Section 18.8. Solaris Device Driver Framework
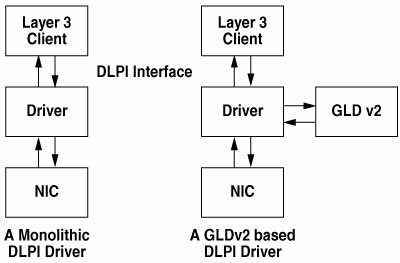
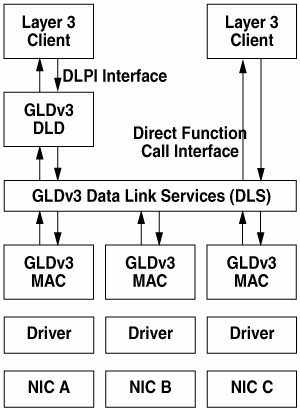
18.8. Solaris Device Driver FrameworkLet's quickly look at how network device drivers were implemented before Solaris 10 and why they needed to change with the new Solaris 10 stack. 18.8.1. GLDv2 and DLPI Drivers (Solaris 9 and Prior)Before the Solaris 10 release, the network stack depends on Data-Link Provider Interface (DLPI1) providers, which are normally implemented in one of two ways. Figure 18.5 illustrates two stacks: one based on a monolithic DLPI driver and one based on a driver utilizing the generic LAN driver (GLDv2) module. Figure 18.5. GLDv2 and DLPI Stacks The GLDv2 module essentially behaves like a library. The client still talks to the driver instance bound to the device, but the DLPI protocol processing is handled by a call into the GLDv2 module, which then calls back into the driver to access the hardware. Using the GLD module has a clear advantage in that the driver writer need not reimplement large amounts of mostly generic DLPI protocol processing. Layer 2 (Data-Link) features such as 802.1q virtual LANs (VLANs) can also be implemented centrally in the GLD module, where they can be leveraged by all drivers. The architecture still poses a problem, though, with respect to implementing features such as 802.3ad link aggregation (a.k.a. trunking) where the one-to-one correspondence between network interface and device is broken. Both GLDv2 and monolithic drivers depend on DLPI messages and communicate with upper layers through the STREAMS framework. This mechanism was relatively ineffective for link aggregation or 10-Gbit NICs. With the new stack, we needed a better mechanism that could ensure data locality and allow the stack to control the device drivers at much finer granularity to deal with interrupts. 18.8.2. A New Architecture: GLDv3The Solaris 10 release introduced a new device driver framework called GLDv3 (internal name project Nemo) along with the new stack. Most of the major device drivers were ported to this framework, and all future and 10-Gbit device drivers will be based on this framework. This framework also provided a STREAMS-based DLPI layer for backward compatibility (to allow external, non-IP modules to continue to work). The GLDv3 architecture virtualizes layer 2 of the network stack. There is no longer a one-to-one correspondence between network interfaces and devices. Figure 18.6 shows multiple devices registered with a MAC Services (MAC) module. It also shows two clients: one traditional client that communicates through DLPI to a data-link driver (DLD) and a kernel-based client that simply makes direct function calls into the Data-Link Services (DLS) module. Figure 18.6. GLDv3 Architecture 18.8.2.1. GLDv3 DriversGLDv3 drivers are similar to GLD drivers. The driver must be linked with a dependency on the misc/mac and misc/dld kernel modules. It must call mac_register() with a pointer to an instance of the following structure to register with the MAC module. typedef struct mac { const char *m_ident; /* MAC_IDENT */ mac_ext_t *m_extp; mac_impl_t *m_impl; /* MAC private data */ void *m_driver; /* Driver private data */ dev_info_t *m_dip; uint_t m_port; mac_info_t m_info; mac_stat_t m_stat; mac_start_t m_start; mac_stop_t m_stop; mac_promisc_t m_promisc; mac_multicst_t m_multicst; mac_unicst_t m_unicst; mac_resources_t m_resources; mac_ioctl_t m_ioctl; mac_tx_t m_tx; } mac_t; See usr/src/uts/common/sys/mac.h This structure must persist for the lifetime of the registration, that is, it cannot be deallocated until after mac_unregister() is called. A GLDv3 driver _init(9E) enTRy point is also required to call mac_init_ops() before calling mod_install(9F), and they are required to call mac_fini_ops() after calling mod_remove(9F) from _fini(9E). The following are important members of the mac_t structure:
Key MAC layer functions include the following:
typedef struct mac_info_s { uint_t mi_media; uint_t mi_sdu_min; uint_t mi_sdu_max; uint32_t mi_cksum; uint32_t mi_poll; uint_t mi_addr_length; uint8_t mi_unicst_addr[MAXADDRLEN]; uint8_t mi_brdcst_addr[MAXADDRLEN]; boolean_t mi_stat[MAC_NSTAT]; } mac_info_t; See usr/src/uts/common/sys/mac.h Where:
The macros MAC_MIB_SET(), MAC_ETHER_SET(), and MAC_MII_SET() set all the values in each of the three groups respectively to B_TRUE. 18.8.2.2. MAC Services ModuleThe driver support functions of the interfaces described in this section are intended to be used by GLDv3 driver developers. typedef void (*mac_blank_t)(void *, time_t, uint_t); typedef mblk_t *(*mac_poll_t)(void *, unit_t); typedef enum { MAC_RX_FIFO = 1 } mac_resource_type_t; typedef struct mac_rx_fifo_s { mac_resource_type_t mrf_type; /* MAC_RX_FIFO */ mac_blank_t mrf_blank; void *mrf_arg; time_t mrf_normal_blank_time; uint_t mrf_normal_pkt_count; } mac_rx_fifo_t; typedef struct mac_txinfo_s { mac_tx_t mt_fn; void *mt_arg; } mac_txinfo_t; typedef union mac_resource_u { mac_resource_type_t mr_type; mac_rx_fifo_t mr_fifo; } mac_resource_t; typedef mac_resource_handle_t (*mac_resource_add_t)(void *, mac_resource_t *); usr/src/uts/common/sys/mac.h The mac_resource_add() function should be called from the m_resources() enTRy point to register individual receive resources (commonly, ring buffers of DMA descriptors) with the MAC module. The returned mac_resource_handle_t value should then be supplied in calls to mac_rx(). The second argument to mac_resource_add() specifies the resource being added. Resources are specified by the mac_resource_t structure. Currently, only resources of type MAC_RX_FIFO are supported. MAC_RX_FIFO resources are described by the mac_rx_fifo_t structure. The upper layers use the mac_blank() function to control the interrupt rate of the device. The first argument is the device context that is to be used as the first argument to the poll_blank() function. The fields mrf_normal_blank_time and mrf_normal_pkt_cnt specify the default interrupt interval and packet count threshold, respectively. These parameters can be the second and third arguments to mac_blank() when the upper layer wants the driver to revert to the default interrupt rate. The interrupt rate is controlled by the upper layer by a call to poll_blank() with different arguments. The interrupt rate can be increased or decreased: the upper layer passes a multiple of these values to the last two arguments of mac_blank(). Setting these values to zero disables the interrupts, and the NIC is deemed to be in polling mode. mac_poll() is the driver-supplied function used by upper layers to retrieve a chain of packets (up to max count, specified by the second argument) from the RX ring corresponding to the earlier supplied mrf_arg during mac_resource_add() (supplied as first argument to mac_poll()). The function mac_resource_update() is invoked by the driver when available resources have changed. The function mac_rx() function delivers a chain of packets, contained in mblk_t structures, for reception. The b_cont field links fragments of the same packet. The b_next field of the leading fragment links separate packets. If the packet chain was received by a registered resource, then the appropriate mac_resource_handle_t value should be supplied as the second argument to the function. The protocol stack uses this value as a hint when trying to load-spread across multiple CPUs. It is assumed that packets belonging to the same flow are always received by the same resource. If the resource is unknown or is unregistered, then NULL should be passed as the second argument. 18.8.2.3. Data-Link Services ModuleThe Data-Link Services (DLS) module provides the Data-Link Services interface analogous to DLPI. The DLS interface is a kernel-level functional interface, as opposed to the STREAMS message-based interface specified by DLPI. This module provides the interfaces necessary for the upper layer to create and destroy a data link service. It also provides the interfaces necessary to plumb and unplumb the NIC. The plumbing and unplumbing of an NIC for GLDv3-based device drivers is unchanged from the older GLDv2 or monolithic DLPI device drivers. The major changes are in data paths that allow direct calls, packet chains, and much finer-grained control over an NIC. 18.8.2.4. Data-Link DriverThe Data-Link Driver (DLD) provides a DLPI by using interfaces from the DLS and MAC modules. The driver is configured by ioctls passed to a control node. These ioctls create and destroy separate DLPI provider nodes. This module deals with DLPI messages necessary to plumb and unplumb the NIC and affords backward compatibility for the data path through STREAMS for non-GLDv3-aware clients. 18.8.3. GLDv3 Link Aggregation ArchitectureThe GLDv3 framework supports link aggregation as defined by IEEE 802.3ad. The key principles governing the design of this facility are these:
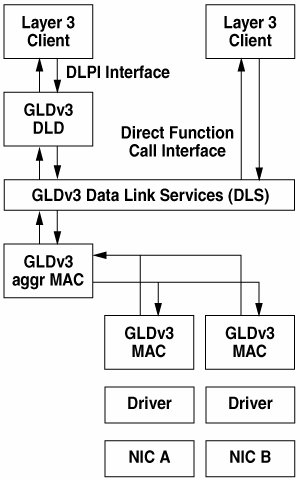
GLDv3 link aggregation is implemented by means of a pseudo-driver called aggr. It registers virtual ports corresponding to link aggregation groups with the GLDv3 MAC layer. It uses the client interface provided by the MAC layer to control and communicate with aggregated MAC ports as illustrated in Figure 18.7. It also exports a pseudo aggr device driver that the dladm(1M) command uses to configure and control the link-aggregated interface. Once a MAC port is configured to be part of a link aggregation group, it cannot be simultaneously accessed by other MAC clients such as the DLS layer. The exclusive access is enforced by the MAC layer. The implementation of LACP is implemented by the aggr driver, which has access to individual MAC ports or links. Figure 18.7. GLDv3 Link Aggregation Architecture The GLDv3 aggr driver acts as a normal MAC module to the upper layer and appears as a standard NIC interface which, once created with dladm(1M), can be configured and managed by the ifconfig(1M) command. The aggr module registers each MAC port that is part of the aggregation with the upper layer by using the mac_resource_add() function, such that the data paths and interrupts from each MAC port can be independently managed by the upper layers (see Section 18.9.2). In short, the aggregated interface is managed as a single interface with possibly one IP address, and the data paths are managed as individual NICs by unique CPUs and squeues. This management scheme gives aggregation capability to Solaris 10 with near zero overhead and linear scalability with respect to the number of MAC ports that are part of the aggregation group. 18.8.4. Checksum OffloadSolaris 10 improved the hardware checksum offload capability further to improve overall performance for most applications. A 16-bit, one's complement, checksum offload framework has existed in Solaris for some time. It was originally added as a requirement for Zero Copy TCP/IP in the Solaris 2.6 release but was only recently extended to handle other protocols. Solaris 10 defines two classes of checksum offload:
Adding support for nonfragmented IPV4 cases (unicast or multicast) is trivial for both transmit and receive since most modern network adapters support either class of checksum offload with minor differences in the interface. The IPV6 cases are not as straightforward, because very few full-checksum network adapters can handle checksum calculation for TCP/UDP packets over IPV64. The fragmented IP cases have similar constraints. On transmit, checksumming applies to the unfragmented datagram. An adapter that is to support checksum offload must be able to buffer all the IP fragments (or perform the fragmentation in hardware) before finally calculating the checksum and sending the fragments over the wire; until then, checksum offloading for outbound IP fragments cannot be done. On the other hand, the receive fragment reassembly case is more flexible since most full-checksum (and all partial-checksum) network adapters can compute and provide the checksum value to the network stack. During the fragment reassembly stage, the network stack can derive the checksum status of the unfragmented datagram by combining all the values. Things are simplified by not offloading the checksum when the IP option is present. For partial-checksum offload, certain adapters limit the start offset to a width sufficient for simple IP packets. When the length of protocol headers exceeds such a limit (because certain options are present), the start offset wraps around, causing an incorrect calculation. For full-checksum offload, none of the capable adapters correctly handle the IPV4 source routing option. When transmit checksum offload takes place, the network stack associates eligible packets with ancillary information needed by the driver to offload the checksum computation to hardware. In the inbound case, the driver has full control over the packets that become associated with hardware-calculated checksum values. Once a driver advertises its capability through DL CAPAB HCKSUM, the network stack accepts full- or partial-checksum information for IPV4 and IPV6 packets. This process happens for both nonfragmented and fragmented payloads. Fragmented packets first need to be reassembled because checksum validation happens for fully reassembled datagrams. During reassembly, the network stack combines the hardware-calculated checksum value of each fragment. |
EAN: 2147483647
Pages: 244