Inline Assembler and MMX Extension
The next important topic we will address is the use of the inline assembler for optimization of applications that use Intel Single Instruction Multiple Data (SIMD) extensions. In practice, SIMD is implemented as two interrelated data processing technologies:
-
MultiMedia eXtensions (MMX) technology used for effectively processing 64-bit integer data
-
Streaming SIMD Extensions (SSE) technology used for effectively processing 128-bit floating-point data
Visual C++ .NET 2003 supports these technologies. Chapter 1 concentrated on theoretical issues of using SIMD; now, we will discuss practical aspects of using this technology. SIMD is used when developing the following types of applications:
-
Audio signal coding, decoding, and processing
-
Speech recognition
-
Video signal processing and capturing
-
Work with 3D graphics
-
Work with 3D sound
-
CAD/CAM
-
Cryptography
Programming MMX and SSE requires fundamentally new approaches in comparison to developing classic programs. One of the approaches involves vectorization, or transformation, of sequentially executed code to code executed in parallel. The main advantage of the SIMD architecture is that much of computation can be done simultaneously on several operands, and this is used in code vectorization.
Using the assembler in the SIMD extensions has two advantages:
-
Possibility of writing compact and fast code in crucial segments of an application
-
Highly effective coding with special assembly instructions for the SIMD extensions
First, we will look at operations using MMX extension. Despite the wide use of MMX, practical examples of code with detailed explanations are scarce . Microsoft s documentation provides little information on using MMX in application development. Before demonstrating the possibilities of the C++ .NET inline assembler concerning optimization of MMX applications, it is necessary to understand how this technology is implemented.
Before developing programs supporting MMX extension, make sure that the processor supports it. For this purpose, you can use the cpuid assembly command. Before executing this command, put a one to the EAX register. After the command is executed, check the 23rd bit in the EDX register to confirm that the processor supports MMX. If this bit is equal to one, it does. The simplest console application that checks this is shown in Listing 10.8.
| |
// MMX_CPUID_TEST.cpp : Defines the entry point for the console // application #include stdafx.h int _tmain(int argc, _TCHAR* argv[]) { bool supMMX = true; _asm { mov supMMX, 1 mov EAX, 1 cpuid test EDX, 0x800000 jnz sup mov supMMX, 0 sup: }; if (supMMX)printf("MMX is supported!\n"); else printf("MMX not supported!\n"); getchar(); return 0; }; | |
To execute SIMD (MMX or SSE) operations, C++ .NET uses so-called intrinsics . These functions have the following syntax:
_mm_<operation>_<suffix>
where < operation > is the name of operation (such as add for addition or sub for subtraction). The suffix indicates data, on which the operation is done. The first two letters of the suffix indicate whether the data are packed (the letter p ), packed with an extension ( ep ), or of a scalar type ( s ). The rest of the letters in the suffix indicate the data type:
-
s ”an ordinary-precision floating-point variable
-
d ”a double-precision floating-point variable
-
i128 ”a 128-bit signed integer
-
i64 ”a 64-bit signed integer
-
u64 ”a 64-bit unsigned integer
-
i32 ”a 32-bit signed integer
-
u32 ”a 64-bit unsigned integer
-
i16 ”a 16-bit signed integer
-
u16 ”a 16-bit unsigned integer
-
i8 ”a 8-bit signed integer
-
u8 ”a 8-bit unsigned integer
The intrinsics are similar to common C++ functions. They operate with 64-bit integers. The operations can be performed on packed bytes ( 8 — 8 ), words ( 16 — 4 ), double words ( 32 — 2 ), or a quadruple word ( 64 — 1 ). Regardless of the method of processing a 64-bit value, the _m64 notation is used in C++ .NET. The intrinsics are classified into a few main groups:
-
General support functions. These are functions of moving, packing, and unpacking integer data.
-
Packed-arithmetic functions. These are addition, subtraction, and multiplication of integers. It is easy to understand why division is missing from this list since the result of division is generally a real number.
-
Shift functions that logically shift operands left or right to a certain number of positions .
-
Logical functions ( AND, OR, and XOR ) that perform logical operations.
-
Comparison functions that compare operands.
-
Set functions that set bytes, words, and double words in 64-bit operands.
Intrinsics allow you to increase application performance significantly. They are all built using assembly instructions, but their code is redundant for convenience of use.
Not all intrinsics use MMX registers directly but, rather, take one or two 64-bit memory operands. On one hand, this is convenient because it saves you from learning the MMX architecture. On the other hand, it hampers optimization of computational algorithms. Now, we will examine the main idea by using an example of the int_mm_cvtsi64_si32 (__m64 m) function. It converts 32 low order bits of a 64-bit variable to an integer. Consider the following fragment of code:
int i1; __m64 msres; ... i1 = _mm_cvtsi64_si32 (msres); ...
The disassembled code of this fragment could be as follows :
00411C9D movq mm0, mmword ptr [msres] 00411CA4 movd eax, mm0 00411CA7 mov ecx, dword ptr [i1] 00411CAD mov dword ptr [ecx], eax
The last three commands of this code can be substituted with one:
movd DWORD PTR i1, mm0
Moreover, if you use the movd and movq assembly commands, which work directly with MMX registers, you will be able to avoid using intermediate 64-bit variables (in our case, msres ).
Many programmers know little about using MMX extensions in practice. This is why we provide examples both in an assembly version and in a version with C++ .NET intrinsics.
As noted in Chapter 1 , MMX extension makes it possible to operate with integer data in parallel. A threading model of data processing facilitates optimizing operations in multimedia applications, programs that process long sequences of characters and numbers , and in sort and search operations. Since operations with data are executed in MMX instructions in parallel, the commands can be executed in much less processor time.
As an example, suppose you want to substitute each byte in an 8-byte character sequence with this byte s value increased by two. The length of 8 bytes is taken for simplicity s sake. First, develop a console application that uses intrinsics. The source code of the application is shown in Listing 10.9.
| |
// MMX_2_ADD_BYTES.cpp : Defines the entry point for the console // application #include stdafx.h #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { unsigned char s1[9] = ABCDEFGH"; unsigned char s2[9] = {02, 02, 02, 02, 02, 02, 02, 02}; unsigned char sres[9]= " "; unsigned char* psres=sres; __m64 ms1, ms2, msres; ms1 = _mm_set_pi8 (s1[7], s1[6], s1[5], s1[4], s1[3], s1[2], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2[7], s2[6], s2[5], s2[4], s2[3], s2[2], s2[1], s2[0]); msres = _mm_adds_pu8 (ms1, ms2) ; for (int cnt = 0; cnt < 8; cnt++) { *psres = (char)_mm_cvtsi64_si32 (msres); psres++; msres = _mm_srli_si64 (msres, 8); }; _mm_empty(); printf("USING INTRINSICS IN MMX : PACKED ADDING OF BYTES \n\n"); printf(" Before operation: %s\n, s1); printf(" After operation (+2): %s\n, sres); getchar(); return 0; } | |
To use intrinsics of the MMX extension, be sure to include the mmintrin.h header file (the corresponding line is in bold) that contains declarations of intrinsics and variables. This program declares two 8-character strings ( s1 and s2 ) and the sres string for the result of addition of packed bytes. For intermediate results of conversions and computation, three 64-bit variables of the __m64 type are used: ms1, ms2, and msres . Note that the type identifier contains two underscore characters!
To execute operations with 64-bit values, the s1 and s2 strings are copied to ms1 and ms2 with two _mm_set_pi8 commands. Then the _mm_adds_pu8 instruction performs bytewise addition of the ms1 and ms2 variables, and the result is put to the msres variable. The _mm_adds_pu8 intrinsic adds 8-bit unsigned values, and this is exactly what you need.
Be very careful. Before the for loop is executed, the msres variable contains a 64-bit value. However, you want to obtain and display an 8-byte string sres . Therefore, you should extract eight bytes from the 64-bit variable and write them to the sres string. C++ .NET misses functions that could do such a conversion. To implement this task, use two intrinsics of the MMX extension:
int _mm_cvtsi64_si32 (__m64 m) __m64 _mm_srli_si64 (__m64 m, int count)
The first of these functions converts 32 low order bits to an integer, the other shifts a 64-bit number count positions to the right. To increase performance, Microsoft recommends that programmers use a constant as a bit counter. To extract one byte and write it to an appropriate position in the sres string, use a pointer to this string declared as follows:
unsigned char* psres=sres
One byte can be easily read from the msres variable and written to the sres string with the following statement:
*psres = (char)_mm_cvtsi64_si32 (msres);
To write the next byte to the string, increment the psres pointer and shift the msres variable eight bits to the right. This sequence of operations is implemented in the for loop:
for (int cnt = 0; cnt < 8; cnt++) { *psres = (char)_mm_cvtsi64_si32 (msres); psres++; msres = _mm_srli_si64 (msres, 8); }; After the MMX operations are executed, the _mm_empty() function is called to reset the coprocessor.
The window of this application is shown in Fig. 1 0.4.
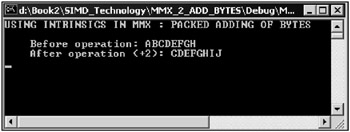
Fig. 10.4: Window of an application that demonstrates C++ intrinsics adding byte sequences
Now look at a disassembled fragment of code that adds two byte arrays (Listing 10.10). The source statements are in bold.
| |
__ m64 ms1, ms2, msres; ms1 = _mm_set_pi8 (sl[7], s1[6], s1[5],s1[4], s1[3], s1[2], s1[1], s1[0]); 00411ABF mov al, byte ptr [s1] 00411AC2 mov byte ptr [ebp198h], al 00411AC8 mov cl, byte ptr [ebp0Fh] 00411ACB mov byte ptr [ebp197h], cl 00411AD1 mov dl, byte ptr [ebp0Eh] 00411AD4 mov byte ptr [ebp196h], dl 00411ADA mov al, byte ptr [ebp0Dh] 00411ADD mov byte ptr [ebp195h], al 00411AE3 mov cl, byte ptr [ebp0Ch] 00411AE6 mov byte ptr [ebp194h], cl 00411AEC mov dl, byte ptr [ebp0Bh] 00411AEF mov byte ptr [ebp193h], dl 00411AF5 mov al, byte ptr [ebp0Ah] 00411AF8 mov byte ptr [ebp192h], al 00411AFE mov cl, byte ptr [ebp9] 00411B01 mov byte ptr [ebp191h], cl 00411B07 movq mm0, mmword ptr [ebp198h] 00411B0E movq mmword ptr [ebp148h], mm0 00411B15 movq mm0, mmword ptr [ebp148h] 00411B1C movq mmword ptr [ms1], mm0 ms2 = _mm_set_pi8 (s2[7], s2[6], s2[5], s2[4], s2[3], s2[2], s2[1], s2[0]); 00411B20 mov al, byte ptr [s2] 00411B23 mov byte ptr [ebp198h], al 00411B29 mov cl, byte ptr [ebp23h] 00411B2C mov byte ptr [ebp197h], cl 00411B32 mov dl, byte ptr [ebp22h] 00411B35 mov byte ptr [ebp196h], dl 00411B3B mov al, byte ptr [ebp21h] 00411B3E mov byte ptr [ebp195h], al 00411B44 mov cl, byte ptr [ebp20h] 00411B47 mov byte ptr [ebp194h], cl 00411B4D mov dl, byte ptr [ebp1Fh] 00411B50 mov byte ptr [ebp193h], dl 00411B56 mov al, byte ptr [ebp1Eh] 00411B59 mov byte ptr [ebp192h], al 00411B5F mov cl, byte ptr [ebp1Dh] 00411B62 mov byte ptr [ebp191h], cl 00411B68 movq mm0, mmword ptr [ebp198h] 00411B6F movq mmword ptr [ebp158h], mm0 00411B76 movq mm0, mmword ptr [ebp158h] 00411B7D movq mmword ptr [ms2], mm0 msres = _mm_adds_pu8 (ms1, ms2); 00411B81 movq mm0, mmword ptr [ms2] 00411B85 movq mm1, mmword ptr [ms1] 00411B89 paddusb mm1, mm0 00411B8C movq mmword ptr [ebp168h], mm1 00411B93 movq mm0, mmword ptr [ebp168h] 00411B9A movq mmword ptr [msres], mm0 for (int cnt = 0; cnt < 8; cnt++) 00411B9E mov dword ptr [cnt], 0 00411BA8 jmp main+189h (411BB9h) 00411BAA mov eax, dword ptr [cnt] 00411BB0 add eax, 1 00411BB3 mov dword ptr [cnt], eax 00411BB9 cmp dword ptr [cnt], 8 00411BC0 jge main+1C3h (411BF3h) { *psres = (char)_mm_cvtsi64_si32 (msres) 00411BC2 movq mm0, mmword ptr [msres] 00411BC6 movd eax, mm0 00411BC9 mov ecx, dword ptr [psres] 00411BCC mov byte ptr [ecx], al psres++; 00411BCE mov eax, dword ptr [psres] 00411BD1 add eax, 1 00411BD4 mov dword ptr [psres], eax msres = _mm_srli_si64 (msres, 8); 00411BDB psrlq mm0, mmword ptr [msres] 00411BD7 movq mm0, 8 00411BDF movq mmword ptr [ebp188h], mm0 00411BE6 movq mm0, mmword ptr [ebp188h] 00411BED movq mmword ptr [msres], mm0 }; 00411BF1 jmp main+17Ah (411BAAh) 00411BF3 emms | |
This disassembled fragment of code allows us to draw a few important conclusions. First, all the intrinsics use the MMX registers in one way or another. Second, when exchanging data between the MMX registers and 64-bit operands in the memory, the movq (more rarely, movd ) command is used. Since the MMX registers are not directly available to you when working with intrinsics, the assembly version of the MMX extension operations can increase performance.
Now, we will consider the assembly version of the same task. Replace the MMX extension intrinsics with the assembly commands and slightly modify the s1 and s2 strings. The source code of the application will become much simpler (Listing 10.11).
| |
// ADD_8_BYTES_MMX_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { unsigned char s1 [9] = "12345678"; unsigned char s2 [9] = {01, 01, 01, 01, 01, 01, 01, 01}; unsigned char sres[9]= " "; _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 paddd mm0, mm1 movq QWORD PTR sres, mm0 emms }; printf("USING ASSEMBLER IN MMX: PACKED ADDING OF BYTES \n\n"); printf(" Before operation: %s\n", s1); printf(" After operation (+2): %s\n", sres); getchar(); return 0; } | |
Note that all computation is done in the assembly block. Listing 10.12 shows the disassembled code of the example. As you see, the code is actually optimum when assembly commands are used.
| |
_asm { movq mm0, qword ptr s1 00411AA7 movq mm0, mmword ptr [s1] movq mm1, qword ptr s2 00411AAB movq mm1, mmword ptr [s2] paddd mm0 mm1 00411AAF paddd mm0, mm1 movq qword ptr sres, mm0 00411AB2 movq mmword ptr [sres], mm0 emms 00411AB6 emms }; | |
The window of the application is shown in Fig. 10.5.
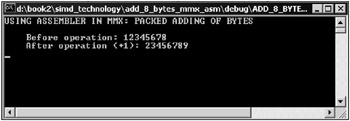
Fig. 10.5: Window of an application that adds two bytes with MMX extension assembly commands
Develop an application that adds together the elements of two integer arrays in pairs and puts the result to a third array. All three arrays have the same size . Develop three variants of such an application, each being a console application. Let the first program add the array elements with common C++ statements, the second program use MMX extension functions, and the third use MMX assembly instructions. The common variant is shown in Listing 10.13.
| |
// MMX_2_1.cpp : Defines the entry point for the console application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int al[] = {23, 12, 45, 9, 44, 16, 7, 19, 1, 14, 2}; int b1[] = {12, 70, 12, 33, 12, 35, 29, 33, 99, 5, 7}; int ires[16]; int isize = sizeof(al)/4; for (int cnt = 0; cnt < isize; cnt++) ires[cnt] = al[cnt] + b1[cnt]; printf("al: "); for (int cnt = 0; cnt < isize; cnt++) printf("%d ", al[cnt]); printf("\nb1: "); for (int cnt = 0; cnt < isize; cnt++) printf("%d ", b1[cnt]); printf("\n\n); for (int cnt = 0; cnt < isize; cnt++) printf(ires [%d] = %d\n, cnt, ires[cnt]); getchar(); return 0; }; | |
You can upgrade this application with the C++ .NET intrinsics for the MMX extension. The source code of a modified program is shown in Listing 10.14.
| |
// MMX_ADD_ARRAYS_INTRINSICS.cpp : Defines the entry point for the // console application #include stdafx.h #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { int al[] = {23, 12, 45, 9, 44, 16, 7, 19, 1, 14, 2}; int* pa1 = a1; int b1[] = {12, 70, i2, 33, 12, 35, 29, 33, 99, 5, 7}; int* pb1 = b1; int ires [16]; int* pires = ires; __m64 ma1, mb1, mires; int isize = sizeof (al) /4; for (int cnt = 0; cnt < isize; cnt++) { ma1 = _mm_cvtsi32_si64 (*pa1); mb1 = _mm_cvtsi32_si64 (*pb1); mires = _mm_add_pi32 (ma1, mb1); *pires = _mm_cvtsi64_si32 (mires); pa1++; pb1++; pires++; }; printf ("al: "); for (int cnt = 0; cnt < isize; cnt ++) printf ("%d ", a1[cnt]); printf ("\nb1: "); for (int cnt = 0; cnt < isize; cnt ++) printf ("%d ", b1[cnt]); printf ("\n\n"); for (int cnt = 0; cnt < isize; cnt ++) printf ("ires [%d] = %d\n", cnt, ires [cnt]; getchar (); return 0; }; | |
The second version is faster despite the greater number of statements. However, it does not use the possibilities of 64-bit data processing to the full extent because one double word is processed in each iteration. The assembler can help in this situation. The third version of the program uses MMX extension assembly commands to speed up data processing even further. This is shown in Listing 10.15.
| |
// ADD_2_ARRAYS_MMX_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int al[] = {23, 12, 45, 9, 44, 16, 7, 19, 1, 14, 2}; int b1[] = {12, 70, 12, 33, 12, 35, 29, 33, -99, 5, 7}; int ires[16]; bool flag = false; if ((sizeof(al)%8) != 0)flag = true; int isize = sizeof(al)/4; int qsize=sizeof(a1)/8; _asm { lea ESI, DWORD PTR a1 lea EDI, DWORD PTR b1 lea EDX, DWORD PTR ires sub ESI, 8 sub EDI, 8 sub EDX, 8 mov ECX, DWORD PTR qsize next: add ESI, 8 add EDI, 8 add EDX, 8 movq mm0, QWORD PTR [ESI] movq mm1, QWORD PTR [EDI] paddd DWORD PTR [EDX], mm0 movq mm0, mm1 loop next emms cmp flag, 1 jne ex mov EAX, DWORD PTR [ESI+8] add EAX, DWORD PTR [EDI+8] mov DWORD PTR [EDX+8], EAX ex: }; printf("a1: "); for (int cnt=0; cnt < isize; cnt++) printf("%d ", a1[cnt]); printf("\nb1: "); for (int cnt=0; cnt < isize; cnt++) printf("%d ", b1[cnt]); printf("\n\n"); for (int cnt=0; cnt < isize; cnt++) printf("ires[%d] = %d\n, cnt, ires[cnt]; getchar(); return 0; }; | |
This source code does not need detailed explanations. It declares the qsize variable that is equal to the size of the a1 array divided by eight. In other words, this variable determines the number of quadwords (64 bits each) contained in the array. The flag variable indicates whether there is a 32-bit variable among the 64-bit numbers. Why? The following example provides an explanation. Consider an array of eleven integers. The size of an integer variable is four bytes. For operations with MMX extension, it is desirable that a variable has a size of 64 bits. Then the performance of such operations will be very high. This can be achieved if two integers ( 32 — 2 bits) are processed as one ( 64 — 1 bits). Of eleven integers, you can make up five 64-bit numbers plus one 32-bit number, which should be processed individually.
The flag variable indicates whether there is a 32-bit variable in the array. Now, we will describe the assembly block in more detail. The commands
lea ESI, DWORD PTR a1 lea EDI, DWORD PTR b1 lea EDX, DWORD PTR ires sub ESI, 8 sub EDI, 8 sub EDX, 8 mov ECX, DWORD PTR qsize
load the addresses of the arrays a1, b1, and ires to the registers ESI, EDI, and EDX, respectively. Subtraction of an eight from the values put to the registers is done for convenience in the use of the loop loop. The number of 64-bit operands that should be processed is put to the ECX register. These operands are added with the following commands:
movq mm0, QWORD PTR [ESI] movq mm1, QWORD PTR [EDI] paddd mm0, mm1
The result is put at the address stored in the EDX register:
movq DWORD PTR [EDX], mm0
At the beginning of each iteration, the addresses of the next 64-bit variables are put to the registers ESI, EDI, and EDX by adding an eight to the addresses currently stored in the registers:
add ESI, 8 add EDI, 8 add EDX, 8
Then addition is done again. After exiting the loop , the value of the flag variable is checked. If flag is equal to zero, there is no 32-bit remainder, and the assembly block can be exited. Otherwise, the 32-bit number should be processed with the following commands:
mov EAX, DWORD PTR [ESI+8] add EAX, DWORD PTR [EDI+8] mov DWORD PTR [EDX+8], EAX
The rest of the code is self-explanatory. The window of the application is shown in Fig. 10.6.
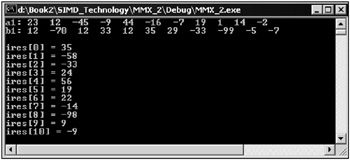
Fig. 10.6: Window of an application that demonstrates addition of the elements of two integer arrays with MMX extension assembly commands
The next group of MMX extension commands that we will discuss includes comparison commands. They can be divided into two groups: common comparison commands (equal / not equal) and value comparison commands (greater than / less than). The comparison commands are executed on packed bytes, words, or double words.
The common comparison commands are pcmeqb, pcmeqw, and pcmeqd ; and the value comparison commands are pcmpgtb, pcmpgtw, and pcmpgtd . The last letter in the command names denotes a byte ( b ), word ( w ), and double word ( d ), respectively.
The commands have the following syntax:
pcmpxxx <operand_1>, <operand_2>
As the first operand, one of the MMX registers ( mm0, mm1, etc.) can be used; and as the second operand, either a MMX register or a 64-bit memory operand can be used. The result of a comparison operation is a zero or non-zero byte, word, or double word.
The common comparison operations return zero results if the bytes, words, or double words being compared are not equal. Ones are returned if the bytes, words, or double words being compared are equal. The value operations return ones if the bytes, words, or double words of the first operand are greater than those of the second.
Consider an example. Suppose you want to check two character strings for equality. For simplicity s sake, use 8-byte strings. Develop two variants: one using C++ .NET intrinsics, the other using the inline assembler.
The source code of a console application that uses intrinsics is shown in Listing 10.16.
| |
// CMP_8_BYTES_INTRINSICS.cpp : Defines the entry point for the console // application #include "stdafx.h" #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires [32]; _ _m64 ms1, ms2, msres; printf("Comparison 2 strings with MMX Intrinsics\n\n"); while(true) { memset(s1, ' // CMP_8_BYTES_INTRINSICS.cpp : Defines the entry point for the console // application #include "stdafx.h" #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires [32]; _ _m64 ms1, ms2, msres; printf("Comparison 2 strings with MMX Intrinsics\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset (ires, '\0' , 16); char* pires = ires; printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2: "); scanf("%s", s2); ms1 = _mm_set_pi8 (s1[7], s1[6], s1[5], s1[4], s1[3], s1[2 ], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2 [7], s2 [6], s2 [5], s2 [4], s2[3], s2 [2], s2 [1], s2 [0]); msres = _mm_cmpeq_pi8 (ms1, ms2); *(int*) pires = _mm_cvtsi64_si32 (msres); msres =_mm_srli_si64 (msres, 32) ; pires = pires+4; *(int*)pires = _mm_cvtsi64_si32 (msres); _mm_empty (); for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] == 0) { printf("s1 not equal s2 !\n"); break; } }; if (cnt == 8)printf("s1=s2 !\n") }; return 0; } ', 16); memset(s2, ' // CMP_8_BYTES_INTRINSICS.cpp : Defines the entry point for the console // application #include "stdafx.h" #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires [32]; _ _m64 ms1, ms2, msres; printf("Comparison 2 strings with MMX Intrinsics\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset (ires, '\0' , 16); char* pires = ires; printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2: "); scanf("%s", s2); ms1 = _mm_set_pi8 (s1[7], s1[6], s1[5], s1[4], s1[3], s1[2 ], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2 [7], s2 [6], s2 [5], s2 [4], s2[3], s2 [2], s2 [1], s2 [0]); msres = _mm_cmpeq_pi8 (ms1, ms2); *(int*) pires = _mm_cvtsi64_si32 (msres); msres =_mm_srli_si64 (msres, 32) ; pires = pires+4; *(int*)pires = _mm_cvtsi64_si32 (msres); _mm_empty (); for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] == 0) { printf("s1 not equal s2 !\n"); break; } }; if (cnt == 8)printf("s1=s2 !\n") }; return 0; } ', 16); memset(ires, ' // CMP_8_BYTES_INTRINSICS.cpp : Defines the entry point for the console // application #include "stdafx.h" #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires [32]; _ _m64 ms1, ms2, msres; printf("Comparison 2 strings with MMX Intrinsics\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset (ires, '\0' , 16); char* pires = ires; printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2: "); scanf("%s", s2); ms1 = _mm_set_pi8 (s1[7], s1[6], s1[5], s1[4], s1[3], s1[2 ], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2 [7], s2 [6], s2 [5], s2 [4], s2[3], s2 [2], s2 [1], s2 [0]); msres = _mm_cmpeq_pi8 (ms1, ms2); *(int*) pires = _mm_cvtsi64_si32 (msres); msres =_mm_srli_si64 (msres, 32) ; pires = pires+4; *(int*)pires = _mm_cvtsi64_si32 (msres); _mm_empty (); for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] == 0) { printf("s1 not equal s2 !\n"); break; } }; if (cnt == 8)printf("s1=s2 !\n") }; return 0; } ' , 16); char* pires = ires; printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2: "); scanf("%s", s2); ms1 = _mm_set_pi8 (s1[7], s1[6], s1[5], s1[4], s1[3], s1[2 ], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2 [7], s2 [6], s2 [5], s2 [4], s2[3], s2 [2], s2 [1], s2 [0]); msres = _mm_cmpeq_pi8 (ms1, ms2); *(int*) pires = _mm_cvtsi64_si32 (msres); msres =_mm_srli_si64 (msres, 32) ; pires = pires+4; *(int*)pires = _mm_cvtsi64_si32 (msres); _mm_empty (); for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] == 0) { printf("s1 not equal s2 !\n"); break; } }; if (cnt == 8)printf("s1=s2 !\n") }; return 0; } | |
The operation of comparison of arrays (not only character arrays) involves comparing individual elements, moving the address counter to the next elements, and so on until the end of the array is encountered . MMX technology allows you to compare several bytes, words, or double words simultaneously. Comparison of eight bytes is done with the following commands:
ms1 = _mm_set_pi8 (s1 [7], s1[6], s1[5], s1 [4], s1 [3], s1 [2], s1[1], s1[0]); ms2 = _mm_set_pi8 (s2 [7], s2[6], s2[5], s2 [4], s2 [3], s2 [2], s2[1], s2[0]); msres = _mm_cmpeq_pi8 (ms1, ms2);
The first two statements put eight bytes from the strings s1 and s2 to 64-bit variables ms1 and ms2 . The comparison proper is done with the last statement, and the result is stored in the msres variable. Then the eight bytes of this variable are written to the ires string:
*(int*)pires = _mm_cvtsi64_si32 (msres); msres =_mm_srli_si64 (msres, 32); pires = pires+4; *(int*)pires = _mm_cvtsi64_si32 (msres);
The window of the application is shown in Fig. 10.7.
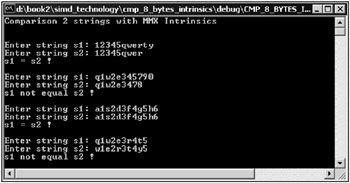
Fig. 10.7: Window of an application that compares two strings with MMX extension intrinsics
The other variant of the application that uses MMX assembly instructions looks much simpler. Its source code is shown in Listing 10.17.
| |
// CMP_8_BYTES_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32 ]; printf("Comparison 2 strings with MMX assembly instructions\n\n"); while(true) { memset(s1, ' // CMP_8_BYTES_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32 ]; printf("Comparison 2 strings with MMX assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf ("Enter string s2: ") ; scanf ("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires [cnt] == 0) { printf ("s1 not equal s2 !\n"); break; } }; if (cnt == 8) printf ("s1 = s2 !\n") }; return 0; }; ', 16); memset(s2, ' // CMP_8_BYTES_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32 ]; printf("Comparison 2 strings with MMX assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf ("Enter string s2: ") ; scanf ("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires [cnt] == 0) { printf ("s1 not equal s2 !\n"); break; } }; if (cnt == 8) printf ("s1 = s2 !\n") }; return 0; }; ', 16); memset(ires, ' // CMP_8_BYTES_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32 ]; printf("Comparison 2 strings with MMX assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf ("Enter string s2: ") ; scanf ("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires [cnt] == 0) { printf ("s1 not equal s2 !\n"); break; } }; if (cnt == 8) printf ("s1 = s2 !\n") }; return 0; }; ', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf ("Enter string s2: ") ; scanf ("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires [cnt] == 0) { printf ("s1 not equal s2 !\n"); break; } }; if (cnt == 8) printf ("s1 = s2 !\n") }; return 0; }; | |
Comparison is done in the _asm block. The contents of two strings are copied to MMX registers, and then the bytewise comparison of the contents of the registers is done with the command pcmpeqb mm0, mm1 . The result is stored in the ires string with the command movq QWORD PTR ires, mm0 . The obtained result is checked in the for loop.
The window of the application is shown in Fig. 10.8.
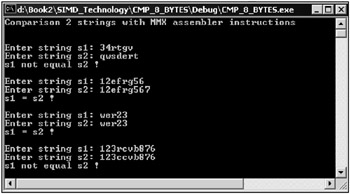
Fig. 10.8: Window of an application that compares two strings with MMX extension assembly commands
The following example compares eight bytes located on the same positions in two strings, s1 and s2 . The comparison is done according to the greater than / less than principle with the pcmpgtb assembly command. If a byte of the s1 string is greater than the corresponding byte of the s2 string, ones are written to the corresponding byte of the ires string. Otherwise, zeroes are written to that byte. The result of comparison is displayed.
The source code of the application is shown in Listing 10.18.
| |
// CMPGT_8_ASM_MMX.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32]; printf("Using PCMPGTB in string comparison with assembly instructions\n\n"); while(true) { memset(s1, ' // CMPGT_8_ASM_MMX.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32]; printf("Using PCMPGTB in string comparison with assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2 : "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpgtb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] != 0 —0) printf ("s1[%d] > s2 [%d]\n", cnt, cnt); if (ires [cnt] == 0 —0) printf ("s1 [%d] <= s2 [%d]\n", cnt, cnt); }; }; return 0; }; ', 16); memset(s2, ' // CMPGT_8_ASM_MMX.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32]; printf("Using PCMPGTB in string comparison with assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2 : "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpgtb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] != 0 —0) printf ("s1[%d] > s2 [%d]\n", cnt, cnt); if (ires [cnt] == 0 —0) printf ("s1 [%d] <= s2 [%d]\n", cnt, cnt); }; }; return 0; }; ', 16); memset(ires, ' // CMPGT_8_ASM_MMX.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32 ]; char ires[32]; printf("Using PCMPGTB in string comparison with assembly instructions\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2 : "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpgtb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] != 0 —0) printf ("s1[%d] > s2 [%d]\n", cnt, cnt); if (ires [cnt] == 0 —0) printf ("s1 [%d] <= s2 [%d]\n", cnt, cnt); }; }; return 0; }; ', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("Enter string s2 : "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpgtb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt ++) { if (ires [cnt] != 00) printf ("s1[%d] > s2 [%d]\n", cnt, cnt); if (ires [cnt] == 00) printf ("s1 [%d] <= s2 [%d]\n", cnt, cnt); }; }; return 0; }; | |
The window of the application is shown in Fig. 10.9.
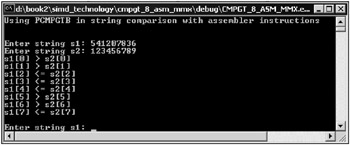
Fig. 10.9: Window of an application that does a bytewise comparison of strings with MMX assembly commands and displays the result
The assembly comparison commands make it possible to implement quick algorithms to search for elements in arrays. Consider this example. Suppose you want to find a character in a string. The search can be done with common assembly commands, but MMX instructions allow you to compare several bytes simultaneously, so the performance gain is significant. Take the program in Listing 10.17 as a sample for this application, but make a few changes in the source code. The resulting source code is shown in Listing 10.19.
| |
// FIND_CHAR_PCMPEQB_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32]; char c1 = 'r'; char ires[32 ]; printf("Find char with PCMPEQB instruction\n\n") while(true) { memset(s1, ' // FIND_CHAR_PCMPEQB_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32]; char c1 = 'r'; char ires[32 ]; printf("Find char with PCMPEQB instruction\n\n") while(true) { memset(s1, '\0', 16); memset(s2, c1, 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("Character %c found in s1 !\n", c1); break; } }; if (cnt = 8)printf("Character %c not found in s1 !\n", c1); }; return 0; } ', 16); memset(s2, c1, 16); memset(ires, ' // FIND_CHAR_PCMPEQB_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1[32]; char s2 [32]; char c1 = 'r'; char ires[32 ]; printf("Find char with PCMPEQB instruction\n\n") while(true) { memset(s1, '\0', 16); memset(s2, c1, 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("Character %c found in s1 !\n", c1); break; } }; if (cnt = 8)printf("Character %c not found in s1 !\n", c1); }; return 0; } ', 16); printf("\nEnter string s1: "); scanf("%s", s1); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pcmpeqb mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("Character %c found in s1 !\n", c1); break; } }; if (cnt = 8)printf("Character %c not found in s1 !\n", c1); }; return 0; } | |
The necessary changes are in bold. Suppose you want to find the ˜ r character in the s1 string. To be able to use the pcmeqb command, fill the s2 string with this character:
memset(s2, c1, 16);
If there is a letter r in s1 , at least one of the first eight bytes of the ires string that contains the result will be non-zero.
The window of the application that searches for an element in a string is shown in Fig. 10.10.
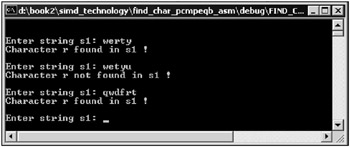
Fig. 10.10: Window of an application that searches for an element in a character string with the MMX extension assembler
The next example, which focuses on the use of the inline assembler in MMX applications, is more complicated. In this example, we will demonstrate the use of addition, packing, and extracting commands for simultaneous pairwise addition of two integers stored in two arrays. For simplicity s sake, only positive integers are considered . Name the initial arrays a1 and b1 and the resulting array c1 . The source code of the console application is shown in Listing 10.20.
| |
// PACK_n_ADD_2_in_4WORD.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int a1[4] = {12, 1, 34, 17}; int b1[4] = {17, 7, 4, 33}; int c1[4]; printf(" a1: "); for (int cnt = 0; cnt < 4; cnt++) printf("%d\t", a1[cnt]); printf("\n b1: "); for (int cnt = 0; cnt < 4; cnt++) printf("%d\t", b1[cnt]); _asm { movq mm0, QWORD PTR a1 movq mm1, QWORD PTR a1+8 packssdw mm0, mm1 movq mm1, QWORD PTR b1 movq mm2, QWORD PTR b1+8 packssdw mm1, mm2 paddw mm0, mm1 lea ESI, c1 pextrw EDI, mm0, 0 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 1 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 2 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 3 mov DWORD PTR [ESI], EDI add ESI, 4 emms }; printf("\n\n c1: \n"); for (int cnt = 0; cnt < 4; cnt++) printf(" a1[%d] + b1[%d] = %d\n", cnt, cnt, c1[cnt]); getchar(); return 0; }; | |
We will analyze the source code of this example. First, look at the following commands of the assembly block:
movq mm0, QWORD PTR a1 movq mm1, QWORD PTR a1+8 packssdw mm0, mm1
The first two commands move two integers from the a1 array to 64-bit registers mm0 and mm1 . After executing these commands, each of the registers will contain two 32-bit integers ( 32 — 2 ). The current task is to add simultaneously the integers in the a1 array to the integers in the a2 array. This is why the numbers in the registers mm0 and mm1 are packed, and the result is written to the mm0 register. The essence of packing is in decreasing the size of the elements by half. In our case, two 32-bit numbers from the mm0 and mm1 registers can be packed into four 16-bit numbers, and the result can be put to the mm0 register. Packing numbers allows you to perform arithmetic and logic operations simultaneously on twice as many elements as without packing. This improves the performance of an application as a whole. Keep in mind that operations on packed numbers can cause overflow, so use these commands with care.
Returning to our example, the contents of the mm0 and mm1 MMX registers are packed with the packssdw mm0 , mm1 command.
The next three commands do similar operations on the first two elements of the b1 array:
movq mm1, QWORD PTR b1 movq mm2, QWORD PTR b1+8 packssdw mm1, mm2
Note that the mm1 and mm2 MMX registers are used for operations on the elements of the b1 array. The mm0 register cannot be used because it contains four packed 16-bit numbers from the a1 array.
After packing the array elements, four words contained in the mm0 and mm1 registers can be added with the paddw mm0 , mm1 command. The result is put into the mm0 MMX register.
Now, it is necessary to extract four sums from the mm0 register and write them to the first four elements of the c1 array. For this purpose, one of additional MMX commands that appeared in Pentium III is used. The pextrw command extracts one of four packed words from the source operand into a 32-bit common register. The extracted operand is put to the low-order word of the register, and the high-order word is zeroed. The position of the extracted operand is determined by a mask containing a value from 0 to 3. A minor inconvenience of this command is that the mask must be a constant, which does not allow use of the command in loops . This command has no analogs among the Visual C++ .NET intrinsics (at least, at the time of this publication).
As a destination, the EDI register is used, into which the 16-bit sum is put. To write to the c1 array, the ESI register containing the array address is used. The lea ESI , c1 command loads the address of the first array element into the ESI register. The groups of commands that extract 16-bit numbers into an array are similar to each other, so here we will give only a code fragment for operations with the zero element of the mm0 register:
pextrw EDI, mm0, 0 mov DWORD PTR [ESI], EDI add ESI, 4
The first two commands of this fragment write a number to a particular position in the c1 array, and the add ESI , 4 command moves the pointer to the next element of the array.
The rest of the source code of the program is simple and does not require further explanation.
The window of the application is shown in Fig. 10.11.
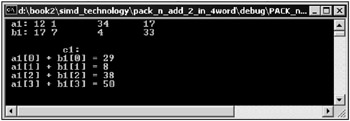
Fig. 10.11: Window of an application that demonstrates manipulations with packed data with the MMX extension assembler
In the previous example, we used the pextrw command, one of additional MMX extension commands of Pentium III and higher. Four more additional commands make it possible to increase the computational power of C++ .NET applications. These commands allow you to extract minimum or maximum values of each pair of packed elements. The elements can be unsigned bytes or signed words. These commands are very effective when implementing algorithms for sort, search, and bit fields processing in multimedia applications. We will give examples of programs that use the pmaxsw and pminsw commands.
Use the source code of the previous example and make a few changes. This application will display the maximum of two numbers located at corresponding positions in the a1 and b1 arrays. The pmaxsw command is in bold. The source code of the application is shown in Listing 10.21.
| |
// MAX_FROM_PAIR_ARRAYS. cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int a1[4] = {9, 1, 34, 1}; int b1[4] = [1, 5, 79, 3}; int c1[4]; printf(" a1: "); for (int cnt = 0; cnt < 4; cnt++) printf("%d\t", a1[cnt]); printf("\n b1: "); for (int cnt = 0; cnt < 4; cnt++) printf("%d\t", b1[cnt]); _asm { movq mm0, QWORD PTR a1 movq mm1, QWORD PTR a1+8 packssdw mm0, mm1 movq mm1, QWORD PTR b1 movq mm2, QWORD PTR b1+8 packssdw mm1, mm2 pmaxsw mm0, mm1 lea ESI, c1 pextrw EDI, mm0, 0 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 1 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 2 mov DWORD PTR [ESI], EDI add ESI, 4 pextrw EDI, mm0, 3 mov DWORD PTR [ESI], EDI add ESI, 4 emms }; printf ("\n\n c1: \n") ; for (int cnt = 0; cnt < 4; cnt++) printf ("max of a1[%d] and b1[%d] = %d\n", cnt, cnt, c1[cnt]), getchar (); return 0; }; | |
The pmaxsw command uses the mm0 and mm1 MMX registers as operands and stores the result in the mm0 register. The rest of the source code was discussed in the previous example. To find the minimum of two array elements, substitute the pmaxsw mm0 , mm1 command with pminsw mm0 , mm1 . You can do this as an exercise.
The window of the application is shown in Fig. 10.12.
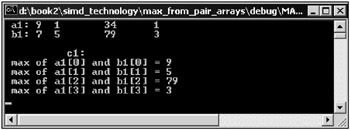
Fig. 10.12: Window of an application that demonstrates a search for maximum elements with the MMX extension inline assembler
Another group of commands widely used in applications includes MMX logical commands. These commands implement logical operations such as AND ( pand ), AND-NOT ( pandn ), OR ( por ), and XOR ( pxor ). A distinct feature of these commands is that they perform logical operations on 64-bit values. These commands were described in Chapter 1 . Now, we will focus on an example that uses the pxor command. With this command, you can implement an algorithm for comparing two character strings. A similar algorithm implemented with the pcmpeqb command was considered earlier, and this example uses pxor .
The source code of this console application is shown in Listing 10.22.
| |
// COMPARE_STR_WITH_PXOR.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires[32]; printf("Comparison of strings with PXOR instruction\n\n"); while(true) { memset(s1, ' // COMPARE_STR_WITH_PXOR.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires[32]; printf("Comparison of strings with PXOR instruction\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("\nEnter string s2: "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pxor mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("\nString s1 not equal s2!", c1); break; } }; if (cnt == 8) printf("\nString s1=s2!", c1); }; return 0; } ', 16); memset(s2, ' // COMPARE_STR_WITH_PXOR.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires[32]; printf("Comparison of strings with PXOR instruction\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("\nEnter string s2: "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pxor mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("\nString s1 not equal s2!", c1); break; } }; if (cnt == 8) printf("\nString s1=s2!", c1); }; return 0; } ', 16); memset(ires, ' // COMPARE_STR_WITH_PXOR.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { char s1 [32]; char s2 [32]; char ires[32]; printf("Comparison of strings with PXOR instruction\n\n"); while(true) { memset(s1, '\0', 16); memset(s2, '\0', 16); memset(ires, '\0', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("\nEnter string s2: "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pxor mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("\nString s1 not equal s2!", c1); break; } }; if (cnt == 8) printf("\nString s1=s2!", c1); }; return 0; } ', 16); printf("\nEnter string s1: "); scanf("%s", s1); printf("\nEnter string s2: "); scanf("%s", s2); _asm { movq mm0, QWORD PTR s1 movq mm1, QWORD PTR s2 pxor mm0, mm1 movq QWORD PTR ires, mm0 emms }; for (int cnt = 0; cnt < 8; cnt++) { if (ires[cnt] != 0) { printf("\nString s1 not equal s2!", c1); break; } }; if (cnt == 8) printf("\nString s1=s2!", c1); }; return 0; } | |
A distinct feature of the pxor command is that if the operands are equal, the result is zero. This feature is used when comparing two strings. The window of the application that compares two strings using this method is shown in Fig. 10.13.
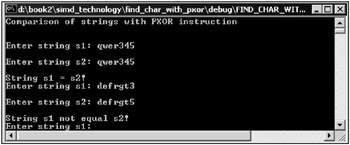
Fig. 10.13: Window of an application that compares character strings with the pxor command
The next group of MMX extension commands we will demonstrate includes multiplication commands. The algorithm they use is different from that of common integer multiplication commands. The size of the result obtained with common multiplication commands is usually twice as large as the size of the operands. The MMX multiplication commands use another multiplication algorithm.
Multiplication is done simultaneously on four 16-bit signed operands. Integer operands can be multiplied with either the pmulhw and pmullw commands or the pmaddwd command. Here, we will demonstrate multiplication of two integers with the pmaddwd command. You can try to develop a version with the pmulhw/pmullw commands on your own.
First, develop a console application that multiplies two integers and displays the result using C++ .NET intrinsics. The source code of this application is shown in Listing 10.23.
| |
// MUL_2_INTS_INTR.cpp : Defines the entry point for the console // application #include "stdafx.h" #include <mmintrin.h> int _tmain(int argc, _TCHAR* argv[]) { int i1, i2; int ires; _ _m64 mi1, mi2, mires; printf ("MULTIPLICATION OF 2 INTS WITH INTRINSICS (MMX_EXT.) \n\n") while (true) { printf ("\nEnter i1: "); scanf("%d", &i1); printf ("Enter i2: "); scanf("%d", &i2); mi1 = _mm_cvtsi32_si64 (i1); mi2 = _mm_cvtsi32_si64 (i2); mi1 = _mm_packs_pi32 (mi1, mi1); mi2 = _mm_packs_pi32 (mi2 , mi 2); mires = _mm_madd_pi16 (mi1, mi 2); ires = _mm_cvtsi64_si32 (mires); printf ("\nil * i2 = %d\n", ires); } return 0; } | |
In this example, the functions _mm_cvtsi32_si64 (i1) and _mm_cvtsi32_si64 (i2) convert 32-bit integers i1 and i2 to the format of 64-bit packed variables mi1 and mi 2 . The i1 and i2 variables are put to 32 low-order bits of mi1 and mi2 , and 32 high-order bits are padded with zeroes. The statements
mi1 = _mm_packs_pi32 (mi1, mi1) ; mi2 = _mm_packs_pi32 (mi2, mi2) ;
pack four double words to four words. The source and destination in each of these functions is the same ( mi1 in the first case and mi2 in the second). These functions are required to multiply the numbers with the statement:
mires = _mm_madd_pi16 (mi1, mi2)
Finally, the statement
ires = _mm_cvtsi64_si32 (mires)
puts the product from mires to ires .
The window of the application is shown in Fig. 10.14.
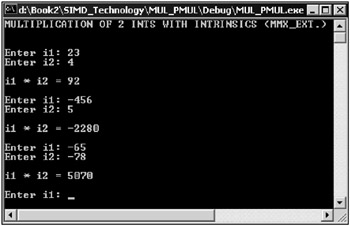
Fig. 10.14: Window of an application that demonstrates multiplication of integers with C++ .NET intrinsics
Another variant of this program that uses the inline assembler requires fewer commands. Its source code is shown in Listing 10.24.
| |
// INT__MUL_ASM.cpp : Defines the entry point for the console // application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int i1, i2; int ires; printf("MULTIPLICATION OF 2 INTS WITH ASM (MMXEXT.)\n\n"); while (true) { printf("\nEnter i1: "); scanf("%d", &i1); printf("Enter i2: "); scanf("%d", &i2); _asm { pxor mm0, mm0 movd mm0, DWORD PTR i1 packssdw mm0, mm0 pxor mm1, mm1 movd mm1, DWORD PTR i2 packssdw mm1, mm1 pmaddwd mm0, mm1 movd DWORD PTR ires, mm0 emms }; printf("\nil * i2 = %d\n", ires); } return 0; } | |
It is easy to understand the assembly block code if you remember that movd is an assembly analog for the _mm_cvtsi32_si64 function, and packssdw and pmaddwd correspond to _mm_packs_pi32 and _mm_madd_pi16 , respectively.
The window of the application is shown in Fig. 10.15.
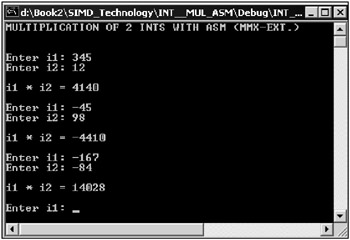
Fig. 10.15: Window of an application that multiplies integers with the MMX extension assembly commands
The next example is a program that computes the absolute value of an integer with a few MMX operations. Here, the commands movd , pxor , and pmaxsw are used; they are already familiar to you. The result is stored in the EDI register with the pextrw command:
pextrw EDI, mm1, 0
The last operand, which is equal to zero, extracts the low order word from the mm1 register and writes it to the low order word of the EDI register. The high order word of the EDI register is zeroed.
The source code of the application is shown in Listing 10.25.
| |
// ABS_INT.cpp : Defines the entry point for the console application #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int i1, modi1; printf(" Calculating the modulus of integer\n\n"); while (true) { printf("\nEnter i1: "); scanf("%d", &i1); _asm { movd mm0, DWORD PTR i1 pxor mm1, mm1 psubw mm1, mm0 pmaxsw mm1, mm0 pextrw EDI, mm1, 0 mov DWORD PTR modil, EDI emms }; printf("Modulus of i1 = %d\n, modil); }; return 0; } | |
The algorithm for finding the absolute value is straightforward. The window of the application that finds the absolute value of an integer is shown in Fig. 10.16.
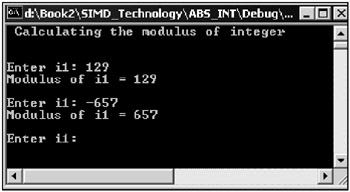
Fig. 10.16: Window of an application that finds the absolute value of an integer
These examples do not address all of the possibilities of optimizing applications with MMX extension assembly functions; however, they will be a helpful resource as you write much more complex and effective programs.
EAN: 2147483647
Pages: 50