Chapter 11: Optimizing Multimedia Applications with Assembly Language
Multimedia applications are the most performance-dependent. They work in real time and have strict requirements regarding hardware and software. This chapter will focus on a few methods for optimizing multimedia applications using the assembler. First, we will review a few notes concerning performance improvement, regardless of which language is used for programming.
Multimedia applications code must be as simple as possible. The same is true for the data structures used in these applications. Avoid data type conversion if possible. Converting integers to floating-point numbers and vice versa decreases performance because additional commands are required.
Use 32-bit data for operations on variables . 8-bit or 16-bit data require less memory, but operations on 32-bit data are the best for Pentium processors.
In your multimedia applications, avoid floating-point operations because integer operations are faster.
Pass parameters to your functions by reference, rather than by value. Also, align your data on a double-word boundary. Prefer global variables to local.
The performance of multimedia applications can be improved by optimizing the vector conversion algorithms and by using multithreading.
The concept of multithreading is a very important aspect of writing multimedia applications. No serious multimedia applications can do without threads. Threads are usually used to implement the following tasks :
-
Creating controls and menus
-
Creating sound effects
-
Updating data structures
-
Updating animation frames
The use of threads is not confined to these tasks; there are other ways of using them. Multithread applications are discussed in more detail in Chapter 12 . For now, we will consider an example of a program with two threads (main and auxiliary), in which a 3D vector is scaled. The vector s coordinates are stored in the a1 array, and the scale factor is 4. Additionally, the vector s length is computed. First, we will consider a variant of the application with common C++ .NET statements (Listing 11.1).
| |
// MHTHREAD_GRAPHICS.cpp : Defines the entry point for the console. // application #include "stdafx.h" #include <windows.h> #include <math.h> int i1; // The vector's coordinates (x, y, z) int a1[4] = {4, 7, 3}; void myFunc(LPVOID k1) { for(i1 = 0; i1 < 4; i al [il] = (int) kl*al [il]; } int _tmain(int argc, _TCHAR* argv[]) { HANDLE mythread; DWORD mythread_id; double vec_len; printf("CHANGING THE LENGTH OF VECTOR a = (a0, a1, a2) (DirectX Optimizing Tips) \n"); printf("\nBefore scaling vector a=(%d, %d, %d)\n", a1[0], a1[1], a1[2]); vec_len = sqrt((double) (a1 [0] *al [0]+a1 [1] *al [1]+a1 [2] *al [2])); printf("\Length of a1 = %.2f\n", vec_len) ; printf("\n\n Starting thread \n\n"); mythread = CreateThread(NULL, 0, (PTHREAD_START_ROUTINE)myFunc, (LPVOID) (4) , 0, &mythread_id); while(true) { if (WaitForSingleObject (mythread, 0) == WAIT_OB JECT_0) { vec_len = sqrt((double) (a1 [0] *al [0]+a1 [1] *al [1]+a1 [2] *al [2])); break; } // Any useful operations } CloseHandle(mythread); printf("After scaling vector a1= (%d, %d, %d) ", a1[0], a1[1], a1[2]) printf("\nLength of a1=%.2f\n", vec_len); printf("\n Thread terminated \n"); getchar(); return 0; } | |
In this program, the main process uses the auxiliary thread mythread . This thread computes the new coordinates of the 3D vector. The main thread waits for mythread to complete computation and then computes the length of the vector with the statement
vec_len = sqrt ((double) (a1 [0] *al [0] + a1 [1] *al [1] + a1 [2] *al [2]))
The window of the program is shown in Fig. 11.1.
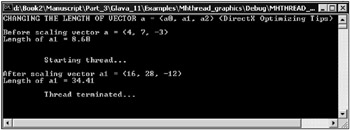
Fig. 11.1: Window of a program demonstrating operations on vectors
The program can be improved by optimizing a few fragments of the code that are related to mathematical calculations. First, the computation in the thread function can be simplified if the assembler is used. The function
void myFunc(LPVOID k1) { for (i1 = 0;i1 < 4; il++) al [il] = (int)kl*al[il]; } can be rewritten in the assembler as follows :
void myFunc(LPVOID*) { _asm { lea ESI, a1 lea EDI, c1 mov ECX, 3 sub ESI, 4 next: add ESI, 4 fild DWORD PTR [ESI] fimul DWORD PTR c1 fistp DWORD PTR [ESI] dec ECX jnz next } } For optimization, it is best to use a mathematical coprocessor or one of the extensions (MMX or SSE). The source code of the modified program is shown in Listing 11.2.
| |
// OPTIMIZING_VECTOR_OPERATIONS.cpp : Defines the entry point for the // console application. #include "stdafx.h" #include <windows . h> #include <math.h> int i1; int a1[4] = {4, 1, 3}; // Size of vector = sqrt ((a1a0) * (a1a0) + .) const int c1 = 4; void myFunc(LPVOID k1) { _asm { lea ESI, a1 lea EDI, c1 mov ECX, 3 sub ESI, 4 next: add ESI, 4 fild DWORD PTR [ESI] fimul DWORD PTR c1 fistp DWORD PTR [ESI] dec ECX jnz next } } int _tmain(int argc, _TCHAR* argv[]) { HANDLE mythread ; DWORD mythread_id; double vec_len; printf ("MOD. VARIANT VECTOR OPERATIONS with a = (a0, a1, a2) (DirectX Tips)\n") ; printf ("\nBefore scaling vector a = (%d, %d, %d)\n", a1[0], a1[1], a1[2]; vec_len = sqrt ((double) (a1 [0] *a1 [0]+a1 [1] *a1 [1]+a1 [2] *a1 [2])); printf("\Length of a1 = %.2f\n", vec_len); printf("\n\n Starting thread \n\n"); mythread = CreateThread(NULL,0, (PTHREAD_START_ROUTINE)myFunc, (LPVOID)(4), 0, &mythread_id); while(true) { if (WaitForSingleObject(mythread, 0) == WAIT_OBJECT_0) { vec_len = sqrt ((double) (a1 [0] *a1 [0]+a1 [1] *a1 [1]+a1 [2]*a1 [2])) ; break; } // any useful operations } CloseHandle(mythread); printf("After scaling vector a1 = (%d, %d, %d)", a1[0]f a1[1]f a1[2]) printf("\nLength of a1 = %.2f\n", vec_len); printf("\n Thread terminated \n"); getchar(); return 0; } | |
Further improvement of the program code can be done using the MMX extension assembly commands. They can be used to optimize the vector scaling code. The source code of the program is shown in Listing 11.3.
| |
// OPTIMIZING_VECTOR_OPERATIONS.cpp : Defines the entry point for the // console application. #include "stdafx.h" #include <windows.h> #include <math.h> int i1; int a1[4] = {4, 7, 3, 0}; int c1[4] = {4,4,4,4}; void myFunc(LPVOID*) { _asm { mov ECX, 3 lea ESI, a1 sub ESI, 4 next: add ESI, 4 pxor mm0, mm0 movd mm0, DWORD PTR [ESI] packssdw mm0, mm0 pxor mm1, mm1 movd mm1, DWORD PTR c1 packssdw mm1, mm1 pmaddwd mm0 , mm1 movd DWORD PTR [ESI], mm0 dec ECX jnz next emms }; } int _tmain(int argc, _TCHAR* argv[]) { HANDLE mythread ; DWORD mythread_id; double vec_len; printf("MOD. VARIANT VECTOR OPERATIONS with a = (a0, a1, a2) (DirectX Tips)\n") ; printf("\nBefore scaling vector a = (%d, %d, %d)\n", a1[0], a1[1], a1[2]); vec_len = sqrt ((double) (a1[0] *a1[0] +a1[1] *a1[1] +a1[2] *a1[2])) ; printf("\Length of a1 = %.2f\n", vec_len) ; printf("\n\n Starting thread. .. \n\n); mythread=CreateThread(NULL, 0, (PTHREAD_START_ROUTINE)myFunc, (LPVOID)(4), 0, &mythread_id); while (true) { if (WaitForSingleObject (mythread, 0) == WAIT_OBJECT_0) { vec_len = sqrt ((double) (a1[0] *a1[0] + a1[1] *a1[1] + a1[2] *a1[2])); break; } // Any useful operations } CloseHandle (mythread) ; printf("After scaling vector a1 = (%d, %d, %d) ", a1[0], a1[1], a1[2]) printf("\nLength of a1 = %.2f\n", vec_len) ; printf("\n Thread terminated \n") ; getchar(); return 0; } | |
In the examples above, the statement
if (WaitForSingleObject (mythread, 0) == WAIT_OBJECT_0)
is used, in which a WIN API function, WaitForSingleObject , plays an important role. This function waits for setting a signal by the mythread thread. If the signal is not set, the function immediately passes control to the next program statement. Such a design makes it possible to run several threads without decreasing performance.
The window of the program is shown in Fig. 11.2.
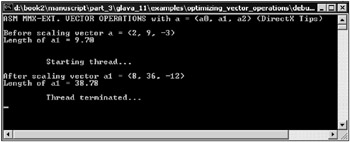
Fig. 11.2: Window of the program demonstrating the use of the MMX extension for operations on vectors
When developing multimedia applications, special DirectX function libraries are widely used. Combining the assembler with DirectX functions makes it possible to develop high-performance applications. Although the assembler interface to DirectX functions has a few distinct features, it is quite similar to common function calls.
EAN: 2147483647
Pages: 50