9.3. Constructing Routines by Using the PPP
| < Free Open Study > |
| This section describes the activities involved in constructing a routine, namely these:
Design the RoutineOnce you've identified a class's routines, the first step in constructing any of the class's more complicated routines is to design it. Suppose that you want to write a routine to output an error message depending on an error code, and suppose that you call the routine ReportErrorMessage(). Here's an informal spec for ReportErrorMessage(): Cross-Reference For details on other aspects of design, see Chapters 5 through 8.
The rest of the chapter uses this routine as a running example. The rest of this section describes how to design the routine. Check the prerequisites Before doing any work on the routine itself, check to see that the job of the routine is well defined and fits cleanly into the overall design. Check to be sure that the routine is actually called for, at the very least indirectly, by the project's requirements. Cross-Reference For details on checking prerequisites, see Chapter 3, "Measure Twice, Cut Once: Upstream Prerequisites," and Chapter 4, "Key Construction Decisions." Define the problem the routine will solve State the problem the routine will solve in enough detail to allow creation of the routine. If the high-level design is sufficiently detailed, the job might already be done. The high-level design should at least indicate the following:
Here's how these concerns are addressed in the ReportErrorMessage() example:
Name the routine Naming the routine might seem trivial, but good routine names are one sign of a superior program and they're not easy to come up with. In general, a routine should have a clear, unambiguous name. If you have trouble creating a good name, that usually indicates that the purpose of the routine isn't clear. A vague, wishy-washy name is like a politician on the campaign trail. It sounds as if it's saying something, but when you take a hard look, you can't figure out what it means. If you can make the name clearer, do so. If the wishy-washy name results from a wishy-washy design, pay attention to the warning sign. Back up and improve the design. Cross-Reference For details on naming routines, see Section 7.3, "Good Routine Names." In the example, ReportErrorMessage() is unambiguous. It is a good name. Decide how to test the routine As you're writing the routine, think about how you can test it. This is useful for you when you do unit testing and for the tester who tests your routine independently. Further Reading For a different approach to construction that focuses on writing test cases first, see Test-Driven Development: By Example (Beck 2003). In the example, the input is simple, so you might plan to test ReportErrorMessage() with all valid error codes and a variety of invalid codes. Research functionality available in the standard libraries The single biggest way to improve both the quality of your code and your productivity is to reuse good code. If you find yourself grappling to design a routine that seems overly complicated, ask whether some or all of the routine's functionality might already be available in the library code of the language, platform, or tools you're using. Ask whether the code might be available in library code maintained by your company. Many algorithms have already been invented, tested, discussed in the trade literature, reviewed, and improved. Rather than spending your time inventing something when someone has already written a Ph.D. dissertation on it, take a few minutes to look through the code that's already been written and make sure you're not doing more work than necessary. Think about error handling Think about all the things that could possibly go wrong in the routine. Think about bad input values, invalid values returned from other routines, and so on. Routines can handle errors numerous ways, and you should choose consciously how to handle errors. If the program's architecture defines the program's error-handling strategy, you can simply plan to follow that strategy. In other cases, you have to decide what approach will work best for the specific routine. Think about efficiency Depending on your situation, you can address efficiency in one of two ways. In the first situation, in the vast majority of systems, efficiency isn't critical. In such a case, see that the routine's interface is well abstracted and its code is readable so that you can improve it later if you need to. If you have good encapsulation, you can replace a slow, resource-hogging, high-level language implementation with a better algorithm or a fast, lean, low-level language implementation, and you won't affect any other routines. In the second situation in the minority of systems performance is critical. The performance issue might be related to scarce database connections, limited memory, few available handles, ambitious timing constraints, or some other scarce resource. The architecture should indicate how many resources each routine (or class) is allowed to use and how fast it should perform its operations. Cross-Reference For details on efficiency, see Chapter 25, "Code-Tuning Strategies," and Chapter 26, "Code-Tuning Techniques." Design your routine so that it will meet its resource and speed goals. If either resources or speed seems more critical, design so that you trade resources for speed or vice versa. It's acceptable during initial construction of the routine to tune it enough to meet its resource and speed budgets. Aside from taking the approaches suggested for these two general situations, it's usually a waste of effort to work on efficiency at the level of individual routines. The big optimizations come from refining the high-level design, not the individual routines. You generally use micro-optimizations only when the high-level design turns out not to support the system's performance goals, and you won't know that until the whole program is done. Don't waste time scraping for incremental improvements until you know they're needed. Research the algorithms and data types If functionality isn't available in the available libraries, it might still be described in an algorithms book. Before you launch into writing complicated code from scratch, check an algorithms book to see what's already available. If you use a predefined algorithm, be sure to adapt it correctly to your programming language. Write the pseudocode You might not have much in writing after you finish the preceding steps. The main purpose of the steps is to establish a mental orientation that's useful when you actually write the routine. With the preliminary steps completed, you can begin to write the routine as high-level pseudocode. Go ahead and use your programming editor or your integrated environment to write the pseudocode the pseudocode will be used shortly as the basis for programming-language code. Cross-Reference This discussion assumes that good design techniques are used to create the pseudocode version of the routine. For details on design, see Chapter 5, "Design in Construction." Start with the general and work toward something more specific. The most general part of a routine is a header comment describing what the routine is supposed to do, so first write a concise statement of the purpose of the routine. Writing the statement will help you clarify your understanding of the routine. Trouble in writing the general comment is a warning that you need to understand the routine's role in the program better. In general, if it's hard to summarize the routine's role, you should probably assume that something is wrong. Here's an example of a concise header comment describing a routine: Example of a Header Comment for a RoutineThis routine outputs an error message based on an error code supplied by the calling routine. The way it outputs the message depends on the current processing state, which it retrieves on its own. It returns a value indicating success or failure. After you've written the general comment, fill in high-level pseudocode for the routine. Here's the pseudocode for this example: Example of Pseudocode for a RoutineThis routine outputs an error message based on an error code supplied by the calling routine. The way it outputs the message depends on the current processing state, which it retrieves on its own. It returns a value indicating success or failure. set the default status to "fail" look up the message based on the error code if the error code is valid if doing interactive processing, display the error message interactively and declare success if doing command line processing, log the error message to the command line and declare success if the error code isn't valid, notify the user that an internal error has been detected return status information Again, note that the pseudocode is written at a fairly high level. It certainly isn't written in a programming language. Instead, it expresses in precise English what the routine needs to do. Think about the data You can design the routine's data at several different points in the process. In this example, the data is simple and data manipulation isn't a prominent part of the routine. If data manipulation is a prominent part of the routine, it's worth-while to think about the major pieces of data before you think about the routine's logic. Definitions of key data types are useful to have when you design the logic of a routine. Cross-Reference For details on effective use of variables, see Chapters 10 through 13. Check the pseudocode Once you've written the pseudocode and designed the data, take a minute to review the pseudocode you've written. Back away from it, and think about how you would explain it to someone else. Cross-Reference For details on review techniques, see Chapter 21, "Collaborative Construction." Ask someone else to look at it or listen to you explain it. You might think that it's silly to have someone look at 11 lines of pseudocode, but you'll be surprised. Pseudocode can make your assumptions and high-level mistakes more obvious than programming-language code does. People are also more willing to review a few lines of pseudocode than they are to review 35 lines of C++ or Java. Make sure you have an easy and comfortable understanding of what the routine does and how it does it. If you don't understand it conceptually, at the pseudocode level, what chance do you have of understanding it at the programming-language level? And if you don't understand it, who else will? Try a few ideas in pseudocode, and keep the best (iterate) Try as many ideas as you can in pseudocode before you start coding. Once you start coding, you get emotionally involved with your code and it becomes harder to throw away a bad design and start over. Cross-Reference For more on iteration, see Section 34.8, "Iterate, Repeatedly, Again and Again." The general idea is to iterate the routine in pseudocode until the pseudocode statements become simple enough that you can fill in code below each statement and leave the original pseudocode as documentation. Some of the pseudocode from your first attempt might be high-level enough that you need to decompose it further. Be sure you do decompose it further. If you're not sure how to code something, keep working with the pseudocode until you are sure. Keep refining and decomposing the pseudocode until it seems like a waste of time to write it instead of the actual code. Code the RoutineOnce you've designed the routine, construct it. You can perform construction steps in a nearly standard order, but feel free to vary them as you need to. Figure 9-3 shows the steps in constructing a routine. Figure 9-3. You'll perform all of these steps as you design a routine but not necessarily in any particular order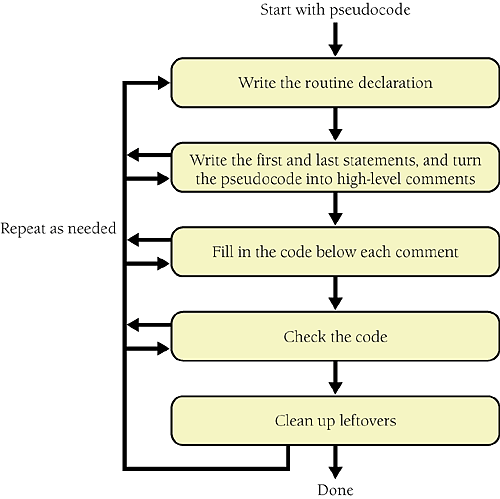 Write the routine declaration Write the routine interface statement the function declaration in C++, method declaration in Java, function or sub procedure declaration in Microsoft Visual Basic, or whatever your language calls for. Turn the original header comment into a programming-language comment. Leave it in position above the pseudocode you've already written. Here are the example routine's interface statement and header in C++: C++ Example of a Routine Interface and Header Added to Pseudocode/* This routine outputs an error message based on an error code <-- 1 supplied by the calling routine. The way it outputs the message | depends on the current processing state, which it retrieves | on its own. It returns a value indicating success or failure. | */ <-- 1 Status ReportErrorMessage( <-- 2 ErrorCode errorToReport ) set the default status to "fail" look up the message based on the error code if the error code is valid if doing interactive processing, display the error message interactively and declare success if doing command line processing, log the error message to the command line and declare success if the error code isn't valid, notify the user that an internal error has been detected return status information
This is a good time to make notes about any interface assumptions. In this case, the interface variable error is straightforward and typed for its specific purpose, so it doesn't need to be documented. Turn the pseudocode into high-level comments Keep the ball rolling by writing the first and last statements: { and } in C++. Then turn the pseudocode into comments. Here's how it would look in the example: C++ Example of Writing the First and Last Statements Around Pseudocode/* This routine outputs an error message based on an error code supplied by the calling routine. The way it outputs the message depends on the current processing state, which it retrieves on its own. It returns a value indicating success or failure. */ Status ReportErrorMessage( ErrorCode errorToReport ) { // set the default status to "fail" <-- 1 // look up the message based on the error code // if the error code is valid // if doing interactive processing, display the error message // interactively and declare success // if doing command line processing, log the error message to the // command line and declare success // if the error code isn't valid, notify the user that an // internal error has been detected // return status information }
At this point, the character of the routine is evident. The design work is complete, and you can sense how the routine works even without seeing any code. You should feel that converting the pseudocode to programming-language code will be mechanical, natural, and easy. If you don't, continue designing in pseudocode until the design feels solid. Fill in the code below each comment Fill in the code below each line of pseudocode comment. The process is a lot like writing a term paper. First you write an outline, and then you write a paragraph for each point in the outline. Each pseudocode comment describes a block or paragraph of code. Like the lengths of literary paragraphs, the lengths of code paragraphs vary according to the thought being expressed, and the quality of the paragraphs depends on the vividness and focus of the thoughts in them. Cross-Reference This is a case where the writing metaphor works well in the small. For criticism of applying the writing metaphor in the large, see "Software Penmanship: Writing Code" in Section 2.3. In this example, the first two pseudocode comments give rise to two lines of code: C++ Example of Expressing Pseudocode Comments as Code/* This routine outputs an error message based on an error code supplied by the calling routine. The way it outputs the message depends on the current processing state, which it retrieves on its own. It returns a value indicating success or failure. */ Status ReportErrorMessage( ErrorCode errorToReport ) { // set the default status to "fail" Status errorMessageStatus = Status_Failure; <-- 1 // look up the message based on the error code Message errorMessage = LookupErrorMessage( errorToReport ); <-- 2 // if the error code is valid // if doing interactive processing, display the error message // interactively and declare success // if doing command line processing, log the error message to the // command line and declare success // if the error code isn't not valid, notify the user that an // internal error has been dtected // return status information
This is a start on the code. The variable errorMessage is used, so it needs to be declared. If you were commenting after the fact, two lines of comments for two lines of code would nearly always be overkill. In this approach, however, it's the semantic content of the comments that's important, not how many lines of code they comment. The comments are already there, and they explain the intent of the code, so leave them in. The code below each of the remaining comments needs to be filled in: C++ Example of a Complete Routine Created with the PseudocodeProgramming Process /* This routine outputs an error message based on an error code supplied by the calling routine. The way it outputs the message depends on the current processing state, which it retrieves on its own. It returns a value indicating success or failure. */ Status ReportErrorMessage( ErrorCode errorToReport ) { // set the default status to "fail" Status errorMessageStatus = Status_Failure; // look up the message based on the error code Message errorMessage = LookupErrorMessage( errorToReport ); // if the error code is valid if ( errorMessage.ValidCode() ) { <-- 1 // determine the processing method ProcessingMethod errorProcessingMethod = CurrentProcessingMethod(); // if doing interactive processing, display the error message // interactively and declare success if ( errorProcessingMethod == ProcessingMethod_Interactive ) { DisplayInteractiveMessage( errorMessage.Text() ); errorMessageStatus = Status_Success; } // if doing command line processing, log the error message to the // command line and declare success else if ( errorProcessingMethod == ProcessingMethod_CommandLine ) { <-- 2 CommandLine messageLog; | if ( messageLog.Status() == CommandLineStatus_Ok ) { | messageLog.AddToMessageQueue( errorMessage.Text() ); | messageLog.FlushMessageQueue(); | errorMessageStatus = Status_Success; | } <-- 2 else { <-- 3 // can't do anything because the routine is already error processing } <-- 3 else { <-- 4 // can't do anything because the routine is already error processing } <-- 4 } // if the error code isn't valid, notify the user that an // internal error has been detected else { DisplayInteractiveMessage( "Internal Error: Invalid error code in ReportErrorMessage()" ); } // return status information return errorMessageStatus; }
Each comment has given rise to one or more lines of code. Each block of code forms a complete thought based on the comment. The comments have been retained to provide a higher-level explanation of the code. All variables have been declared and defined close to the point they're first used. Each comment should normally expand to about 2 to 10 lines of code. (Because this example is just for purposes of illustration, the code expansion is on the low side of what you should usually experience in practice.) Now look again at the spec on page 000 and the initial pseudocode on page 000. The original five-sentence spec expanded to 15 lines of pseudocode (depending on how you count the lines), which in turn expanded into a page-long routine. Even though the spec was detailed, creation of the routine required substantial design work in pseudocode and code. That low-level design is one reason why "coding" is a nontrivial task and why the subject of this book is important. Check whether code should be further factored In some cases, you'll see an explosion of code below one of the initial lines of pseudocode. In this case, you should consider taking one of two courses of action:
Check the CodeAfter designing and implementing the routine, the third big step in constructing it is checking to be sure that what you've constructed is correct. Any errors you miss at this stage won't be found until later testing. They're more expensive to find and correct then, so you should find all that you can at this stage. A problem might not appear until the routine is fully coded for several reasons. An error in the pseudocode might become more apparent in the detailed implementation logic. A design that looks elegant in pseudocode might become clumsy in the implementation language. Working with the detailed implementation might disclose an error in the architecture, high-level design, or requirements. Finally, the code might have an old-fashioned, mongrel coding error nobody's perfect! For all these reasons, review the code before you move on. Cross-Reference For details on checking for errors in architecture and requirements, see Chapter 3, "Measure Twice, Cut Once: Upstream Prerequisites." Mentally check the routine for errors The first formal check of a routine is mental. The cleanup and informal checking steps mentioned earlier are two kinds of mental checks. Another is executing each path mentally. Mentally executing a routine is difficult, and that difficulty is one reason to keep your routines small. Make sure that you check nominal paths and endpoints and all exception conditions. Do this both by yourself, which is called "desk checking," and with one or more peers, which is called a "peer review," a "walk-through," or an "inspection," depending on how you do it.
Bottom line: A working routine isn't enough. If you don't know why it works, study it, discuss it, and experiment with alternative designs until you do. Compile the routine You'll benefit in several ways, however, by not compiling until late in the process. The main reason is that when you compile new code, an internal stopwatch starts ticking. After the first compile, you step up the pressure: "I'll get it right with just one more compile." The "Just One More Compile" syndrome leads to hasty, error-prone changes that take more time in the long run. Avoid the rush to completion by not compiling until you've convinced yourself that the routine is right. The point of this book is to show how to rise above the cycle of hacking something together and running it to see if it works. Compiling before you're sure your program works is often a symptom of the hacker mindset. If you're not caught in the hacking-and-compiling cycle, compile when you feel it's appropriate. But be conscious of the tug most people feel toward "hacking, compiling, and fixing" their way to a working program. Here are some guidelines for getting the most out of compiling your routine:
Step through the code in the debugger Once the routine compiles, put it into the debugger and step through each line of code. Make sure each line executes as you expect it to. You can find many errors by following this simple practice. Test the code Test the code using the test cases you planned or created while you were developing the routine. You might have to develop scaffolding to support your test cases that is, code that's used to support routines while they're tested and that isn't included in the final product. Scaffolding can be a test-harness routine that calls your routine with test data, or it can be stubs called by your routine. Cross-Reference For details, see Chapter 22, "Developer Testing." Also see "Building Scaffolding to Test Individual Classes" in Section 22.5. Remove errors from the routine Once an error has been detected, it has to be removed. If the routine you're developing is buggy at this point, chances are good that it will stay buggy. If you find that a routine is unusually buggy, start over. Don't hack around it rewrite it. Hacks usually indicate incomplete understanding and guarantee errors both now and later. Creating an entirely new design for a buggy routine pays off. Few things are more satisfying than rewriting a problematic routine and never finding another error in it. Cross-Reference For details, see Chapter 23, "Debugging." Clean Up LeftoversWhen you've finished checking your code for problems, check it for the general characteristics described throughout this book. You can take several cleanup steps to make sure that the routine's quality is up to your standards:
Repeat Steps as NeededIf the quality of the routine is poor, back up to the pseudocode. High-quality programming is an iterative process, so don't hesitate to loop through the construction activities again. |
 After reviewing the routine, compile it. It might seem inefficient to wait this long to compile since the code was completed several pages ago. Admittedly, you might have saved some work by compiling the routine earlier and letting the computer check for undeclared variables, naming conflicts, and so on.
After reviewing the routine, compile it. It might seem inefficient to wait this long to compile since the code was completed several pages ago. Admittedly, you might have saved some work by compiling the routine earlier and letting the computer check for undeclared variables, naming conflicts, and so on.| < Free Open Study > |
EAN: 2147483647
Pages: 334