Section 13.2. Cricket
13.2. CricketCricket can be loosely associated with MRTG because it is an interface to RRDtool. It facilitates the following:
Cricket allows users to view graphs over the following time periods:
The main web site for Cricket is http://cricket.sourceforge.net. 13.2.1. Cricket's HistoryWhile working for WebTV[*] in 1998, Jeff Allen originally conceived of Cricket. Jeff wanted to find a way to reduce the complexity of WebTV's MRTG configuration and deployment. At that time, Tobias Oetiker, author of MRTG, released RRDtool. Once Jeff saw RRDtool, he began to see how its design could aid in solving many of WebTV's MRTG woes. MRTG had been known as the tool used for graphing router data. Jeff wanted a new way to graph other things as well, like data from servers.
13.2.2. Cricket's Config TreeUnderstanding the config tree is critical to understanding how to use and modify Cricket. Everything Cricket knows it learns from the config tree. That includes things like which variables to fetch for a certain type of device, how to fetch those variables, which devices to talk to, and the device types. The inheritance property of the config tree applies equally to all types of data, making it possible to create a concise description of a large, complicated set of monitored devices. At the top of the config tree is a file called Defaults. It contains default values for things like OIDs Cricket polls frequently. The config tree is made up of subdirectories which create logical devices, systems, and so on, from which Cricket may be asked to gather data. An example config tree might look like Figure 13-1. In this tree, we have two subtrees systemperf and routers. These two subtrees represent groups of targets that are interesting. For example, systemperf may be Unix systems from which we wish to gather CPU and disk information, and routers may contain Cisco devices for which we want to gather per-interface usage statistics. Each subtree has a file called Targets. This file contains information about what devices Cricket will actually poll. The filename used is arbitrary since Cricket will discover the file and the contents on its own. Also notice how the systemperf subtree has a Defaults file and the routers subtree does not. This means the systemperf subtree can override default values found in the top-level Defaults file. Since it has no specialized Defaults file, the routers subtree uses the top-level default values. Figure 13-1. Sample config tree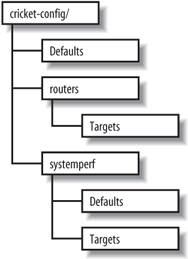 This config tree also allows Cricket to parallelize its data-gathering techniques. We'll discuss Cricket parallelization in a little more detail later in the chapter. 13.2.3. Installing CricketCricket requires some Perl modules to be in place before you can begin using it. A list of these modules can be found at http://cricket.sourceforge.net/support/doc/beginner.html. Once you have downloaded Cricket, create a user on the system on which you plan to run Cricket. We will use cricket as the username in all of the examples. Here are the initial steps to install Cricket: $ cd ~cricket $ tar zxvf cricket-1.0.5.tar.gz $ cd ~cricket/cricket-1.0.5 $ sh configure $ cd ~cricket $ ln -s cricket-1.0.5 cricket The sh configure command updates the Perl scripts to point to where your Perl interpreter is installed. The symbolic link makes it easier to install future versions. If you always reference ~cricket/cricket, nothing should break. Next, copy the sample Cricket configuration file and edit it: $ cd ~cricket/cricket $ cp cricket-conf.pl.sample cricket-conf.pl When you edit the file, make sure the variable $gCricketHome points to the home directory for the Cricket user, in our case, /home/cricket. Next, make sure $gInstallRoot points to the location where you installed Cricket. Here's what our file contains: $gCricketHome = "/home/cricket"; $gInstallRoot = "$gCricketHome/cricket"; We show how to configure Cricket to gather information on a Unix host. To set up the initial config tree to accomplish this, do the following: $ mkdir cricket-config $ cp -r cricket/sample-config/systemperf/ cricket-config/ $ cp cricket/sample-config/Defaults cricket-config/ Later we'll talk about how to add other devices for Cricket to monitor. Now we need to get the graphing component of Cricket set up. This requires a running instance of Apache. We created a public_html subdirectory in the Cricket user's directory. From there, we need to set up the environment: $ cd ~cricket/public_html $ mkdir cricket $ cd cricket $ ln -s ~cricket/cricket/VERSION . $ ln -s ~cricket/cricket/grapher.cgi . $ ln -s ~cricket/cricket/mini-graph.cgi . $ ln -s ~cricket/cricket/lib . $ ln -s ~cricket/cricket/images . That's it. We are now ready to configure and begin using Cricket. 13.2.4. Configuring and Using CricketSince we will be monitoring a Unix system, we need to set up the Cricket configuration properly. Luckily, Cricket comes with several scripts that make it easy to set up various configurations to monitor many types of devices. Let's look at one we can use to set up our Unix box (assume we are in /home/cricket): $ cricket/util/systemPerfConf.pl --host 192.168.1.69 \ --community public --auto > cricket-config/systemperf/Targets This command uses SNMP to gather various bits of information about the host and stores these details in cricket-config/systemperf/Targets. The - -auto configuration switch instructs the script to discover what it can with regard to what MIBs the box may support. The next step is to compile the configuration into a format that both Cricket and RRDtool can use: $ cricket/compile [05-Jun-2005 17:39:40 ] Log level changed from warn to info. [05-Jun-2005 17:39:40 ] Starting compile: Cricket version 1.0.5 (2004-03-28) [05-Jun-2005 17:39:40 ] Config directory is /home/cricket/cricket-config [05-Jun-2005 17:39:40 ] Processed 13 nodes (in 3 files) in 0 seconds. This sets the stage for actually gathering data. We can do a quick trial run of the collector by running the following command: $ cricket/collector /systemperf [05-Jun-2005 17:39:58 ] Log level changed from warn to info. [05-Jun-2005 17:39:58 ] Starting collector: Cricket version 1.0.5 (2004-03-28) [05-Jun-2005 17:39:58 ] Retrieved data for hr_sys (0): 60,5 [05-Jun-2005 17:39:58 ] Retrieved data for ucd_sys ( ): 455947,168,74908,10090430,24148,522072,546220,0.11,0.08,0.02 [05-Jun-2005 17:39:58 ] Retrieved data for if_lo (1): 15722669,15722669,0,0,93777,93777 [05-Jun-2005 17:39:58 ] Retrieved data for if_eth0 (2): 52684451,22813456,0,0,129146,115315 [05-Jun-2005 17:39:58 ] Retrieved data for if_eth1 (3): 0,0,0,0,0,0 [05-Jun-2005 17:39:58 ] Retrieved data for disk_root (4): 225570,381139 [05-Jun-2005 17:39:58 ] Retrieved data for disk_boot (5): 5912,46636 [05-Jun-2005 17:39:58 ] Retrieved data for disk_home (6): 101004,507980 [05-Jun-2005 17:39:58 ] Retrieved data for disk_usr (7): 242226,1393492 [05-Jun-2005 17:39:58 ] Retrieved data for disk_var (8): 34853,256667 [05-Jun-2005 17:39:58 ] Processed 10 targets in 0 seconds. Notice the argument passed to the collector: /systemperf. This is the directory name under ~cricket/cricket-config/ where the configuration for our Unix box is stored. Now we want to set up the interval at which we will poll our Unix system. Edit the file ~cricket/cricket/subtree-sets. It should look like the following: # This file lists the subtrees that will be processed together in one # set. See the comments at the beginning of collect-subtrees for more info. # This will be passed to collector so it can find the Config Tree. # If this directory does not start with a slash, it will # have $HOME prepended. base: cricket-config # this is where logs will be put. (The $HOME rule applies here too.) logdir: cricket-logs set normal: /routers /router-interfaces Change the end of the file so that it looks like this: # This file lists the subtrees that will be processed together in one # set. See the comments at the beginning of collect-subtrees for more info. # This will be passed to collector so it can find the Config Tree. # If this directory does not start with a slash, it will # have $HOME prepended. base: cricket-config # this is where logs will be put. (The $HOME rule applies here too.) logdir: cricket-logs set normal: /systemperf #/routers #/router-interfaces We'll talk about the /routers and /router-interfaces subtrees in a moment. Now, as your Cricket user, run crontab -e and add the following entry: */5 * * * * /home/cricket/cricket/collect-subtrees normal This notation works on Linux systems and will run the collect-subtrees command every five minutes. The argument passed to this command (normal) corresponds to the subtree-set in the subtree-sets file we just edited. The collect-subtrees command gathers data for all the subtrees configured beneath normal. Now, you should be ready to access the main Cricket screen. The URL we used is http://192.168.1.69/~cricket/cricket/grapher.cgi. Of course, you'll need to insert your own IP address and username in the URL. Figure 13-2 shows the main Cricket screen. Figure 13-2. Main Cricket screen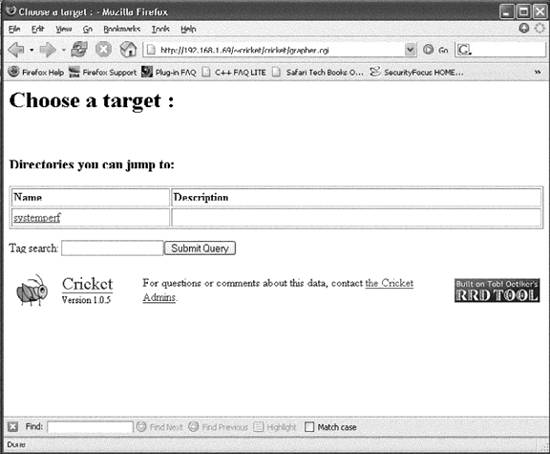 Clicking on the systemperf link takes you to a page that looks like Figure 13-3. What we see here are various links to things like the number of users and processes on the system, traffic statistics for the various network interfaces, and other system-specific variables. Figure 13-3. Data variables captured for Unix system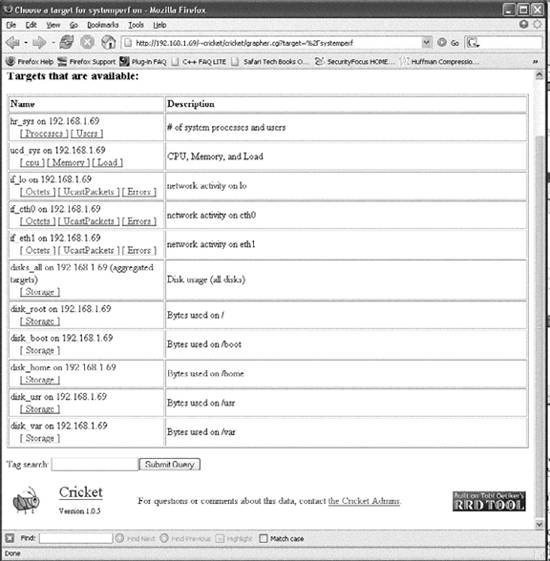 Let's now look at some of the graphs that the /systemperf subtree has created. Figure 13-4 shows a graph of the number of users on the system. This sort of graph can be useful because it shows, over time, how many users are logged onto the system. Let's say you come into the office on Monday morning and notice that on Saturday night the number of users jumped from its normal number of 5 to 10 for a 15-minute period. No one was supposed to be on the system over the weekend beyond the five you already know about. This could tip you off that your system has been compromised and that you should investigate immediately. Figure 13-5 shows a graph of processes running on the system. Figure 13-4. Number of users on the system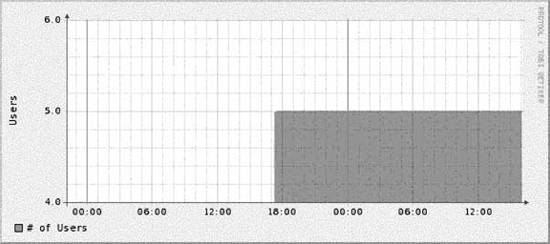 Figure 13-5. Number of processes on the system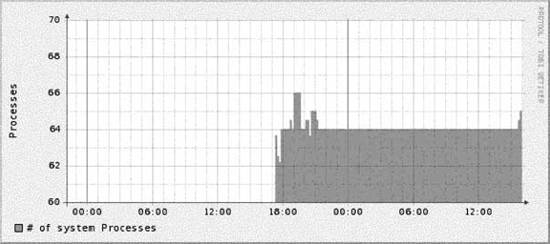 Figure 13-5 can be useful to watch how a critical server is utilized. If you are routinely seeing your web server's process load spike very high in the middle of the day, this graph can help pinpoint contributing suspects. Perhaps you are running a database on the server as well and certain users are generating routine reports at that time of the day. This could be your first clue that it is time to move the database off the web server. Figure 13-6 shows CPU utilization. Watching CPU utilization can also be very telling. If you see spikes in utilization that remain high for periods of time, you can use the time axis to cross-reference system logs to identify which processes are impacting the system. Figure 13-6. CPU utilization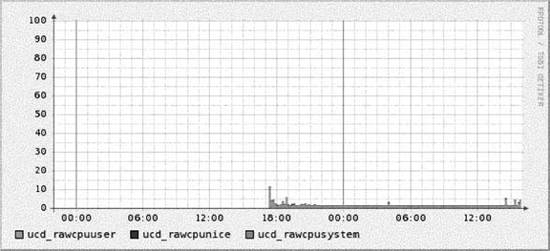 Figure 13-7 shows bits in and out on the system's Ethernet interface. This can be useful, for example, to determine when your system is saturating its connection to the Internet. If the time that the traffic surge occurs is questionable, you might look into whether someone is performing illegal file transfers at 2 a.m. Figure 13-7. Ethernet utilization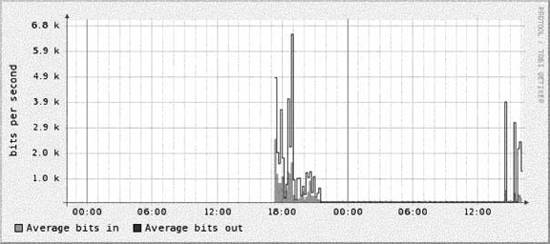 13.2.5. Gathering Router DataA discussion about Cricket wouldn't be complete without explaining how to configure it to gather data from your Cisco routers. We need to set up our config tree: $ cd ~cricket $ cp -r cricket/sample-config/routers/ ./cricket-config/ $ cp -r cricket/sample-config/router-interfaces/ cricket-config/ First, the routers subtree gathers variables such as temperature, CPU utilization, and so on. You will most certainly want to edit the default values in cricket-config/routers/Targets. Here is a sample from this file: target main-router target-type=Cisco-7500-Router short-desc = "Main router" The target clause is the hostname of the router from which you wish to gather data. target-type is the type of Cisco device. Cricket currently supports the following:
It supports only these routers because Cricket uses Cisco-specific private MIB objects to gather temperature, CPU information, and so on. Finally, short-desc is as the name implies: a short description of the device. Try to make this as meaningful as possible in case other people have to interpret this device's graphs. If you have other routers you wish to add to this file, go ahead. Next we will want to configure the router-interfaces subtree. This tree does not have the Cisco-specific version restriction, so most any router can reside under this subtree. The file we are concerned with is cricket-config/router-interfaces/interfaces. Here is a sample from this file: target --default-- router = bsn-router target Serial0_0_5 interface-name = Serial0/0/5 short-desc = "T1 to Nebraska" The line router = bsn-router tells the collector that a router target is defined and each subsequent target configuration denotes an interface on the routerin our case, bsn-routerabout which Cricket should gather interface statistics. It may seem like a daunting task to keep this file up-to-date. Well, don't fear. As with the systemperf example, there is a tool to help gather interface configurations from your routers. Here's a sample run: $ cd ~cricket $ cricket/util/listInterfaces router public > cricket-config/router-interfaces/ \ interfaces The listInterfaces command discovers all interfaces on the router and creates configurations for each of them. The downside to this is you may end up with router interfaces you don't care to graph. If this is the case, just edit the interfaces file and remove the entries you don't want. Now that we have changed the config tree, we must recompile it: $ cricket/compile
The final step is to edit the subtree-sets file and reinstate these two subtrees: # This file lists the subtrees that will be processed together in one # set. See the comments at the beginning of collect-subtrees for more info. # This will be passed to collector so it can find the Config Tree. # If this directory does not start with a slash, it will # have $HOME prepended. base: cricket-config # this is where logs will be put. (The $HOME rule applies here too.) logdir: cricket-logs set normal: /systemperf /routers /router-interfaces Here we have uncommented the /routers and /router-interfaces subtrees. The next time the collect-subtrees command runs, it will begin gathering data for these two new trees. Figure 13-8 and Figure 13-9 show two router interface graphs. Figure 13-8. Fast Ethernet routing instability during peer handoff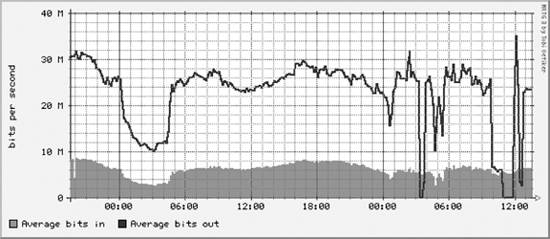 The two graphs show router instability occurring in a service provider's peer network. During the event, about 10 Mb/sec of traffic shifted over to the second peer. Figure 13-9. Handoff to another peer during router instability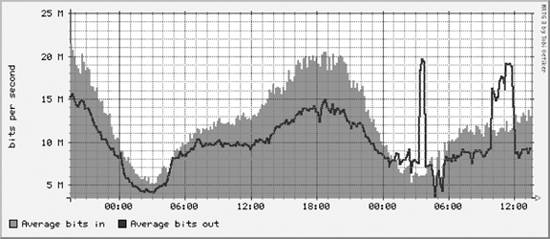 Cricket helped discover the nature of the problem. The outbound traffic failed over to a nonoptimal but functional link. After the instability passed, the traffic returned to normal. 13.2.6. Command-Line Data SourcesCricket is capable of executing commands instead of issuing SNMP queries. To help you to understand how Cricket does this, we will show how to switch one of the systemperf data sources from using SNMP to using a command-line tool. First, let's look at the cricket-config/systemperf/Defaults file. Ellipses (...) show where we truncated the file for brevity. target --default-- server = "" snmp-host = %server% display-name = "%auto-target-name% on %server%" min-size = 0 max-size = undef OID hrSystemNumUsers 1.3.6.1.2.1.25.1.5.0 . . . ##### Datasources ######### datasource hrSystemNumUsers ds-source = snmp://%snmp%/hrSystemNumUsers rrd-ds-type = GAUGE . . . #### Target Types ######### targetType hr_System ds = "hrSystemProcesses, hrSystemNumUsers" view = "Processes: hrSystemProcesses, Users: hrSystemNumUsers" . . . #### Graphs ############### graph hrSystemNumUsers color = dark-green draw-as = AREA y-axis = "Users" units = "Users" legend = "# of Users" precision = integer The first configuration block is a default setting for target. Cricket uses target as a generic term for a variable or set of variables that will be gathered and/or graphed for a device. The default target sets snmp-host to %server%, which is defined in our Targets file. The display-name is set to "%auto-target-name% on %server%". The auto-target-name is set to the target name (more on this in a moment). The min-size and max-size are used later in the Defaults file for graph configuration. The next section of the Defaults file sets various OIDs we wish to use in our data sources. The data sources section sets up each piece of data we wish to gather. Here we show the data source for the number of users on the system. The line: ds-source = snmp://%snmp%/hrSystemNumUsers shows the basic syntax for SNMP polling. The convention used is specific to Cricket and resembles a URL. Basically, Cricket will SNMP poll hrSystemNumUsers. But how does it know what community string to use? Recall that the top level of the config tree has a Defaults file. Looking near the top of the file reveals: Target --default-- dataDir = %auto-base%/../cricket-data/%auto-target-path% email-program = /usr/bin/mailx rrd-datafile = %dataDir%/%auto-target-name%.rrd rrd-poll-interval = 300 persistent-alarms = false snmp-host = %auto-target-name% snmp-community = public snmp-port = 161 snmp-timeout = 2.0 snmp-retries = 5 snmp-backoff = 1.0 snmp-version = 1 snmp = %snmp-community%@%snmp-host%:%snmp-port%:%snmp-timeout%: %snmp-retries%:%snmp-backoff%:%snmp-version% summary-loc = top show-path = no The Defaults file configures variables like community string, port, and version. Set these defaults to suit your requirements. But what if you need to use different community strings, for example, for different config subtrees? If this is the case, you can replicate variables like snmp-community in the particular subtree's Defaults file and Cricket will use them instead of the top-level defaults. The next section of the systemperf Defaults file sets the target types. The target type in the example configuration is hr_System. The line: ds = "hrSystemProcesses, hrSystemNumUsers" defines the data sources that make up this target type: hrSystemProcesses and hrSystemNumUsers. Finally, the graph configuration for hrSystemNumUsers is shown. Running a command to gather hrSystemNumUsers instead of using SNMP is as easy as changing the following line of code: ds-source = snmp://%snmp%/hrSystemNumUsers to this: ds-source = "exec:0:/usr/bin/who | /usr/bin/wc -l" Cricket supports the exec option for the ds-source identifier. Basically, it is interpreted like this: exec:output_line_to_grab:command The output_line_to_grab argument is meant for commands that may return multiple lines of output. The first line starts at 0, the second line at 1, and so on. The who command returns only one line of output, but notice how the data is returned: $ /usr/bin/who | /usr/bin/wc -l 5 There is whitespace before the 5. This is alright since Cricket will ignore leading whitespace until it finds a floating-point (or integer) number.
13.2.7. Parallelizing CricketOne advantage to Cricket's config tree is that you can break the tree into logical groupings and have Cricket gather data from each tree (or groups of trees) in parallel. Recall our subtree-sets file: # This file lists the subtrees that will be processed together in one # set. See the comments at the beginning of collect-subtrees for more info. # This will be passed to collector so it can find the Config Tree. # If this directory does not start with a slash, it will # have $HOME prepended. base: cricket-config # this is where logs will be put. (The $HOME rule applies here too.) logdir: cricket-logs set normal: /systemperf /routers /router-interfaces If we change the end like this: # This file lists the subtrees that will be processed together in one # set. See the comments at the beginning of collect-subtrees for more info. # This will be passed to collector so it can find the Config Tree. # If this directory does not start with a slash, it will # have $HOME prepended. base: cricket-config # this is where logs will be put. (The $HOME rule applies here too.) logdir: cricket-logs set servers: /systemperf set routers: /routers /router-interfaces we have created two separate subtree sets: one for servers and the other for routers. The next step is to edit our crontab file and change it like this: */5 * * * * /home/cricket/cricket/collect-subtrees servers */5 * * * * /home/cricket/cricket/collect-subtrees routers This will cause two separate collect-subtree commands to run. The first one will collect data for the /systemperf subtree and the other will collect for the /routers and /router-interfaces subtrees. If you have a machine that is underpowered with respect to CPU and memory, you will want to limit how many of these collect-subtrees you configure. At the very least, try to stagger the times when each one begins. For example, one can start every five minutes, the next every six minutes, and so forth. This technique is also not foolproof, however. Because of variations in how operating systems perform with respect to clock-based activities, you are not guaranteed that something in cron that is scheduled to start every five minutes will start precisely 300 seconds after the last crontab entry. It could be off by a few microseconds, a few milliseconds, or even a few seconds. Depending on how many such activities you have scheduled and the limitations of the hardware in question, this could make a difference in performance. 13.2.8. Help with CricketThis chapter only briefly described how to use Cricket. To learn more about Cricket, check out the following web pages:
|

EAN: 2147483647
Pages: 165