Accessing Data with DataSets
| An instance of the class DataSet, contained in the System.Data namespace, is an in-memory cache for data. Most commonly, that data is the set of rows resulting from one or more SQL queries, but it can also include information derived from an XML document or from some other source. Unlike Connection, Command, and DataReader, each of which has a unique class for each .NET Framework data provider, there is only one DataSet class used by all .NET Framework data providers.
DataSets are very general things, so they're useful in many different situations. For instance, if a client application wishes to examine data in an arbitrary way, such as scrolling back and forth through the rows resulting from a SQL query, a DataReader won't sufficebut a DataSet will. DataSets are also useful for combining data from different data sources, such as two separate queries, or different types of data, such as the result of a query on a relational DBMS and the contents of an XML document. And because DataSets are serializable, they can be used for data that will be sent across a network. In fact, once it's been created, a DataSet can be passed around and used independentlyit's just a managed object with state and methods like any other.
Another important distinction between a DataSet and a DataReader is that DataSets can be used to modify data. Changes made to information stored in a DataSet can be written back to a database. Unlike DataReaders, DataSets aren't purely read-only objects, and so any ADO.NET client that wishes to update data will rely on DataSets.
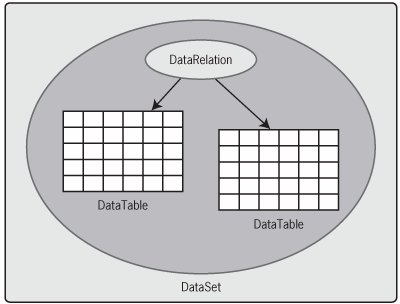
Figure 6-3 shows a simplified picture of a DataSet. Each DataSet object can contain zero or more DataTable objects, which are instances of the DataTable class defined in System.Data. Each DataTable can contain the result of a query or perhaps something else. A DataSet can also maintain relationships among DataTables using DataRelation objects. For example, a column in one table might contain a foreign key for another table, a relationship that could be modeled by a DataRelation. These relationships can be used to navigate through the contents of a DataSet. A simple DataSet, one that contains the result of just a single SQL query, might have only one DataTable and no DataRelations. DataSets can be quite complex, however, so an application that needed to maintain the results of several queries in memory could stuff them all into one DataSet, each in its own DataTable. Figure 6-3. A DataSet contains DataTables, and it can have DataRelation objects that describe relationships among those tables.
Each DataSet has a schema. Since DataSets hold tables, this schema describes those tables, including the columns each one contains and the types of those columns. Each DataSet and DataTable also has an ExtendedProperties property that can be used in various ways. For example, the ExtendedProperties value for each DataTable might contain the SQL query that generated the information stored in that table.
Creating and Using DataSetsAs mentioned earlier, DataSet objects can be created using a .NET Framework data provider's DataAdapter object. For example, the .NET Framework data provider for SQL Server offers the class SqlDataAdapter, while the .NET Framework data provider for OLE DB uses OleDbDataAdapter. Whatever data provider is used, all of the specific DataAdapter classes offer a similar set of properties and methods for creating and working with DataSets. Among the most important properties of a DataAdapter are the following:
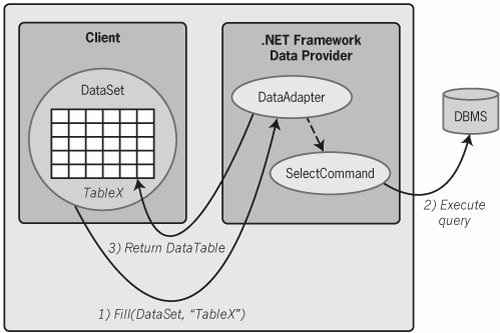
The contents of these properties, which can be explicit SQL statements or stored procedures, are accessed by various methods provided by the DataAdapter. The most important of these methods is Fill. As shown in Figure 6-4, this method executes the command in the DataAdapter's SelectCommand property and then places the results in a DataTable object inside whatever DataSet is passed as a parameter on the Fill call. The connection to the database can be closed once the desired results are returned, since a DataSet object is completely independent of any connection to any data source. Figure 6-4. Calling a DataAdapter's Fill method causes the associated SelectCommand to be executed and the results placed in a DataSet as a DataTable.
Here's a C# example that shows how a DataAdapter can be used to add a DataTable containing the results of a query to a DataSet: using System.Data; using System.Data.SqlClient; class DataSetExample { public static void Main() { SqlConnection Cn = new SqlConnection( "Data Source=localhost;" + "Integrated Security=SSPI;" + "Initial Catalog=example"); SqlCommand Cmd = Cn.CreateCommand(); Cmd.CommandText = "SELECT Name, Age FROM Employees"; SqlDataAdapter Da = new SqlDataAdapter(); Da.SelectCommand = Cmd; DataSet Ds = new DataSet(); Cn.Open(); Da.Fill(Ds, "NamesAndAges"); Cn.Close(); } }This example begins with using statements for the System.Data namespace, home of the DataSet class, and for System.Data.SqlClient, because this example will once again use the .NET Framework data provider for SQL Server. Like the previous example, this class's single method creates Connection and Command objects and then sets the Command object's CommandText property to contain a simple SQL query. The example next creates an instance of the SqlDataAdapter class and sets its SelectCommand property to contain the Command object created earlier. The method then creates a DataSet and opens a connection to the database. Once this connection is open, the method calls the DataAdapter's Fill method, passing in the DataSet in which a new DataTable object should be created and the name that DataTable object should have. Closing the connection, the last step, doesn't affect the DataSet in any wayit never had any idea what connection was used to create the data it contains anyway. The DataSet created by this simple example contains just one DataTable. To add other DataTables with different contents to this same DataSet, the Fill method could be called again once the SelectCommand property of the DataAdapter had been changed to contain a different query. Alternatively, as shown in Figure 6-5, another DataAdapter could be used on a different data source. In the figure, a single DataSet is being populated with DataTables from two different .NET Framework data providers accessing two different databases. In each case, the same DataSet is passed into a call to the appropriate DataAdapter's Fill method. The result of each call is a DataTable within this DataSet whose contents are the result of running whatever query is represented by the SelectCommand object associated with the DataAdapter. Figure 6-5. A single DataSet can contain DataTables whose contents are derived from different databases.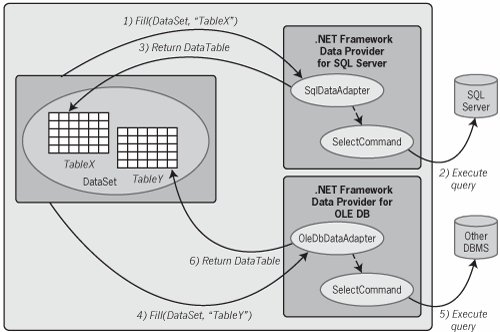
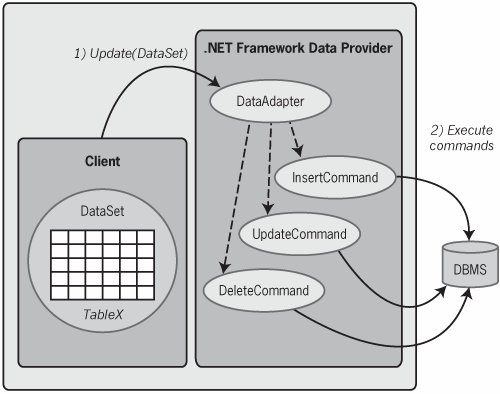
As mentioned earlier, it's also possible to modify information in a DBMS using a DataSet. Once one or more DataTables have been created in the DataSet, the information in those tables can be changed by the client in various ways, as described later in this section. As shown in Figure 6-6, calling a DataAdapter's Update method will cause the DataAdapter to examine the changes in any DataSet or DataTable passed into this call and then modify the underlying database to reflect those changes. These modifications are made using the commands stored in the DataAdapter's InsertCommand, UpdateCommand, and DeleteCommand properties described earlier. Because these commands can be stored procedures as well as dynamically executed statements, these update operations can be quite efficient.
Note that there is no way for the DataSet itself to maintain a lock on the underlying data from which its contents were derived. As a result, it's possible that the data in the database has changed since some of its information was copied into the DataSet. Whether updates succeed if the underlying data has changed depends on what commands are placed into the InsertCommand, UpdateCommand, and DeleteCommand properties of the DataAdapter. For example, it's possible to generate those commands automatically using a CommandBuilder object supplied by the .NET Framework class library. If this is done, the automatically generated update commands are designed to fail if any of the affected data has changed since it was originally read. This need not be the case for commands created manually, howeverit's up to the developer to decide what's best for each application. Figure 6-6. Calling a DataAdapter's Update method updates the DBMS to reflect any changes made to a DataSet.
Every DataSet has a few collections that logically group some of the DataSet's objects. For example, all of the DataTables in a DataSet belong to the Tables collection. An application can create a freestanding DataTable object, one that's not part of any DataSet, then explicitly add it to some DataSet object[1] To do this, the application can pass this DataTable object as a parameter on the Add method of the DataSet's Tables collection. Similarly, each DataSet has a Relations collection that contains all of the DataRelation objects in this DataSet, each of which represents a relationship of some kind between two tables. Calling the Add method of a DataSet's Relations collection allows creating a new DataRelation object. The parameters on this call can be used to specify exactly which fields in the two tables are related.
Accessing and Modifying a DataSet's ContentsDataSets exist primarily to let applications read and change the data they contain. That data is grouped into one or more DataTables, as just described, and so access to a DataSet's information is accomplished by accessing these contained objects. Because applications need to work with data in diverse ways, DataTables provide several options for accessing and modifying the data they contain. Whatever option is used, two classes are commonly used to work with information in a DataTable:
For more complex examinations of data, each DataTable provides a Select method. This method allows an application to describe the data it's interested in and then have that data returned in an array of DataRow objects. Select takes up to three parameters: a filter, a sort order, and a row state. The filter allows specifying a variety of criteria that selected rows must meet, such as "Name='Smith'" or "Age >45." The sort order allows specifying which column the results should be sorted by and whether those results should be sorted in ascending or descending order. Finally, the row state parameter allows returning only records in a specific state, such as those that have been added or those that have not been changed. Whatever criteria are used on the call to Select, the result is an array of DataRows. The application can then access individual elements of this array as needed to work with the data each one contains.
To add data to a DataTable, an application can create a new DataRow object, populate it, and insert it into the table. To create the new DataRow, the application can call a DataTable's NewRow method. Once this DataRow exists, the application can assign values to the fields in the row, then add the row to the table by calling the Add method provided by the DataTable's Rows collection. It's also possible to modify the contents of a DataTable directly by assigning new values to the contents of its DataRows and to delete rows using the Remove method of the Rows collection.
The state of a DataRow changes as that DataRow is modified. The current state is kept in a property of the DataRow called RowState, and several possibilities are defined. Changes made to a DataRow can be made permanent by calling the DataRow.AcceptChanges method for that row, which sets the DataRow's RowState property to Unchanged. To accept all changes made to all DataRows in a DataTable at once, an application can call DataTable.AcceptChanges, while to accept all changes made to all DataRows in all DataTables in a DataSet at once, an application can call DataSet.AcceptChanges. It's also possible to call the RejectChanges method at each of these levels to roll back any modifications that have been made.
Using DataSets with XML-Defined DataInformation stored in relational DBMS probably comprises the majority of business data today. Increasingly, though, data defined using XML is also important, and XML's hierarchical approach to describing information will probably matter even more in the future. Recognizing this, the designers of ADO.NET chose to integrate DataSets and XML-defined data in several different ways. This section describes the available choices.
Translating Between DataSets and XML DocumentsIn the description so far, the contents of a DataTable inside a DataSet have always been generated by a SQL query. It's also possible, however, to create DataTables in a DataSet whose contents come from an XML document. To do this, an application can call a DataSet's ReadXml method, passing as a parameter an indication of where the XML data can be found. The possible sources for this data include a file, a stream, and an XmlReader object. Wherever it comes from, the XML-defined information is read into a DataTable in the DataSet.
There's an obvious problem here. Both XML and the relational model have the notion of schemas for describing data. Yet the two technologies view this notion in very different ways. An XML schema defines a hierarchy using the XML Schema definition (XSD) language. The relational model defines a schema as a set of tables, each having a particular group of columns in a particular order. DataSets and the DataTables they contain are firmly in the relational camp. When an XML document is loaded into a DataSet, what should the schema of the resulting table look like? Like most questions, the answer to this one is: It depends. The DataSet.ReadXml method allows passing an XmlReadMode parameter to control how the XML document's schema is mapped into the schema for the DataTable in which that document's information will be stored. One option is to tell the DataSet to read an XSD schema that appears in the XML document being read, while another instructs the DataSet to infer a relational schema from the XML schema.
Mapping the hierarchical form of an XML document into the tables contained in a DataSet can be a nontrivial undertaking. In particular, the rules for inferring a relational schema are not especially simple. Some parts are easy, though. For instance, all columns have the type String, since if no XSD schema is available a DataSet has no way to identify any other types. Mapping the document's hierarchy into tables is more interesting. When inferring a relational schema, a DataSet assumes that an XML element with attributes should become a table, with the attributes and the element value represented as columns in that table. Similarly, an element with child elements will also become a table containing some number of values.
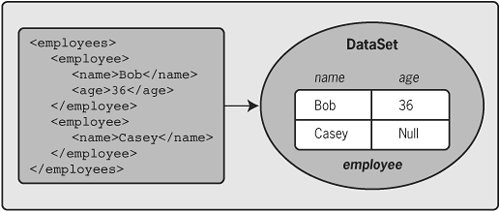
Figure 6-7 shows how the simple XML document we saw in Chapter 4 might be mapped into a DataSet if it were read with DataSet.ReadXml. The <employee> elements are placed into a single DataTable named employee, with the information in each of the child elements mapped into a row in that table. Notice that because there's no age present for Casey that value is of the type null (or more exactly, the type DBNull defined in the System namespace). Figure 6-7. A DataSet can infer a relational schema from an XML document read with DataSet.ReadXml. While this simple example worked fine, inferring a relational schema from an XML document is in general likely to produce a less attractive result than creating one directly from an XSD schema. When possible, then, it's better to tell the DataSet to read an XML document's schema. Also, if an XML document is being read into a DataSet that contains data and already has a schema, the ReadXml method can be instructed just to use the DataSet's existing schema. Note too that it's possible to read an XML schema explicitly from a stream, a file, or somewhere else into a DataSet by calling the DataSet's ReadXmlSchema method.
Once an XML document has been loaded into a DataSet, the data it contains can be treated just like any other data in any other DataSetthere's nothing special about it. And just as an application can populate a DataSet from an XML document, so too it's possible to write out a DataSet's contents as an XML document. In other words, the contents of any DataSet can be serialized as XML, whether or not its data originally came from an XML document. A primary choice for doing this is the DataSet's WriteXml method. This method writes the DataSet's contents as an XML document to a stream, an XmlWriter, or some other destination. A parameter on this method can be used to control whether an XSD schema is written with the data. If desired, a developer can specify how columns are mapped to XML and control other options in the transformation from table to hierarchy.
One common reason for serializing a DataSet as an XML document is to allow the information it contains to be sent to a browser. Similarly, an XML document received from a browser can be read into a DataSet and then used to update a DBMS or in some other way. It's also worth noting that because DataSets are serializable, they can be passed as parameters by applications that use .NET Remoting[2] Data wrapped in XML can be applied in many contexts, and so being able to easily serialize a DataSet into this format is quite useful.
Synchronizing a DataSet and an XML DocumentReading an XML document into a DataSet converts the information it contains into a set of tables. Similarly, writing the contents of a DataSet as an XML document converts the information in that DataSet into a hierarchical form. Being able to translate data between tables and trees is certainly a useful thing. Yet sometimes you'd like the ability to treat the same data as either relational tables or an XML tree at the same time. Rather than converting between the two formats, a transformation that can lose information, you'd like to maintain the flexibility to view the same data in either form depending on your requirements. ADO.NET allows this by synchronizing a DataSet with an instance of a class called XmlDataDocument.
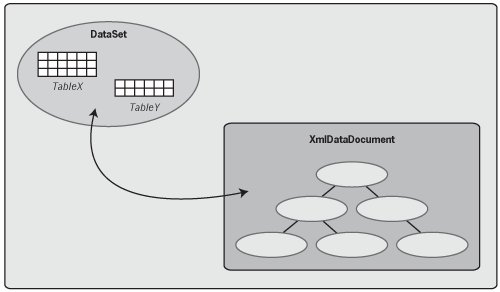
Figure 6-8 shows how this looks. By having the data available in a DataSet, it can be accessed using standard operations such as DataTable.Select. Yet having the same data available in an XmlDataDocument allows running XPath queries on the data, performing XSLT transforms, and doing other kinds of hierarchically oriented access. XmlDataDocument inherits from XmlDocument, a class described in Chapter 4 that implements the standard navigational API for XML, the Document Object Model (DOM). Since it derives from XmlDocument, XmlDataDocument also allows its contents to be accessed using this navigational interface. Along with this, however, XmlDataDocument also allows its user to work simultaneously with the data it contains as a DataSet. Figure 6-8. Synchronizing a DataSet with an XmlDataDocument allows an application to view the same data either relationally or hierarchically.
To view an existing XmlDataDocument's information as a DataSet, an application can simply access the XmlDataDocument's DataSet property. The result is a DataSet object containing the XmlDataDocument's information in a relational form. There are also other ways to create a synchronized DataSet/XmlDataDocument pair. One choice is to create an instance of an XmlDataDocument and pass in a DataSet on the new operation. This will create an XmlDataDocument that provides a hierarchical view of whatever data is in that DataSet. Another option is to create a DataSet containing only relational schema information rather than data, then pass this DataSet on the new operation that creates an XmlDataDocument. An XML document can now be loaded into the XmlDataDocument using its Load method, and the data in that document will be both loaded as an XML hierarchy and mapped to tables using the DataSet's existing schema. However it's done, the ability to use the same data either hierarchically or relationally is an interesting idea, one that's quite useful for some kinds of applications.
|
EAN: 2147483647
Pages: 67