ClientServer Architecture
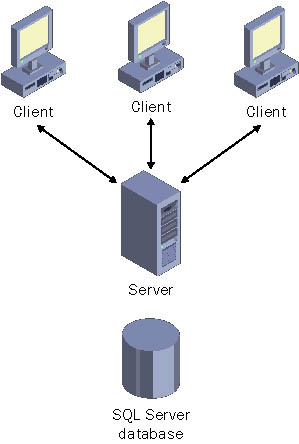
Client/Server ArchitectureEnterprise computing has evolved through several stages. It started with proprietary mainframes and monolithic applications. Later, it spread wildly to desktops and local area networks (LANs) with the client/server model, which suddenly allowed the lowly desktop computer to play a role in sophisticated business applications. The client/server model, for all its flaws, is probably the most successful single model of application design. It has persisted, unchanged, as the dominant application architecture until the past few years. A typical client/server application is hosted by a server on an internal network. It's usually an all-in-one package that relies on a back-end database. Multiple clients run the application from different computers, as shown in Figure 1-1. In this case, we'll also assume that the server plays two roles: hosting the database software and hosting the application files. This is a common choice for a small-scale setup, but it's certainly not the only possibility (and rarely the best design in distributed architecture). Figure 1-1. Basic client/server interaction This deployment model provides two basic benefits. First of all, it ensures that every client can access the same version of the application. (Ideally, no client deployment is needed at all, but a few thorny problems often thwart that vision all of which I cover a little later in this chapter.) Second, it centralizes all the back-end business information in one place: a server-side resource such as a database. The defining characteristic of this design is that although the application is shared with multiple clients, it's really the clients rather than the server that perform all the work. That's because the central computer is little more than a file server. The client reads the appropriate executable and DLL files from the server's hard drive and loads them into its process space. It then uses its CPU and memory to run the program. Inevitably, the server does perform some work. In this example, the server runs the relational database software, Microsoft SQL Server. When rows are retrieved or changes are applied to a table, SQL Server performs the low-level grunt work. To a certain extent, you can offload some additional responsibility to the server by adding stored procedures that encapsulate some of the business logic in the database. Even in a client-server application, you are free to use a multi-layered design. For example, you can create middle-tier components that handle data access tasks such as retrieving data or committing changes, saving your application from needing to connect directly to the database. This approach improves organization, simplifies your code, and makes it easier to change data access details without modifying the application logic (and vice versa). The application is still a client/server application, however, because all the code is still executed on the client side, as illustrated in Figure 1-2. Later chapters consider in more detail how you can divide an application into objects and tiers. For now, the important insight you should gain from all this is that adding more logical tiers to your application or placing your application files on different computers doesn't make your application distributed. As long as the client has the responsibility of executing all the code, the application is a client/server one. Figure 1-2. Client/server process usage Note Developers who are familiar with the concept of two-tier, three-tier, and multitier architecture might have noticed the absence of these terms in this chapter. These concepts help define the difference between client/server and distributed application modeling, but they don't designate where code is executed. (This difference between modeling and execution is also referred to as the difference between logical and physical partitioning.) In other words, using multitier design doesn't make a client/server application into a distributed application. Furthermore, solid multitier design practices are a good idea regardless of the type of application you're creating. Chapter 10 explores application architecture concepts in detail. Problems with Client/Server ArchitectureThe inevitable question is, What's wrong with client/server design? Clearly, it can't accommodate easy client interaction because each client runs a separate instance of the application. Similarly, it doesn't allow for thin clients (sometimes derisively known as "feeble clients") because each client runs the application inside its own process space. However, another more troubling problem exists. If this application needs to expand to serve not dozens but hundreds or thousands of simultaneous users, the server-side database quickly becomes a bottleneck. The overhead required to continuously release and create database connections for each client limits the performance and reduces the maximum number of clients that can be served simultaneously. This bottleneck has no easy solution in the client/server world. The Real Database BottleneckIt's often said that the problem with client/server development is that clients hold open connections to the database for their entire lifetime. This poor design restricts the maximum number of concurrent application users to the maximum number of connections that the database server (for example, SQL Server) can create at a time, introducing a significant bottleneck. However, this problem on its own doesn't tell the whole story about the limitations of client/server architecture. In fact, although this poor design is common in client/server code, it's just as easy to create in a distributed application. It all boils down to good coding practices. Whenever an application accesses a limited, shared resource such as a database connection, it should acquire it for the shortest amount of time possible. Ideally, an application should acquire the connection, perform a single update or query, and disconnect immediately. Sometimes it seems that the world is filled with poorly written client/server applications. However, a well-written client/server application that behaves nicely acquiring a database connection just long enough to perform a single database transaction will still suffer from a fundamental bottleneck that distributed applications can avoid. The real problem is that just creating a connection involves a certain amount of work. This task requires a number of low-level operations, including validating the authentication information supplied by the client. This basic overhead is unavoidable, and it means that a client/server application has difficulty supporting a massive number of clients (thousands of simultaneous connections, rather than hundreds) even if they have relatively modest needs. The server tends to become tied up with the overhead of creating and releasing connections long before it has reached its maximum throughput or taxed the processing power of its CPU. The database bottleneck problem exists with any server-side resource that's frequently used and expensive to create. It's this type of problem that effectively prevents almost all client/server programs from being able to expose their features to the wider audience of the Internet. Quite simply, they can't handle the load. Distributed applications, on the other hand, tackle this problem with the help of pooling, as discussed a little later in this chapter. Is Deployment a Client/Server Problem?In the client/server example discussed so far, the application is deployed on the server and the clients are more or less untouched. This approach is ideal because the application can be updated just by replacing the server-side files (although all the current clients must disconnect before you can take this step). Real life, however, is rarely as easy. First of all, clients might require various system components. For example, an application that incorporates advanced user interface controls (particularly if written in Microsoft Visual Basic) can require various system DLLs and ActiveX controls, which are often distributed as part of Microsoft Internet Explorer, Office, or the Windows operating system. Alternatively, the application might make use of custom COM components that have been developed in-house. Before the application can use these components, they must be installed and registered on each client computer. In this situation, a dedicated setup program is the only practical approach. Unfortunately, every time the component is modified, a new setup program is usually required and each client must run this setup before it can use the updated application. Clearly, the deployment picture has become much less pleasant. These complications have led many developers to add "deployment hell" to the list of client/server drawbacks. The only problem is that this situation isn't unique to client/server applications. It's actually a fundamental stumbling block with COM, and distributed applications are rarely better off. If distributed applications use COM components directly, these components must be installed and registered. In theory, life should be simplified in a distributed application because components can be registered on the computers where they're executed (not on every client), but traditional DCOM often requires additional, more painful setup and configuration steps. You've probably already heard about the .NET zero-touch deployment and support for side-by-side installation of different component versions. These features (dissected in the next chapter), along with the advanced support for version policies, remove the requirement for manual client-side setup. Don't be misled, however: this is a benefit for all .NET programmers, even those who create pure client/server programs. It has little to do with your choice of architecture. |

EAN: 2147483647
Pages: 174