The Different Types of Testing
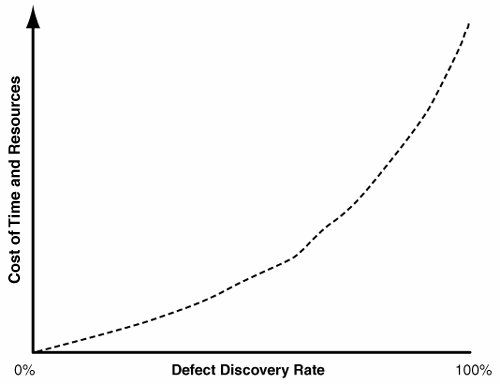
| There are nearly as many ways to test software as there are ways to develop it. In an ideal world, developers would write perfect code, and testing would be unnecessary. Because the technology does not yet exist to write error-free code, you must test carefully to discover and repair the defects found before the customer discovers them. Given that you cannot produce error-free code, the goal of testing is to catch as many defects as possible. Of course, your resources are finite. Even with nearly unlimited time and resources, it is nearly impossible to exercise a system to the point where you can guarantee that all bugs are removed from it. But for most projects, you cannot allocate that many resources to testing (see Figure 11-3). The best you can do is obtain the best testing coverage possible and leverage the resources available in the most effective way possible. Customers are willing to accept some level of defects if the overall product is of an acceptable quality level. Figure 11-3. Resources and defect discovery rates The key to a successful testing effort is determining a point on the curve illustrated in Figure 11-3 that is acceptable to both the customer and end users and that can be accommodated by the number of people available for testing on the project. To help identify this point on the curve, it is important to review the project requirements (especially the supplemental requirements). The Vision Statement may also have clues as to the customer's expectations. Is this system mission-critical? Will the safety of lives and property depend on the system's functioning correctly? If so, you will no doubt want to devote considerably more resources to the testing effort than if the system had none of these qualities. The following sections cover the different types of testing that are common on outsourced projects. The advantages and disadvantages of each type are discussed. For projects that have severe resource constraints, types of testing that are particularly economical (in terms of resources expended per defect found) are identified. Functional TestingFunctional testing is the most common type of testing. It is the process of verifying that the product meets its functional requirements. If a project performs only one type of testing, it is probably functional testing. Functional testing is often used to prove to a customer that the system meets all the functional requirements. After a system is delivered to the customer, some customers simply want to see all the functional tests executed. A witness, usually part of the customer organization, signs off after agreeing that the tests have passed. Functional testing performed in this scenario is generally called acceptance testing. With iterative development, functional testing consists of testing all the newly implemented requirements, plus the requirements previously tested on earlier iterations. As more iterations are completed, the number of previously tested requirements grows as more and more of the system is progressively implemented. It is necessary to retest these requirements. As the code base changes and new code is added, it is quite possible that previously working functionality may cease working. The process of retesting previously tested requirements is known as regression testing. Functional testing is an arduous task when performed manually. Systems with extensive user interfaces might need hundreds of tests. Each test may contain dozens of steps that must be followed in the correct order. As a result, the process can be error-prone and time-consuming. Automated Functional TestingA number of companies offer automated functional testing tools. Most of these tools are of the capture-replay variety. These tools record all mouse movements, mouse clicks, keystrokes, and so on. They can start an application, perform the necessary steps in the correct order, compare the application's response with the expected results, and produce an error log for any responses from the application under test that are not equivalent to the expected results. This provides an obvious increase in productivity and reduces the number of manual steps that have to be performed. Careful consideration should occur before you invest in automated testing tools. Although the advantages are real, preparing a suite of automated tests takes more time than preparing a suite of manual tests. In a Waterfall lifecycle model, where the tests are performed once, or perhaps twice, the extra time involved in creating automated tests may not be recouped. It may make more sense in these situations to use manual tests. Iterative development and automated functional testing are an excellent match. Because regression tests on previously tested functionality are performed at the conclusion of each iteration, there is a greater chance that the upfront investment in developing the automated scripts will be advantageous in the long run. Precautions to Follow When Considering Automated TestingAlthough advances in test tool technology have been tremendously useful, you should follow some precautions before making the investment:
Unit TestingUntil recently, I was not a big fan of unit testing. Setting up unit tests is generally very time-consuming and tedious. Most programming languages have individual modular routines that are considered by themselves for unit testing. Some languages call them functions; others call them procedures, methods, or subroutines. Regardless, a unit is the smallest amount of code that performs a specific purpose. Because it is a small segment of code, it may have no user interface, or it may not perform any action externally visible to an end user. Developers generally are the ones who perform unit tests. The reason is that individual units often require additional code to be written as test "drivers." These routines must be written, and appropriate values need to be determined to pass to the unit under test. When the unit is tested, the response from the unit under test must be determined and compared to the expected result. As a result of the additional code that must be written, unit testing takes longer, on average, per defect found. In addition, unit tests require the developer to try to identify input values that will adequately test the unit. Although there are always exceptions, developers as a group are not highly motivated to properly perform unit tests. Recently, a new generation of automated unit test tools has appeared in the marketplace, such as those from Agitar. These new tools can exercise code in an automated fashion, freeing the developer from having to write test drivers and running the tests manually. If your project can acquire these new testing tools, they will elevate unit testing on a project to an entirely new level. Without them, and especially if you have very limited time, a project may be better off investing more time in the other types of testing. Reliability TestingSome types of errors lurking in code cannot be caught through traditional functional or unit-testing techniques. The most common examples are memory leaks and similar types of storage mismanagement. When these errors are contained in developed code, they may not occur until the system has been running for many hours. Or the error might occur only when a certain sequence of functionality is used. Although these types of errors are less common than simple functional errors, they are serious when they do occur, for the following reasons:
These types of errors are also severe because the system is probably unusable when the error occurs. The application will probably crash or present nonsensical errors randomly. It may take a long time for the developers to understand and correct the cause. As a result, these errors undermine the user's confidence in the system. If the system is mission-critical or involves the safety of lives or property, the customer may consider the entire system unacceptable. Tools to the RescueFortunately, some excellent tools are available to detect these types of errors. Perhaps the most commonly known tool is Purify, marketed by IBM/Rational, but others exist as well. Because these tools require an intimate knowledge of the code under test, the developers, instead of the testing personnel, are the appropriate ones to use them. Many development organizations require use of these tools as part of the unit testing process. The result is an application that is more stable and less likely to suffer from unexplainable crashes. Performance/Stress TestingMany systems have supplemental requirements of this form: "The system shall support a concurrent load of 500 users while maintaining a response time of less than 2 seconds." How can you determine that a system under development meets this requirement? Even if you are convinced that your system can meet the requirement, how can you advise the customer what minimum system configuration (such as CPU speed and memory) is needed to meet the requirement? How many users above the 500 required could the system support before the response time exceeds 2 seconds? The answer is to perform formal load and stress testing. Ironically, this kind of testing seems to be the most neglected type of testing today. This is unfortunate, because if the system fails to meet the requirement, the solution can be expensive. Customers should be more assertive and ask their contractor to prove it can support the required load, just as they would for any functional requirement. On the other hand, contractors should be more diligent and test systems with these kinds of requirements before formal delivery to the customer. Until a few years ago, performance and stress testing was done by attempting to have a large group of people interact with the system and extrapolating the results to the required number of users. However, this approach has several problems:
Tools to the RescueAgainA number of vendors, in particular Mercury Interactive and IBM Rational, have developed tools to simulate multiuser loads very efficiently. The catch is that most vendors price their tools according to how many users are needed in the simulation. If you are building a single system that has to support 5,000 users, the cost of the tool may be too high for a single project to afford. Companies that build many systems can spread the costs among several projects or treat the purchase as a capital investment, so the cost is incorporated in the corporate overhead. One alternative is vendors that offer testing services, where you effectively rent the tools and testing personnel who are experienced with the tools. They perform a set of test runs and provide the results for a fee. If your project is fortunate enough to have access to these load and stress testing tools, keep in mind the following points when planning a load/stress/performance testing effort:
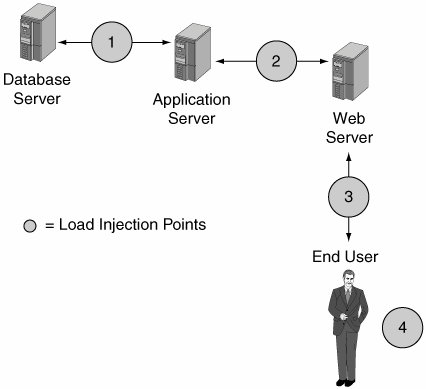
Another advantage of performance testing tools is the ability to help identify performance bottlenecks. Figure 11-4 shows the hardware architecture for a Web-based system. Most load testing tools can record and play back the traffic between any two tiers of the system. Initially, in a system such as the one shown in Figure 11-4, the network traffic caused by interaction with the user interface is captured and played back to simulate the load of multiple end users. This corresponds to load injection point 3 in Figure 11-4. If the performance test reveals a problem, the network traffic can be recorded and played back at load injection point 2 (for the application server) or load injection point 1 (for the database server). If playing back the traffic recorded at injection point 1 shows markedly improved performance, there is an excellent chance that the performance problem is caused by either the application server or the Web server. Recording and playing back the traffic can then narrow the performance problem to the tier causing the problem. At that point, you may be able to use code-profiling tools to find the specific code module causing the problem. Figure 11-4. Where is the bottleneck? Other Types of TestingOther types of testing cannot be automated. One example is usability testing. For some projects, it may not be possible to understand the collective skill set of all the system's potential users. An example is a Commercial Off-The-Shelf (COTS) system or a product for the retail environment. For these types of products, particularly high-volume products, usability testing may be indicated. This might consist of randomly selected users placed in a room while being observed (or even filmed) while attempting to use the software. When the users experience difficulty figuring out how to interact with the system, it may be because the system is not intuitive. Correcting these types of problems beforehand can eliminate many calls for support after the system is deployed. |
EAN: 2147483647
Pages: 166