Four Different Approaches
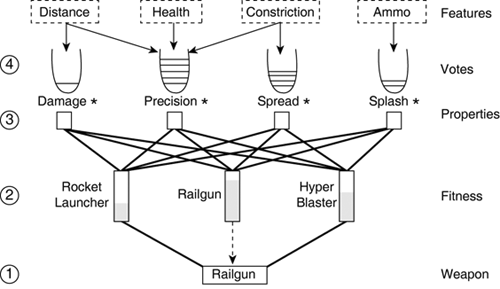
| The great thing about DTs is that they are very generic. There are also numerous ways to tackle weapon selection. As expected, there are even more ways to combine the two together. In fact, there are four options, as shown in Figure 27.1: Figure 27.1. The different concepts and processes involved in the decision of selecting a weapon.
In each of these cases, the DTs use features of the current situation as predictor variables (for instance, distance, health, and terrain constriction) as discussed in Chapter 23, "Weapon Selection." However, the four different models optionally use additional predictor variables and different response variables. Learning the Appropriate WeaponThe first approach is to use a DT to return the most appropriate weapon for each situation. This corresponds to a mapping from a set of environment features to a weapon type. In theory, this approach summarizes what weapon selection is all about. Sadly, using a single AI component to determine only the best weapon has many problems in practice:
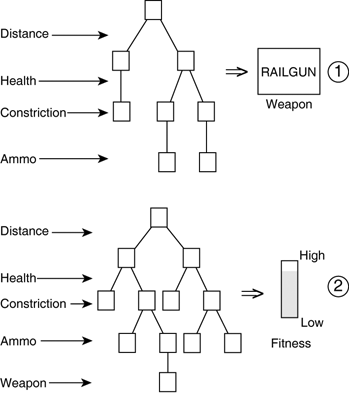
There are three obvious ways to fix these problems in a more or less improvised fashion. First, we could duplicate the DTs, so different trees would be used depending on the weapons available; this requires more memory and is slower to learn. Second, we could specify the weapons available as additional inputs, but this leads to a combinatorial explosion of the problem space, and the approximation of the DT would be error prone. Third, we could have the result of the DT as a list of weapons ranked by preference. However, this requires adapting the DT to deal with multidimensional responses. In brief, it's possible, but not ideal. A more appropriate approach would be to learn the fitness of weapons in each situation, as described in the next section. Learning Weapon FitnessIn the second model, the DT maps the features of the situation onto a single fitness value (see Figure 27.2). Then, a small script (or a native C++ function) finds the highest fitness and selects the corresponding weapon. Figure 27.2. On the top, the DT that learns the right weapon directly. On the bottom, it estimates the fitness. Each weapon could have its own DT to evaluate its fitness based on the current situation. This requires nine DTs for Quake 2 (excluding the default weapon). This approach organizes the selection skills by weapon, so they can easily be learned modularly. However, this dissociation has the cost of using additional memory and code. Instead, the weapon type could be used as a predictor variable in the DT, so only one large tree is needed to evaluate the fitness of all weapons. This option is more convenient because only one tree is needed, and the tree may be more compact. The biggest problem is computing the fitness values in some situations to supervise the learning. In essence, the problem must be solved in some cases, allowing the DT to induce the general behavior. An easy way of doing this is to reuse the voting system we developed in Chapter 25, "Scripting Tactical Decisions." The DT is based on the exact same features as the voting system. Then, the final result of the voting is used to induce the DT. The learned DT would be capable of approximating the result of the voting efficiently, without having to go through the whole process. Learning Weapon PropertiesWorking on a lower level, the DT can learn the different weapon properties based on the features of the current situation. Naturally, rate of fire and speed of projectiles don't need learning or at least, not with DTs because they are constant values. On the other hand, characteristics such as maximum damage and estimated damage per second are very much dependent on the current situation (as discussed for the shooting skills). The advantage of this approach is that it results in accurate measurements for the weapon properties that were relied upon in Chapter 25. Thanks to the DTs, the statistics are dependent on the skill of the animat, and even the different situations. On the other hand, the DT is not a self-standing solution, and still relies on other aspects of the AI. If we opt for this approach, we'll be able to reuse the entire voting system which will be enhanced by learning. Learning Votes for PropertiesThe final approach learns the votes for the weapon properties based on the features. This model avoids using a voting system, replacing it with a hierarchy of decisions that would be more efficient but approximate. The voting system is still required during learning to provide the DT with some examples, but it can be removed in the final architecture. The fitness of the weapon is then the sum of the fitness of its characteristics. |
EAN: 2147483647
Pages: 399