Section 16.2. Memory Placement Optimization Framework
16.2. Memory Placement Optimization FrameworkThree concepts enable the Solaris kernel to perform well on NUMA machines:
For an application to run well on a NUMA machine, it is beneficial for all the required resourcesCPU, cache, memory, and perhaps I/Oto be co-located. Co-location helps minimize memory latencies by keeping most or all of the memory accesses local and avoiding the higher remote memory latencies. To enable co-location, the MPO Solaris kernel is locality aware; that is, it knows which hardware resources reside on which nodes, so it can try to allocate the resources needed by the application closer together for optimal performance. Furthermore, the kernel provides an interface to allow an application to be more aware of machine topology or even to control, if the application developer so chooses, how its resources are allocated. While locality awareness is important, the resources on the machine may become overloaded with too many threads trying to use the resources in too few nodes. The kernel will try to balance this load across the whole machine in this case so that no one node is much more loaded than any other node. The MPO framework also takes into account any changes in the hardware configuration of the machine during runtime, to refresh the information that the kernel has to keep for locality awareness. To make optimal decisions on scheduling and resource allocation, the kernel is aware of the latency topology of the hardware. The kernel uses a simpler representation of the latency topology and may or may not mirror the physical topology exactly. 16.2.1. Latency ModelThe latency model consists of one or more locality groups (lgroups). See Figure 16.1. Conceptually, each locality group is made up of all the hardware resources in a machine that are "close" to a defined reference point, for some value of close. It usually consists of the following:
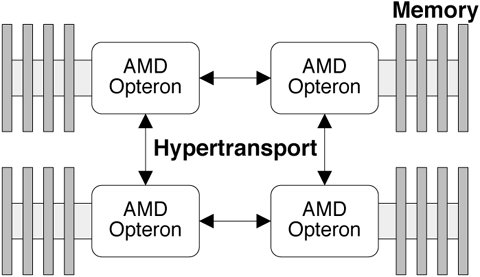
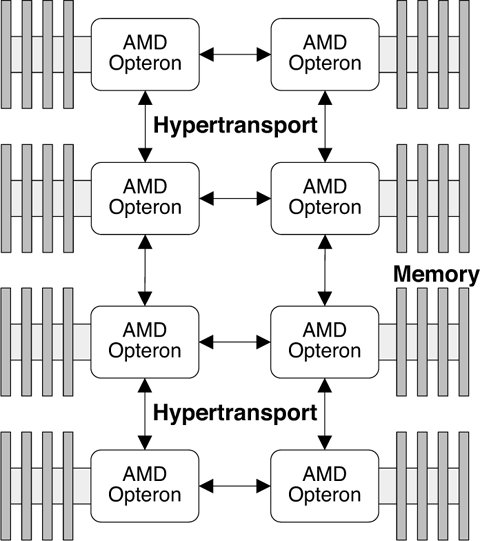
Figure 16.1. Lgroups and Hierarchies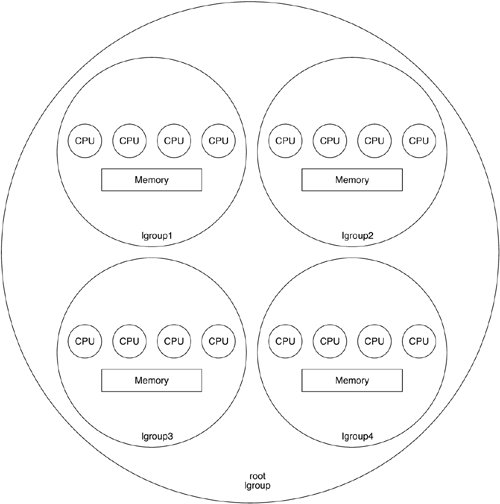 Using this model, we can represent the latency behavior of AMD Opteron, Starcat, and other NUMA machines. A simple example is that of a Starcat system: Each board contains set of processors that are close to the local memory on the board and less close to the memory on a remote board. In this case, a simple flat descriptions of lgroupsone per boardis sufficient. 16.2.2. More Complex ModelsIn the case of more complex systems, more than two levels of latency may be present, for example, as in a four-processor AMD Opteron system. The CPUs and memory are connected in a ring topology as shown in Figure 16.2. Figure 16.2. 4-Way Hypertransport Ring In this example, three levels of memory latency exist: local to the processor, one hop away, and two hops away. Eight processors are typically connected in a ladder configuration as shown in Figure 16.3. Figure 16.3. 8-Way Hypertransport Ladder The kernel creates and organizes lgroups into a hierarchy that can be quickly consulted and traversed to find the resources are closest, farther away, farther away still, etc. |
EAN: 2147483647
Pages: 244