5.1 Disk Architecture
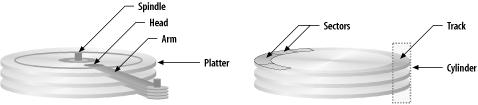
A disk drive consists of a number of stacked metal disks coated with a magnetic recording medium; these disks are called platters . The platters rotate around a central spindle , generally at speeds between 5,400 and 15,000 rotations per minute. Between these platters are a set of movable arms, which have small sensors called read/write heads . In order for a disk operation to complete to a given part of the disk, the arms must move into place, and then the appropriate location on the platter must spin beneath the heads. With proper positioning thusly achieved, data can now be read from, or written to the disk. [1]
[1] The disk drive also stores some vital information, like the disk label, at the very beginning of the disk.
The usable storage area of the disk is divided up based on an address scheme. [2] The ring of data that is swept out by the heads on a given platter as the platter rotates is called a track ; the group of tracks on all platters that share a given arm position is called a cylinder . Cylinders are numbered from the outside edge of the disk inward; that is, the lowest numbered cylinders are also the outermost. Each track is further broken up into sectors , which are generally 512 bytes [3] long. The number of sectors per track is dependent on the size of the platter and the recording density. Figure 5-1 is an illustration of disk architecture.
[2] Some space is reserved for the disk drive's internal use; it stores things like head alignment data and error correction data.
[3] This size is mandated by the SCSI standard.
Figure 5-1. Disk architecture
5.1.1 Zoned Bit Rate (ZBR) recording
If the number of sectors per track were constant, data would become less dense across tracks as you moved outward along the disk, wasting space as you move outward. To address this problem, all modern disk drives use a technique called zone bit rate (ZBR) recording, in which the disk is divided up into zones, and more sectors are stored on the outer tracks. [4] Lower-numbered zones have more sectors per track than higher-numbered zones. This results in a roughly constant data density, in terms of bits per inch; it also causes the data rate to vary with the cylinder number.
[4] Most modern disks have about fifteen zones.
|

Unfortunately, this makes disk performance calculations somewhat complicated, since the transfer rate varies depending on which cylinder you're accessing.
5.1.1.1 Disk caches
SCSI and IDE disks typically have local caches associated with them. These caches are simply a small amount of memory, typically between 128 KB and 4 MB, associated with the disk's embedded controller. When data is read from the drive, a copy is stored in this cache. Because most of the delay in accessing a disk is either in the time spent transferring data from the platters or in the time spent moving the read/write heads into position and waiting for the appropriate sector to fly by, servicing a data request from the disk's local cache saves a lot of time, and for commonly accessed data, the local caches can be very effective. By default, most drives have read caching enabled.
What is usually not enabled is the ability to use this local cache memory to cache writes . Typically, a drive will not acknowledge a write as complete until the data is physically written to disk. If write caching is enabled, the disk will acknowledge the write as complete when the data is stored in this memory. This memory is volatile, which means that its contents vanish when power is lost: this is not a problem for caching reads, but a power failure at an inopportune moment could cause an acknowledged write to be silently discarded because the data hasn't been physically written to disk. There is absolutely no guarantee that anything written to the disk buffer cache will actually ever see the platters. Because of this reliability issue, these caches are not normally enabled. Enabling them can substantially increase performance; however, this performance improvement comes with the risk of data loss.
We'll discuss how to enable and check the status of these caches in Section 5.5.1 later in this chapter.
5.1.2 Access Patterns
Disk accesses tend to be either clustered together ( sequential access ) or spread out in no particular order ( random access ). Just because disk accesses are clustered together does not necessarily mean that they are sequential; most disk accesses that happen to be close together on the disk end up being sequential. Clustered accesses aren't necessarily , but often are, accesses to sequential sectors on the disk. Unfortunately, these terms also have relevance in other areas: it is possible for media to be " randomly accessible" in the sense that "any bit can be accessed about as fast as any other bit" (such as a hard drive), or "sequentially accessible" (such as a tape drive). When I use these terms in this chapter, I only refer to the pattern of accesses.
The performance of the two access patterns is given by two very different rules:
-
Sequential access is dominated by the actual transfer time from the disk platters (internal transfer speed).
-
Random access is dominated by the platter rotational speed and the seek time.
Increasing the transfer size or transforming random access patterns into sequential access patterns significantly increases disk subsystem performance. This is one of the most profitable areas to target for improvements in performance .
5.1.3 Reads
A disk read is normally synchronous; the requesting process blocks until the read is complete. This is not always the case, as an asynchronous read could have been issued by aioread(3) . When the system reads the data, it is cached in case it is needed again. Caching uses the main memory area and is described in detail in Section 4.4.1. If you are debating expanding main memory or investing in a big disk controller in the interest of improving read performance, you are almost always better off expanding main memory; you will have an expanded filesystem cache that is accessible in less than a microsecond, and you will almost certainly reduce the number of reads issued, saving on bus loading and CPU time.
Generally, the goals in designing a read-oriented disk subsystem are to minimize the latency for the initial read of uncached data and to maximize throughput for sequential data.
5.1.4 Writes
Disk writes are a mix of synchronous and asynchronous events. Asynchronous events occur when a file is written to the local filesystem: the data is written to memory and the write is immediately acknowledged. This data is actually flushed out to disk later by means of the filesystem flush daemon (see Section 4.4.2). Applications can request that a file be written out immediately by calling fsync (3C) or by closing the file. Note that when a process exits, all of its open filehandles are closed and therefore flushed. This can take a while and cause a substantial amount of disk activity if many processes exit at the same time.
5.1.4.1 UFS write throttling
In order to prevent too much memory from being consumed by pending writes, Solaris implements a write throttle algorithm. This algorithm limits the amount of data pending to any given file; it is a per-process , per-file limitation. For each file, between 256 KB (the low-water mark , set by the ufs:ufs_LW variable) and 384 KB (the high-water mark , set by the ufs:ufs_HW variable) of data can be pending at any one time. When there is less data than the low-water mark pending to a file, flushing the data is left to the filesystem flush daemon. When the amount of pending data is between the two water marks, writes are scheduled to push the data out to disk. If more than the high-water mark data is pending, the application is not allowed to write any more data (that is, the write( ) system call will block) until the amount of pending data drops below the low-water mark again.
|
When you want to write quickly to a file and the underlying disk subsystem can cope with the throughput, it may still be impossible to drive the disk subsystem to maximum efficiency because the write throttle kicks in too early. The write throttle can also affect applications that perform large bursts of write activity at spaced intervals. The best diagnostic for this condition is the ufs_throttles kernel counter. It is incremented every time the write throttle kicks in, so a steadily increasing value means that you should bump up the write throttle.
Increasing the write throttle has the side effect of queuing a larger number of I/O requests for a file; this method can improve throughput, but it increases the average response time, since the queue is longer. A simple way to see the effect of changing the write throttle is to use ptime (1) to look at the time required to create a file with mkfile . Please note that you probably do not want to use /tmp for this test. The reason is described in Section 5.4.8 later in this chapter.
In practice, the watermarks are set far too low by default. The high-water mark should be set to many times the value of the maxphys tunable (for a description of this variable, see Section 4.4.4), and the low-water mark should be set to one-half to two- thirds of the high-water mark. In practice, I often set the low-water mark equal to 1/32nd of physical memory, and the high-water mark is set to 1/16th of physical memory. This means that if you have, say, one process writing full-out to sixteen separate files, you are in theory able to use all of the system's memory as a write cache. However, in practice, you would never exhaust memory this way, because the pagedaemon would kick in and start reaping cached pages and pushing them out to disk. For more information on the pagedaemon, see Section 4.3.
The entire write throttle mechanism is controlled by the ufs:ufs_WRITES kernel tunable; by default it is set to one, which corresponds to enabling the throttle. If you set it to zero, it is turned off. The potential side effect of this is very high memory consumption.
5.1.5 Performance Specifications
One of the problems in analyzing disk performance is the confusing way most vendors provide performance statistics for their devices.
5.1.5.1 One million bytes is a megabyte?
Disk vendors, as well as the SCSI specification, use the term megabyte to mean one million (1,000,000) bytes. The convention everywhere else, however, is to use megabyte to mean 1,024 kilobytes, or 2 20 (1,048,576) bytes. This five-percent difference applies to both performance specifications and storage specifications:
-
A disk drive rated to transfer 8.4 million bytes per second can only transfer 8.0 MB per second.
-
A disk drive with an advertised capacity of 9,100 million bytes will only store 8.67 GB.
This convention is adhered to by the entire industry, despite the confusion it causes.
5.1.5.2 Burst speed versus internal transfer speed
Disk vendors also like to quote the burst speed of the embedded controller. This specifies the rate that the embedded controller can transmit data on the bus. It does not account for command overhead or state changes. It is simply the speed that bits are transmitted, which can only be sustained if the disk can provide data at that speed and the target can deal with a flow that fast. Practically, this speed only happens when data is being transferred from the disk's local cache to the host system's memory. In most cases, the data does not reside in the disk's cache, and so the operation must be satisfied from the disk platters. For random I/O, the disk probably also needs to move the disk arm into position.
The internal transfer speed reflects the speed that bits are read from the disk platters to the read/write head, exclusive of all other factors (such as seeking). This measures only how fast data can be pulled off the platters; it doesn't measure the performance of any other part of the disk drive. The internal transfer speed is much lower than the burst speed, and can vary substantially depending on which cylinder is being read (see Section 5.1.1 earlier in this chapter). As a result, the internal transfer speed is a reasonably good predictor of sequential transfer performance.
|
5.1.5.3 Internal transfer speed versus actual speed
Let's further complicate matters.
The internal transfer speed reflects the true performance abilities of a disk drive more than burst speed does. However, the internal transfer speed measures only the speed at which all data flies past the read/write heads, and this measurement includes a substantial amount of overhead. Much of this overhead is spent on error-correcting codes that prevent most disk errors from resulting in corrupted data. By applying the following formula, we can get a more accurate measure of a single disk's performance:
Here's an example, using the Seagate 18.2 GB Barracuda disk (ST118273W). By consulting the manufacturer's specification sheet to find the average number of sectors per track (237) and the rotational speed of the drive (7,200 rpm), we can perform the following computation:
This represents the speed that data can be transferred to/from the disk, assuming purely sequential access.
5.1.5.4 Average seek time
The average seek time is another number that is often quoted, but it is remarkably misleading. According to the disk vendors, the average seek time is the sum of all possible seeks over the number of possible seeks. While this is mathematically true, it turns out that the physics involved in moving the disk arm mean that short seeks take much less time than long seeks. In fact, the "average" seek does not at all resemble a "typical" seek -- it involves moving the disk arm much farther than in a typical seek.
The lesson here is that storing data in a way that minimizes seek time optimizes performance. Splitting a single disk into two slices, each of which is busy, turns out to be a very bad idea. In such a configuration, every time the disk fields an access for the slice it's not currently on, it will need to seek from the average position in one slice to the average position in the other slice, which is half the maximum seek time. This takes a long time. It would be a better idea to put the two slices on different disks, in order to minimize the seek time.
|
5.1.5.5 Storage capacity and access capacity
For random-access activity, disk performance is dominated by the platter rotational speed and the seek time. Consequently, drives that spin at the same rate perform about the same, largely irrespective of capacity or physical size. [5] For random-access activity, the most effective way to increase access capacity is to buy as many fast-spinning drives as possible!
[5] 5.25" drives have slightly higher seek times, but this is not likely to have any practical impact.
Unfortunately, increases in access capacity (generally quantified as random access operations per second) have not kept pace with increases in storage capacity . To illustrate this principle, let's consider a 5,400 rpm 2.1 GB disk and a 7,200 rpm 9.1 GB disk. The larger disk has more than four times the storage capacity, but only about 30% greater access capacity. Therefore, the greatest random access I/O capacity is usually achieved by using several of the smallest feasible disks, rather than one larger disk with superior specifications! This is illustrated in Table 5-1.
Table 5-1. Access capacity comparisons for various 218 GB installations
| Disks [6] | Number | Buses [7] | I/O ops per second per disk [8] | Aggregate I/O ops per second | Aggregatetransfer rate |
|---|---|---|---|---|---|
| 4.3 GB | 51 | 4 | 108 | 5,508 | 160 MB/sec |
| 9.1 GB | 24 | 2 | 85 | 2,040 | 80 MB/sec |
| 18.2 GB | 12 | 1 | 70 | 840 | 40 MB/sec |
[6] All disk types rotate at the same speed.
[7] The minimum number of Ultra Wide (fast-40) SCSI buses required to support the drives.
[8] These numbers are empirical.
However, using smaller disks is usually more expensive, more complicated, and takes more space. It also necessitates the use of disk arrays, which we'll discuss later, to solve the problems brought about by increased subsystem failure rate that is observed when more components are used. In most environments, it is preferable to design mixtures of large and small capacity disks to ride the "sweet spot" of the disk cost/performance curve as much as possible.
|