Database Structure
3 4
Each SQL Server 2000 database is created from a set of operating system files. These files can be grouped together into filegroups to improve data manageability, data placement, and performance. In this section, you'll learn about SQL Server files and filegroups and examine their role in database creation.
Files
As mentioned, a SQL Server database is made up of a set of operating system files. A database file can be either a data file or a log file. Data files are used to store data and objects, such as tables, indexes, views, triggers, and stored procedures. There are two types of data files: primary and secondary. Log files are used to store transaction log information only. Log space is always managed separately from data space and can never be part of a data file.
Every database must be created with at least one data file and one log file, and files may not be used by more than one database—that is, databases cannot share files. The following list describes the three types of files that a database can use.
- Primary data file A primary data file contains all of the startup information for the database and its system tables and objects. It points to the rest of the files created in the database. It can also store user-defined tables and objects, but it is not required to do so. Each database must have exactly one primary file. The recommended file extension is .mdf.
- Secondary data files Secondary data files are optional. They can hold data and objects that are not in the primary file. A database might not have any secondary files if all its data is placed in the primary file. You can have zero, one, or multiple secondary files. Some databases need multiple secondary files in order to spread data across separate disks. (This is different from RAID, as we'll see in the following section.) The recommended file extension is .ndf.
- Transaction log files A transaction log file holds all of the transaction log information used to recover the database. Every database must have at least one log file and can have multiple log files. The recommended file extension is .ldf.
NOTE
The maximum file size for a SQL Server database is 32 terabytes (TB) for data files and 4 TB for log files.
A simple database might have one primary data file, which is large enough to hold all data and objects, and one transaction log file. A more complex database might have one primary data file, five secondary data files, and two transaction log files. How, then, could the data be spread across all the data files? The answer is that filegroups can be used to arrange data.
Filegroups
Filegroups enable you to group files for administrative and data placement purposes. (They are similar to segments in Microsoft SQL Server versions 6.5 and earlier.) Filegroups can improve database performance by allowing a database to be created across multiple disks, multiple disk controllers, or RAID systems. (RAID is described in Chapter 5.) You can create tables and indexes on specific disks by using filegroups, thus enabling you to direct the I/O for a certain table or index to specific physical disks, controllers, or arrays of disks. We'll look at some examples of this process later in this section.
There are three types of filegroups. The main characteristics of these filegroups are outlined in the following list:
- Primary filegroup Contains the primary data file and all other files not put into another filegroup. System tables—which define the users, objects, and permissions for a database—are allocated to the primary filegroup for that database. SQL Server automatically creates the system tables when you create a database.
- User-defined filegroups Includes any filegroups defined by the user during the process of creating (or later altering) the database. A table or an index can be created for placement in a specific user-defined filegroup.
- Default filegroup Holds all pages for tables and indexes that do not have a specified filegroup when they are created. The default filegroup is, by default, the primary filegroup. Members of the db_owner database role can switch the default status from one filegroup to another. Only one filegroup at a time can be the default—again, if no default filegroup is specified, the primary filegroup automatically remains the default. The ALTER DATABASE command is used to change the default filegroup. The syntax for this Transact-SQL (T-SQL) command is shown here:
ALTER DATABASE database_name MODIFY FILEGROUP filegroup_name DEFAULT
(You'll learn how to use T-SQL in Part III.) You might want to change the default filegroup to be one of your user-defined filegroups so that any objects created in your database will automatically be created in the filegroup you specified without your having to specify it every time.
To improve performance, you can control data placement by creating tables and indexes in different filegroups. For example, you might want to place a table that is heavily used in one filegroup on a large disk array (made up of 10 disk drives, for example) and place another table that is less heavily used in another filegroup located on a separate, smaller disk array (made up of 4 disk drives, for example). Therefore, the more heavily accessed table will be spread across the greater number of disks, allowing more parallel disk I/O. If you are not using RAID and you have multiple disk drives, you can still make use of filegroups. For example, you can create a separate file on each disk drive, placing each file in a separate user-defined filegroup. This allows you to place each table and index in a specific file (and on a specific disk) by designating the filegroup when you create the table or index. Figure 9-1 shows a sample arrangement: one primary data file in the primary filegroup on the C drive, one secondary data file in each of the user-defined filegroups (FG1 and FG2) on the E and F drives, and one log file on the G drive. You can then create tables and indexes in either user-defined filegroup—FG1 or FG2.
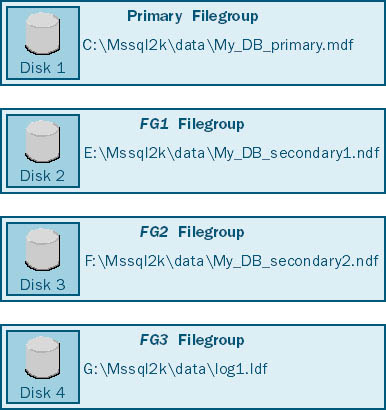
Figure 9-1. Using filegroups to control data placement.
Or you might use one user-defined filegroup to spread data across several disks. Figure 9-2 shows a user-defined filegroup (FG1) that includes two secondary data files, one on drive E and one on drive F (with the log file on drive G and the primary file on drive C). Again, in this case, we are assuming each database file is created on a single physical disk drive; there is no hardware RAID involved. Tables and indexes created in the user-defined filegroup will be spread across the two disks, as a result of SQL Server's proportional filling strategy.
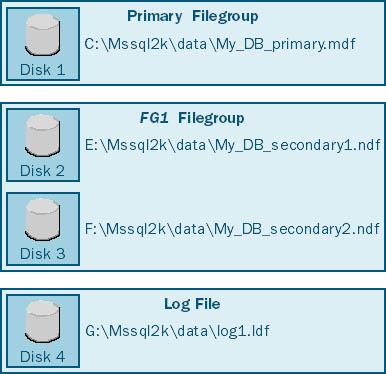
Figure 9-2. Using one filegroup to spread data across several disks.
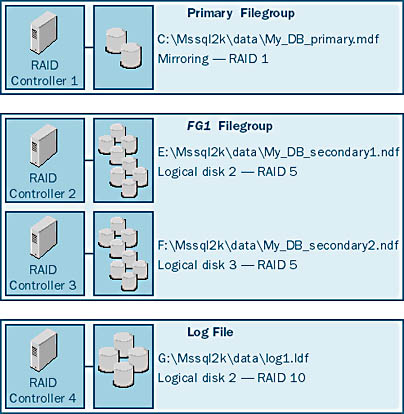
If you use a RAID system, you might need to spread the data from a larger-than-average table across multiple logical disk arrays configured on two or more RAID controllers. You do this by creating a user-defined filegroup that includes a file on each of those controllers. Say you have created two secondary data files, each on a different array of disks, with each logical array made up of eight physical disks and configured with RAID 5. The two arrays are on separate RAID controllers. To create a table or an index across both controllers (thus across all 16 disk drives), define a single user-defined filegroup in which to place both files, and then create the table or index in that filegroup. Figure 9-3 shows the user-defined filegroup, FG1, that spans 16 physical disks, or two logical RAID disk arrays. It also shows the primary data file on another controller (with RAID 1) and the log file on yet another controller (with RAID 10).
SQL Server enables you to optimally distribute your data across disk drives because it automatically stripes, or distributes, data proportionally across all the files in a filegroup. "Striping" is the term used to describe distributing data across more than one database file. SQL Server file striping is independent of RAID disk striping, and it can be used alone or in conjunction with RAID, as we saw in our previous examples.
To stripe data, SQL Server writes data to a file in an amount proportional to the free space in that file as compared with the free space in other files. Space is allocated for tables and indexes in extents. An extent is a unit of 8 pages, and each page is 8 kilobytes (KB), for a total of 64 KB per extent. For example, if 5 extents need to be allocated between file F1, which has 400 megabytes (MB) free, and file F2, which has 100 MB free, 4 extents are allocated to F1, and 1 extent is allocated to F2. Both files will become full at about the same time, allowing for a better distribution of I/O across the disks. Proportional striping will occur whether files F1 and F2 are in a user-defined filegroup or in the primary filegroup. If all the files in a filegroup are defined with the same initial size, data will be spread evenly across the files as it is loaded. This method of creating files with the same initial size in a filegroup is the recommended one for evenly distributing data across drives, in an attempt to allow for evenly distributed I/Os as well.
Another benefit of using filegroups is that SQL Server allows you to perform database backups based on a file or filegroup. If your database is too large to back up all at one time, you can back up just certain portions. This technique will be covered in detail in Chapter 32.
Rules and Recommendations
You should have a well-developed strategy for the use of files and filegroups before creating your database. In order to do that, you must know the following SQL Server 2000 rules:
- Files and filegroups cannot be used by more than one database.
- A file can be a member of only one filegroup.
- Data and transaction log information cannot be part of the same file. Log space is always managed separately from data space.
- Transaction log files are never part of a filegroup.
- Once a file is created as part of a database, it cannot be moved to another filegroup. If you want to move a file, you must delete and re-create it.
In addition to these rules, there are specific methods of using files and filegroups that are known to work well. Here are some general recommendations for using files and filegroups that will help you design your database:
- Most databases perform well with only a primary data file and one transaction log file. This is the recommended design for databases that are not particularly I/O intensive. If you have an I/O-intensive system that requires many disk drives, you will probably want to use user-defined filegroups to allow you to spread the data across disks or disk arrays for parallel I/O performance.
- Always place log files on separate physical disks from the disks containing data files, as explained in Chapter 5.
- If you do need to use multiple data files, use the primary data file for system tables and objects only, and create one or more secondary data files for user data and objects.
- Create files and filegroups across as many physical disks as are available to allow a greater amount of parallel disk I/O and to maximize performance.
- Place nonclustered indexes for heavily used tables in a separate filegroup on different physical disks from the disks containing the table data itself. This technique also allows for parallel disk I/O. (Indexes are covered in Chapter 17.)
- Place different tables that are used in the same query on different physical disks, if possible, to allow parallel disk I/O while the search engine is searching for data.
The last two items might not hold true for a system using RAID volumes with many disk drives. If you have many disk drives, you might do just as well or better to spread the indexes and tables across as many drives as are available, to achieve the greatest amount of parallel I/O possible for each table and index.
Automatic File Growth
SQL Server allows files to grow automatically when necessary. When a file is created, you can specify whether to allow SQL Server to automatically grow the file. Allowing automatic growth, which is the default when you are creating a database, is recommended, as it saves the administrator the burden of manually monitoring and increasing file space.
A file is created with an initial size. When that initial space is filled, SQL Server will increase the file size by a specified amount, known as the growth increment. When this new space fills, SQL Server will allocate another growth increment. The file will continue to grow at the specified rate, as needed, until the disk is full or until the maximum file size (if one is specified) is reached.
NOTE
Automatic file growth is different from proportional filling. With automatic file growth, SQL Server automatically increases the size of a file when the file becomes full. With proportional filling, SQL Server places data in files in proportion to how much space the files have available but does not increase the files' size.
The maximum file size is just that—the maximum size to which a file is allowed to grow. This value is also specified at file creation but can be revised later using Enterprise Manager or the ALTER DATABASE command. If no maximum size is set for a file, SQL Server will continue to grow the file until all available disk space is filled. To avoid running out of disk space and causing SQL Server to receive errors, set a maximum size for each file. If a file does ever reach its maximum size, you can increase the maximum size by using the ALTER DATABASE statement. Or you can create another file on the same disk if space is still available on that disk, or on a different disk. Be sure that the new file is in the same filegroup as the original file. If a file is allowed to grow without restriction (per the default) until all the available disk space is used up, you will need to create a file on another disk that has free space.
As a rule, you should use automatic file growth and maximum file sizes. When you create a database, specify the largest size to which you think the files will ever grow. Even though automatic file growth is available, you should still monitor database growth on a regular basis—daily or weekly, perhaps—for your own records. You could keep the growth information in a spreadsheet, for example. With this information, you can extrapolate to estimate how much disk space will be needed for the next month, the next year, the next five years, and so on. By monitoring space, you should know if your files have experienced automatic growth and when or if you should alter the database to add more files. This continual space evaluation will help you avoid hitting the maximum file size or using up all the available disk space.
EAN: N/A
Pages: 264