Tools and Approaches for Cataloging the Semantics
The preceding gives an idea of the detail and structure of the semantics to be captured. It should be apparent that even in the simplest business the volume of semantic information being gathered will quickly overwhelm any effort to keep track of it in a simple textual format. The sheer volume makes communicating the semantics difficult. This section discusses strategies and categories of products for storing and organizing this information, reviews products and approaches for communicating it graphically to others, and discusses formal methods for expressing the semantics.
These are the major tool-based strategies for dealing with this complexity:
-
Dictionaries
-
Database do-it-yourself options
-
Document management systems
-
Content management systems
-
Knowledge management systems
-
Metadata repositories
-
Ontology editors
Dictionaries
Typically, when people begin gathering information about terms and relationships, the first reaction is to want to put them in a dictionary. The first problem that comes up with dictionaries is the synonym and homonym problem: The dictionary works best if there is one and only one word for each concept. If these problems aren't solved, you will get multiple definitions of the same word or multiple meanings commingled.
The homonym problem is not that serious, because we aren't trying to interpret natural language. The synonym problem, however, is more subtle. We have no problem with exact synonyms, and this is how we would do foreign language versions of our dictionary and, by extension, our semantic model. However, as pointed out by John Saeed, there are few true synonyms.[63] Most things that we refer to as synonyms contain slight variations in meaning and are not in fact synonyms. A rule of thumb is to ask yourself whether it is likely that we would write code (or make the distinction in a model) that would cause us to treat the near synonyms differently. In the Swetsville example, if there were a real distinction between a statue and a statuette (say, statuettes are small enough to be shipped by parcel post), you should set it up as a different term; otherwise, just note it as a synonym (Figure 10.5).
If (item = statuette ) then routine1 Elseif (item = statue) then routine2
Figure 10.5: Behavioral difference indicating different type.
We need to avoid the urge to catalog every word we can think of related to the application; only those that will cause the system to do something behaviorally different are worth capturing.
How System Lexical Scope Affects Complexity
I believe the lexical scope (the number of distinctions an application makes) is the real reason that the same system implemented for a large company is more complex and costly to write than if it were implemented for a small company. As we discussed in Chapter 2, a small company will not make a capital investment in creating a procedure for a variation that for them will occur very infrequently.
What is needed is a way to track the lexical scope of each distinction made, and ultimately whether the distinction is ever referred to; if it is not, it could be eliminated. The tricky thing is that there may be distinctions that humans will use in making decisions that will not be used by the system, and it will therefore be difficult to find which ones are really being used.
The next step up from a simple dictionary is some form of storage that can capture some of the richer aspects of the metadata and its interrelationships.
Database Do-It-Yourself Options
It would be handy to store this information in a database, which would allow sorting and searching by various attributes. In most cases this will mean building your own system. This section is an outline of some of the considerations if you decide to go this route. Note that the database schema should be arrived at through the same reasoning process as that which is used for the schema of any other application created this way.
If you decide you're going to "roll your own," there are four basic patterns you might structure your metadata around. Figure 10.6 is the simplest starting point for a metadata repository: Everything is a node that might be related to another node. This is the structure of document object model (DOM[64]), which is one of many ways to process an extensible markup language (XML) document. It has the advantage of simplicity, but requires that any inference you make about the structure be in the code that accesses it.

Figure 10.6: Generic repository model.
Figure 10.7 is a highly simplified version of the repository for a relational model. Each entity can have many attributes and has many relationships, each of which is binary (attached to two entities). In practice you would embellish this with domains, constraints, and so on, but this is the basic structure. To build a database from this, entities become tables, attributes become columns, and the relationships must be implemented as foreign key and primary key pairs.
![]()
Figure 10.7: Repository model for ER model.
Figure 10.8 shows a repository model for an associative model of data.[65] The associative model promotes the association ("relationship" in entity relationship terminology or "fact" in rule-based terminology) to a first class object. I haven't actually built any repositories or systems off this model, but it is very much in line with the semantic modeling approaches.
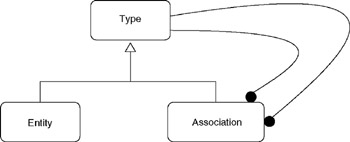
Figure 10.8: Repository model for associative model.
Figure 10.9 shows a repository oriented more toward the rule-based approach. You would expand the rule hierarchy, because each rule type has its own attributes to store, but this is the essential structure.
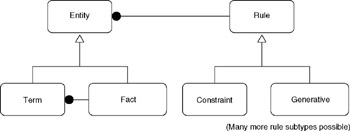
Figure 10.9: Repository model for rule metadata.
Any of these approaches will work. As you can see, the essential structures are simple and should not deter you if you do not have other tools at hand. By storing the metadata in a database, we have a reasonable way to cross-reference synonyms, and we can find out which terms are being used by which relationships or rules.
This is the route you might take if you needed to design your own system. Purchased metadata repositories have a similar schema.
Document Management Systems
Document management systems began life as a place to store and retrieve "documents." This initially meant images of documents that were scanned in and documents that were internally generated, in their native word processor formats. The main features of the system were to add indexing and work flow on top of the documents, which was useful for traditional "paper-centric" work flow procedures.
More recently, document management has been extended to include markup, which begins to put it in the realm of something that could be used to keep track of the semantic information gathered. From the document management systems I've reviewed, this would not make a particularly good repository, but if it were the tool at hand you could do something with it.
Content Management Systems
Content management became popular with the advent of the corporate web and the need to manage far more content than was easily tractable just by storing HTML pages in the file system. Content management systems have gone a bit further than document management systems in terms of structuring content and supporting more complex linkages between documents and fragments of documents. This is the type of solution that you would not buy for this purpose, but you might use it if you had it in house and were familiar with it.
Content management systems tend to focus on four areas:
-
Authoring—helping with the process of building content
-
Work flow—routing content around for approval and editing
-
Repository—organizing, cross-referencing, and storing the content
-
Publishing—reformatting and repurposing content to different viewing devices
We are primarily interested in the repository functions. Don't buy this just for a semantic repository, but if you have one and have completed the learning curve you should be able to put it to good use.
Knowledge Management Systems
Knowledge management has become an umbrella concept covering many different technologies. Most practitioners agree that the implementation is far more important than the tools. The knowledge management vendors make various distinctions between explicit knowledge (that which can be expressed as storable information, such as a recipe) and tacit knowledge (the often unexpressed skills or abilities we possess). Knowledge management systems typically focus on these areas:
-
Synthesis—tools to help create knowledge or information from existing data
-
Communication—tools that help with sharing and collaborating
-
Storage—storing, indexing, and searching the knowledge base
-
Gathering—tools to acquire data, including data mining and optical character recognition for getting data from scanned documents
-
Publishing—technology for disseminating the information
Again we're most interested in the storage features, for use as a repository.
Ontology Editors
Several products are available that make it easy to construct and maintain your evolving ontology. One of the more popular is Prot g , which is available free as a download. Figure 10.10 is the main window for Prot g and shows the buildup of an ontology.
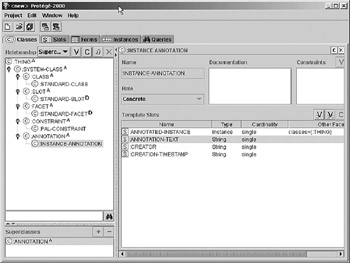
Figure 10.10: Prot g , an ontology editor.
Prot g is freely available from Stanford.[66] It is representative of a large family of ontology editors that includes Ontolingua,[67] Ontosaurus,[68] and OilEd.[69] Their main strengths are that they are applications specifically built for the purpose of building and reviewing complex ontologies, and as such have many of the features that would be needed. Most of them export the ontologies in standard formats such as rescource description framework (RDF) glossary (see Chapter 14) or the knowledge interface format used in many artificial intelligence tools.
The primary weakness is that ontology editors are not primarily graphic. Although they can export data that might be graphed, the primary input and display are not graphic (other than an outline view), which is a disadvantage for nondedicated modelers. In the next section we discuss graphically oriented approaches to semantic modeling and look at what is needed to communicate the vast amount of knowledge that will have been accumulated through this process, and how some of the current approaches stack up.
The main point with any of these repositories is to gather as much of the semantic information as you can and capture it in an electronic format that can be indexed and searched. Anything you do to increase the likelihood of reusing this information will be useful; the tool itself is secondary. In the next section we take up the issue of building and reviewing semantic models graphically, which may be done based on extracts from these repositories, or these tools may be used instead of the repository.
[63]John I. Saeed, Semantics. Oxford: Blackwell Publishers, 1997, p 65.
[64]See http://www.w3.org/DOM/ for further information.
[65]Simon Williams, The Associative Model of Data. Great Britain: Lazy Software Ltd., 2000, p 215.
[66]See http://protege.stanford.edu for further information.
[67]See http://www.ksl.stanford.edu/software/ontolingua/ for further information.
[68]See http://sevak.isi.edu:8900/ploom/shuttle.html for further information.
[69]See http://oiled.man.ac.uk/ for further information.
EAN: 2147483647
Pages: 184