7.2. COMMUNICATION PATTERNS
Parallel Computing on Heterogeneous Networks, by Alexey Lastovetsky
ISBN 0-471-22982-2 Copyright 2003 by John Wiley & Sons, Inc.
7.1. INTERPROCESS COMMUNICATION
The subset of the mpC language presented in Chapter 6 allows the programmers not only to describe computations and communications implementing the heterogeneous parallel algorithm but also to specify its performance model. The performance model reflects the following basic features of the implemented algorithm having an impact on its execution time:
-
The number of parallel processes executing the algorithm.
-
The relative volume of computations performed by each of the processes.
The compiler uses this information to map the parallel processes of the algorithm to the network of computers in order to minimize its execution time.
The perfomance model provided by the mpC subset fully ignores communication operations. In other words, the model presumes that the communication operations’ contribution to the total execution time of the algorithm is negligibly small compared to that of the computations.
This assumption is acceptable for “normal” message-passing parallel algorithms if the communication layer of the executing network of computers is of the quality of the MPP communication layer, that is, homogeneous, fast, and balanced in the number and speed of processors (see Section 4.1 for more detail). In other words, the assumption is acceptable for “normal” parallel algorithms running on heterogeneous clusters as they are defined in Section 5.2.
The assumption is also acceptable for message-passing algorithms whose parallel processes do not communicate frequently sending each other relatively short messages, even if they run on the network of computers whose communication layer is far removed from the ideal MPP communication network.
However, this assumption is too far removed from the reality of what happens during “normal” message-passing parallel algorithms running on common heterogeneous networks of computers. In Section 5.2 we have showed that the low speeds and narrow bandwidths of some communication links can cause communication operations to raise the total execution time of a “normal” parallel algorithm to an even more significant extent than the computations. The mapping of the parallel algorithm to the executing common network of computers, which does not take into account the material nature of communication operations, will therefore not be accurate. These may even result a parallel program that is slower than the corresponding serial program solving the same problem.
Thus, in order to support parallel programming for common networks of computers, the mpC language should additionally allow the programmers to explicitly specify the volume of data that should be transferred between different parallel processes during execution of the algorithm. Unfortunately, such an advanced performance model of a heterogeneous parallel algorithm that can take into account the costs of computations and communications cannot be obtained by a straightforward extension of the simplified basic model. As soon as communication operations are brought into the model, the algorithm should provide more information about computations than just their relative volume performed by different parallel processes. Otherwise, specification of communication operations will be useless.
To see this point, consider two parallel algorithms that are equivalent in terms of the total number of parallel processes, relative volumes of computation, and volumes of transferred data. During execution of any of the algorithms, all processes perform the same volume of computation and transfer in total about 10 Mbyte.
Let us assume the following:
-
The algorithms differ in absolute volumes of computation performed by the parallel processes so that the first algorithm performs about 100 times as much computation compared to the second one.
-
All processors of the executing network of computers are identical.
-
The per-processor cost of computation of the first algorithm on the network is around 103 seconds, while that of the second algorithm is around 10 seconds.
-
The executing network consists of two communication segments, one based on plain 10 Mbit Ethernet and the other using 1 Gigabit Ethernet.
-
The number of processors in each of the segments is greater than the total number of processes of the algorithms.
Then any one-to-one mapping of processes of the first algorithm to processors of the network will be approximately equivalent in terms of the execution time. Even if the algorithm is entirely executed by processors of the slower segment, its execution will still take nearly 103 seconds since the communications will add to the total execution time about 1 second.
However, the execution time of the second algorithm may differ significantly depending on the mapping of its processes to the executing network. If processors of the faster segment execute the algorithm, it will take about 10 seconds as in this case the cost of communications will be close to 10-1 second. If it is executed by processors of the slower segment, it will take more than 20 seconds as the cost of communications will be no less than 10 seconds. Thus the two algorithms, which are equivalent in terms of relative volumes of computation and volumes of transferred data but not equivalent in terms of absolute volumes of computation, should be mapped differently to achieve a better execution time.
For the compiler to optimally map parallel algorithms with substantial contribution of communication operations into the execution time, the programmers should specify absolute volumes of computation to be performed by different processes and volumes of data transferred between the processes. The mpC language provides the programmers with such facilities. The key issue in specification of absolute volumes of computation and communication is how to measure these volumes. The specification should provide the compiler with information sufficient for it to estimate the computation and communication portions of the total execution time.
Specification of the volume of communication is not a big problem. The byte is a natural unit of mesurement for data transferred between processes of the parallel algorithm. Given the size in bytes of data transferred between a pair of processes and the speed and bandwidth of the corresponding communication link, the compiler can estimate the time elapsed by the communication operation.
Specification of the volume of computation is not as easy. What is the natural unit of computation to measure the volume of computations performed by a process? The main requirement is that if given the volume of the computation measured in those units, the compiler should be able to accurately esimate the time of execution of the corresponding computations by any process of the program.
The solution proposed in the mpC language is that the very code that was used to estimate the speed of physical processors of the executing network can also serve as a unit of measure for the volume of computation performed by processes of the parallel algorithm. Recall that the code is commonly provided by the programmer as a part of the recon statement (see Section 6.9).
To introduce the advanced mpC model of a heterogeneous parallel algorithm and the language constructs supporting the model, let us consider two typical mpC applications. The first simulates the evolution of a system of bodies under the influence of Newtonian gravitational attraction. It is supposed that the system consists of a number of large groups of bodies, with different groups at a good distance from each other (see Figure 7.1).

Figure 7.1: The system of bodies consists of large groups of bodies, with different groups at a good distance from each other. The bodies move under the influence of Newtonian gravitational attraction.
Since the magnitude of interaction among the bodies falls off rapidly with distance, the effect of a large group of bodies may be approximated by a single equivalent body, if the group of bodies is far enough away from the point where the effect is being evaluated. This way we can effect a paralleling of the problem. The parallel algorithm simulating the evolution of the system of bodies can be summarized as follows:
-
Each body is characterized by several variables, including its position x, y, and z (the Cartesian x, y, and z coordinates); its velocity vx, vy, and vz (the x, y and z components of velocity); and its mass m.
-
Newton’s law of gravitation is used to calculate the strength of the gravitational force between two bodies: the strength is given by the product of their masses divided by the square of the distance between them, scaled by the gravitational constant G,
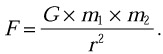
-
To calculate the total force acting on one body, the gravitational force between this body and every other body in the system should be accumulated. The principle of superposition says that the net force acting on a body is the sum of the individual pairwise forces. Therefore the total forces in the x, y, and z directions are obtained by adding up the forces in the x, y, and z directions.
-
Newton’s second law of motion, F = m x a, is used to get the x, y, and z components of the body’s acceleration is implied by these forces.
-
Time is discretized, and the time variable t is increased in increments of the time quantum dt. The simulation is more accurate when dt is very small. At each discrete time interval dt, the force on each body is computed, and this information is used to update the position and velocity of each body:
-
The position at time t is used to compute the gravitational force F and acceleration a.
-
Velocity v and acceleration a at time t are used to compute velocity v at time t + dt as v = v + a dt.
-
Position p, velocity v, and acceleration a at time t as well as velocity v at time t + dt are used to compute position p at time t + dt as p = p + (a x v + b v) x dt + a x (dt2/2). In this formula, a, b ≥ 0 and a + b = 1 (usually a = b = 1–2) are used.
-
After the position and velocity of each body are updated, all bodies whose distances between each other are small enough compared to their masses are merged into a single body. The mass of the resulting single body is the sum of the individual masses of the merged bodies, m = Simi. The position of the resulting body is the center of mass of the collection of merged bodies. The velocity of the resulting body is computed so that the momentum of the resulting body is equal to the total momentum of the collection of merged bodies, v = Simi x vi/m.
-
-
There is one-to-one mapping between groups of bodies and parallel processes of the algorithm. Each process has in its memory all data characterizing bodies of its group, and is responsible for updating it.
-
The effect of each remote group of bodies is approximated by a single equivalent body. This means that in order to update the position and velocity of bodies, each process requires the total mass and the position of center of mass of the remote group (see Figure 7.2).

Figure 7.2: The point of view of each individual process. The system of bodies includes all bodies of its group while each remote group is approximated by a single equivalent body. -
The total mass of a group of bodies is constant during the simulation. Therefore it is calculated once in the very beginning of the execution of the algorithm. Each process receives from the other processes their calculated total masses, and stores all these values in its memory.
-
The position of the center of mass of a group is a function of time. Therefore, at each step of the simulation, a process computes the center of mass of its group and sends it to other processes. Each process receives from the other processes their calculated center, of mass and stores all the centers in its memory.
-
It is presumed that at every step of the simulation the updated system of bodies is displayed on the computer. For this reason all groups of bodies are gathered by the process responsible for effecting the visualization which is the host-process.
In general, since different groups of the system of bodies have different sizes, different processes perform different volumes of computation, and different volumes of data are transferred between different pairs of processes. Like the parallel algorithm of Section 6.8 for calculating the mass of a metallic construction welded from N heterogeneous rails, the heterogeneity of the algorithm above is induced by the irregularity of the problem being solved by the algorithm. Schematically this algorithm can be expressed by the following pseudocode:
Initialize groups of bodies on the host-process Visualize the groups of bodies Scatter the groups across processes Compute masses of the groups in parallel Communicate to share the masses among processes while(1) { Compute centers of mass of the groups in parallel Communicate to share the centers among processes Update the state of the groups in parallel Gather the groups to the host-process Visualize the groups of bodies } The core of the mpC application, implementing the preceding algorithm, is the specification of its performance model:
nettype Nbody(int m, int k, int n[m]) { coord I=m; node { I>=0: bench*((n[I]/k)*(n[I]/k)); }; link { I>0 : length*(n[I]*sizeof(Body)) [I]->[0]; }; parent [0]; }; Informally, it looks like a description of an abstract network of computers (which execute the algorithm) complemented by a description of the workload of each processor and each communication link of this abstract network.
From the mpC language point of view, the description defines a parameterized type of abstract networks. The first line of this network type of definition introduces the name Nbody of the network type and a list of parameters, including the integer scalar parameters m and k, and the vector parameter n of m integers. The next line declares the coordinate system with which the abstract processors will be associated. It introduces the coordinate variable I, which ranges from 0 to m-1. The following line associates the abstract processors with this coordinate system, and describes the (absolute) volume of computation to be performed by each processor.
As a unit of measure, the volume of computation performed by some benchmark code is used. In this particular case it is assumed that the benchmark code updates the position and velocity of bodies of a single group of k bodies. It is also assumed that the ith element of vector n is just equal to the number of bodies in the group updated by the ith abstract processor.
The number of operations to update the position and velocity of bodies of one group is proportional to the number of bodies in this group squared. Therefore the volume of computations to be performed by the I-th abstract processor is (n[I]/k)2 times bigger than the volume of computations performed by the benchmark code. This line just says it.
The following line specifies the volume of data in bytes to be transferred between the abstract processors during execution of the algorithm. This line simply says that the ith abstract processor (i = 1,...) will send data characterizing all of its bodies to the host-processor, where they should be visualized.
Note that the definition of the Nbody network type actually specifies the volume of computation and communication during a single iteration of the main loop of the algorithm. This is a good approximation because practically all computations and communications concentrate in this loop. Therefore the total execution time of this algorithm is approximately equal to the execution time of a single iteration multiplied by the total number of iterations.
In general, the mpC code implementing the heterogeneous parallel algorithm takes the following form:
#include <stdio.h> #include <stdlib.h> #include <mpc.h> typedef double Triplet[3]; typedef struct { Triplet p; // Position Triplet v; // Velocity double m; // Mass } Body; nettype Nbody(int m, int k, int n[m]) { coord I=m; node { I>=0: bench*((n[I]/k)*(n[I]/k));}; link { I>0: length*(n[I]*sizeof(Body)) [I]->[0];}; parent [0]; }; repl M; // The number of groups double [host]t; // The time variable repl int tgsize; // The number of bodies in a test group #include "serial_code.h" void [net Nbody(m, l, n[m]) g] ShareMasses (void *masses) { double mass; repl i, j; typedef double (*pArray)[m]; mass = (*(pArray)masses)[I coordof i]; for(i=0; i<m; i++) for(j=0; j<m; j++) [g:I==i](*(pArray)masses)[j] = [g:I==j]mass; } void [net Nbody(m, l, n[m]) g] ShareCenters(void *centers) { Triplet center; repl i, j; typedef Triplet (*pArray)[m]; center[] = (*(pArray)centers)[I coordof i][]; for(i=0; i<m; i++) for(j=0; j<m; j++) [g:I==i](*(pArray)centers)[j][] = [g:I==j]center[]; } void [*]main(int [host]argc, char **[host]argv) { // Get the number of groups on the host-process // and broadcast it to all processes M = [host]GetNumberOfGroups(argv[1]); { repl N[M]; // Array of group sizes Body *[host]Groups[[host]M]; // Initialize N and Groups on the abstract host-processor [host]: InputGroups(argv[1], M, &N, &Groups); // Broadcast the group sizes across all processes N[] = [host]N[]; // Set the size of test group to the size of the smallest // group in the system of bodies tgsize = [?<]N[]; // Update performance characteristics of the executing // physical processors { Body OldTestGroup[tgsize], TestGroup[tgsize]; typedef Body (*pTestGroup)[tgsize]; // Make the test group consist of first tgsize bodies // of the very first group of the system of bodies OldTestGroup[] = (*(pTestGroup)Groups[0])[]; recon UpdateGroup(tgsize, &OldTestGroup, &TestGroup, 1, NULL, NULL, 0); } // Define an abstract mpC network, g, and specify // computations and communications on the network // implementing the heterogeneous parallel algorithm { net Nbody(M, tgsize, N) g; int [g]myN, // Size of my group [g]mycoord; // My coordinate in network g mycoord = I coordof g; myN = ([g]N)[mycoord]; { double [g]Masses[[g]M]; // Masses of all groups Triplet [g]Centers[[g]M]; // Centers of mass of all groups Body [g]OldGroup[myN], // State of my group at time t [g]Group[myN]; // State of my group at time t+DELTA repl [g]gc, // Counter of groups in the system of bodies [g]bc, // Counter of bodies in group [g]gsize; // Size of group //Scatter groups for(gc=0; gc<[g]M; gc++) { [host]: gsize = N[gc]; { typedef Body (*pGroup)[[host]gsize]; [g:I==gc]Group[] = (*(pGroup)Groups[gc])[]; } } // Visualize the system of bodies on the computer display // associated with the abstract host-processor [host]: FirstDrawGroups(argc, argv, M, N, Groups); // Compute masses of the groups in parallel for(bc=0, Masses[mycoord]=0.0; bc<myN; bc++) Masses[mycoord] += Group[bc].m; // Communicate to share the masses among abstract // processors of network g ([([g]M, [g]tgsize, [g]N)g])ShareMasses(Masses); // Main loop of the parallel algorithm do { OldGroup[] = Group[]; // Compute centers of masses of the groups in parallel Centers[] = 0.0; for(bc=0; bc<myN; bc++) Centers[mycoord][] += (Group[bc].m/Masses[mycoord])*(Group[bc].p)[]; // Communicate to share the centers among abstract // processors of network g ([([g]M, [g]tgsize, [g]N)g])ShareCenters(Centers); // Update the groups of bodies in parallel. OldGroup // contains the state of each group at time t. // Group will contain the state of each group // at time t+DELTA. ([g]UpdateGroup)(myN, &OldGroup, &Group, [g]M, &Centers, &Masses, mycoord); // Increment the time variable t t += DELTA; // Gather all groups to the abstract host-processor for(gc=0; gc<[g]M; gc++) { gsize = [host]N[[host]gc]; { typedef Body (*pGroup)[gsize]; (*(pGroup)Groups[gc])[] = [g:I==gc]Group[]; } } // Visualise the groups on the computer display // associated with the abstract host-processor if(DrawGroups([host]M, [host]N, Groups)<0) MPC_Exit(-1); } while(1); [host]: DrawBye(M, N, Groups); } } } } The code presented here does not contain the source code of the mpC program, which specifies the routine serial computations peformed by a single process to update the state of a group of bodies or to visualize the system of bodies. It only contains the mpC-specific parallel code. The serial routine code is contained in the file source_code.h, and it is included in the program with an include directive. The full code of the mpC application can be found in Appendix A.
In the preceding code there are three key components that control the mapping of the heterogeneous parallel algorithm to the executing network of computers:
-
The definition of the network type Nbody.
-
The recon statement updating performance characteristics of physical processors.
-
The definition of the abstract mpC network g.
The recon statement uses a call to function UpdateGroup that updates the state of a test group of tgsize bodies, in order to estimate the speeds of the physical processors. The total volume of computations performed by each abstract processor of network g mainly falls into execution of calls to function UpdateGroup. Therefore the obtained speed estimations of the physical processors will be very close to their actual speeds in executing the program.
The recon statement not only updates the performance characteristics of the physical processors but also specifies a unit of measure for the absolute volume of the computation. It is assumed that after the execution of the recon statement and before the execution of the next recon statement, the absolute volume of computation is measured in calls to function UpdateGroup, which updates the state of a group of tgsize bodies. Thus, if some computations are specified to be of volume v in this time slot, the execution time of the computations will be considered equal to the execution time of the call to function UpdateGroup updating the state of a test group of tgsize bodies multiplied by v, tcomp = tunit x v.
The recon statement is executed right before definition of network g. The definition causes the creation of an mpC network of type Nbody with the following actual parameters:
-
Integer variable M specifying the actual number of groups of bodies.
-
Integer variable tgsize specifying the actual size of the group, whose bodies’ position and velocity are updated by the benchmark code.
-
Array N of M integers containing actual sizes of the groups of bodies of the modeled system.
These parameters in concert with the definition of the network type Nbody and the test code provided by the recon statement specify that
-
network g will consist of M abstract processors,
-
the absolute volume of computation performed by the ith abstract processor will be (N[i]/tgsize)2 times bigger than the volume of computation performed by a call to function UpdateGroup updating the state of a group of tgsize bodies, and
-
the ith abstract processor will send N[i]*sizeof(Body) bytes to the abstract host-processor.
In effect the volume of computations and communications performed by a single iteration of the main loop of the program is specified in the program with high accuracy. This information, along with information about the performance characteristics of the physical processors and communication links, is used to map the abstract processors of network g to the parallel processes of the parallel program.
The mapping is performed at runtime to minimize the execution time of a single iteration of the main loop. Note that the performance characteristics of the physical processors are refreshed by the recon statement directly before the mapping is performed. Therefore the mapping is based on the actual speeds of the physical processors demonstrated during the execution of the program. By all these means the mpC programming system can accurately estimate the execution time of a single iteration of the main loop for any particular mapping of abstract processors to parallel processes of the program, and then select mapping leading to faster execution.
Note that the mpC program implicitly assumes that the size of type Body is the same on all abstract processors. Because of this condition the communications time element can be accurately estimated. In heterogeneous environments this condition may not be satisfied. The following slight modification of the definition of the Nbody network type makes the program independent of this condition:
nettype Nbody(int m, int k, int n[m]) { coord I=m; node { I>=0: bench*((n[I]/k)*(n[I]/k));}; link { I>0: length(Body)*n[I] [I]->[0];}; parent [0]; }; By default, a link declaration uses byte as a unit of measure and so specifies the volume of communication data in bytes. The link declaration in the network type above defines a unit of measure different from byte. It specifies that the volume of data transferred between abstract processors be measured in Bodys. This means that the data units are now equal in size to that of type Body on the abstract processor sending the data.
The next mpC application implements an algorithm of parallel multiplication of matrix A and the transposition of matrix B on a heterogeneous network; that is, it performs matrix operation C = A x BT, where A, B are dense square n x n matrices. The algorithm is a result of slight modification of the algorithm presented in Section 6.10.
The modification is aimed at taking into account the contribution of communication operations into the execution time of the algorithm. As communication overheads may exceed gains due to the parallel execution of computations, the distribution of computations across all available physical processors does not always result in the fastest execution of the matrix-matrix multiplication. Sometimes certain subnetworks of the computers better execute the algorithm.
In general, there is some optimal subset of the available physical processors that will perform the matrix-matrix multiplication. The modified algorithm includes such an optimal subset in the computations. The main problem that must be solved by the modified algorithm of parallel matrix-matrix multiplication is that of finding a subset of physical processors to execute the algorithm faster than the other subsets.
Suppose that there are, in total, p physical processors available and that we can estimate the execution time of the algorithm on each given subset. Then, to arrive at an accurate solution, we should examine as many as 2p possible subsets to find the optimal one. Obviously that computational complexity is not acceptable for a practical algorithm. Therefore the algorithm will search for an approximate solution that can be found in some reasonable time. Namely, instead of 2p subsets, only p subsets {si}pi1 will be examined. The subsets are defined as follows:
-
Subset s1 consists of the processor running the host-process.
-
Subset si consists of all processors of subset si1 and the fastest of the remaining processors (i = 2,..., p).
This scheme assumes that among subsets with the same number of processors, the fastest execution of the algorithm is provided by the subset having the highest total speed of processors. An obvious case when this approach may not work well is when a very slow communication link connects the fastest processor with other processors. The following mpC code implements this modified algorithm:
#include <stdio.h> #include <stdlib.h> #include <mpc.h> #include <float.h> void Partition(), SerialAxBT(); nettype ParallelAxBT(int p, int n, int r, int d[p]) { coord I=p; node { I>=0: bench*((d[I]*n)/(r*r)); }; link (J=p) { I!=J: length*(d[I]*n*sizeof(double)) [J]->[I]; }; parent [0]; }; int compar(const void *px, const void *py) { if(*(double*)px > *(double*)py) return –1; else if(*(double*)px < *(double*)py) return 1; else return 0; } int [*]main(int [host]argc, char **[host]argv) { repl int n, r, p, *d; repl double *speeds; n = [host]atoi(argv[1]); r = [host]atoi(argv[2]); // Run a test code in parallel by all physical processors // to refresh the estimation of their speeds { repl double a[r][n], b[r][n], c[r][n]; repl int i, j; for(i=0; i<r; i++) for(j=0; j<n; j++) { a[i][j] = 1.0; b[i][j] = 1.0; } recon SerialAxBT((void*)a, (void*)b, (void*)c, r, n); } // Detect the total number of physical processors p = MPC_Get_number_of_processors(); speeds = calloc(p, sizeof(double)); d = calloc(p, sizeof(int)); // Detect the speed of the physical processors MPC_Get_processors_info(NULL, speeds); // Sort the speeds in descending order qsort(speeds+1, p-1, sizeof(double), compar); // Calculate on the abstract host-processor the optimal number // of physical processors to perform the matrix operation [host]: { int m; struct {int p; double t;} min; double t; min.p = 0; min.t = DBL_MAX; for(m=1; m<=p; m++) { // Calculate the size of C slice to be computed by // each of m involved physical processors Partition(m, speeds, d, n, r); // Estimate the execution time of matrix-matrix // multiplication on m physical processors t = timeof(net ParallelAxBT(m, n, r, d) w); if(t<min.t) { min.p = m; min.t = t; } } p = min.p; } // Broadcast the optimal number of involved processors to all // parallel processes of the program p = [host]p; // Calculate the size of C slice to be computed by // each of p involved physical processors Partition(p, speeds, d, n, r); { net ParallelAxBT(p, n, r, d) w; int [w]myn; myn = ([w]d)[I coordof w]; [w]: { double A[myn/r][r][n], B[myn/r][r][n], C[myn/r][r][n]; repl double Brow[r][n]; int i, j, k; for(i=0; i<myn/r; i++) for(j=0; j<r; j++) for(k=0; k<n; k++) { A[i][j][k] = 1.0; B[i][j][k] = 1.0; } { repl int PivotNode=0, RelPivotRow, AbsPivotRow; for(AbsPivotRow=0, RelPivotRow=0, PivotNode=0; AbsPivotRow < n; RelPivotRow += r, AbsPivotRow += r) { if(RelPivotRow >= d[PivotNode]) { PivotNode++; RelPivotRow = 0; } Brow[] = [w:I==PivotNode]B[RelPivotRow/r][]; for(j=0; j<myn/r; j++) SerialAxBT((void*)A[j][0], (void*)Brow[0], (void*)(C[j][0]+AbsPivotRow), r, n); } } } } free(speeds); free(d); } The preceding code does not contain the source code of functions Partition and SerialAxBT, which is identical to that presented in Section 6.10. It is presumed that there is one-to-one mapping between processes of the parallel program and physical processors of the executing network of computers. That is, the total number of processes of the mpC program is assumed to be equal to the total number of available physical processors with each processor running exactly one process.
Major changes are made in the definition of the network type ParallelAxBT. Recall that this network type describes the performance model of the implemented algorithm of parallel matrix-matrix multiplication. Now this performance model includes the absolute volume of computation performed by each abstract processor and the volume of data transferred between each pair of abstract processors.
It is presumed that the test code, which is used for estimation of the speed of physical processors, multiplies rxn and nxr matrices, where r is small enough compared to n and supposed to be a multiple of n. It is also presumed that ith element of vector parameter d is just the number of rows in the C slice mapped to the ith abstract processor of the mpC network performing the algorithm.
Correspondingly the node declaration specifies that the volume of computation to be performed by the ith abstract processor is d[i]*n/(r*r) times bigger than the volume of computation performed by the test code. The link declaration specifies that each abstract processor will send its B slice to each of other abstract processors.
The recon statement updates the estimation of the speed of the physical processors of the executing network by using serial multiplication of test rxn and nxr matrices with the function SerialAxBT. The computations performed by each abstract processor will mainly fall into the execution of calls to SerialAxBT. Therefore the speed of the physical processors returned in array speeds by function MPC_Get_processors_info will be an accurate approximation of the real speed demonstrated by the physical processors during execution of the program. The recon statement also specifies that a call to function SerialAxBT multiplying rxn and nxr matrices will be used as a unit of measure of the absolute volume of computation in this program.
There is a brand new block in this program executed by the abstract host-processor. The block calculates the number of physical processors that will perform the parallel matrix-matrix multiplication. In this block the operator timeof estimates the execution time of the parallel algorithm, which is specified by its operand, without its real execution.
The only operand of the timeof operator looks like a definition of the mpC network. The definition specifies the performance model of a parallel algorithm providing the following information:
-
The number of abstract processors performing the algorithm.
-
The volume of computation performed by each abstract processor measured in units specified by the most recently executed recon statement. In our program the volume will be measured in calls to function SerialAxBT multiplying rxn and nxr matrices.
-
The volume of communication between each pair of the abstract processors measured in bytes.
Based on this information and the most recent performance characteristics of physical processors and communication links, the operator does not really create an mpC network specified by its operand. Instead, it calculates the time of execution of the corresponding parallel algorithm on such a network as if it were created at this point of the program. The operator returns the calculated time in seconds.
Thus, at each iteration of the for loop in the block, the timeof operator returns the calculated time of execution of the matrix-matrix multiplication on an mpC network of m abstract processors (m = 1,..., p). As there is one-to-one mapping between abstract processors of the mpC network and physical processors, the mpC network represents the subset of physical processors consisting of the host-processor and m-1 fastest processors. After execution of this block, the value of variable p on the host-processor will be equal to the number of processors in the subset providing the fastest execution of the algorithm.
The definition of network w specifies exactly this optimal number of processors. Therefore the parallel matrix-matrix multiplication itself will be performed by the very subset of physical processors that is found to provide the fastest execution of the algorithm.
Note, again, that the mpC program above implicitly assumes that the size of double is the same on all abstract processors. The following slight modification of the definition of the ParallelAxB network type makes the program independent of the condition:
nettype ParallelAxBT(int p, int n, int r, int d[p]) { coord I=p; node { I>=0: bench*((d[I]*n)/(r*r)); }; link (J=p) { I!=J: length(double)*(d[I]*n) [J]->[I]; }; parent [0]; }; EAN: N/A
Pages: 95