18.4. TCP as an Implementation of the New Framework Solaris 10 provides the same view for TCP as in previous releases; that is, TCP appears as a clone device but is actually a composite, with the TCP and IP code merged into a single D_MP STREAMS module. The merged TCP/IP module's STREAMS entry points for open and close are the same as IP's entry points: ip_open() and ip_close(). Based on the major number passed during an open, IP decides whether the open corresponds to a TCP open or an IP open. The put and service STREAMS entry points for TCP are tcp_wput(), tcp_wsrv(), and tcp_rsrv(). The tcp_wput() entry point simply serves as a wrapper routine and enables sockfs and other modules from the top to talk to TCP by using STREAMS. Note that tcp_rput() is missing, because IP calls TCP functions directly. IP STREAMS entry points remain unchanged from earlier Solaris releases. The operational part of TCP is fully protected by the vertical perimeter, which entered through the squeue primitives, as illustrated in Figure 18.4. Figure 18.4. TCP Flow 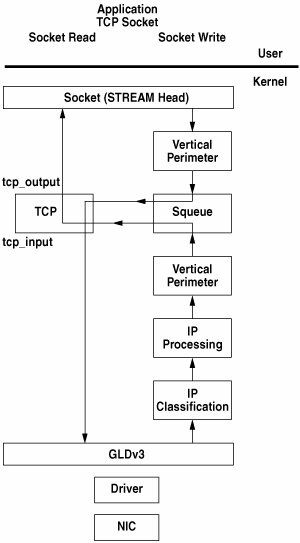
Packets flowing from the top enter TCP through the wrapper function tcp_wput(), which then tries to execute the real TCP output processing function tcp_output() after entering the corresponding vertical perimeter. Similarly, packets coming from the bottom try to execute the real TCP input processing function tcp_input() after entering the vertical perimeter. There are multiple entry points into TCP through the vertical perimeter: tcp_input(). All inbound data packets and control messages tcp_output(). All outbound data packets and control messages tcp_close_output(). On user close tcp_timewait_output(). timewait expiry tcp_rsrv_input(). Flow control relief on read side tcp_timer(). All tcp timers
18.4.1. The Interface between TCP and IP FireEngine changes the interface between TCP and IP from the existing STREAMS-based message passing interface to an interface based on a function calls, both in the control and data paths. On the outbound side, TCP passes a fully prepared packet directly to IP by calling ip_output() while inside the vertical perimeter. Similarly, control messages are also passed directly as function arguments. ip_bind_v{4, 6}() receives a bind message as an argument, performs the required action, and returns a result message pointer to the caller. TCP directly calls ip_bind_v{4, 6}() in the connect(), bind(), and listen() paths. IP still retains all its STREAMS entry points, but TCP (/dev/tcp) becomes a real device driver, that is, it cannot be pushed over other device drivers. The basic protocol processing code is unchanged. Let's look at common socket calls and see how they interact with the framework. socket(). A socket open of TCP (or /dev/tcp) eventually calls into ip_open(). The open then calls into the IP connection classifier and allocates the per-TCP endpoint control block already integrated with the conn_t structure. It chooses the squeue for this connection. In the case of an internal open (that is, by sockfs for an acceptor stream), almost nothing is done, and we delay doing useful work until accept time. bind(). tcp_bind() eventually needs to talk to IP to determine whether the address passed in is valid. FireEngine TCP prepares this request as usual in the form of a TPI message. However, this messages is directly passed as a function argument to ip_bind_v{4, 6}(), which returns the result as another message. The use of messages as parameters is helpful in leveraging the existing code with minimal change. The port hash table used by TCP to validate binds still remains in TCP since the classifier has no use for it. connect(). The changes in tcp_connect() are similar to those in tcp_bind(). The full bind() request is prepared as a TPI message and passed as a function argument to ip_bind_v{4, 6}(). IP calls into the classifier and inserts the connection in the connected hash table. The conn_hash table in TCP is no longer used. listen(). This path is part of tcp_bind(). The tcp_bind() function prepares a local bind TPI message and passes it as a function argument to ip_bind_v{4, 6}(). IP calls the classifier and inserts the connection in the bind hash table. The listen hash table of TCP does not exist any more. accept(). The pre-Solaris 10 accept() implementation did the bulk of the connection setup processing in the listener context. The three-way handshake was completed in the listener's perimeter, and the connection indication was sent up the listener's stream. The messages necessary to perform the accept were sent down the listener stream, and the listener was single-threaded from the point of sending the T_CONN_RES message to TCP until sockfs received the acknowledgment. If the connection arrival rate was high, the ability of the pre-Solaris 10 stack to accept new connections deteriorated significantly. Furthermore, some additional TCP overhead contributed to slower accept rates: When sockfs opened an acceptor stream to TCP to accept a new connection, TCP was not aware that the data structures necessary for the new connection had already been allocated. So it allocated new structures and initialized them, but later, as part of the accept processing, these were freed. Another major problem with the pre-Solaris 10 design was that packets for a newly created connection arrived on the listener's perimeter. This requires a check for every incoming packet, and packets landing on the wrong perimeter had to be sent to their correct perimeter, causing additional delay. The FireEngine model establishes an eager connection (an incoming connection is called eager until accept() completes) in its own perimeter as soon as a SYN packet arrives, thus ensuring that packets always land on the correct connection. As a result, the TCP global queues are completely eliminated. The connection indication is still sent to the listener on the listener's stream, but the accept happens on the newly created acceptor stream. Thus, data structures need not be allocated for this stream, and the acknowledgment can be sent on the acceptor stream. As a result, sockfs need not become single-threaded at any time during the accept processing. The new model was carefully implemented because the new incoming connection (eager) exists only because there is a listener for it, and both eager and listener can disappear at any time during accept processing as a result of the eager receiving a reset or listener closing. The eager starts out by placing a reference on the listener so that the eager reference to the listener is always valid, even though the listener might close. When a connection indication needs to be sent after the three-way handshake is completed, the eager places a reference on itself so that it can close on receiving a reset, but any reference to it is still valid. The eager sends a pointer to itself as part of the connection indication message, which is sent through the listener's stream after checking that the listener has not closed. When the T_CONN_RES message comes down the newly created acceptor stream, we again enter the eager's perimeter and check that the eager has not closed because of receiving a reset before completing the accept processing. For applications based on TLI or XTI, the T_CONN_RES message is still handled on the listener's stream, and the acknowledgment is sent back on listener's stream, so there is no change in behavior. close(). Close processing in TCP now does not have to wait until the reference count drops to zero, since references to the closing queue and references to TCP are now decoupled. close() can return as soon as all references to the closing queue are gone. In most cases, the TCP data structures can continue to stay around as a detached TCP. The release of the last reference to the TCP frees the TCP data structure. A user-initiated close closes only the stream. The underlying TCP structures may continue to stay around. The TCP then goes through the FIN/ACK exchange with the peer after all user data is transferred and enters the TIME_WAIT state, where it stays around for a certain duration. This kind of TCP is called a detached TCP. These detached TCPs also need protection to prevent outbound and inbound processing from occurring at the same time on a given detached TCP. datapath. TCP does not need to call IP to transmit the outbound packet in the most common case if it can access the IRE. With a merged TCP/IP we have the advantage of being able to access the cached IRE for a connection, and TCP can execute putnext() on the data directly to the link layer driver on the basis of information in the IRE. This is exactly what FireEngine does.
18.4.2. TCP Loopback TCP Fusion is a nonprotocol data path for loopback TCP connections in Solaris 10. The fusion of two local TCP endpoints occurs when the connection is established. By default, all loopback TCP connections are fused. You can change this behavior by setting the systemwide tunable do_tcp_fusion to 0. For fusion to be successful, various conditions on both endpoints need to be met: They must share a common squeue. They must be TCP, and not raw sockets. They must not require protocol-level processing; that is, IPsec or IPQoS policy is not present for the connection.
If the fusion fails, we fall back to the regular TCP data path; if it succeeds, both endpoints use tcp_fuse_output() as the transmit path. tcp_fuse_output() queues application data directly onto the peer's receive queue; no protocol processing is involved. After queueing the data, the sender can either pushby calling putnext()the data up the receiver's read queue. Or the sender can simply return and let the receiver retrieve the queued data through the synchronous STREAMS entry point. The latter path is taken if synchronous STREAMS is enabled. It is automatically disabled if sockfs no longer resides directly on top of the TCP module because a module was inserted or removed. Locking in TCP Fusion is handled by the squeue and the mutex tcp_fuse_lock. One of the requirements for fusion to succeed is that both endpoints must be using the same squeue. This ensures that neither side can disappear while the other side is still sending data. By itself, the squeue is not sufficient for guaranteeing safe access when synchronous STREAMS is enabled. The reason is that tcp_fuse_rrw() doesn't enter the squeue, and its access to the tcp_rcv_list and other fusion-related fields needs to be synchronized with the sender. tcp_fuse_lock is used for this purpose. Rate limit for small writes flow control for TCP Fusion in synchronous stream mode is achieved by checking the size of receive buffer and the number of data blocks, both set to different limits. This is different from regular STREAMS flow control, wherein cumulative size check dominates data block count check. Each queuing triggers notifications sent to the receiving process; a buildup of data blocks indicates a slow receiver, and the sender should be blocked or informed at the earliest moment instead of further wasting system resources. In effect, this is equivalent to limiting the number of outstanding segments in flight. The minimum number of allowable queued data blocks defaults to 8 and is changeable with the systemwide tunable tcp_fusion_burst_min to either a higher value or to 0 (the latter disables the burst check). |