Some Current Approaches to Document Interpretation
In this section we discuss some of the approaches that are being brought to bear on the problem of interpreting unstructured information.
How Google Interprets Relevance
Google doesn't attempt to interpret the meaning of the content on the sites it indexes. It focuses on keywords and relevance. The keywords are harvested mechanically. The relevance algorithm makes use of a number of "clues" to determine the likelihood that a given page will be of interest to a searcher. Some of the main clues include its listing in DMOZ[30] (the Open Directory Project, which is a human-based indexing) and the number of other sites that refer to a given site or page.
Although this includes very little interpretation, Google has become the most popular search engine based on the breadth of its offering (over three billion pages as of the end of 2002), the speed of access (Google has local copies, called "caches," of all the pages on their own servers), and ability to rank pages in a way that most users find approximates their intentions quite well.
Microsoft Smart Tags
Microsoft has recently introduced what they call "Smart Tags" in two different products. The Microsoft Office Suite has implemented Smart Tags to automatically interpret a few words or phrases in a document. The XP Operating System also contains a Smart Tag feature that potentially allows in-route annotating of Web pages. We'll briefly consider each, from the standpoint of its bearing on semantic interpretation.
Office Smart Tags
Microsoft has created eight Smart Tags in Microsoft Office. These are the items that it would be possible to parse out of context and get right at least enough of the time to make it worthwhile. The tags are shown in the Smart Tags dialog in Figure 7.6.
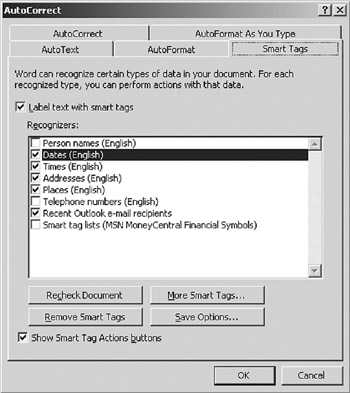
Figure 7.6: Smart Tags in Microsoft Office.
Smart Tags use syntax as a clue to interpret meaning. As we will describe in the next few paragraphs, this won't get you very far.
In each of these cases, if Microsoft Word (or Excel, etc.) detects you typing something like 12/21/01, it will assume that you have typed a date and tag it as such. Once tagged as a date, the application (Microsoft Office) assumes that it is a date and allows you to pop up a menu that would allow you to do something with the date. (In the case of date there are only two available options, but this is a programmable feature.)
The syntactic interpretation is easily fooled. Information concerning invoice terms structured as 2/10/30 (2% discount if paid in 10 days, balance due in 30 days) is interpreted as February 10, 1930. This style of punctuation is not used often, and the downside is minimal, but we need to be careful and not be lulled into believing that this is semantically verified information.
The rest of the tags are similar, are easy to parse, and charge little penalty for misinterpretation. Even at this level, though, there are a number of false positives (you typed in something other than a date that the application thought was a date) and false negatives (you typed in a date and the system did not recognize it). Here is a quick rundown on a few of the tags:
-
Person names—This Smart Tag relies on capitalization and only finds full names. As a result, typing in only someone's first name or last name does not register. False positives are generated for company names that sound like personal names, and so on. Actions available include sending email, and adding to a contact list.
-
Dates—As described earlier, any set of numbers with slashes is interpreted as a date. Jan 1 is a false negative, but Jan 1 2000 comes up right. There are also a few false positives on boundary cases (e.g., 2/30/2000). Alternate delimiters do not work (12.21.2000), but English style does (31/3/2001).
-
E-mail—Anything that looks like an email address gets a hyperlink to send an email, but it is only a Smart Tag if you have corresponded via Outlook.
-
Stock tickers—Curiously, the Smart Tag interpreter seems to know the difference between valid and nonvalid stock symbols. PPG (originally Pittsburgh Plate Glass) gets a Smart Tag, but PPD does not. There does not seem to be a syntactic clue in this case, which suggests that there is a database behind the scenes. However, there are many false negatives for the one-letter stocks (T for AT&T) and for lowercasing the names. The allowed options all send you to http://www.msn.com.
When Microsoft Office XP finds one of these tags in a document during typing, it puts an XML tag around it. This tagging is its connection to the right-click mouse behaviors.
I bring this up for a couple of reasons. The primary reason is that this is the starting point for some low-grade semantic interpretation of nonstructured documents. The Smart Tag interpreter is attempting to find a few semantic crumbs in documents that are otherwise opaque. Although this adds some information to a document, we need to be aware that very little semantic interpretation is going on.
[30]See http://dmoz.org/ for further information.
EAN: 2147483647
Pages: 184