Figure 25-1
You've learnt now the basics of reporting in PHP against a typical database. How do you put this theory into practice, however, and build a reporting platform for your application?
You may be tempted to follow an approach similar to the following:
A page called salesreport.php renders a form requesting input criteria.
When submitted, this page performs an HTTP POST to salesreport-results.php, which performs the SQL queries necessary to retrieve the report results, and renders the data on screen.
Quick, yes, but dirty, too; there a number of drawbacks to this approach:
It's not a good example of using the MVC design pattern that, for reasons discussed in Chapter 13, is to be encouraged and employed wherever possible.
There is little scope for code reuse (except through the copy-and-paste approach) when developing different reports in the future.
If the user wants to view the report's output again at some point in the future, the report has to be generated once more. This results in not only a waste of processing time but also the possibility of different results. What if the database has changed since then? A report is a snapshot in time; users will expect it to be the same next time they view it.
Users may be kept waiting for a long time while the report generates. On more complex reports, this could be up to a minute or more; what if the request times out at their end, that is, in their Web browser? What if they click the Stop button? It's generally accepted that a Web page should load pretty quickly to keep the user happy, and this includes a report that's been generated.
The last of these drawbacks is potentially the most serious, of course. Our book sales example won't take more than a few seconds on even the slowest of database servers, but many reports run to considerably more complex output than that and can even comprise hundreds, if not thousands, of queries.
As a rule, and given the nature of HTTP as a stateless protocol, if the rendering of a subsequent page on your application is dependent on some external, potentially slow process, you should attempt to take that process offline.
To cite another example, consider how many e-commerce sites ask their users for credit card numbers to make online purchases. It's a fair number, isn't it? Consider, however, how many of those sport almost comical messages declaring "don't click the Submit button more than once'' or something similar. Furthermore, even the most credit-worthy of you will have been made to wait as many as forty seconds to have your card authorized. If your request times out, how do you know whether you've been charged?
The approach adopted by Amazon is very different, and certainly far more highly recommended. Why do you need to authorize there and then? Why not do it offline and let the user know in due course whether the purchase went through successfully?
Of course, since Amazon's delivery is physical rather than electronic, it can afford to notify its user of success or otherwise by e-mail some minutes, or even hours, later. But the same principle can be applied to real-time scenarios, too, such as when allowing access to online content requiring credit card payment.
Consider the traditional approach to authorizing credit cards:
First page requests card number in HTML form; offers data via SSL HTTP POST.
Second page accepts HTTP POST from first page, authorizes card in real time, and returns result to user thirty seconds later.
Compare this to a more intelligent approach, which is an extension of that adopted by Amazon and provides pseudo real-time processing:
First page requests card number in HTML form; offers data via SSL HTTP POST.
Second page accepts HTTP POST from first page, puts card data into to-be-processed database, and returns user to authorization-pending page a split second later.
The authorization-pending page refreshes on the client side every couple of seconds until consultation with the database shows that the card transaction has been processed and a result has been determined.
An entirely separate process on the server that runs independently of the Web servers periodically (or constantly) checks the database for pending card transactions and, if it finds them, processes them, updating the database with the result when finished.
The benefits are obvious:
There is virtually no scope for the user to click the Stop button, because there is virtually no delay in returning the page to him/her.
If the user clicks the Submit button more than once, it's no big deal because a UNIQUE key on the database can prevent duplicate entries.
If the user clicks Refresh on the authorization-pending page, there's no problem because it isn't changing any data it simply refreshes.
We can apply this same logic to generating reports, as discussed next.
Using the offline approach to generating reports has huge benefits from both a user experience and an application performance perspective. Admittedly, the report itself doesn't generate any more quickly, since exactly the same database queries are being executed. But the user experience is far better, and many of the practical and technical pitfalls discussed previously are avoided altogether.
The basic principles are as follows:
A database table called report contains template information for every distinct report available on the system.
A generic page called reporting.php lists the available reports by consulting said table (and, of course, uses a Smarty template so as to be MVC-compliant). A link is also provided to the My Reports page (more on that shortly).
The user can select a given report from the table, which links to another page called newreport.php, with the report identifier passed as an HTTP GET parameter (for example, newreport.php?report_id=14). This page uses an XML template associated with that report to render a page specific to that report, which is then used by the users to specify the criteria for this instance of the report.
When the user submits the report, it is entered into a table called report_instance and flagged as PENDING. The supplied criteria are entered into a table called report_instance_ criteria. The user is then redirected to the My Reports page.
The My Reports page shows a list of all reports held in the database for that user, along with their status; PENDING, PROCESSING, or COMPLETED. The COMPLETED ones can be viewed in one of a number of formats (for example, HTML, PDF, Excel). Which formats are available depends on the "translator'' scripts available for that report.
A single PHP script called reportprocessor.phpx (with the extension .phpx signifying this is a command line executable rather than a Web page) runs constantly on a machine attached to the application's database server, constantly scanning for reports in the report_instance table with their status set to PENDING. It immediately sets them to PROCESSING and then forks a new handler process appropriate to that script, with each script having its own dedicated handler, which is also a PHP script. It then recommences the loop, again looking for reports marked as PENDING.
The handler script consults the report_instance_criteria to determine the criteria for this report and then builds SQL queries as needed to extract the relevant data. This data is written to an XML file and the instance marked as COMPLETED.
Should the user then look at the My Reports page, the report in question will be seen to be COMPLETED rather than PROCESSING. The user can then view the results of the report.
The "translator'' scripts for a given report take the raw XML output of the handler scripts and translate them into the output format in question. In the case of HTML, this might be accomplished using XSLT. In the case of a PDF, this might be accomplished using an XSLT followed by a pass of Apache FOP to translate that XML into a PDF document, as discussed in the first section of this chapter.
Let's look at this approach in more detail now. We don't give you the source code verbatim because it would run to many hundreds of pages; however, if you follow the architectural outline detailed in this section, you should easily be able to construct a reporting platform to fit your application's requirements perfectly. Alternatively, the full source code for an example implementation of this methodology can be found on the Wrox Web site at www.wrox.com.
Later in the chapter, you'll meet a real-world example of using this methodology to process a user's request for a report.
The main Reports interface is the home page of the reporting component of your application. Should you add reporting as an option to your navigation, this is inevitably the first page to be rendered.
The page will comprise two files reporting.php and reporting.tpl, a Smarty template.
The purpose of the interface is as follows:
Welcome the user to the reporting component of the application.
Provide a link to the My Reports page so that the user may view any requested reports and see their status.
Provide a list of the types of report on the system and allow the user to create a new instance of that report.
Note that "instance'' has nothing to do with OOP. It is simply an incarnation of a particular report. For example, you may have a generic report that generates sales comparison figures; an instance of that report would be that generated by Joe Bloggs on the 3rd of August to compare figures from April and June, for example. A report is not associated with particular input criteria, whereas an instance of it is associated with a very particular set of input criteria.
The list of types of report available on the system would be achieved through the consultation of the report table. You may wish to provide some administrative interface to allow new reports to be added to this table, but keep in mind that in the architecture we are presenting there is a requirement for some fairly sophisticated files to be constructed for each new report. With this in mind, you may see limited value in providing an interface to create brand-new reports. Indeed, it is probably commercially preferable that your client is dependent on you for creating new report templates.
The report database table, which contains the list of available report types and is used by the Reports interface to generate the list of available report types, is structured as shown in the following table.
| Column | Data Type | Description |
|---|---|---|
| Id | SERIAL | The identifier and primary key of the table |
| report_code | character varying(8) NOT NULL | Another unique identifier, but more human readable, such as salesrep |
| report_name | character varying(64) NOT NULL | The name of the report, such as "sales comparison'' |
| report_desc | character varying(256) | A description for the report |
Note that the preceding is tailored for PostgreSQL in keeping with the rest of this book. It would be a trivial matter to adapt this table structure for MySQL or another database platform, however.
As you can see, we don't store much data about the report in the report table. We don't need to; almost everything else will be stored on disk, as you'll see.
The data about available reports is extracted from the preceding table. Unless a huge number of reports are available, you probably don't need to concern yourself with pagination. You simply provide the name of each report type and a link to create a new instance of a report of this type, using the interface discussed in the next section.
This should be passed as an HTTP GET parameter to newreport.php, discussed next. The preceding information should be presented using a Smarty template (see Chapter 13), perhaps named reporting.tpl.
This page will be called exclusively from the master Reports interface of the previous section. It will be passed as an HTTP GET parameter the database identifier of the report required. The purpose of this page, which will also be comprised of two files (a.php model and Smarty template as view and controller) is to render a criteria entry form for the given report.
Essentially, the user must be presented with a form showing the available criteria for that form, including showing clearly which are mandatory and which are optional.
You could, of course, use a Smarty template for each report, (for example, report salesrep uses /templates/salesrep.tpl) but if you have to construct tens or even hundreds of reports, the prospect of hand-coding HTML forms for each one will doubtless be an unpleasant one. After all, you are a PHP professional; there are plenty of high school kids just itching to do some HTML for you.
Instead, you can use XML templates, one for each report.
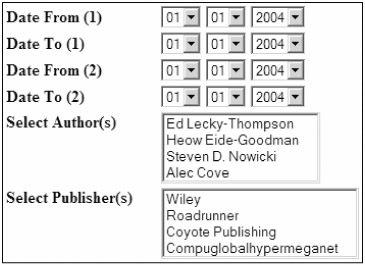
Each report will have an XML template detailing which criteria are available for data entry. In the case of our rolling sales comparison report example, it is permissible to specify two start dates, two end dates, and, optionally, a publisher, an author, or both. These permissible criteria are detailed in an XML template associated with this report.
Each XML document should live somewhere central and be named to correspond with the code used in the database. Don't use the id column of the report table as a naming mechanism; this may change if you move the database from one server to another, or upgrade PostgreSQL. Consider it for internal use only; instead, name your XML templates /templates/salesrep.xml or similar.
The exact format of this XML is of course entirely down to you, but consider something similar to the following. This file might well be named /templates/salesrep.xml:
<report > <criterion type="date" name="datefrom1" mandatory="true" caption="Date From (1)"/> <criterion type="date" name="dateto1" mandatory="true" caption="Date To (1)"/> <criterion type="date" name="datefrom2" mandatory="true" caption="Date From (2)"/> <criterion type="date" name="dateto2" mandatory="true" caption="Date To (2)"/> <criterion type="fkmultiple:author/id/author_name" name="authors" caption="Select Author(s)"/> <criterion type="fkmultiple:publisher/id/publisher_name" name="publishers" caption="Select Publisher(s)"/> </report>
As demonstrated, we list each criterion made available for use when you generate the report by using several instances of the criterion tag.
Each tag has a name used when storing the input, a caption (displayed on screen), and a type.
The type is crucial. It determines how the field is presented when rendered in the Web browser. You might want to consider supporting types as follows:
| Type | Description |
|---|---|
| freetext | A free text entry box, stored as entered |
| date | A date, represented as three form components (day, month, year) but stored as a single ISO date (YYYY-MM-DD) |
| time | A time, represented as three form components (hour, minute, seconds) but stored as a single ISO time (HH:MM:SS) |
| datetime | A date and time, represented as six form components (day, month, year, hours, minutes, seconds) but stored as a single ISO date (YYYY-MM-DD HH:MM:SS) |
| fkmultiple | A list box showing entries from a foreign key table. The format for this type is fkmultiple:tablename/storecolumn/displaycolumn, where tablename is the table containing the foreign entity, storecolumn is the column containing the values to be stored, and displaycolumn is the column to display in the list box. This is used in our preceding example to allow the selection of a publisher or author (from the publisher and author tables respectively). |
| fksingle | As described previously, but allowing only a single entity from the foreign table to be selected |
Of the types in the preceding table, probably only the fkmultiple and fksingle criterion types require further explanation.
The purpose of these types is to easily allow the user to select from either a drop-down list or static list box of values from a foreign table. In the previous example, we allow the user to select author(s) or publisher(s) to which to restrict the report. Rather than require the requesting user to enter author IDs or publisher IDs, we allow the user to select from a list box that is automatically generated for that user.
This is another example of why the XML approach is preferred; there is no need to write code to generate such list boxes for every report. A single piece of code can be used for every report.
In our example XML, your new report interface would likely parse it and render an HTML form that resembles Figure 25-1.
Figure 25-1
You can, of course, jazz up this simple form to match the styling and design of the interface of your particular application.
Your page searches for the XML template that corresponds to the report being requested and then traverses it to render an appropriate HTML form in the user's Web browser.
Each form element is named so that when the data is posted, the criterion name can be easily decoded. For example, for a criterion called date_from1, the form element name CRITERION_date_from1 may be used. Using the CRITERION_ prefix means that you can differentiate between the value of criteria being submitted and other, unrelated form parameters.
You may wish to extend the previous architecture slightly to suit your needs. For example, you may want to prepopulate form elements with default values, such as by setting any date elements to today's date.
The target for the form should always be newreport.php. The page should be adapted so that a separate block of logic is executed if it is receiving POST data as opposed to GET data, because this implies that a report is being submitted with populated criteria rather than a request for a new form being made, as described previously.
When newreport.php does receive POST data, it's important that it handle that data correctly. The task at hand, of course, is to lodge a new instance of the report in question so that the report processor script, discussed shortly, can start processing it.
Instances of reports are effectively requests for a given report with a given set of criteria and made at a given point in time. Each instance is generated only once and stored in its generated state, so if the user does need to refer back to it later, it won't be regenerated needlessly. However, the user also has the opportunity to create a whole new instance to reflect the most up-to-date data available to the Reports engine.
With this in mind, you should store such requests in a database table called report_instance or similar, structured as follows:
| Column | Data Type | Description |
|---|---|---|
| Id | SERIAL | The identifier and primary key of the table |
| report_id | int4 | The report in question, a foreign key from the report table |
| submitted | datetime | Date and time at which the report was submitted for processing |
| submitting_user_id | int4 | The ID of the user submitting the report, used for matching on the My Reports page |
| status_flag | character(1) | The status of the report for the processor; P is pending, I is in progress, and C is completed |
You will also need a table to store the criteria that you are associating with the instance of the report. A separate table ensures that some degree of normalization is maintained, necessary because you will undoubtedly have more than one criterion specified per report. Without using a separate table, you would be forced to comma-separate that data when storing it in the table. Yuck!
Call this table report_instance_criterion or similar:
| Column | Data Type | Description |
|---|---|---|
| Id | SERIAL | The identifier and primary key of the table |
| instance_id | int4 | The report instance in question, a foreign key from the report_instance table |
| criterion_name | varying(128) | The name of the criterion in question, such as datefrom1 |
| criterion_value | character varying(128) | The value of the criterion in question, such as 2004-01-01 |
This table structure allows you to support multiple criteria for a given report instance; there would simply exist more than one row in the report_instance_criterion table for the report_instance in question.
Your script should read input parameters from the POST data and record them into the database as appropriate. You should use the P (Pending) status for the report so that the processor knows to start processing it. Ideally, it should also consult the XML template for the report in question to determine which fields are mandatory and which are not; if the user has not supplied mandatory fields, he or she should be returned to the criteria entry screen (and be suitably castigated).
When storing criterion values, you may have to suffer a degree of poor database normalization. The previous example invited users to provide lists of authors and publishers. This can result in having more than one author or publisher provided for a given report request. If you apply the rules of Boyce-Codd normalization (or 3rd Normal Form), you should separate this into two tables rather than one:
report_instance_criterion and report_instance_criterion_value instead of just report_instance_criterion. You may well consider this to be overkill, however, and resort to storing lists as comma-separated values in the criterion_value field. If so, you will be forgiven for this, on this occasion.
If you are likely to encounter occasions when a criterion_value entry can contain, say, many hundreds of different values, you may need to increase the length of the criterion_value column in your table from 128 characters to, say, 1024 characters. Because PostgreSQL allows up to 8192 for character fields, this wouldn't pose a problem.
Having recorded the relevant information into both report_instance and report_instance_ criterion, your front-end PHP has really done its work; the back-end takes over from here. To aid the user experience, you should use a 302 redirect to transport the user to the My Reports page, like this:
header("Location: /myreports.php"); exit(0);
The user will be able to see the report just submitted with a Pending status against it or, if the processor gets to it in time, an "In progress'' status against it.
The report processor script (which might be named/scripts/reportprocessor.phpx note the .phpx extension to signify a server executable rather than a Web page) is an example of an off-line or back-end PHP script. It is not invoked by the user's Web browser. Rather, it runs on the server independently of Apache.
Its purpose is to run continuously, seeking out report instances that are set to PENDING, update them to IN PROGRESS and then invoke an appropriate script (a handler) to actually generate the report results.
There are a couple of approaches for this. You can simply have a single instance script that runs continuously from server boot in an infinite loop, or you can use the server's crontab to schedule the script to run every few seconds.
The first approach is possibly a better bet, though. Simply invoking the procedure every n seconds would be fine if you knew how long the procedure would take. You don't, however, and you could end up with multiple instances of the processor launching, with unpredictable results. Far better to have the script run in perpetuity from the moment the server boots up, and maybe have a cron job to ensure that it is still running at any given time, relaunching it if it has stopped or failed for some reason.
The pseudo-code for your script will probably look something like this:
Begin Loop.
Look for any reports set as status P (Pending).
For each report set as status I (In Progress), determine the report code, such as salesrep, and then look for a handler script with that name, such as /scripts/handlers/salesrep.phpx.
Launch the handler, if found, into the background to generate the script results.
For any handlers that appear to have finished, mark the corresponding report as C for Completed.
Sleep for 5 seconds.
Repeat loop.
Setting the report to status I, In Progress, not only allows users to be informed that their report request is being processed but also prevents the processor from attempting to process the report request again on the next pass.
The five-second delay with each loop is at your discretion; keep in mind, however, that each pass of the script requires at least one SQL query to be made, so you will almost certainly want some kind of delay to prevent your database from becoming saturated with connections.
It is important that you launch the appropriate handler script into the background rather than simply launch it and wait for it to execute. Do not be tempted to execute it using require() or include(). You should launch it as though it were any other system executable. This way, the execution of the report processor script is not impeded by the launch of your handler script, and it can proceed to process any other reports that might be pending.
You may want to consider using the syntax provided by proc_open() to effect this. See http://www.php.net/manual/en/function.proc-open.php for more details. This allows you to launch a process and then have some control over it from within your code rather than simply be a slave to its execution. This allows you to have handlers with read-only rights on your database. You pass the handler the name of the output file (for the results) as a command-line parameter and the criteria for the report as standard input parameters.
The output file in question should be associable with the report instance in question. For example, for instance ID 19039, name your output file /generated/output19039.xml or similar.
Keep track of the process you have invoked during subsequent iterations, and when it has terminated, update the database to reflect this by marking that report request as C for completed.
Having your handlers separate from the reporting system itself is an excellent approach; it means that they can be truly dumb scripts, concerning themselves only with querying the database, and be highly efficient as a result. Redundant code duplication is also minimized.
In the previous section, we mention that each type of report supported by your architecture will require its own "handler'' script, such as /scripts/handlers/salesrep.phpx in the case of a report called salesrep.
This handler script will be invoked by the report processor script and will accept as a single command-line argument the name of an output document in which its results are stored. As mentioned previously, this output filename is determined exclusively by the request_instance ID.
More important, of course, the handler needs to be presented with key/value pairs of criteria as set by the user originally requesting the report.
These, too, will be provided by the processor script, but it would obviously be impractical to allow such criteria to be passed using the command line.
Instead, the processor script should pass such parameters as key/pair values directly through standard input that is, as though they were being typed at the keyboard. A terminating double newline (that is, a blank line) indicates the end of such criteria and allows the script to start.
If the handler script were run at the command line, the following would be valid input:
# /scripts/handlers/salesrep.php /generated/output19039.xml datefrom1=2004-03-01 dateto1=2004-03-31 datefrom2=2004-05-01 dateto2=2004-05-31 authors=31,14,12,11,15 publishers= [blank line] [script executes here]
Of course, all the previous data entry is actually provided by the processor script. The handler script therefore has the following tasks upon launch:
Determine output filename using argv array. Create this file.
Loop through STDIN input receiving key/value pairs until a newline character is encountered. Push such key/value pairs into an associative array.
After a newline character is received, ignore any further input and execute whatever SQL queries are necessary to produce suitable output.
Push this output into a suitably formatted XML document and save it into the output file determined and opened in the first step.
Simple. The handler script doesn't even need to update the database it's a read-only process. The process of terminating will allow the processor script to determine that the report is completed.
The format of the output XML is unimportant. At least one translator script is needed for every report on the system, and each translator script will be unique to that report. Accordingly, the output XML is up to you.
In our recurring example, however, it may look something like this:
<results> <rangeonesales>31319</rangeonesales> <rangetwosales>33153</rangetwosales> <percentuplift>5.856</percentuplift> </results>
The output XML is short and simple, as you can see. Even though the input criteria specified were quite complex, including two date ranges and a list of five authors, the results from the report are still simple: the sales for these five authors in the first date range, the sales for the five authors in the second date range, and the percentage difference between the two.
Regardless of the specificity or vagueness of the input criteria for this report instance, the output data will always be of the same format. This is very useful because it allows the translator scripts, which are covered shortly, to be completely generic that is, it doesn't matter in the slightest what input criteria were originally specified.
Very shortly, we discuss these translator scripts and how they can turn this XML data into something more readable.
Back to online pages now. This page, as the name suggests, will show requesting users a paginated summary list of all reports they have requested on the system, along with the reports' status (pending, in progress or completed).
Options to view completed reports will be shown. The user may view in native format (XML) or, more usefully, and depending on which translator scripts are available, a number of translated formats, such as HTML or PDF.
You may also wish to provide an option for users to remove reports, or to e-mail the results to an address of their choice.
How the system determines which output formats are available is based on the translator scripts available. The next section shows how this works.
The report translator scripts take the XML output results of a given script as produced by the handler scripts discussed earlier and present it in a more user-readable format.
These are online scripts in the sense that they are executed in real time and viewed using the Web browser. However, they will almost always be linked to the My Reports page and not called explicitly by the user.
In practice, you will want to name them in a convention that allows the My Reports page to see instantly which translators are available for each report:
/translators/html/salesrep.php /translators/pdf/salesrep.php /translators/excel/salesrep.php
. . . and so forth.
We recommend that you adopt a consistent input and output approach for each script. The input is simply the name of the input XML to parse; the output is the parsed data itself. For example, to render our recurring example in PDF format, use
/translators/pdf/salesrep.php?filename=output19039.xml
as the URL. This link will, of course, be directly generated by the My Reports page, which checks for the existence of the appropriately named script to determine whether it's available. If not, it would respond with an error; however, this situation should never crop up, given that the My Reports page will only ever display links to view report instances that have been successfully generated.
How you perform the translation is very much up to you and depends on the report in question and how much data is likely to be rendered, as well as the XML schema you have adopted to produce the report output.
You may find the following hints useful, however.
HTML in its purest form is just another form of XML albeit with a very precise, defined DTD (document type definition). With this in mind, it is relatively simple to use an XSL style sheet to convert your input XML to well-formatted output HTML.
In PHP4, this was accomplished using the Sablotron package and was tricky at best, horrendous at worst. In PHP5, DOM (Document Object Model) XML has taken over, so XSL translation has become simply a function of the interaction of two DOM objects:
$objDomXML = new DomDocument; $objDomXML->loadXML($strXML); $objDomXSL = new DomDocument; $objDomXSL->loadXML($strXSL); $proc = new XSLTProcessor; $proc->importStyleSheet($objDomXSL); $strHTML = $proc->transformToXML($objDomXML);
As you can see, the trick is to instantiate two DOM classes and load the XML and XSL into each. Because XSL is just another form of XML, it's perfectly allowable to load it straight into a DOM Document object as if it were a piece of XML.
You can then create an instance of the XSLTProcessor utility class. This is the class that actually performs the XSL transformation, but it cannot work with XSL in a raw string form. You therefore must tell it about the XSL style sheet by making reference to the DOM Document object you just created for that style sheet.
Having done this, you can use the transformToXML method, passing in your original XML DOM Document object, to perform the translation of your original XML against this XSL. The result is pure HTML, which is easily captured into a string.
There are a number of ways to produce PDFs. If you are insistent on using PHP, you can put together a solution for your particular DTD using the R&OS PDF class (http://www.ros.co.nz/pdf/). This has the huge advantage over PHP's recommended PDF methodology, in that it is completely free of any third-party library dependencies and, hence, any commercial licensing restrictions.
Producing PDFs in this way is harder than you think, though, because you're the one responsible for line wrapping, getting table borders and cell interiors drawn, and so on. It is akin to producing a magazine page in Visio instead of Publisher.
An easier route may well be using Apache FOP see http://xml.apache.org/fop/ for more details. This provides a standard DTD for representing PDF documents. Using a simple XSL translation followed by processing in FOP, you can easily produce PDFs of your work without having to worry about the finer points of Cartesian geometry.
The downside of FOP is that it is Java based. It therefore requires the Java SDK to run, and hence is slightly trickier to get up and running than a native PHP application.
However, the architecture you have adopted so far (of keeping translator scripts away from your database and reporting infrastructure) means that this isn't such a big deal you can even run a separate Java application server (such as Jakarta) on another port, and keep the PDF translator on there. As long as it can see the same output XML documents as an equivalent PHP page, you'll be fine.
You can produce Microsoft Excel spreadsheets using the Spreadsheet_Excel_Writer package from PEAR (see http://pear.php.net/package/Spreadsheet_Excel_Writer for more information). It is a native mechanism for writing Excel documents and hence needs no external libraries or COM objects to function, and will happily run on UNIX-based servers.
It may be difficult to visualize all the previous in practice. Here we work through an example from start to finish, examining what happens in the background throughout.
The user journey starts on the Reports home page, where a list of reports available to be generated appears. Our user picks the sales comparison report (known as salesrep internally) and clicks through to generate a new instance of that report.
The newreport.php page loads the corresponding XML template file and renders the criteria fields silently and transparently. The user then populates these with the criteria in question and submits the form. The same page then records the user's criteria in the database and creates a new report instance with the status set to P for pending. Meanwhile, the user is transported back to the My Reports page, where he will see the status of the new report as "pending processing'' (hence why it can't be viewed at this stage).
The processor script, already running in the background, then almost immediately picks up on that new entry in the database and sets its status to In Progress. It then locates the appropriate handler script and launches it as a new process. This may take a while, so it gets on with its subsequent iterations until the script finishes executing. Meanwhile, the handler script parses the input parameters it has been passed and uses them to query the database and generate useful output in XML, using the filename passed to it by the processor to stores its output. When it finishes, the processor script takes over and marks the report as status C for Completed.
When users next visit the My Reports page, they notice that their report are marked C for Completed. Options to view the report in XML, PDF and HTML are presented to them and they choose to view it in PDF. The link to do so is in fact a link to a translator script, which takes the report's XML as input and produces a neatly formatted PDF as output, which users then print.
You may often find, particularly when producing HTML output, that it is easier to show some or all of your report's results in a graphical format. You may have a long string of value pairs in your report's raw XML. It would be far easier to show these on a line graph, for example.
When producing Excel output, users theoretically can easily implement such graphs themselves. When producing HTML output, however, no such facility exists, and you must embed appropriate graphics directly into the HTML.
Thankfully, producing graphs and charts in PHP is relatively straightforward.
The Image_Graph package to be found in PEAR (see http://pear.php.net/package/Image_Graph/ for more information) allows you to easily convert raw data sets into line and bar charts, and myriad unsupported third-party packages for producing pie charts can be found on Google.
The principle is that you use your translator script to generate output PNGs, which are saved on disk in a path accessible to the Web server; the output HTML generated then includes references to these PNGs so that they can be displayed in-line.