Introduction
| Automation is the holy grail of software development. In fact, much of the progress in software development is driven by the notion of code generation from some higher-level specification. After all, isn't that what assemblers and compilers do? However, in another form of code generation, the target language is not executable machine code, but a high-level language such as Java or C++. Why would you want to generate code in this way, and what does XML have to do with it? When you write programs, you essentially encode many kinds of knowledge into a very specific syntax that is optimized for one particular development life-cycle phase. It is difficult to leverage the work done in coding to other important development tasks because programming languages are difficult to parse and much of the interesting information is encoded in ad-hoc comments. Representing application knowledge in XML provides the opportunity for much greater leverage. From XML specifications, you can generate application code, test programs, documentation, and possibly even test data. This is not to say that XML gives you this for free. As with all software-development tasks, a great deal of planning and infrastructure building is required to reap the benefits. This chapter is different from most other chapters in this book because most examples are components of a solution within the context of a particular application. The reason for this structure is two-fold. First, it is unlikely that you would encode information in XML to generate code just because XML is cool. In most cases, a larger problem must be solved in which XML can be further leveraged. The examples in this section will make more sense if they are presented in the context of a larger problem. Second, the particular problem is common in large-scale application development, so readers might find it interesting in its own right. However, even if this is not the case, the larger problem will not take away from the application of the concepts to other development tasks. So what is this large problem? Imagine a complex client-server application. Complex means that it consists of many types of server and client processes. These processes communicate via messages using message-oriented middleware (either pointing to point, publish/subscribe, or both). IBM MQSeries, Microsoft Message Queuing (MSMQ), BEA Systems Tuxedo, and TIBCO Rendezvous are just a few of the many products in this space. In this example, the particular middleware product is not particularly relevant. What is relevant is that all significant work performed by the system is triggered by the receipt of a message and the subsequent response involving one or more messages.[1] The message may contain XML (SOAP), non-XML text, or binary data. Chapter 12 covers SOAP in the context of WSDL. This chapter is primarily interested in server-to-server communication in which XML is used less often.
What is particularly daunting about such complex systems is that you cannot simply understand them by viewing the source code of any one particular type of process. You must begin by first understanding the conversations or inter-process messaging protocols spoken by these processes. This chapter goes even further and states that, at a first level of approximation, the details of each individual process are irrelevant. You can simply treat each process as a black box. Then, rather than understand the hundreds of thousands of lines of code that make up the entire system, you can start by understanding the smaller set of messages that these processes exchange. Thus the question becomes, how do you go about understanding the interprocess language of a complex application? Can you go to a single place to get this information? Sadly, this is often not the case. I find that you can rarely find an up-to-date and complete specification of an application's messaging protocols. You can usually find pieces of the puzzle in various shared header files and other pieces in design documents developed over the system's life cycle, but rarely will you find a one-stop source for such vital information. And in many cases, the only truly reliable method of obtaining such information is to reverse-engineer it from the applications' source code, which is exactly what I claimed you should not have to do! Okay, so what does this problem have to do with XML, XSLT, and, in particular, code generation? You can describe the solution to this problem in terms of the need for a documentation that describes in complete detail an application's interprocess messaging structure. What kind of document should this be? Maybe the developers should maintain an MS Word document describing all the messages or, better still, a messaging web site that can be browsed and searched. Or, maybe (and you should have guessed the answer already) the information should be kept in XML! Perhaps you should generate the web site from this XML. While you're at it, maybe you should generate some of the code needed by the applications that processes these messages. This is, in fact, exactly what you shall do in this chapter. I call the set of XML files an interprocess message repository . Many recipes in this chapter demonstrate how to generate code using this repository. Before moving to the actual recipes, this chapter presents the repository's design in terms of its schema. It uses W3C XSD Schema for this purpose but only shows an intuitive graphical view for those unfamiliar with XML schema. Figure 12-1 was produced using Altova's XML Spy 4.0 (http://www.xmlspy.com). The icons with three dots (...) represent an ordered sequence. The icon that looks like a multiway switch represents a choice. Figure 12-1. Graphical representation of XSD schema for repository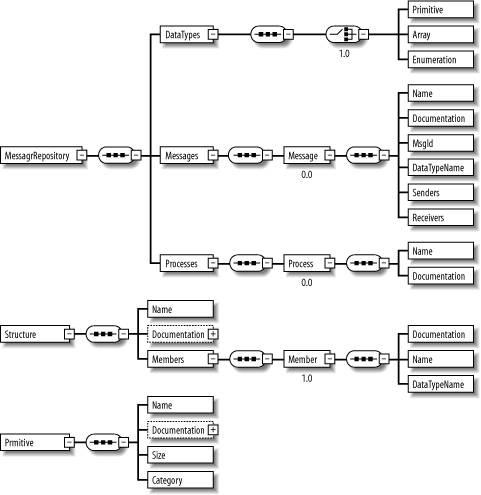 Although this schema is sufficient to illustrate interesting code-generation recipes, it is probably inadequate for an industrial-strength message repository. Additional data might be stored in a message repository, as shown in the following list:
As sample repository data, imagine a simple client-server application that submits orders and cancellations for common stock. The repository for such an application might look like this: <MessageRepository xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi: noNamespaceSchemaLocation="C:\MyProjects\XSLT Cookbook\code gen\MessageRepository. xsd"> <DataTypes> <Primitive> <Name>Real</Name> <Size>8</Size> <Category>real</Category> </Primitive> <Primitive> <Name>Integer</Name> <Size>4</Size> <Category>signed integer</Category> </Primitive> <Primitive> <Name>StkSymbol</Name> <Size>10</Size> <Category>string</Category> </Primitive> <Primitive> <Name>Message</Name> <Size>100</Size> <Category>string</Category> </Primitive> <Primitive> <Name>Shares</Name> <Size>4</Size> <Category>signed integer</Category> </Primitive> <Enumeration> <Name>BuyOrSell</Name> <Enumerators> <Enumerator> <Name>BUY</Name> <Value>0</Value> </Enumerator> <Enumerator> <Name>SELL</Name> <Value>1</Value> </Enumerator> </Enumerators> </Enumeration> <Enumeration> <Name>OrderType</Name> <Enumerators> <Enumerator> <Name>MARKET</Name> <Value>0</Value> </Enumerator> <Enumerator> <Name>LIMIT</Name> <Value>1</Value> </Enumerator> </Enumerators> </Enumeration> <Structure> <Name>TestData</Name> <Members> <Member> <Name>order</Name> <DataTypeName>AddStockOrderData</DataTypeName> </Member> <Member> <Name>cancel</Name> <DataTypeName>CancelStockOrderData</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>AddStockOrderData</Name> <Documentation>A request to add a new order.</Documentation> <Members> <Member> <Name>symbol</Name> <DataTypeName>StkSymbol</DataTypeName> </Member> <Member> <Name>quantity</Name> <DataTypeName>Shares</DataTypeName> </Member> <Member> <Name>side</Name> <DataTypeName>BuyOrSell</DataTypeName> </Member> <Member> <Name>type</Name> <DataTypeName>OrderType</DataTypeName> </Member> <Member> <Name>price</Name> <DataTypeName>Real</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>AddStockOrderAckData</Name> <Documentation>A positive acknowledgment that order was added successfully. </Documentation> <Members> <Member> <Name>orderId</Name> <DataTypeName>Integer</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>AddStockOrderNackData</Name> <Documentation>A negative acknowledgment that order add was unsuccessful. </Documentation> <Members> <Member> <Name>reason</Name> <DataTypeName>Message</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>CancelStockOrderData</Name> <Documentation>A request to cancel all or part of an order</Documentation> <Members> <Member> <Name>orderId</Name> <DataTypeName>Integer</DataTypeName> </Member> <Member> <Name>quantity</Name> <DataTypeName>Shares</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>CancelStockOrderAckData</Name> <Documentation>A positive acknowledgment that order was canceled successfully. </Documentation> <Members> <Member> <Name>orderId</Name> <DataTypeName>Integer</DataTypeName> </Member> <Member> <Name>quantityRemaining</Name> <DataTypeName>Shares</DataTypeName> </Member> </Members> </Structure> <Structure> <Name>CancelStockOrderNackData</Name> <Documentation>A negative acknowledgment that the order cancel was unsuccessful.</Documentation> <Members> <Member> <Name>orderId</Name> <DataTypeName>Integer</DataTypeName> </Member> <Member> <Name>reason</Name> <DataTypeName>Message</DataTypeName> </Member> </Members> </Structure> </DataTypes> <Messages> <Message> <Name>ADD_STOCK_ORDER</Name> <MsgId>1</MsgId> <DataTypeName>AddStockOrderData</DataTypeName> <Senders> <ProcessRef>StockClient</ProcessRef> </Senders> <Receivers> <ProcessRef>StockServer</ProcessRef> </Receivers> </Message> <Message> <Name>ADD_STOCK_ORDER_ACK</Name> <MsgId>2</MsgId> <DataTypeName>AddStockOrderAckData</DataTypeName> <Senders> <ProcessRef>StockServer</ProcessRef> </Senders> <Receivers> <ProcessRef>StockClient</ProcessRef> </Receivers> </Message> <Message> <Name>ADD_STOCK_ORDER_NACK</Name> <MsgId>3</MsgId> <DataTypeName>AddStockOrderNackData</DataTypeName> <Senders> <ProcessRef>StockServer</ProcessRef> </Senders> <Receivers> <ProcessRef>StockClient</ProcessRef> </Receivers> </Message> <Message> <Name>CANCEL_STOCK_ORDER</Name> <MsgId>4</MsgId> <DataTypeName>CancelStockOrderData</DataTypeName> <Senders> <ProcessRef>StockClient</ProcessRef> </Senders> <Receivers> <ProcessRef>StockServer</ProcessRef> </Receivers> </Message> <Message> <Name>CANCEL_STOCK_ORDER_ACK</Name> <MsgId>5</MsgId> <DataTypeName>CancelStockOrderAckData</DataTypeName> <Senders> <ProcessRef>StockServer</ProcessRef> </Senders> <Receivers> <ProcessRef>StockClient</ProcessRef> </Receivers> </Message> <Message> <Name>CANCEL_STOCK_ORDER_NACK</Name> <MsgId>6</MsgId> <DataTypeName>CancelStockOrderNackData</DataTypeName> <Senders> <ProcessRef>StockServer</ProcessRef> </Senders> <Receivers> <ProcessRef>StockClient</ProcessRef> </Receivers> </Message> <Message> <Name>TEST</Name> <MsgId>7</MsgId> <DataTypeName>TestData</DataTypeName> <Senders> <ProcessRef>StockServer</ProcessRef> </Senders> <Receivers> <ProcessRef>StockClient</ProcessRef> </Receivers> </Message> </Messages> <Processes> <Process> <Name>StockClient</Name> </Process> <Process> <Name>StockServer</Name> </Process> </Processes> </MessageRepository> This repository describes the messages that are sent between a client (called StockClient) and a server (called StockServer) as the application performs its various duties. Readers familiar with WSDL will see a similarity; however, WSDL is specific to web-service specifications and is most often used in the context of SOAP services, even though the WSDL specification is technically protocol-neutral (http://www.w3.org/TR/wsdl). The last two examples in this chapter are independent of the messaging problem. The first focuses on generating C++ code from Unified Modeling Language (UML) models exported from a UML modeling tool via XML Metadata Interchange (XMI). The second discusses using XSLT to generate XSLT. Before proceeding with the actual examples, I apologize for favoring C++ for most of the examples. I did this only because it is the language with which I am most familiar; it is the language for which I have actually written generators; and the conceptual framework is transferable to other languages, even if the literal XSLT is not.[2]
XSLT 2.0Due to the specialized nature of these recipes, I do not present both XSLT 1.0 and 2.0 solutions, as is done in many of the earlier chapters. However, readers interested in using XSLT 2.0 to generate code should study Chapter 6. Many of the 2.0 specific features and techniques presented there can be applied nicely to code generation. Here are a list of general ideas:
|
EAN: 2147483647
Pages: 208