Cluster Architecture
By the architecture of a cluster, I mean the node topology and the techniques employed for achieving scalability. Even for the end user of a clustered JMS messaging system, it is beneficial to understand the architecture used within the cluster, as this will have a big impact on the cluster's capabilities. Some architectures are inherently good at providing certain aspects of scalability, and inherently poor at others, regardless of the actual implementation details.
There is no limit to the number of different possible cluster architectures, but the variety presented in this chapter should be a good representation of the ones most commonly used in practice. In addition, I will discuss a number of clustering issues that must be considered in any architecture. At this point in the chapter, it is important to make the distinction between the two main types of cluster architecture: shared storage (shared disk or shared database) and private storage (often referred to by the term shared nothing) in which each hardware node maintains its own storage.
Shared storage eliminates many complications involved in cluster design, but creates others. The complications introduced by shared storage are relatively generic and not specific to the requirements of JMS. For this reason, shared storage will be discussed in its own section, and all other sections of this chapter will assume the private storage case unless explicitly stated otherwise.
The Pub/Sub and PTP messaging domains represent, in many ways, two completely different types of messaging. This distinction is particularly true with clustering, as certain architectures provide much better scalability for one domain than the other. For this reason I will begin by pointing out the issues particular to each domain, and then move on to discuss particular aspects of cluster architectures.
Clustering in the Publish/Subscribe Domain
In the Pub/Sub domain, a copy of every message in a topic is sent to every subscriber that is interested in that topic. This allows more possibilities for parallel processing than in the PTP domain, where the cluster must guarantee that a message is not delivered to more than one receiver. With Pub/Sub, every message can be replicated to each cluster node. Each node can forward the message to each subscriber that it knows about with no need to be concerned about the subscribers on other nodes. If a node has no subscribers, it may just discard the message. Since the basic clustering scenario for Pub/Sub is simple, some vendors only provide clustering in this domain.
In reality, of course, clustering in this domain is not quite as simple as this description would lead you to believe. There are a number of factors that add complications, namely durable subscribers, transactions, and failure recovery. Durable subscribers themselves are described in more detail in Chapter 2.
Durable Subscribers
In order to support durable subscribers, messages must be stored somewhere in the cluster. There are two basic approaches to this: full replication, in which every message is stored on every node, or topic home, in which one node is designated as the "home" for a particular topic and all messages for that topic are stored there. The latter option could be extended to include one or more backup nodes that could store messages in addition to the topic home, and provide redundant storage in case the topic home fails. I will ignore this case for the moment to keep the discussion simple.
Full Replication
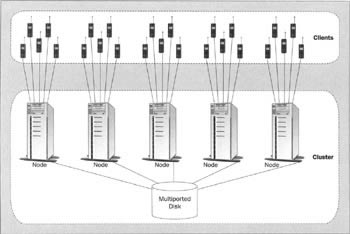
Full replication requires the least coordination among the cluster nodes. Each message is replicated to every node and the nodes can otherwise operate quite independently. Not only does this simplify the architecture, it provides superb redundancy. Since every node stores every message, any number of nodes may fail at once without losing messages as long as at least one survives. The diagram below shows the topology of full replication supporting durable subscribers:
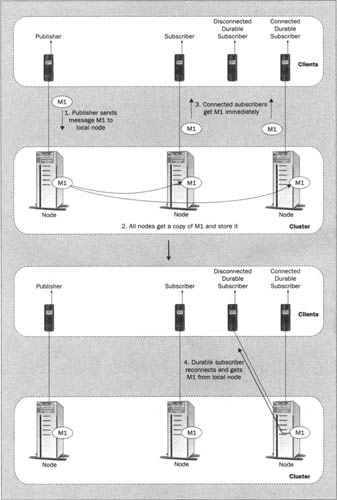
The price for this superb redundancy is poor storage scalability: adding nodes to the cluster will not increase the total storage capacity of the cluster. Moreover, if one node has less storage capacity than the others (it has less hard disk capacity or shares this capacity with other applications), then the entire storage capacity of the cluster is limited to the capacity of that one node.
There are other complications in the case of full replication. I mentioned above that the nodes could operate independently once the messages are copied. This is largely true if all nodes will unconditionally store every message until it expires. To gain more efficiency though, a server will often not store messages in which no durable subscriber is interested. Additionally, the server will usually try to delete messages that have been consumed by all known durable subscribers.
This is not a problem if a durable subscriber will always reconnect to the same node, but this can seldom be guaranteed. Since the durable subscriber may reconnect to any node, this node must have all of the messages in which the durable subscriber is interested. This requires that the nodes share information about durable subscribers: subscription, message selector, subscription termination, and message acknowledgment. Propagating each message acknowledgement to every node could lead to a lot of communication traffic.
Since it is actually not essential to delete each message immediately after the last durable subscriber has acknowledged it, it would be sufficient to send periodic summaries of the acknowledgments, or employ some other protocol between the nodes that enables them to agree on which messages may be removed from storage. A problem arises here when a durable subscriber disconnects and immediately reconnects to another node. That node may not be aware of the most recent message acknowledgments that that subscriber has made, and try to deliver the most recent messages again. Thus, extra logic would be required to handle reconnections properly.
Another shortcoming of full replication, which can offset the benefit of the independence of the nodes, is that it can require substantial network bandwidth. This is a major factor in any architecture, but in full replication, it will become a performance bottleneck quite quickly. If unicast communication is used to interconnect the nodes (as is often the case), then a cluster of n nodes must copy each message n-1 times over the network. This can be reduced to copying each message only once if multicast communication is employed within the cluster.
| Note | Progress SonicMQ and FioranoMQ are examples of JMS providers that use fall replication to provide clustering in the Pub/Sub domain. |
Topic Home
The topic home approach allows scalability of storage space by distributing the responsibility for storing messages in different topics over different nodes. More advanced schemes could potentially distribute message storage for one topic over multiple nodes, but I will not discuss these here in the interest of keeping things simple.
There are two basic variations of the topic home, which are shown as "version 1" and "version 2" in the diagrams overleaf. In version 1, all messages are distributed to all nodes, and the node that is the topic home stores the message, in addition to distributing it to any connected subscribers. In version 2, all messages are sent directly to the topic home, and then the topic home distributes them to those nodes that have subscribers:
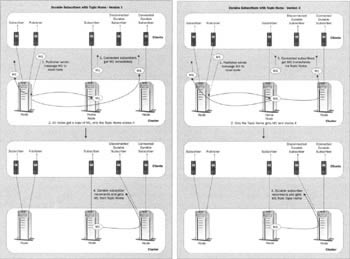
Using unicast communication between the nodes can potentially save network bandwidth. When using multicast, bandwidth would actually need to increase as every message must be sent twice over the network instead of once. When a durable subscriber reconnects to a node, that node must contact the topic home and retrieve all messages that were stored while that durable subscriber was offline. This gives rise to a large potential increase in bandwidth usage compared to full replication if multiple durable subscribers with interest in the same messages reconnect to the same node at different times, then the same messages must be transferred to that node from the topic home several times.
Topic home solves another potential problem with durable subscribers. Since they can reconnect at any time, and they can potentially reconnect to any node, every node must offer the same "view" of the topic state at the same time. Although one would expect durables to disconnect for longer periods of time, there is nothing to stop them from disconnecting and reconnecting immediately to another node. In the case of the topic home, everything is coordinated from a central point, and the reconnecting subscriber will receive all messages, as it should. As mentioned above, this guarantee is more difficult to achieve with full replication.
| Note | In the PTP domain the corresponding concept is called queue home. Later in this chapter I will use the term destination home to generically refer to both of these. |
Transactions
The general implications of clustering on transacted messages will be presented in a separate section below. Here I will briefly comment on some of the implications relevant to the immediate discussion. Transactions give rise to another situation, besides durable subscribers, in which published messages must be stored. This is because a transacted message cannot be distributed until it is committed, and the commit could occur some time after the message is published.
The simplest variant is to temporarily store the message on the node to which the publisher is connected. When the transaction is committed, processing continues largely as described in the last section. If the producer reconnects to another node before committing, then the transaction must be aborted. If the transaction is large, then a correspondingly large amount of network traffic is generated immediately upon commit.
More refined schemes will try to move the uncommitted messages to other nodes as soon as they are published. If a topic home is used, then version 2 in the diagram above is the natural choice, as the message can be forwarded to the topic home and the topic home can take care that it is not distributed further until committed. In the other schemes, where all messages are sent directly to all other nodes for immediate distribution to currently connected subscribers, extra logic is required to guarantee that the transacted messages are stored and not distributed until the commit comes. This fully distributed case make the atomic properties of the transaction more difficult to guarantee.
Failure Recovery
Failure recovery scenarios tend to complicate operations that are quite simple under normal circumstances. We already looked at the case of a durable subscriber reconnecting above. If the cluster provides support for clients reconnecting after losing their connection to the server, possibly due to failed node, then the complications that arose for durables could apply to normal subscribers as well. In this case it may not even be possible for the cluster to recover the state of the subscriber without the subscriber's help, as the failed node may not have had a chance to report the most recent acknowledgements to the rest of the cluster. This implies that all subscribers need to be treated like durable subscribers, since they can briefly disconnect and reconnect at any time.
Another point to keep in mind is that after a node fails it must sooner or later be replaced. The replacement node must get copies of all messages to store from other nodes before it can be integrated into the cluster. In the case of full replication, this includes all messages for all durable subscribers, which could amount to a huge volume of data. In the case of topic homes, the volume of data for a single node should be much smaller, but recovery is only possible if there was a second node acting as a backup for the node that failed. Remember we did not discuss the implications of this in detail.
Despite all the different tradeoffs involved in the selection of a Pub/Sub clustering architecture, full replication is a clear favorite, since it solves both connection load balancing and high availability with one elegant concept. It does very little for other aspects of scalability, but in practice the two aspects that it does address are the most common reasons for employing clustering. As we shall see next, there is no corresponding single favorite in the PTP domain.
Clustering in the Point-to-Point Domain
If the PTP domain were truly PTP for a queue as a whole, then it would behave like Pub/Sub with only one subscriber permitted for each topic. This would make clustering actually simpler than in the Pub/Sub domain. In reality, JMS allows a PTP queue to have any number of receivers. The PTP aspect applies to individual messages and not to destinations. This makes message distribution more complex in a clustered sever.
Since the same message may never be delivered to multiple receivers, the decision as to which receiver should be able to consume a particular message must be coordinated throughout the cluster. PTP messages must be stored if they cannot be consumed right away. In many ways a queue resembles a topic that has exactly one durable subscriber: a message must be stored until it is consumed once, and then it is safe to delete it immediately. If it were not for the fact that multiple receivers can be connected simultaneously, a queue could actually be modeled as a special case of a topic.
Distribution and Storage
The simplest way to coordinate the distribution of messages is to centralize all distribution logic on one node. This gives rise to the notion of a queue home node for distribution. In other words, for each queue there is one node that has the responsibility for comparing the queue's messages to the list of known receivers and their message selectors, and determining which message should be delivered to which receiver. Since PTP messages must be stored, this concept can be combined with the notion of a queue home for storage, similar to the topic home concept discussed for the Pub/Sub domain.
In theory, each node could contain logic for distributing messages and then employ some form of protocol for reaching consensus with the other nodes before actually sending a message to a receiver. This would add quite a bit of complexity to the cluster. In addition to requiring some form of voting algorithm to determine which node is permitted to distribute a message, the cluster also needs to be able to determine whether message delivery was successful. This is important in the case that the selected node fails, because if it failed before delivery was complete then the voting process must be reinitiated. On the other hand, this scheme could also provide more overall robustness in the case of node failure.
Many voting algorithms require only a majority of nodes to agree on a decision. This means that if a minority of nodes are not reachable, processing can continue without the need to first determine if the nodes have failed and without having to wait for any fail-over processes to complete. The effectiveness of this must be compared to the complexity involved in making the queue home concept provide high availability with a queue home backup.
Full Replication
Even though the PTP domain tends to be better served by centralized distribution logic, the storage need not necessarily be centralized. For example, a full replication scheme, as described above for topics, could be employed. This would provide full redundancy and enhance high availability. It would also ensure that a particular message is readily available on the node on which it will be consumed, even though the decision as to which receiver should consume it is made elsewhere.
A full replication scheme for queues could be quite inefficient, since it requires all messages to be sent to all nodes, even though it is known in advance that it will only be consumed on one of them. The degree to which this is inefficient depends on the cost of distributing a message to multiple nodes, which is high when unicast networking is used, and low when multicast is used.
Queue Homes
The concept of a queue home for storage is more palatable here than it is with topics. Since the logic of queue homes for distribution will probably be incorporated anyway, the additional effort in implementing queue homes for storage, along with backup nodes for high availability, is less in this case. The advantage to be gained by doing this is an additional dimension of scalability, namely scalability of storage capacity as described in the section on scalability above.
Message Routing
An alternative to the concept of queue homes is to employ a message routing scheme. In this scheme, each node keeps a list of which other nodes have receivers for a certain queue. As each message is published, the node to which the publisher is connected routes the message directly to one of the nodes that has receivers for that message. This scheme can allow more parallelism between the nodes and reduce inter-node communication compared to other architectures.
This comes at a price of course. A message routing cluster does not provide the outward appearance of a single monolithic server, but appears more like a loosely associated group of cooperating, but separate message servers. This has implications in terms of fairness and the order of message delivery. For Point-to-Point messaging, the fairness issue means that receivers subscribed to same queue, but connected to different nodes cannot expect to receive messages at the same rate (see "Starvation" below). For Pub/Sub messaging it means that subscribers connected to different nodes cannot all expect to receive a given message at the same time. For both types of messaging, it is difficult to guarantee in-order message delivery across the whole cluster.
Each node in a message routing cluster only stores messages that are destined for consumption on that node, so it can make these local distribution decisions autonomously and in parallel with the other nodes.
Starvation
Message routing is desirable for nodes that are geographically distributed and require more independence from each other due to the relatively high cost and latency of inter-node communication. This can, however, easily lead to receiver starvation, where some nodes have a long queue of messages waiting to be delivered to local receivers, while another node has no messages even though it has idle receivers that could consume them. This could happen if one node has very slow receivers, or if a new receiver connects (or an existing receiver reconnects) to a node that previously had no receivers for that particular queue.
Delivery Order
A problem related to starvation is delivery order. Although one of the tenets of JMS is guaranteed inorder delivery, it is impossible to guarantee absolute ordering of messages across multiple receivers unless a message is not delivered until the previous message is acknowledged. This would have dramatic performance implications, and would prevent multiple receivers from processing messages in parallel.
The actual guarantee made by JMS is that all messages consumed by one receiver that originate from the same publisher will be consumed in the order in which the publisher sent them. Despite this, the concept of a message queue is global first in, first out ordering. JMS providers are expected to maintain a global ordering reasonably well across multiple receivers.
Unreasonably Late Delivery
The same conditions that lead to starvation could lead to unreasonably late delivery. This is best illustrated with an example: A publisher sends two messages, A and B, in that order to the same queue. A gets routed to a node that has a large number of undelivered messages for that queue and a very slow receiver. B gets routed to a node that has no undelivered messages for that queue, and is consumed immediately. The messages A and B get consumed out of order. It might be tolerable for them to be out of order by a few seconds, but in an extreme case, message A may be delayed by minutes or hours. Some applications that depend on the "in order" delivery of messages would have trouble functioning correctly in this case.
This problem can be even more acute in the case that the receiver on the node where message A is stored closes before A is consumed. In order to avoid having the message sit indefinately on that node, the only reasonable action is to reroute the message to a node that still has receivers. Consider what happens if the only other receiver in the cluster is the one that already consumed message B. Now it is impossible to deliver the message without violating the strong in-order requirements imposed byJMS. Message routing increases the risk of out of order delivery during normal operation.
| Note | In all fairness to message routing, I should mention that there are other scenarios in which messages can be delivered out of order even when message routing is not used. These are usually failure scenarios that should occur infrequently. |
The use of a flow control scheme within the cluster could significantly reduce the likelihood of receiver starvation and out of order delivery. This would involve storing each sent message at the node of the publisher until one or more nodes that have potential receivers of that message indicate that they are likely to be able to distribute messages to those receivers with little or no delay. This indication could take the form of flow start and flow stop messages that are sent to all other nodes in the cluster depending on how many undelivered messages that node has for a particular queue.
As with the queue home concept, message routing does not address redundancy and high availability. Thus backup nodes and fail-over logic must be implemented separately.
Failure Recovery
As with the Pub/Sub domain, there are some failure scenarios that cause particular difficulty in the PTP domain. One of these is the case of a node failing and its receivers reconnecting to another node. In the case of full replication and queue home schemes described above, this presents very little difficulty. Since message distribution must either be centralized or well coordinated throughout the cluster, there is very little danger of the new node presenting a different view of the state of the message queue. Not so with message routing; this scheme falls short here too. In this case the receiver finds a completely different set of messages on the new node, some of which may be older than other messages that it already consumed.
Another failure scenario that causes problems for PTP messaging is the case of a receiver failing before it has acknowledged all of the messages that it has received. This case is not specific to clustering, but it is worth mentioning in the context of the current discussion. From the point of view of the JMS provider, if a message has not been acknowledged, it has not been consumed. Any messages that were distributed to the now dead receiver, which this receiver did not acknowledge before failing, must be deliver to another receiver. Remember that JMS guarantees exactly once delivery for persistent messages. By the time that the server detects the failure of the first receiver, all other receivers for the same queue may have already consumed later messages from the same sender. In this case it is not possible to deliver the messages without violating the strict JMS requirements for in-order delivery.
Balancing Load
When using a cluster to increase server capacity, whether for connections, throughput or storage, there must be some mechanism in place to ensure that these resources are fairly utilized across all the nodes of the cluster. This is the balancing aspect that should be inherent in load balancing. If the capacity of the whole cluster is reduced just because one machine is overloaded, then the cluster is not scalable.
When people talk about load balancing in the context of a clustered JMS message server, they are mostly referring to connection load balancing. As mentioned previously, the connection limit of a Java VM is often the first scalability limit encountered in a messaging system. Given that the cluster has no way to know how much message volume each connection will generate in the future, balancing connections among the nodes is often the best means available for balancing overall load. (More advanced schemes for getting around this will be discussed below.)
In the case where a cluster stores messages on the node to which the publisher is connected (instead of having central storage for each destination), connection balancing will effectively determine the balancing of message storage across the nodes. For clusters, the aim of achieving scalable storage capacity, and of balancing the storage across nodes is a highly relevant issue.
Firstly, we'll define some of the terminology needed to discuss load balancing, and the then move on to discuss some common techniques for implementing it.
| Note | Note that I prefer the use of the term "fair" to "even", as an evenly balanced load may not be desired, especially when machines with different capabilities are mixed in the same cluster. |
Load Monitoring
This is a very important concept in conjunction with any load-balancing scheme. The most effective decisions about distributing load (connections, storage) can be made only if the current load for all nodes is known. The first step here, of course, is to define "load" appropriately. This may be simplistic in that it measures just the number of connections per node, or it may be a complex function that takes many factors into account, such as CPU utilization, memory usage, and I/O volume.
All of the individual system parameters that contribute to this load calculation must be monitored by each node and periodically sent to the entities (other nodes, connection brokers) that are responsible for distributing load fairly. The definition of fair may also be non-trivial if the nodes in the cluster do not have identical hardware capacities. In this case it may be necessary for each node to distribute information about its basic capabilities in addition to load parameters.
Remember though, pure Java programs have difficulty obtaining basic system information like free memory and free disk space. Java-based cluster nodes must interact with native code (either via JNI or a separate process) to get access to all possible system parameters. Static parameters such as total available memory or disk space can be passed to the node as configuration parameters.
Static Load Balancing
This means a critical decision about how to balance load is made once and then never changed. Specifically, the decision of which node a client should connect to is made at the time of connection, and then the client cannot change nodes later, even if the load across the nodes becomes unbalanced. For message storage, this might mean that the home node for a destination is determined when the destination is created, and cannot be changed later.
Static load balancing schemes that distribute load automatically must make simplistic assumptions about load distributions. These assumptions are that all connections generate the same message volume, and that all destinations will handle the same message volume and require the same amount of storage. The cluster cannot automatically predict how connections and destinations will be used at the time that they are created.
The only way around this is to force the system administrator to pre-configure the anticipated load generated by each client and handled by each destination, or worse yet, that the system administrator be required to pre-configure the location of each destination (in the case of destination homes) and pre-configure the node to which each client should connect.
Dynamic Load Balancing
This means the load can be rebalanced at any time. This makes most sense when done in conjunction with load monitoring. If the load becomes unbalanced then it will be corrected, for example by transferring connections to other nodes, or moving destination storage. When this is implemented properly, it provides the most effective load balancing with the least amount of administrative work. There is no need to pre-configure anticipated loads in order to get optimum balancing. However, redistributing connections and storage incurs a lot of overhead, so there is still benefit to getting the load distribution done right on the first try.
Balancing Connections
As mentioned above, load balancing is usually a mater of balancing client connections among the cluster nodes. Any scheme that attempts to balance load independently of connections will almost certainly require clients to connect to multiple servers. This is not practical, as connections are often one of the scarcest resources.
The simplest connection-balancing scheme is to statically connect each new client to another node in round-robin fashion. This assumes that, on average, there will end up being roughly the same number of connections per node, and the same throughput per connection. This can be achieved externally to the cluster by employing a load balancing Domain Name Server (DNS), which translates each new request for the same host name into a different IP address, where each IP address is that of a different cluster node.
Although new connections are spread evenly throughout the cluster, if many connections are closed, and these closed connections are primarily from only a few nodes, the cluster can get unbalanced (unless the DNS is tied into a load monitoring scheme).
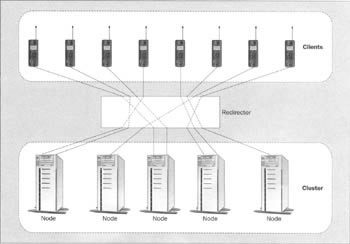
IP Redirection
The next step up in sophistication is the use of IP redirection. In this case, a redirector is situated between clients and the cluster, and all connections must go through that redirector. The redirector can be a dedicated computer or a specialized hardware device. It assigns each connection to a different node. It then routes the low-level network packets for each connection to the correct node. Thus it is transparent to both server and client and minimizes the effort required to cluster-enable a server.
These devices tend to be quite sophisticated in that they can direct SSL encrypted connections and they can be configured to ensure that subsequent connections from the same client are always directed to the same node. Hardware redirectors are available from Cisco and F5, among others. Red Hat offers a software solution based on a specially configured Linux kernel.
More sophisticated redirectors can even monitor the load of the individual nodes to perform more effective balancing. This approach has some disadvantages. Since all connections must pass through the redirector, then the questions of scalability and reliability extend to the redirector too. This means that the redirector must also be scalable and highly available if it is not to become the bottleneck of the whole system. It is also difficult to implement dynamic load balancing with redirectors, as a JMS connection is stateful, and a reconnection cannot occur without additional action on the part of the server and client. If the cluster is fault tolerant, then the redirector could be permitted to abruptly break connections to an overloaded node and rely on the client to automatically reconnect.
In general, redirectors are best suited to clustering web servers, where the client and server themselves do not contain any explicit support for clustering, but the connections are stateless and short lived. The diagram below depicts the topology of a system employing connection balancing with packet redirection:
Connection Brokers
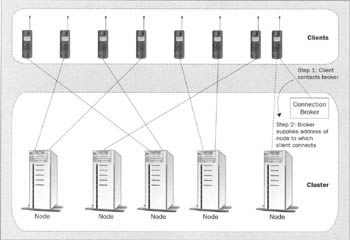
As the level of sophistication increases, the amount of cluster support built into the JMS client increases. An example of this is the connection broker. In this scheme, one node of the cluster is designated as the connection broker. All new connections are first directed to this broker. The broker then instructs the client as to which other node it should ultimately connect to.
The broker may assign nodes in a round-robin fashion, or it may use load monitoring to make intelligent assignments. It is inherently static, since the client has no more contact with the broker after the initial connection is made. In contrast to the redirector, the broker cannot introduce a performance bottleneck, and it does not introduce a single point of failure for existing connections.
If the broker fails, then new connections cannot be made, so it is still worthwhile to have a fail-over scheme for the broker when high availability is important. The diagram below shows the topology of a system employing connection balancing with a connection broker:
Dynamic Load Balancing
The connection balancing schemes discussed so far are all static. They do not attempt to rebalance connections if some nodes become overloaded compared to others. Dynamic load balancing can ultimately ensure fairer load sharing. Even though an intelligent connection broker can add new connections in such a way that the cluster is balanced, it has no control over the closing of connections.
It could be that all the clients connected to one node close their connections, and that node is suddenly underutilized compared to the others. Dynamic load balancing implies that the cluster has the ability to transfer connections from overloaded nodes to underutilized ones. This can be done with or without the cooperation of the client.
In the case that the client server connection is fault tolerant, a node can abruptly close a connection and rely on the client to reconnect to another node. It is of course more efficient to explicitly instruct the client to reconnect. It could be that the client is in the process of sending a large message or has open transactions. It would be better for it to be able to complete these before reconnecting.
Dynamic connection balancing can benefit from increased monitoring. In addition to knowing the number of connections open on each node, CPU and memory usage, and the average data throughput of each connection monitoring can be used to determine when it would be beneficial to rebalance connections. The act of transferring a connection itself consumes resources, so it is also important not to rebalance excessively.
Balancing Storage
Balancing message storage across nodes can be done independently of connection balancing in some cases. In a full replication scheme, balancing is irrelevant since every message must be stored on every node. If messages are stored on the node to which the publisher is connected, then storage cannot be balanced independently of connections. Of the storage strategies previously described, the destination home (queue home or topic home) schemes are the most relevant to storage load balancing.
The idea of a destination home is that each destination is assigned to one particular node. The assignment of a destination to a node could be done according to hashing algorithm, it could be based on the storage available to the nodes when the destination is created, or it could be pre-configured by an administrator. The last option could create a lot of administrative overhead if there are many destinations, but it allows an important degree of flexibility since the administrator may know in advance that some destinations will require more storage space than others and distribute node assignment accordingly.
Storage balancing could, in theory, be done dynamically. This would require the ability to move the home of a destination from one hardware node to another. This could be done according to load monitoring or as an explicit administrative action. In any case, transferring the storage of a destination involves copying all the stored data across the network. This could lead to so much additional system load that it becomes counterproductive. If a cluster does implement dynamic storage rebalancing, I would not expect it to be invoked very often.
Interconnecting the Cluster
Another critical aspect of the internal architecture of a cluster is the means used to interconnect the nodes. Most of this chapter has implicitly assumed the case of a shared nothing cluster and unicast networking. Shared storage simplifies cluster design considerably, almost to the point that there are no architectural issues to discuss. I argue below, though that shared storage is not very appropriate for message servers, and thus have not given it much treatment so far.
Unicast networking is mature, ubiquitous, and free (or more accurately, bundled with every operating system). As such it is a common first choice for all networking chores. Multicast networking has more limited deployment possibilities (much of the public Internet does not route multicast traffic), but I maintain below that it can provide big advantages when used in cluster architecture.
Shared Storage
In shared storage architecture, all nodes use a common persistent storage medium. Each node can read and write to the shared storage, and thus it provides not only a means for the node to persistently store data but also to share data. The most common realizations of this are shared disk and shared database architectures. Most of the issues and implications of shared storage are the same regardless of whether the sharing is done at the level of the disk controller or the database server, so we'll present the shared disk case for the general discussion and mention some of the differences of the database case afterward.
In shared disk architecture, multiple nodes all use the same disk for persistent storage. This is made possible through special hardware, such as a multi-ported SCSI bus. The hardware solution must include, or be combined with software that provides, disk locking that prevents different machines from writing to the same disk areas at the same time. Beyond this, the interface to the shared disk is pretty much the same as that to an ordinary disk:
In the simplest case, one node acts as a primary and is the only one that may write to the disk. If that node fails then another one takes over control of the disk and continues providing services. In this way any server that writes to a disk in a transactional manner could be adapted for high availability, even if it was not originally deigned to provide such.
Many OS-level clustering products use this means to cluster enable arbitrary servers. In this case the OS provides the extra functionality required to detect the failed node and activate the backup. An ordinary disk may be used to implement a special case of this in which the disk is manually disconnected from a failed machine and connected to a cold standby machine.
Problems with Shared Disk
The first problem with a shared disk scheme is that disks are the component of a computer system most prone to failure, and they are inherently slow. This means that a shared disk architecture makes the most sense when the disk is a RAID array. There are many types of RAID configuration, but the most suitable ones for use in this situation provides both high availability (one disk can fail without loosing data) and increased speed by accessing disks in parallel. In this sense, the RAID itself is a cluster for disk services.
| Note | The majority of RAID levels fit this description. RAID 5 seems to be the most commonly used. See http://www.acnc.com/04_00.html for a good overview of the various RAID levels. |
Despite the capabilities offered by using RAID, a shared disk always implies a single point of failure the RAID controller and the multi-ported SCSI bus. It also presents a limit to scalability for a message server, since all messages, even non-persistent ones, must be written to disk before they can be distributed.
Disks are generally faster than data networks (SCSI bus transfer rates are up to 160Mb per second), so a shared disk may be faster for small clusters. However, mutually exclusive disk access and the seek time associated with physically moving disk heads to different parts of the disk will become prohibitive for larger clusters. The use of high speed networking (fiber optic, ATM, Gigabit Ethernet), switched networks, or multicast can ultimately provide more scalability.
In my opinion, shared disks make less sense for message servers than for other types of server. They are appropriate for a database, where the primary purpose of the server is to provide persistent storage and not data transmission. This is most true for data warehousing and data mining applications where the processing power of the hardware node is usually a bigger limitation than the speed of disk access.
Shared Database
The situation is largely the same when all the nodes of a cluster use a common database server for common storage. A database server offers some advantages, though. This is largely a result of the fact that databases servers are designed and optimized for concurrent use by many clients. Database servers can maintain a cache, which will result in far fewer actual disk accesses when multiple nodes access the same data within a short timeframe.
In order to avoid having the database server itself become a single point of failure, the database itself must be implemented as some form of cluster. The usage of a shared database actually translates into an exercise of offloading most of the work of a cluster implementation to the database vendor. The benefit in this is that database clusters are more mature and are currently more widely used than message-server clusters. The downside is that database clusters are designed to support transactional data storage applications and not messaging. My experience and instinct says always use caution when using tools to solve problems that they were not designed to solve.
Misuse of Persistent Storage
The next point may go a bit far in the direction of personal philosophy, but I feel it is worth stating all the same. The whole concept of shared storage clustering is an exercise in misusing persistent storage as distributed inter-process communication. Don't misunderstand this; there are certainly cases where shared storage is the optimum clustering architecture. I believe, though, that very often system designers are much too quick to use disk storage simply because they are most familiar with it.
Distributed Shared Memory
One more side comment before closing this section: shared storage is actually a special case of a more generic concept called Distributed Shared Memory (DSM). This includes any distributed computing technique where multiple processes can access a common memory space, persistent or not. The JavaSpaces API provides DSM services and a JavaSpaces implementation could be used to interconnect the nodes of a cluster. A closer look reveals that despite differences in API and terminology, JavaSpaces provides roughly the same functionality as a message queue. Thus this idea comes dangerously close to the self-defeating concept of using a message queue to implement a message queue.
Shared Nothing
Shared nothing refers to the case when all storage, and all other resources except network communications, are private to each hardware node. This concept is inherently more distributed than shared storage, and is also somewhat more complex to implement. Shared nothing has been the implicit assumption for most of the discussion in this chapter, and thus most of the architectural issues involved have already been covered. This section will be primarily concerned with the lower-level issues of interconnecting the nodes of a cluster when no shared storage medium is used.
In the shared-nothing world, all communication between nodes goes over a network. This may or may not be the same network that clients use to connect to the cluster. There are two types of data that must be exchanged between nodes:
-
JMS data including messages and possibly other domain-specific data such as information about consumers and destinations.
-
Cluster internal data consisting of information about nodes joining and leaving the cluster and possibly configuration and administrative data. Some of this data is sent strictly point-to-point, from one node to another, and some must be distributed to many nodes at the same time.
In a shared-nothing cluster, node interaction consists primarily of passing messages between nodes. Here I mean messages in the generic sense: discrete packets of data. These carry a whole host of information that nodes must exchange, including the JMS messages that the cluster is transferring on behalf of a client. This is most commonly accomplished with TCP based unicast networking.
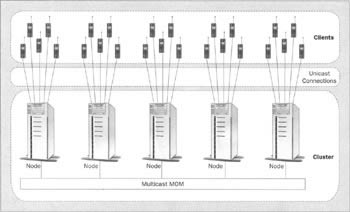
In this section, we will make two basic points: one is that serverless Message-Oriented Middleware (MOM) provides the ideal means of exchanging data throughout a cluster. The other is that multicast communication often provides significant benefits in clustering compared to the more commonly used unicast networking. These two points are related, since multicast is inherently message-oriented, and IP multicast provides a good basis for implementing serverless MOM.
MOM Communication
The first point to make is that JMS defines a standard Java interface to MOM providers. Using MOM to implement a JMS provider may sound like circular logic, but this can actually make sense. What I am actually describing here is a MOM interface to IP Multicast, which can effectively provide non-durable, non-transactional Pub/Sub messaging without a server. Not surprisingly, some multicast-based MOM products, such as those from Softwired and Fiorano, present a subset of the JMS API to the application.
Remember that the purpose of JMS is to provide standard behavior across the products of multiple vendors. If it is important to remain vendor neutral, then it is good to use a JMS-compliant serverless MOM provider for this purpose. When using MOM products to interconnect the relatively closely coupled nodes of a cluster, it may be necessary to rely on the particular behavior of one product, or the extra features not covered by JMS, such as group membership services.
The following features of MOM make it well suited for inter-node communication:
-
Discrete Messages
Most of the information that must be exchanged between cluster nodes represents discrete events a new message, a new publisher, a session closure, etc. When the messages that carry this information are transmitted over a stream-oriented data channel, then the receiver has the extra work of delimiting and extracting the individual messages from the channel. In practice, this is not very difficult and may actually be done transparently by a mechanism such as RMI sitting on top of the data stream. The point here is that the natural form of data transfer is message oriented and it is convenient to use an abstraction that presents data to the node in this form.
-
Subject-Based Addressing
This is a more indirect means of addressing the other nodes in the cluster. Without this, each node must maintain a table of the IP addresses of all of the other nodes in the cluster, along with information such as the role of each node if relevant. This level of indirection is of prime benefit when a node fails and is replaced by a backup. The backup can take over listening to messages on the same subject, without requiring all of the other nodes to explicitly learn the new IP address and update their tables.
-
Pub/Sub
It is very often the case that identical information must be sent to multiple nodes. It is naturally easier to do this as one single operation.
-
Group Membership Services
This is the generic service keeping track of what participants are communicating on a particular subject. In terms of a cluster, this means keeping track of the other nodes, and providing notifications of nodes that join or leave the group, or nodes that fail unexpectedly. This functionality is required in clustering, and using a MOM product that provides these group membership services, like Softwired's iBus//MessageBus, alleviates the need to implement them yourself.
These are many of the same reasons that make MOM useful in general (not just for clusters), and this serves to emphasize the point that MOM will play a big role in the future of distributed systems. These features of MOM go hand-in-hand with the use of multicast networking as the underlying transport: discrete messaging is a must as stream abstractions are not suitable for group communications; subject-based addressing allows groups of machines to be addressed at one time, and Pub/Sub can be efficiently implemented without a server by using multicast.
The features of MOM that are not relevant are message storage and transactions. These are precisely the features that require a server, and thus cannot be used to implement a message server. Basically all nodes in the cluster must be reachable at all times, and any transactional aspects of inter-node communication must be implemented above the MOM layer.
Multicast Networking
In the Internet world, unicast communication is synonymous with the TCP protocol. This is the most ubiquitous protocol in use on the net. This is not surprising, since it is available at no extra cost on virtually every computing platform in use today. It provides reliable, efficient communication and presents an easy to use, stream-based interface. Why use anything else?
| Important | The features of unicast protocols come at a price: you lose access to the broadcast capability inherent in the hardware layers of most networks. While TCP makes sense for efficient long-distance communication, it can be counterproductive to use it for group communication on local networks. |
Consider this example: a cluster of 10 nodes is interconnected with a single network segment. Each node has, at the hardware layer, access to all packets that are transmitted on that segment. If one node wants to send the same message to all other nodes using TCP, then it must send the message nine times. The network interface of each hardware node "sees" all nine copies of message going by but only-passes one of those copies up to the operating system level of its machine. A lot of potential efficiency is lost here. This loss is significant, as for some existing clustering solutions, this is the ultimate limit of scalability, and this limit can be reached with a small number of nodes.
IP multicast provides the necessary alternative to unicast protocols. Multicast packets are sent to class D IP addresses. Unlike the other classes of IP address, a class D address is not associated with a particular host. Instead, any host can instruct its network interface to accept data sent to any number of such addresses.
| Note | There are efficiency considerations here. Most network interface cards can handle a dozen or so class D addresses in hardware. Beyond this, they start passing all multicast packets up to the network driver to be filtered in software. |
Thus multicast provides the subject-based addressing and publish/subscribe abstractions right at the network layer. However, raw multicast is not reliable, and there is no ubiquitous reliable protocol layer on top of raw IP multicast that fills a role corresponding to the role filled by TCP in the unicast world. There are a number of commercial products that provide a reliable protocol on top of IP multicast, such as the JMS-compliant products mentioned above. Cisco and TIBCO have developed a protocol called PGM (Pragmatic General Multicast), which is proposed as a standard, but if you want to use it now you will still need to buy and deploy a product such as TIBCO's Rendezvous or Talarian's SmartPGM.
Although multicast packets can, in theory, be routed over wide-area networks, it is difficult to guarantee that this is done efficiently. Many Internet providers do not permit routing of multicast packets, and there is almost certainly no firewall that is open for multicast traffic. This means that multicast will seldom be a suitable means of connecting clients to a server, or to interconnect servers separated by an arbitrary distance in a message routing configuration. It is an ideal means for interconnecting the nodes of a tight cluster in a local environment.
How beneficial is multicast communication for a shared-nothing cluster? Let's look at some of the fundamental considerations of clustering. Any architecture that provides high availability must store all persistent data on at least two different nodes. Pub/Sub messages must potentially be sent to all nodes. Group membership functions require messages, especially heartbeat messages that confirm that a node is still alive, to be sent to all nodes. In short clusters require a large percentage of all messages sent between nodes to be distributed to more than one destination node. This means that the use of multicast communication provides a dramatic increase in the efficiency of network utilization compared to unicast communication:
Implications for Transactions
Compared to a monolithic server, the processing of transacted JMS sessions takes on a new dimension in a cluster. The most critical aspect of transacted JMS sessions is that the consumption and production of all messages in the same transaction must succeed or fail in an atomic fashion. Of course all actions are supposed to succeed all the time, but situations do arise when things go wrong: disks fill up, destinations are deleted, etc. The important guarantee in a transacted session is that if any one message fails, then the entire transaction is null and void and the entire transaction must be rolled back as though it never happened.
This is not a complex issue in a monolithic server, but when transaction processing involves multiple nodes, extra coordination is required. It is not permissible to commit part of the transaction on one node, if the commit of another part of the transaction on another node fails. It is also not possible for every node to wait to see if all other nodes succeed before performing the commit itself. This dilemma is usually solved with a two-phase commit protocol (which we met in Chapter 4). In the first phase all participating nodes must give a guarantee that they are capable of committing successfully, and in the second phase the nodes are allowed to commit in parallel. Transactions that require a two-phase commit are called distributed transactions.
The implication of clustering on transacted message delivery is that every transaction requires a two-phase commit within the cluster. This causes the implementation of the cluster to become more complex, but this should be entirely transparent to the user of the JMS API. The biggest implication for the end user of the JMS messaging system is performance. The extra communication between nodes costs time, and the entire transaction cannot complete until all nodes have reported their individual results. Much of the parallelism that might be expected from load balancing among multiple nodes is lost during a transaction commit. In general, the speed of message delivery for transacted sessions will not scale as well as that for non-transacted sessions.
The degree to which transactions have an effect on performance depends largely on how many nodes are involved in the transaction. This will vary between one and all of nodes in the cluster depending on where the messages are stored. The successful commit of a produced message means that the cluster has securely stored the messages (persistently or non-persistently, depending on delivery mode) and will guarantee delivery with no further action from the client, even in the case of node failures.
A commit must occur after a message is published and before it can be delivered, so some form of storage is always required for transacted messages. When a cluster employs the concept of destination homes, the number of nodes involved actually depends on the number of destinations involved in the transaction and how those destinations are distributed among the nodes.
The redundancy scheme employed, if any, also plays a big role in determining the number of nodes involved in a transaction. If the cluster guarantees that committed messages will ultimately be delivered in spite of node failures, then a successful commit must also imply that redundant copies of the messages are stored on different nodes.
Consider a full replication scheme. In this case all nodes must participate in every transaction. This means that with every commit a session must always wait on the slowest node in the cluster. Thus, with transactions the problem of an overloaded node slowing down the whole cluster becomes more acute. Clusters that have a high degree of redundancy might benefit from only requiring a majority of the backup or redundant nodes to commit successfully before declaring the commit a success to the client. The feasibility of this approach depends on the exact redundancy scheme employed. A node that does not successfully commit will not have a complete set of messages. With a full redundancy scheme, all nodes are active, so a node that was not successful during the original commit must catch up soon by committing the transaction afterward, or the cluster must declared the node as failed and shut it down.
With a primary/backup scheme, the primary must always commit successfully in order for the transaction to succeed, but if any of the backups do not commit successfully, this does not become a problem until a fail-over occurs, which means that the backup potentially has more time to catch up. Thus, with primary/backup, a "lazy commit" policy for the backup nodes, although riskier, might be acceptable in return for better performance.
Other Issues
So far in this chapter, we have seen the major implications of using a clustered JMS message server. Before closing, we'll briefly visit a number of additional aspects that are less important from an architectural standpoint, but are important nevertheless.
Administration
Although the JMS specification clearly defines the external behavior of a message system, it says nothing about administration. This is an area where there are bound to be big differences between JMS vendors, and with clustering this is the case even more so. Most clustering schemes will maintain the outward appearance of a single monolithic server, which means that there is no difference in programming a JMS client for the clustered and non-clustered cases.
This will not be the case for administration. For the administrative functions common to monolithic servers and clusters, it may make sense to present the cluster to the administrator as though it were monolithic. Clustering brings a host of additional administrative functions, though. Such actions as adding a node to or removing a node from the cluster, configuring backup nodes, assigning destination homes and configuring routing, if necessary, require explicit knowledge of each node. Individual cluster implementations will vary as to how many of these functions are required, and which can be performed automatically and which require administer intervention.
Additionally, implementations will vary as to whether such administrative functions can be performed while the cluster is online, or whether it must be shut down. Downtime for administrative actions is not as critical as downtime due to failures, as administration can usually be planned for low usage periods (typically evenings and weekends), insofar as these exist. If your cluster is expected to provide availability of 99.9% or better (refer to the availability table earlier in this chapter), you are pretty much required to perform all administrative and reconfiguration tasks online.
Configuration
Clustering also adds complexity to the task of maintaining consistent configuration data for the server. Some configuration parameters must be the same for all nodes (especially communication parameters required for the nodes to communicate with each other), and some parameters will need to have a certain consistency across the cluster (two nodes should not be home for the same destination, for example).
It is easier to avoid inconsistencies if there is a central repository for all parameters, such as a configuration server file in a shared directory. This introduces a central point of failure, but not a very serious one, unless the nodes need to continuously access the central configuration data. If the nodes only access the configuration data once at startup time, then a failure of the configuration repository will only prevent new nodes from starting, not affect running nodes.
This scheme still creates difficulty if the configuration data is updated while some nodes are online. Nodes that are added after the change will have a configuration that is inconsistent with the existing nodes. It is important for a cluster to have a systematic scheme for ensuring the consistency of node configuration. It is also helpful if the cluster can automatically detect and report an inconsistency, as this can lead to problems that are difficult to diagnose.
Keep in mind that there will always be some bootstrap parameters that are local to each node. Even if there is a central repository, each node will need to be given some parameters in order to find the repository. In the optimal case the parameters should be minimal: a host address and port, a multicast address, or a filename.
After guaranteeing that nodes can start up with a consistent set of parameters, the next issue is parameter updates. If necessary, can parameters be changed while the cluster is online? If so, the cluster must ensure the changes are carried out consistently over all nodes. This is more easily accomplished if all nodes access a common repository. If each node stores its configuration locally after startup, it may be necessary to signal the nodes to reread the central configuration. A more distributed solution is to handle parameter updates in the same fashion as other data that must be exchanged between nodes, and propagate them through the cluster using message passing.
Intra-Node Security
Intra-node security refers to authenticating the nodes that join the cluster or more generally, to restricting access by any process that tries to impersonate a node. For clusters where all nodes are located together in the same data center, this is seldom an issue, as the network itself can be sufficiently isolated that there is no risk of contact with computers that are controlled by other parties.
Intra-node security is more likely to be important in message routing, where the nodes are separated by larger distances and could easily be reached by processes not associated with the messaging system. In this case it is often prudent to employ security measures between nodes similar to those typically employed between client and server. This could include basic connection level authentication, passing authentication tokens with every message exchange, or stronger security in the form of SSL connections.
If reliability is important, then the cluster should employ basic measures against Byzantine failures, in which a process, even if not intentionally malicious, runs amok and starts distributing invalid messages on the cluster network.
A second aspect of cluster security is closely related to configuration. Authentication and access control data must be consistent across the cluster for it to be meaningful. It does little good to deny a user access to a particular destination if that user can gain access to it anyway by just reconnecting to another node. Here again, the security configuration must be stored centrally, or the update mechanism must ensure that changes are propagated to all nodes in a timely manner.
Backup
Typical computer installations will perform nightly backup of all data to tape archives. Such a backup represents a "snapshot" of the state of the system at one point in time. Performing this type of backup of the message store of a message server makes little sense due to the transient nature of the queued messages. The general concept behind a message server is to store messages for the shortest amount of time possible. If you do need to perform such a backup for some reason, then it is difficult to get a consistent snapshot of the whole cluster without shutting the whole system down during the backup. (This is particularly true if the nodes are geographically dispersed.)
If there is a constant flow of messages in and out of the server, then restoring a server from a backup that is several hours old will probably not be very useful. In fact this would almost certainly lead to both message loss and multiple deliveries. This is one of the reasons that the extra reliability provided by clustering is more important for message servers than for many other types of server.
Consider the following two cases in which uncoordinated backups are done while a message is in the process of being routed between two nodes. If a backup of one node is done after the message leaves it, and the backup of the other node is done before the message arrives, then the message will not appear in any of the backups. Alternatively, if the backup of one node is done before the message leaves it, and the backup of the other node is done after the message arrives, then the message appears twice. In this case it could be delivered twice if the whole cluster were restored from the backups.
In general, it is better not to rely on snapshot-style backups for the message store. The only type of backup that makes sense is one that recedes every message store update continuously, as it happens. This actually describes a backup node in a primary/backup redundancy scheme more than a tape archiving procedure.
It is of course useful to backup configuration files and other cluster metadata, but unlike the message store, this does not present special problems.
EAN: 2147483647
Pages: 154