap operation is performed. After the downheap, cyclic_fire() examines the (potentially changed) root cyclic, repeating the cyclic_expire()/add interval/cyclic_downheap() sequence until the root cyclic has an expiration time in the future. This expiration time (guaranteed to be the earliest in the heap) is then communicated to the back end by cyb_reprogram(). Optimal back ends will next call cyclic_fire() shortly after the root cyclic's expiration time. To allow efficient, deterministic downheap operations, we implement the heap as an array (the cyp_heap member of the cyc_cpu structure), with each element containing an index into the CPU's cyp_cyclics array. The heap is laid out in the array according to the following:
This layout is standard (see, for example, Cormen's "Algorithms"); the proof that these constraints correctly lay out a heap (or indeed, any binary tree) is trivial and left to the reader. To see the heap by example, assume our cyclics array has the following members (at time t), as shown in Table 19.1.
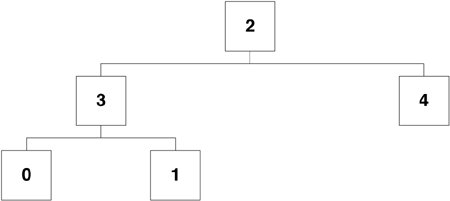
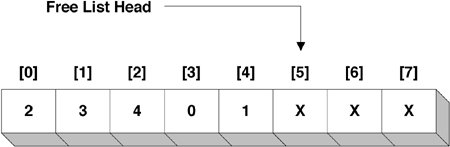
The heap array could be Figure 19.5. Cyclic Array Example, Starting Graphically, this array corresponds to the graph shown in Figure 19.6. Figure 19.6. Cyclic Graph for Figure 19.5 Note that the heap is laid out by layer. All nodes at a given depth are stored in consecutive elements of the array. Moreover, layers of consecutive depths are in adjacent element ranges. This property guarantees high locality of reference during downheap operations. Specifically, we are guaranteed that we can downheap to a depth of lg (cache_line_size / sizeof (cyc_index_t)) nodes with at most one cache miss. On UltraSPARC (64 byte e-cache line size), this corresponds to a depth of four nodes. Thus, if fewer than 16 cyclics are in the heap, downheaps on UltraSPARC miss at most once in the e-cache. Downheaps are required to compare siblings as they proceed down the heap. For downheaps proceeding beyond the one-cache-miss depth, every access to a left child could potentially miss in the cache. However, if we assume (cache_line_size / sizeof (cyc_index_t)) > 2 then all siblings are guaranteed to be on the same cache line. Thus, the miss on the left child will guarantee a hit on the right child; downheaps will incur at most one cache miss per layer beyond the one-cache-miss depth. The total number of cache misses for heap management during a downheap operation is thus bounded by lg (n) - lg (cache_line_size / sizeof (cyc_index_t)) Traditional pointer-based heaps are implemented without regard to locality. Downheaps can thus incur two cache misses per layer (one for each child), but at most one cache miss at the root. This yields a bound of 2 * lg (n) 1 on the total cache misses. This difference may seem theoretically trivial (the difference is, after all, constant), but can become substantial in practiceespecially for caches with very large cache lines and high miss penalties (for example, TLBs). Heaps must always be full, balanced trees. Heap management must therefore track the next point-of-insertion into the heap. In pointer-based heaps, recomputing this point takes O(lg (n)). Given the layout of the array-based implementation, however, the next point-of-insertion is always heap[number_of_elements] We exploit this property by implementing the free-list in the unused heap elements. Heap insertion, therefore, consists only of filling in the cyclic at cyp_cyclics[cyp_heap[number_of_elements]], incrementing the number of elements, and performing an upheap. Heap deletion consists of decrementing the number of elements, swapping the to-be-deleted element with the element at cyp_heap[number_of_elements], and downheaping. Figure 19.7 fills in more details in our earlier example. Figure 19.7. More Details Added to Cyclic Array Example To insert into this heap, we would just need to fill in the cyclic at cyp_cyclics[5], bump the number of elements (from 5 to 6), and perform an upheap. If we wanted to remove, say, cyp_cyclics[3], we would first scan for it in the cyp_heap, and discover it at cyp_heap[1]. We would then decrement the number of elements (from 5 to 4), swap cyp_heap[1] with cyp_heap[4], and perform a downheap from cyp_heap[1]. The linear scan is required because the cyclic does not keep a back-pointer into the heap. This makes heap manipulation (for example, down-heaps) faster at the expense of removal operations. 19.4.2.2. Expiry ProcessingAs alluded to above, cyclic_expire() is called by cyclic_fire() at CY_HIGH_LEVEL to expire a cyclic. Cyclic subsystem consumers are guaranteed that for an arbitrary time t in the future, their cyclic handler will have been called (t - cyt_when) / cyt_interval times. Thus, there must be a one-to-one mapping between a cyclic's expiration at CY_HIGH_LEVEL and its execution at the desired level (CY_HIGH_LEVEL, CY_LOCK_LEVEL, or CY_LOW_LEVEL). For CY_HIGH_LEVEL cyclics, this is trivial; cyclic_expire() simply needs to call the handler. For CY_LOCK_LEVEL and CY_LOW_LEVEL cyclics, however, there exists a potential disconnect: If the CPU is at an interrupt level less than CY_HIGH_LEVEL but greater than the level of a cyclic for a period of time longer than twice the cyclic's interval, the cyclic will be expired twice before it can be handled. To maintain the one-to-one mapping, we track the difference between the number of times a cyclic has been expired and the number of times it has been handled in a "pending count" (the cy_pend field of the cyclic structure). cyclic_expire() thus increments the cy_pend count for the expired cyclic and posts a soft interrupt at the desired level. In the cyclic subsystem's soft interrupt handler, cyclic_softint(), we repeatedly call the cyclic handler and decrement cy_pend until we have decremented cy_pend to zero. 19.4.2.3. The Producer/Consumer BufferTo avoid a linear scan of the cyclics array at the soft interrupt level, cyclic_softint() must be able to quickly determine which cyclics have a non-zero cy_pend count. We thus introduce a per-soft-interrupt-level producer/consumer buffer shared with CY_HIGH_LEVEL. These buffers are encapsulated in the cyc_pcbuffer structure and, like cyp_heap, are implemented as cyc_index_t arrays (the cypc_buf member of the cyc_pcbuffer structure). The producer (cyclic_expire() running at CY_HIGH_LEVEL) enqueues a cyclic by storing the cyclic's index to cypc_buf[cypc_prodndx] and incrementing cypc_prodndx. The consumer (cyclic_softint() running at either CY_LOCK_LEVEL or CY_LOW_LEVEL) dequeues a cyclic by loading from cypc_buf[cypc_consndx] and bumping cypc_consndx. The buffer is empty when cypc_prodndx == cypc_consndx. To bound the size of the producer/consumer buffer, cyclic_expire() only enqueues a cyclic if its cy_pend was zero (if the cyclic's cy_pend is non-zero, cyclic_expire() only bumps cy_pend). Symmetrically, cyclic_softint() only consumes a cyclic after it has decremented the cy_pend count to zero. Returning to our example, Figure 19.8 shows what the CY_LOW_LEVEL producer/consumer buffer might look like. Figure 19.8. Cyclic Array Example with Producer/Consumer Buffer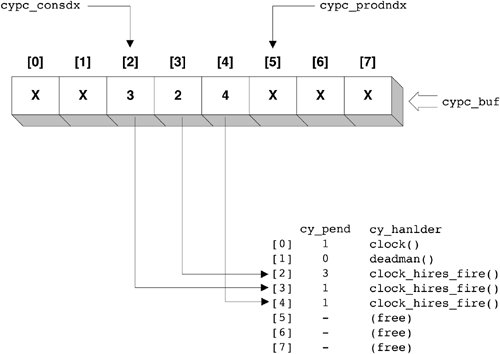 In particular, note that clock()'s cy_pend is 1 but that it is not in this producer/ consumer buffer; it would be enqueued in the CY_LOCK_LEVEL producer/consumer buffer. 19.4.2.4. LockingTraditionally, access to per-CPU data structures shared between interrupt levels is serialized by manipulation of the programmable interrupt level: Readers and writers are required to raise their interrupt level to that of the highest-level writer. The producer/consumer buffers are shared between cyclic_fire()/ cyclic_expire(), which execute at CY_HIGH_LEVEL, and cyclic_softint(), which executes at one of CY_LOCK_LEVEL or CY_LOW_LEVEL. So forcing cyclic_softint() to raise the programmable interrupt level is undesirable. Aside from the additional latency incurred by manipulating the interrupt level in the hot cy_pend processing path, raising the interrupt level would create the potential for soft-level cy_pend processing to delay CY_HIGH_LEVEL firing and expiry processing. CY_LOCK/LOW_LEVEL cyclics could thereby induce jitter in CY_HIGH_LEVEL cyclics. To minimize jitter, then, we would like the cyclic_fire()/cyclic_expire() and cyclic_softint() code paths to be lock free. For cyclic_fire()/cyclic_expire(), lock-free execution is straightforward. Because these routines execute at a higher interrupt level than cyclic_softint(), their actions on the producer/consumer buffer appear atomic. In particular, the increment of cy_pend appears to occur atomically with the increment of cypc_prodndx. For cyclic_softint(), however, lock-free execution requires more delicacy. When cyclic_softint() discovers a cyclic in the producer/consumer buffer, it calls the cyclic's handler and attempts to atomically decrement the cy_pend count with a compare-and-swap operation.
If the count was decremented to a non-zero value, more work must be done on the cyclic; cyclic_softint() calls the cyclic handler and repeats the atomic decrement process. If the compare-and-swap operation fails, cyclic_softint() recognizes that cyclic_expire() has intervened and bumped the cy_pend count. (Resizes and removals complicate this, howeversee the sections on their operation, below.) cyclic_softint() thus reloads cy_pend and reattempts the atomic decrement. Recall that we bound the size of the producer/consumer buffer by having cyclic_expire() enqueue the specified cyclic only if its cy_pend count is zero; thus we ensure that each cyclic is enqueued at most once. This leads to a critical constraint on cyclic_softint(), however. After the compare-and-swap operation that successfully decrements cy_pend to zero, cyclic_softint() must not reexamine the consumed cyclic. In part to obey this constraint, cyclic_softint() calls the cyclic handler before decrementing cy_pend. 19.4.2.5. ResizingAll the discussion thus far has assumed a static number of cyclics. Obviously, static limitations are not practical; we need the capacity to resize our data structures dynamically. We resize our data structures lazily, and only on a per-CPU basis. The size of the data structures always doubles and never shrinks. We serialize adds (and thus resizes) on cpu_lock; we never need to deal with concurrent resizes. Resizes should be rare; they may induce jitter on the CPU being resized, but should not affect cyclic operation on other CPUs. Pending cyclics may not be dropped during a resize operation. Three key cyc_cpu data structures need to be resized: the cyclics array, the heap array, and the producer/consumer buffers. Resizing the first two is relatively straightforward:
The producer/consumer buffer is dicier: cyclic_expand_xcall() may have interrupted cyclic_softint() in the middle of consumption. To resize the producer/consumer buffer, we implement up to two buffers per soft interrupt level: a hard buffer (the buffer being produced into by cyclic_expire()) and a soft buffer (the buffer from which cyclic_softint() is consuming). During normal operation, the hard buffer and soft buffer point to the same underlying producer/consumer buffer. During a resize, however, cyclic_expand_xcall() changes the hard buffer to point to the new, larger producer/consumer buffer; all future cyclic_expire() functions will produce into the new buffer. cyclic_expand_xcall() then posts a CY_LOCK_LEVEL soft interrupt, landing in cyclic_softint(). As under normal operation, cyclic_softint() consumes cyclics from its soft buffer. After the soft buffer is drained, however, cyclic_softint() will see that the hard buffer has changed. At that time, cyclic_softint() changes its soft buffer to point to the hard buffer, and repeats the producer/consumer buffer draining procedure. After the new buffer is drained, cyclic_softint() determines whether both soft levels have seen their new producer/consumer buffer. If both have, cyclic_softint() posts on the semaphore cyp_modify_wait. If not, a soft interrupt is generated for the remaining level. cyclic_expand() blocks on the cyp_modify_wait semaphore (a semaphore is used instead of a condition variable because of the race between the sema_p() in cyclic_expand() and the sema_v() in cyclic_softint()). In that way, cyclic_expand() recognizes when the resize operation is complete, and all the old buffers (the heap, the cyclics array and the producer/ consumer buffers) can be freed. A final caveat on resizing: We described step (5) in the cyclic_expand_xcall() procedure without providing any motivation. This step addresses the problem of a cyclic_softint() attempting to decrement a cy_pend count while interrupted by a cyclic_expand_xcall(). Because cyclic_softint() has already called the handler by the time cy_pend is decremented, we want to ensure that it doesn't decrement a cy_pend count in the old cyclics array. By zeroing the old cyclics array in cyclic_expand_xcall(), we are zeroing out every cy_pend count. When cyclic_softint() attempts to compare-and-swap on the cy_pend count, it fails and recognizes that the count has been zeroed. cyclic_softint() updates its stale copy of the cyp_cyclics pointer, rereads the cy_pend count from the new cyclics array, and reattempts the compare-and-swap. 19.4.2.6. RemovalsCyclic removals should be rare. To simplify the implementation (and to allow optimization for the cyclic_fire()/cyclic_expire()/cyclic_softint() path), we force removals and adds to serialize on cpu_lock. Cyclic removal is complicated by a guarantee made to the consumer of the cyclic subsystem: After cyclic_remove() returns, the cyclic handler has returned and will never again be called. Here is the procedure for cyclic removal:
The motivation for step (3) is explained in Section 19.4.2.7. The cy_pend count is decremented in cyclic_softint() after the cyclic handler returns. Thus, if we find a cy_pend count of zero in step (4), we know that cyclic_remove() doesn't need to block. If the cy_pend count is non-zero, however, we must block in cyclic_remove() until cyclic_softint() has finished calling the cyclic handler. To let cyclic_softint() know that this cyclic has been removed, we zero the cy_pend count. This causes cyclic_softint()'s compare-and-swap to fail. cyclic_softint() then recognizes that the zero cy_pend count is zero, either because cyclic_softint() has been caught during a resize (see Section 19.4.2.5) or because the cyclic has been removed. In the latter case, it calls cyclic_remove_pend() to call the cyclic handler cyp_rpend 1 times, and posts on cyp_modify_wait. 19.4.2.7. JugglingAt first glance, cyclic juggling seems to be a difficult problem. The subsystem must guarantee that a cyclic doesn't execute simultaneously on different CPUs, while also ensuring that a cyclic fires exactly once per interval. We solve this problem by leveraging a property of the platform: gethrtime() is required to increase in lock-step across multiple CPUs. Therefore, to juggle a cyclic, we remove it from its CPU, recording its expiration time in the remove cross-call (step (3) in Section 19.4.2.6). We then add the cyclic to the new CPU, explicitly setting its expiration time to the time recorded in the removal. This leverages the existing cyclic expiry processing, which will compensate for any time lost while juggling. 19.4.3. Clients of the Cyclic SubsystemClients of the cyclic subsystem include the following:
19.4.4. Cyclic Kernel At-Large InterfacesThe cyclic interfaces for the kernel at-large are described in Table 19.2.
19.4.5. Cyclic Kernel Inter-Subsystem InterfacesThe cyclic interfaces between subsystems are described in Table 19.3.
19.4.6. Cyclic Backend InterfacesThe cyclic backend interfaces are described in Table 19.4.
The interfaces supplied by the back end (through the cyc_backend structure) are documented in detail in <sys/cyclic_impl.h> and in the next section. 19.4.7. Cyclic Subsystem Backend-Supplied InterfacesThe design, implementation and interfaces of the cyclic subsystem are covered in detail in block comments in the implementation. This comment covers the interface from the cyclic subsystem into the cyclic back end. The back end is specified by a structure of function pointers defined in Table 19.5.
|


EAN: 2147483647
Pages: 244