1.8 Service Characteristics
1.8 Service Characteristics
One of the goals of network analysis is to be able to characterize services so that they can be designed into the network and purchased from vendors and service providers (e.g., via requests for information [RFI], quote [RFQ], or proposal [RFP], documents used in the procurement process). In addition to today's best-effort delivery, we will also examine new types of services (predictable and guaranteed), as well as single/multipletier performance.
Service characteristics are individual network performance and functional parameters that are used to describe services. These services are offered by the network to the system (the service offering) or are requested from the network by users, applications, or devices (the service request). Characteristics of services that are requested from the network can also be considered requirements for that network.
Examples of service characteristics range from estimates of capacity requirements based on anecdotal or qualitative information about the network to elaborate listings of various capacity, delay, and RMA requirements, per user, application, and/or device, along with requirements for security, manageability, usability, flexibility, and others.
Example 1.3
Examples of service characteristics are:
-
Defining a security or privacy level for a group of users or an organization
-
Providing 1.5 Mb/s peak capacity to a remote user
-
Guaranteeing a maximum round-trip delay of 100 ms to servers in a server farm
Such requirements are useful in determining the need of the system for services, in providing input to the network architecture and design, and in configuring services in network devices (e.g., routers, switches, device operating systems). Measurements of these characteristics in the network to monitor, verify, and manage services are called service metrics. In this book we focus on developing service requirements for the network and using those characteristics to configure, monitor, and verify services within the network.
For services to be useful and effective, they must be described and provisioned end-to-end at all network components between well-defined demarcation points. Note that this means that end-to-end is not necessarily from one user's device to another user's device. It may be defined between networks, from users to servers, or between specialized devices (Figure 1.19). When services are not provisioned end-to-end, some components may not be capable of supporting them, and thus the services will fail. The demarcation points determine where end-to-end is in the network. Determining these demarcation points is an important part of describing a service.
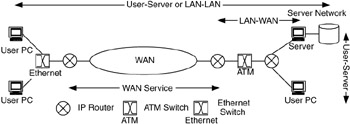
Figure 1.19: Various demarcation points for end-to-end in a network.
Services also need to be configurable, measurable, and verifiable within the system. This is necessary to ensure that end users, applications, and devices are getting the services they have requested (and possibly paying for), and this leads to accounting and billing for system, including network, resources. You will see how service metrics can be used to measure and verify services and their characteristics.
Services are also likely to be hierarchical within the system, with different service types and mechanisms applied at each layer in the hierarchy. For example, Figure 1.20 shows a service hierarchy that focuses on bulk traffic transport in the core of the network while placing specific services at the access network close to the end users, applications, and devices.
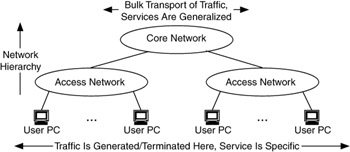
Figure 1.20: Example of service hierarchy within a network.
1.8.1 Service Levels
Service characteristics can be grouped together to form one or more service levels for the network. This is done to make service provisioning easier in that you can configure, manage, account, and bill for a group of service characteristics (service level) instead of a number of individual characteristics. For example, a service level (e.g., premium) may combine capacity (e.g., 1.5 Mb/s) and reliability (as 99.5% uptime). Service levels are also helpful in billing and accounting. This is a service-provider view of the network, where services are offered to customers (users) for a fee. This view of networking is becoming more popular in enterprise networks, displacing the view of networks as purely infrastructure of cost centers.
There are many ways to describe service levels, including frame relay committed information rates (CIRs), which are levels of capacity; ATM classes of service (CoSs), which combine delay and capacity characteristics; and IP types of service (ToSs) and qualities of service (QoSs), which prioritize traffic for traffic conditioning functions, which are described in the performance architecture (see Chapter 8). There can also be combinations of the aforementioned mechanisms, as well as custom service levels, based on groups of individual service characteristics. These combinations depend on which network technology, protocol, mechanism, or combination is providing the service.
In Figure 1.21 service offerings, requests, and metrics are shown applied to the system. In this example, demarcation of services is shown between the device and network components. Depending on the service requirement or characteristic, however, demarcation may also be between the device and application components (as in Figure 1.17).
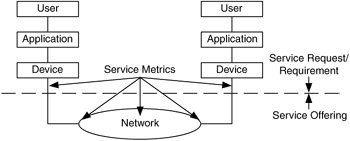
Figure 1.21: Service requests, offerings, and metrics.
Example 1.4
A request from the customer was that each building should have Fast Ethernet (FE) capacity to the rest of the network. As part of the requirements analysis, this request became a requirement for 100 Mb/s peak capacity from the users in each building. This service request was then matched in the requirements and design processes by a technology choice that meets or exceeds the request; in this case, FE was chosen as the technology, and the service offering is 100 Mb/s to each building. Service metrics were then added, consisting of measuring the FE connections from the IP switch or router at each building to the backbone.
Services and service levels can be distinguished by their degrees of predictability or determinism. In the next section we will discuss best-effort delivery, which is not predictable or deterministic, as well as predictable and guaranteed services.
Services and service levels are also distinguished by their degrees of performance. You will see how the service performance characteristics capacity, delay, and RMA are used to describe services and service levels.
1.8.2 System Components and Network Services
Network services are derived from requirements at each of the components in the system. They are end-to-end (between end points that you define) within the system, describing what is expected at each component. Service requirements for the network we are building are derived from each component: There can be user requirements, application requirements, device requirements, and (existing) network requirements. Since the network component is what we are building, any requirements from the network component come from existing networks that the new network will incorporate or connect to.
Component requirements add to each other, refining and expanding requirements as we move closer to the network. User requirements, which are the most subjective and general, are refined and expanded by requirements from the application component, which are then refined and expanded by the device and network components. Thus, requirements filter down from user to application to device to network, resulting in a set of specific requirements that can be configured and managed in the network devices themselves. This results in a service offering that is end-to-end, consisting of service characteristics that are configured in each network device in the path (e.g., routers, switches, hubs). As in Figure 1.22, service characteristics are configured and managed within each element and at interfaces between elements. These services are the most specific of all and have the smallest scope (typically a single network device).
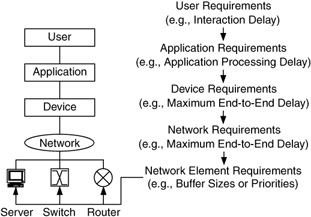
Figure 1.22: Requirements flow down components to network.
Defining network services and service metrics helps keep the system functioning and can provide extra value or convenience to users and their applications. By defining service metrics, we are determining what we will be measuring in the network, which will help us in network monitoring and management.
Recall that network services are sets of performance and function, so requirements may also include functions of one of the components. Examples of functions include network monitoring and management, security, and accounting. Services such as these need to be considered an integral part of the network architecture and design. In this book, security (and privacy) and network management each have their own architectures. This may seem obvious, but traditionally, services such as security and network management have been afterthoughts in architecture and design, often completely forgotten in the architecture, until problems arise.
Example 1.5
The network path shown in Figure 1.23 was designed to optimize performance between users and their servers. The graph at the bottom of the figure is an estimate of the expected aggregate capacity at each segment of the path. In this network, a packet over SONET (POS) link at the OC-48 level (2.544 Gb/s) connects two routers, which then connect to Gigabit Ethernet (GigE) switches.
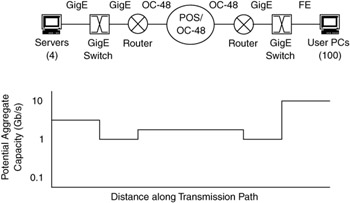
Figure 1.23: Capacity at each point in transmission path before security firewall.
After it was implemented, a security firewall was added at the users' LAN (with FE interfaces), without it being considered part of the original analysis, architecture, or design. The result was that the firewall changed the capacity characteristics across the path by reducing throughput between the user PCs and the GigE switch, as shown in Figure 1.24.
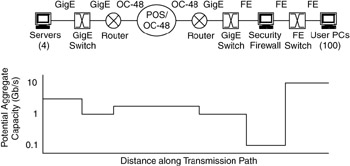
Figure 1.24: Capacity at each point in transmission path after security firewall.
One of our architectural and design goals is to identify such performance bottlenecks before the network is implemented. By considering security, network management, services, and routing and addressing in the analysis process, we are much more likely to understand their behavior and effect on each other and the network. We will therefore be able to architect the network to accommodate their requirements and interoperability.
When service characteristics apply to individual network devices, such as routers, switches, data service units (DSUs), and so on, some of these characteristics may be vendor specific. In this book we will focus on those characteristics that are part of public standards and not vendor specific.
It is important to note that although standards-based characteristics are "standardized" on the basis of having their descriptions either publicly available (e.g., via an IETF RFC), sanctioned by an organization recognized by the networking community, or generally accepted and used as a de facto standard, the implementation of characteristics is open to interpretation and often varies across vendors and vendor platforms.
1.8.3 Service Requests and Requirements
Service requests and requirements are, in part, distinguished by the degree of predictability needed from the service by the user, application, or device making the request. Based on predictability, service requests are categorized as best effort, predictable, and guaranteed. Service requests and requirements can also be for single or multiple-tier performance for a network.
Best-effort service means that there is no control over how the network will satisfy the service request—that there are no guarantees associated with this service. Such requests indicate that the rest of the system (users, applications, and devices) will need to adapt to the state of the network at any given time. Thus, the expected service for such requests will be both unpredictable and unreliable, with variable performance across a range of values (from the network being unavailable to the lowest common denominator of performance across all of the technologies in the end-to-end path). Such service requests either have no specific performance requirements for the network or requirements that are based solely on estimates of capacity. When requirements are nonspecific, network performance cannot be tuned to satisfy any particular user, application, or device requirement.
Guaranteed service is the opposite of best-effort service. Where best-effort service is unpredictable and unreliable, guaranteed service must be predictable and reliable to such a degree that, when service is not available, the system is held accountable. A guaranteed service implies a contract between the user and provider. For periods when the contract is broken (e.g., when the service is not available), the provider must account for the loss of service and, possibly, appropriately compensate the user.
With best-effort and guaranteed services at opposite ends of the service spectrum, many services fall somewhere between. These are predictable services, which require some degree of predictability (more than best effort), yet do not require the accountability of a guaranteed service.
Predictable and guaranteed service requests are based on some a priori knowledge of and control over the state of the system. Such requests may require that the service operates either predictably or is bounded. Therefore, such services must have a clear set of requirements. For the network to provision resources to support a predictable or guaranteed service, the service requirements of that request must be configurable, measurable, and verifiable. This is where service requests, offerings, and metrics are applied.
Note that there are times when a service could be either best effort, predictable, or guaranteed, depending on how it is interpreted. Therefore, it is important to understand the need for a good set of requirements because these will help determine the types of services to plan for. Also, although the term predictable lies in a gray area between best effort and guaranteed, it is the type of service that is most likely to be served by most performance mechanisms, as we will see in Chapter 8.
For example, if a device requests capacity (bandwidth) of between 4 and 10 Mb/s, there needs to be a way to communicate this request across the network, a way to measure and/or derive the level of resources needed to support this request, a way to determine whether the required resources are available, and a method to control the information flow and network resources to keep this service between 4 and 10 Mb/s.
We can consider capacity to be a finite resource within a network. For example, the performance of a 100 Mb/s FE connection between two routers is bounded by that technology. If we were to look at the traffic flows across that 100 Mb/s connection, we would see that, for a common best-effort service, capacity would be distributed across all of the traffic flows. As more flows were added to that connection, the resources would be spread out until, at some point, congestion occurs. Congestion would disrupt the traffic flows across that connection, affecting the protocols and applications for each flow. What is key here is that, in terms of resource allocation, all traffic flows have some access to resources.
This is shown in Figure 1.25. In this figure, available capacity (dashed curve) decreases as the number of traffic flows increases. Correspondingly, the loading on the network (solid curve) from all of the traffic flows increases. However, at some point congestion affects that amount of user traffic that is being carried by the connection, and throughput of the connection (heavy curve) drops. As congestion interferes with the end-to-end transport of traffic, some protocols (e.g., TCP) will retransmit traffic. The difference between the loading and the throughput curves is due to retransmissions. This is undesirable, for while the connection is being loaded, only a percentage of that loading is successfully delivered to destinations. At some point, all of the traffic on that connection could be due to retransmissions and throughput approaches zero. This approach is used in best-effort networks.
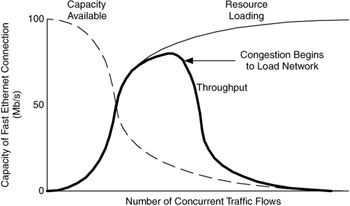
Figure 1.25: Performance of Fast Ethernet connection under best-effort conditions.
In contrast, consider a telephony network. Calls are made on this network, and resources are allocated to each call. As more calls are added to the network, at the point where all of the resources have been allocated, additional calls are refused. The exiting calls on the network may suffer no performance degradation, but no new calls are allowed until resources are available. Call admission control (CAC) is a mechanism to limit the number of calls on a network, thereby controlling the allocation of resources.
This is shown in Figure 1.26. Individual calls are shown in this figure, and each call is 10 Mb/s for simplicity. As each call is accepted, resources are allocated to it, so the availability drops (dotted line) and loading increases (solid line) for each call. When the resources are exhausted, no further calls are permitted (dashed line). Congestion is not a problem for the existing calls, and throughput is maximized. This approach is similar to a guaranteed service.
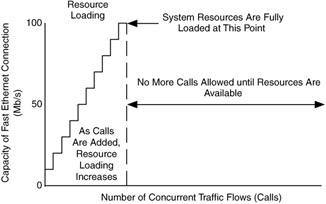
Figure 1.26: Performance of Fast Ethernet connection under CAC.
There is a trade-off between these two approaches to resource allocation in a network. Although a best-effort network will allow access to as many traffic flows as possible, performance degradation across all of the traffic flows can occur. Admission control preserves resources for traffic flows that have already been allocated resources but will refuse additional traffic flows when resources are exhausted. In many networks, both approaches (or a hybrid between them) are desired. This will be discussed in detail in Chapter 8.
Service requests and requirements can also be low or high performance in terms of capacity, delay, and RMA. Low-and high-performance requirements depend on each particular network. A requirement is low or high performance relative to other requirements for that network. Low performance is an indicator that the service request or requirement's performance characteristics are less than a performance threshold determined for that network. Likewise, high performance is an indicator that the service request or requirement's performance characteristics are greater than a performance threshold determined for that network. Thus, in determining low and high performance for a network, we will develop one or more performance thresholds for that network. Multiple-tier performance indicates that there are multiple tiers of performance for that network. Single-tier performance requirements are roughly equivalent within a network.
Note that low and high performance are not described in terms of best-effort, predictable, or guaranteed service because they are independent of each other. Best-effort, predictable, and guaranteed service refer to the degree of predictability of a request or requirement, whereas low and high performance refer to a relative performance level for that request or requirement. For example, a network can be entirely best effort (most current networks are), yet we can often distinguish low-and high-performance requirements for such a network. And when a network has low-and high-performance regions for capacity, delay, and RMA, there may be predictable or guaranteed requirements in either region.
By their nature, each service has its associated set of requirements. These requirements are based on the levels of performance and function desired by the user, application, or device requesting service. Performance requirements are described in terms of capacity, delay, and RMA, whereas functional requirements describe specific functions needed in the service, such as multicast, security, management, or accounting. We will use requests for performance and function in developing the network architecture and design, for example, in describing the overall level of performance needed in the network.
As mentioned earlier, service performance requirements (capacity, delay, and RMA) can be grouped together, forming one or more service levels. For example, a service request may couple a specific capacity (e.g., 1.5 Mb/s) with a bound on end-to-end delay (e.g., 40 ms). At times, such service levels can be mapped to well-known service mechanisms such as ATM CoS, frame relay CIR, SMDS CoS, or IP ToS or QoS. Thus, service levels are a way to map performance and functional requirements to a well-known or standard network service offering. A properly specified service will provide insight into which performance characteristics should be measured in the network to verify service delivery.
1.8.4 Service Offerings
Service requests that are generated by users, applications, or devices are supported by services that are offered by the network. These service offerings (e.g., via ATM CoS, frame relay CIR, SMDS CoS, or IP ToS or QoS mentioned in the previous section) are the network counterparts to user, application, and device requests for service.
Service offerings map to service requests and thus can also be categorized as best effort, predictable, and guaranteed. Best-effort service offerings are not predictable— they are based on the state of the network at any given time. There is little or no prior knowledge about available performance, and there is no control over the network at any time. Most networks today operate in best-effort mode. A good example of a network that offers best-effort service is the current Internet.
Best-effort service offerings are compatible with best-effort service requests. Neither the service offering nor request assume any knowledge about the state of or control over the network. The network offers whatever service is available at that time (typically just available bandwidth), and the rest of the system adapts the flow of information to the available service (e.g., via TCP flow control).
Example 1.6
An example of a best-effort service request and offering is when a file transfer (e.g., using FTP) occurs over the Internet. FTP uses TCP as its transport protocol, which, via a sliding-window flow-control mechanism, adapts to approximate the current state of the network it is operating across. Thus, the service requirement from FTP over TCP is best effort, and the corresponding service offering from the Internet is best effort. The result is that, when the FTP session is active, the performance characteristics of the network (Internet) and flow control (TCP windows) are constantly interacting and adapting, as well as contending with other application sessions for network resources. In addition, as part of TCP's service to the applications it supports, it provides error-free, reliable data transmission.
On the other hand, predictable and guaranteed service offerings have some degree of predictability or are bounded. To achieve this, there has to be some knowledge of the network along with control over the network in order to meet performance bounds or guarantees. Such services must be measurable and verifiable.
Just because a service is predictable or guaranteed does not necessarily imply that it is also high performance. For example, when using our definition of predictable service, the telephone network offers this type of service. Although at first look this may seem unlikely, consider the nature of telephone service. To support voice conversations, this network must be able to support fairly strict delay and delay variation tolerances, even though the capacity per user session (telephone call) is relatively small, or low performance. What is well known from a telephony perspective is somewhat new in the current world of data networking. Support for strict delay and delay variation is one of the more challenging aspects of data network architecture and design.
Predictable and guaranteed service offerings should be compatible with their corresponding service requests. In each case, service performance requirements (capacity, delay, and RMA) in a service request are translated into the corresponding performance characteristics in the service offering.
Example 1.7
An example of a predictable service request and offering can be seen in a network designed to support real-time streams of telemetry data. An architectural/design goal for a network supporting real-time telemetry is the ability to specify end-to-end delay and have the network satisfy this delay request. A real-time telemetry stream should have an end-to-end delay requirement, and this requirement would form the basis for the service request. For example, this service request may be for an end-to-end delay of 25 ms, with a delay variation of 400 s. This would form the request and the service level (i.e., a QoS level) that needs to be supported by the network. The network would then be architected and designed to support a QoS level of 25 ms end-to-end delay and delay variation of 400 s. Delay and delay variation would then be measured and verified with service metrics in the system, perhaps by using common utilities, such as ping (a common utility for measuring round-trip delay) or TCPdump (a utility for capturing TCP information), or by using a custom application.
We will use various methods to describe service performance requirements and characteristics within a network, including thresholds, bounds, and guarantees. We will also learn how to distinguish between high and low performance for each network project.
This approach does not mean that best-effort service is inherently low performance or that predictable or guaranteed services are high performance. What this approach does is signify that predictability in services is also an important characteristic and is separate from performance. There are times when a network is best architected for best-effort service, and other times when best-effort, predictable, and guaranteed services are needed. We will see that when predictable or guaranteed services are required in the network, consideration for those requirements will tend to drive the architecture and design in one direction while consideration for best-effort service will drive the architecture and design in another direction. It will be the combination of all services that will help make the architecture and design complete.
1.8.5 Service Metrics
For service performance requirements and characteristics to be useful, they must be configurable, measurable, and verifiable within the system. Therefore, we will describe performance requirements and characteristics in terms of service metrics, which are intended to be configurable and measurable.
Since service metrics are meant to be measurable quantities, they can be used to measure thresholds and limits of service. Thresholds and limits are used to distinguish whether performance is in conformance (adheres to) or nonconformance (exceeds) with a service requirement. A threshold is a value for a performance characteristic that is a boundary between two regions of conformance and, when crossed in one or both directions, will generate an action. A limit is a boundary between conforming and nonconforming regions and is taken as an upper or lower limit for a performance characteristic. Crossing a limit is more serious than crossing a threshold, and the resulting action is usually more serious (e.g., dropping of packets to bring performance back to conformance).
For example, a threshold can be defined to distinguish between low and high performance for a particular service. Both low-and high-performance levels are conforming to the service, and the threshold is used to indicate when the boundary is crossed. This threshold can be measured and monitored in the network, triggering some action (e.g., a flashing red light on an administrator's console) when this threshold is crossed. An example of this might be in measuring the round-trip delay of a path. A threshold of N ms is applied to this measurement. If the round-trip times exceed N ms, an alert is generated at a network management station. We will discuss this in greater detail in the network management architecture.
In a similar fashion, limits can be created with service metrics to provide upper and lower boundaries on a measured quantity. When a limit is crossed, traffic is considered nonconforming (it exceeds the performance requirement) and action is taken to bring the traffic back into conformance (e.g., by delaying or dropping packets). Figure 1.27 shows how limits and thresholds may be applied in the system. In this figure, a threshold of 6 Mb/s is the boundary between low and high performance for a service requirement, and an upper limit of 8 Mb/s is the boundary between conformance and nonconformance for that service. When traffic crosses the 6 Mb/s threshold, a warning is sent to network management (with a color change from green to yellow). These notices can be used to do trend analysis on the network, for example, to determine when capacity needs to be upgraded. When traffic crosses the 8 Mb/s limit, the network takes action to reduce the capacity used by that traffic flow and an alert is sent to network management (with a color change from yellow to red) until the capacity level drops below 8 Mb/s and is again conforming.
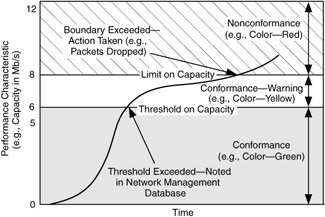
Figure 1.27: Performance limits and thresholds.
Thresholds and limits are useful applications of service metrics to understand and control performance levels in the network, in support of services.
EAN: 2147483647
Pages: 161