Understanding How Overflows Work
This section describes several different overflows, how they work, and basic walkthroughs to demonstrate that they are serious security issues.
Suppose you are testing an application that takes a stock symbol and looks up the current trading price. You enter a few common stock symbols and verify the right price is returned for each stock. Next , you try getting prices on stock on different exchanges to make sure the application works, but you don t stop when you have tested valid input. You continue to test a few nonexistent symbols to see what happens. In addition to the null case, invalid characters , and all of the other basic test cases, you try a long string. After you input the long string, the service is unresponsive . What happened ? When you look on the server you see the service crashed and created a crash log. You restart the service, send in the long string again, and down it goes again (crash). You report the behavior as a bug and mention the bug over lunch . One person says that it s a cool way to shut down the service. Another person overhears the conversation, interrupts, and comments that you can probably do a lot more than just taking down the service ”the bug is quite likely a buffer overflow and someone can use it to take control of the server. But how can that happen? Let s examine how overflows work and why this long input bug is much more serious than just a crash.
Although many overflows occur when the program receives more data than it expects, in fact there are many different kinds of overflows. It is important to distinguish between different classes of overflows to be able to develop good test cases to identify specific types of overflows:
-
Stack overflows Stack overflows are overflows that occur when data is written past the end of buffers allocated on the stack.
-
Integer overflows Integer overflows occur when a specific data type or CPU register meant to hold values within a certain range is assigned a value outside that range. Integer overflows often lead to buffer overflows for cases in which integer overflows occur when computing the size of the memory to allocate.
-
Heap overruns Heap overruns occur when data is written outside of space that was allocated for it on the heap.
-
Format string attacks Format string attacks occur when the %n parameter of the format string is used to write data outside the target buffer. This particular attack is covered in Chapter 9, Format String Attacks.
Stack overflows, integer overflows, and heap overruns are discussed in this chapter. Format string attacks, however, are discussed in Chapter 9.
| Note | Throughout this chapter we use Microsoft Visual Studio as the primary debugger, source code editor, and binary file editor. You should use the tools you are most comfortable with, provided they can do the tasks described in this chapter. Although the computer processor register names and sizes often vary between processor types and manufacturers, this text doesn t delve into the many processor-specific issues that can arise when actually exploiting or fixing bugs that s not what this book is about. For consistency, the text refers to processor registers and sizes consistent with Intel-compatible 32-bit processors; it is certainly the case that other processors generally have the same issues despite their registers size or nomenclature . |
Stack Overflows
To understand stack overflows, let s first examine how the stack works. The stack works like short- term memory ”it stores information needed by the computer to process a given function. When calling a function, the program first places (or pushes ) the various parameters needed to call that function on the stack. The computer processor keeps track of the current location on the stack with a special processor register called the extended stack pointer (ESP). This step is shown in Figure 8-1. In the figure, the arguments for the function were already pushed onto the stack. Notice that in these stack layouts, lower elements on the layouts correspond to higher memory addresses.
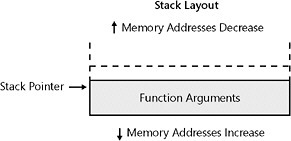
Figure 8-1: A stack just before a function is called
The actual function call then places the return address on the stack. The return address reminds the computer processor where to run the next code when it is finished running the code in this particular function. This is illustrated in Figure 8-2. Notice how the stack pointer decreases every time something is pushed onto the stack.
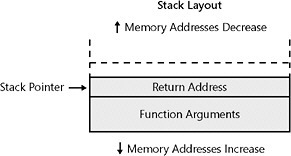
Figure 8-2: The return address placed on the stack
Once the function is running, it usually places additional data on the stack. The stack then looks like the one shown in Figure 8-3, where, once called, the function begins to push local variables onto the stack. Like the return address in Figure 8-2, pushing more onto the stack decreases the value of the stack pointer.
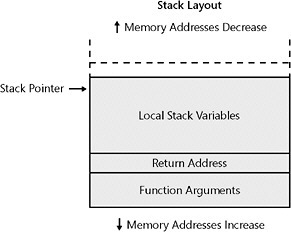
Figure 8-3: The function pushing local variables onto the stack
Some of this data might include a buffer that an attacker can potentially overflow. Normal testing and usage input are shown in Figure 8-4. When one of the function s local variables, a buffer, is overwritten with normal input, the input is usually copied sequentially into the buffer as shown.
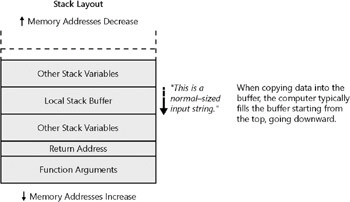
Figure 8-4: Input copied sequentially into the buffer
Once the function is finished running, it removes (or pops off ) the local variables from the stack. (Note that the values contained within the functions are typically still in memory.)
| Important | Look at the input in Figure 8-4. Suppose some of this data included a buffer that an attacker could potentially overflow. In that case, other values on the stack would be overwritten also, as shown in Figure 8-5. |
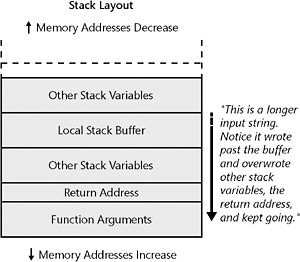
Figure 8-5: Overwriting data outside the allocated space
Then the computer processor runs the code at the return address so the caller can resume where it left off. What happens in the overflow case, however? If the input is longer than the space provided by the stack buffer but the function copies the data anyway, other stack variables and the return address are overwritten. See Figure 8-5 for a view of how the stack looks for the overflow case.
When the data is overwritten past the allocated space, it overwrites other stack variables as well as the return address. What can an attacker do with the return address to try to exploit this? For a hint, see Figure 8-6. If the attacker can control the long data, the attacker can specify long data that includes a return address or other items on the stack crafted to enable the attacker to control the machine. Notice in the figure how the attacker can adjust where in the input string the new return address appears so that it overwrites the old return address in the correct location on the stack.
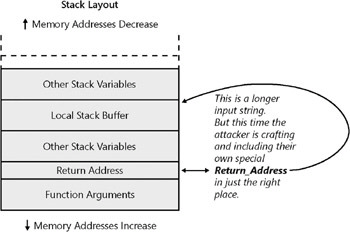
Figure 8-6: Inserting the return address supplied by the attacker
| Process memory | Computer memory is referenced by numerical addresses. On a 32-bit platform, the memory addresses are 32 bits as well. Each executable, when it runs, is given its own address space. What is present at address 0x00405060 for one process might not be the same as what is at address 0x00405060 for other processes. The operating system translates the memory address of each process to the real location to keep life simpler for the application and allow for memory resource load balancing (swapping) between a physical disk or other device and physical memory. When the process first runs, the operating system loads the program s binaries into memory. In addition to loading program files into the process memory, the process also has memory set aside for data. This typically includes the stack and any heaps in use. Other memory set aside includes addresses reserved for passing parameters between kernel and user mode, device driver memory addresses, shared memory sections, and so forth. Addresses close to 0x00000000 are never assigned because programs often accidentally read or write these low addresses. Every time something needs to be created or loaded in the process s memory, it is assigned a range of addresses for the application to use when referencing it. When reading from or writing to memory, 32-bit applications can try to read and write memory using addresses from 0x00000000 to 0xFFFFFFFF. If an application tries to access or reference memory that doesn t map to anything, the operating system generates an Access Violation (AV) exception. Trying to read unassigned memory generates a read AV . Writing to unassigned memory generates a write AV . Assigned memory can also be designated whether it can be read, written, or executed. Trying to write to read-only memory, for example, also generates a WriteAV. Because the code in the process uses the same addressing scheme as the data, addresses of code and addresses of data are interchangeable. Part of the attacker s goal in exploiting overflows is to get the attacker s data run as code by getting the program to mistake the data for code. |
This attack can overwrite the return address to point to anywhere in memory. The attacker can also send in malicious code as part of this input. Then the attacker can overwrite the return address and point it at the malicious code that is in memory. What happens when the function returns? Just like in the normal case, the variables are popped off the stack (the stack pointer ESP moves to the return address).
Then the computer processor looks at the return address listed (now overwritten) and begins to run code as specified by the attacker instead of the code that was originally listed. If attackers can somehow direct the processor to run code anywhere, they certainly can get part of their data run as code. Once the code runs, the victim is no longer 100 percent in control of the computer.
| More Info | The paper Smashing the Stack for Fun and Profit at http://www.phrack.org/show.php?p=49&a=14 provides a good discussion of the basics of how a stack and stack overflows work. |
So what if an attacker can t overwrite the stored address? It turns out there are other interesting pieces of data besides the return address that attackers can overwrite to produce exploitable overruns. The extended instruction pointer (EIP) is a register the processor uses to keep track of which instruction is to be run next. The stack frame pointer (EBP) is another processor register that eventually controls ESP and subsequently EIP. Exception handler routines are usually pushed onto the stack, and if attackers can overwrite them, they can also likely create an exception that can subsequently run their code. If there is a structure that contains a function pointer that is called after the overrun , that works as well.
Integer Overflows
Essentially, an integer overflow (also called a numeric overflow) results when the numeric data type designated to handle an operation fails to handle the data in an expected way when input numerically extends beyond the space available for that data type. For example, suppose we use a 1- dozen egg carton to store data, and we want to add 9 eggs plus 9 eggs. The egg carton holds only 12 eggs, so the groups of 9 eggs fit individually, but when the computer processor tries to add them together and store them in the egg carton, it has 6 eggs left over and cannot figure out how to fit the data.
Similarly, if a programmer tells the computer to store a number in a short integer data type, what happens when the calculation 25,000 + 25,000 is done? The short integer data type is a signed data type that holds 2 bytes (16 bits) worth of data, as illustrated in Figure 8-7 and Figure 8-8. In Figure 8-7, each zero represents one bit in this unsigned short data representation. In Figure 8-8, the leftmost zero represents the high-order bit in the signed short data representation. Like the unsigned short shown in Figure 8-7, the signed short data type uses 2 bytes of memory. The fact it is signed means the high-order bit (leading bit on the left in Figure 8-8) indicates whether the number is positive or negative. This system of storing numbers shown in Figure 8-8 is called two s complement .
Figure 8-7: Unsigned short data representation
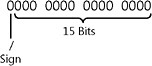
Figure 8-8: Signed short data representation
With 15 bits, 32,768 (2^15) numbers can be represented. By using the leading bit, we can double this because we can represent positive and negative numbers and zero. As you can see in Table 8-1, a given signed data type can represent one more negative numbers than positive because zero has the leading bit cleared.
| Binary | Hexadecimal | Decimal | Comment |
|---|---|---|---|
| 0000 0000 0000 0000 | 0x0000 |
| |
| 0111 1111 1111 1111 | 0x7FFF | 32767 | Largest positive number |
| 1000 0000 0000 0000 | 0x8000 | 32768 | Largest negative number |
| 1111 1111 1111 1111 | 0xFFFF | 1 |
What does the following code print out?
short int a = 25000; short int b = 25000; short int c = a + b; char sz[50]; itoa(c,sz,10); printf("%s",sz); It prints out “15536 because 25,000 plus 25,000 is too big a number to fit in 15 bits, so themath overflows and changes the sign. You ll see another example of how this applies to memory allocation later, but in the meantime let s say an attacker wants to try to get some free merchandise from an online jeweler. The jeweler advertises one item for $2,500.00. The attacker orders 17,180 of the item ”costing a grand total of $327.04! How did that happen? Well, let s take a look at how the merchant implemented its shopping cart.
//Cost per item unsigned long ItemCostPennies= 250000; //Simulated input from user //Number of items unsigned long NumberOrdered= 17180; //Compute the cost. double TotalCost = ((double) (ItemCostPennies * NumberOrdered)) / 100; printf("Transaction will cost $%.2f",TotalCost); The malicious input comes in as unsigned long values, and the total cost is then computed and charged to the customer s credit card. The first thing the computer processor does is take the ItemCostPennies (250000) and multiply by the quantity ordered (17180). This gives 4,295,000,000. Because both ItemCosePennies and NumberOrdered are long data types, the computer processor tries to store the result of the multiplication in a long. An unsigned long data type (4 bytes, or 32 bits) can hold only 2^32 (4,294,967,296) unique values.
Figure 8-9 shows what happens when the computer tries to process the binary equivalent of 4,295,000,000 using an unsigned long data type with only 32 bits of space. Notice that the binary equivalent of 4,295,000,000 uses 33 bits, so the leading bit doesn t fit. The computer processor drops the leading bit and has a remaining 32,704 left over that it carries forward. That figure is converted to a double (approximately 32,704.000000000002) and is divided by 100 (approximately 327.04000000000002). Just think: if the merchant s shopping cart code didn t represent the pennies, the attacker would have had to order 100 times as many items to accomplish the same result.

Figure 8-9: Using an unsigned long data type with only 32 bits of space to process the binary equivalent of 4,295,000,000
The problem isn t just limited to obvious numerical operations. It can also take place with memory allocation ”after all, the size of the allocation is based on numbers.
What happens when buffer allocations are done based on the results of these errors? Allocate 32,704 bytes and copy 4,295,000,000 bytes into the buffer? That s a recipe for an overrun. Follow along with the next program as we consider another example. Using Microsoft Visual Studio, start a new C++ Win32 console application project. (Note: Please use debug to follow along because retail isn t as clear.)
#include <iostream> #include <tchar.h> #include <conio.h> //Prints the data to the console window //Callers note: iLength needs to include // the ' #include < iostream > #include <tchar.h> #include <conio.h> //Prints the data to the console window //Callers note: iLength needs to include // the '\0' (null) terminator. void PrintIt(char *szBuffer, short iLength) { //If there is too much data, let's just quit. if (iLength>2048) return; char szBufferCopy[2048]; //Otherwise, we can copy the data. memcpy (szBufferCopy,szBuffer,iLength); //And send it out to the console window, //waiting for a key press. printf("%s\nPress the key of your choosing"); printf(" to continue ",szBufferCopy); while (_kbhit()) {_getch();} //flush input buffer while (!_kbhit()); //wait for keyboard input printf("\n"); } int _tmain(int argc, _TCHAR* argv[]) { //Allocate room for the incoming data. const unsigned short uiLength = 26; char *szInputFileLen = (char*)malloc(uiLength); if (!szInputFileLen) return(1); //Grab the data (simulated). memcpy(szInputFileLen, "Simulated untrusted data.", uiLength); PrintIt(szInputFileLen,uiLength); free(szInputFileLen); return 0; } ' (null) terminator. void PrintIt(char *szBuffer, short iLength) { //If there is too much data, let's just quit. if (iLength>2048) return; char szBufferCopy[2048]; //Otherwise, we can copy the data. memcpy(szBufferCopy,szBuffer,iLength); //And send it out to the console window, //waiting for a key press. printf("%s\nPress the key of your choosing"); printf(" to continue ",szBufferCopy); while (_kbhit()) {_getch();} //flush input buffer while (!_kbhit()); //wait for keyboard input printf("\n"); } int _tmain(int argc, _TCHAR* argv[]) { //Allocate room for the incoming data. const unsigned short uiLength = 26; char *szInputFileLen = (char*)malloc(uiLength); if (!szInputFileLen) return(1); //Grab the data (simulated). memcpy(szInputFileLen, "Simulated untrusted data.", uiLength); PrintIt(szInputFileLen,uiLength); free(szInputFileLen); return 0; } Assume you are examining an application containing code such as the previous listing. Untrusted input comes into the variable szInputFileLen , which is simulated using the following lines in function _tmain :
//Grab the data (simulated). memcpy(szInputFileLen, "Simulated untrusted data.",uiLength); Run the program as shown in the following graphic, and watch what happens to see how it works.
Pressing any key on the keyboard ends the simple program. If this really is untrusted data, it might be larger. Simulate this larger data by filling up szInputFileLen with 0x61 bytes. To do this quickly, and for the sake of illustration, add a memset function call to fill up the memory with 0x61 bytes (0x61 is a lowercase letter a ).
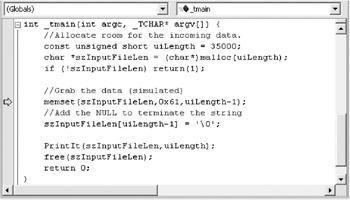
int _tmain(int argc, _TCHAR* argv[]) { //Allocate room for the incoming data. //Note that 35000 is too big for the //unsigned short data type. const unsigned short uiLength = 35000; char *szInputFileLen = (char*)malloc(uiLength); if (!szInputFileLen) return(1); //Grab the data (simulated). memset(szInputFileLen,0x61,uiLength-1); //Add the null to terminate the string. szInputFileLen[uiLength-1] = ' int _tmain(int argc, _TCHAR* argv[]) { //Allocate room for the incoming data. //Note that 35000 is too big for the //unsigned short data type. const unsigned short uiLength = 35000; char *szInputFileLen = (char*)malloc(uiLength); if (!szInputFileLen) return(1); //Grab the data (simulated). memset(szInputFileLen,0x61,uiLength-1); //Add the null to terminate the string. szInputFileLen[uiLength-1] = '\0'; PrintIt(szInputFileLen,uiLength); free(szInputFileLen); return 0; } '; PrintIt(szInputFileLen,uiLength); free(szInputFileLen); return 0; } Don t forget the ending null and to adjust the PrintIt function s parameter. You are now simulating a long string of 34,999 a characters (0x61) followed by a null . The following graphic shows what happens when this code is run:
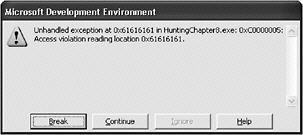
The warning message shown in the graphic claims the program is trying to read at memory location 0x61616161 , which is the data you entered. When you click the Break button, the debugger shows that you are actually trying to run code at address 0x61616161 .
| Note | When breaking into the debugger, Visual Studio might present you with other dialog boxes. One dialog box appears, for example, when Visual Studio is unable to find the source code corresponding to the current value of EIP. To follow along with the examples presented in this book, you should click the Show Disassembly button when encountering this dialog box. For more information about a specific dialog box you encounter, refer to the Visual Studio documentation. |
How did that happen? Let s step through this carefully in the debugger. Put the input focus on the memset call, and press the F9 key to set a breakpoint. Restart (press the F5 key) and run until the memset call, which you can see in the screen below. Once the breakpoint is triggered, you can select menus Debug, Windows , and Autos to automatically view variables of interest.
| More Info | A debug breakpoin t is a place in the application where execution halts, allowing you to look at code, variables, registers, memory, the call stack, and so forth. When the breakpoint location is reached, you can subsequently tell the debugger to step, step into, continue the program, or stop the program. For more information about using Visual Studio as a debugger, see http://msdn.microsoft.com/library/en-us/vcug98/html/_asug_home_page.3a_.debugger.asp . |
Notice (in the preceding screen shot of the code) that uiLength is set to 35000. The program is about to fill the szInputFileLen buffer with 34,999 a characters (0x61) and a null . So far, everything seems good. Step two more times (press the F10 key twice), and inspect what is sent into the PrintIt call as shown in the following graphic:

uiLength is still 35000. What about szInputFileLen ? To find the value of szInputFileLen , do the following.
-
Select the Debug menu.
-
Click the Windows menu.
-
Click the Memory menu.
-
Select Memory1.
-
Type the name of the variable, szInputFileLen , and press Enter.
The memory window now shows szInputFileLen .
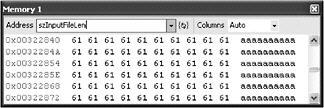
Now, let s see how long the string of 0x61 bytes is to confirm the memset call worked and check the position of the trailing null . The end of the copied data is somewhere around szIn putFileLen + uiLength . One way to check out what the end looks like is to look at the memory window starting a few addresses sooner. szInputFileLen[uiLength] is the element just past the memset data write. szInputFileLen[uiLength-10h] references an earlier element. The memory window wants an address, so &(szInputFileLen[uiLength-10h]) actually represents an address that will show us a few (16 decimal) of the trailing a bytes to confirm what the end of the memset and subsequent operations look like in memory.
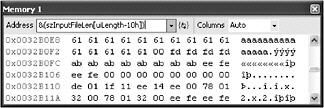
This looks pretty good ”the 0x61 bytes all copied OK, and the null is in the right place. Stepping into PrintIt (press the F11 key) reveals a problem, however:

Because iLength is signed and PrintIt checks only the upper bound, this could get interesting quickly. Stepping twice takes you to the memcpy function.
What happens when memcpy gets a “30536 for the third parameter, iLength ? You can find out because this is debug ”step into this function as shown in the graphic:
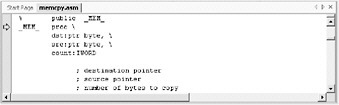
Look down a few lines and continue stepping to the following line:
This line transfers the number of bytes to copy into the ECX register. Step and you can check up on the value of ECX.
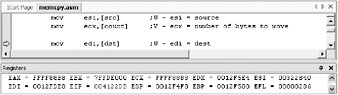
ECX is set to 0xFFFF88B8 ! That s not the 35000 the programmer had in mind.
| Note | This example could continue, and we could show an exploit, but typically it is sufficient to control the instruction pointer register to prove we can control the computer. Those interested in exploits already have many places to look (such as http://www.metasploit.com ). The focus of this book is finding the bugs, not exploiting them. For didactic purposes, there is a complete walkthrough of a proof-of-concept exploit in Chapter 9. |
So what does all of this mean? Well, when testing for buffer overflows and integer overruns, think about the limits of the data types being used and try to go beyond the limits. Think about signed and unsigned data values, especially. In practice, it is critical to construct test data that has a length of various powers of two, and slowly grow buffers from each. This can be hard, especially for 32-bit signed and unsigned values and larger. Despite the difficulty, attackers are good at performing these exploits. Those responsible for testing need to look for these issues so that products don t ship with these bugs.
| More Info | The article Basic Integer Overflows ( http://www.phrack.org/show.php?p=60&a=10 ) describes some integer overflow issues. For programmers looking to avoid making these coding mistakes, the article Integer Handling with the C++ SafeInt Class ( http://msdn.microsoft.com/library / en-us/dncode/html/secure01142004.asp ) can help. |
Heap Overruns
In addition to allocating memory on the stack, as was previously described, memory can be allocated on a heap. Unlike the stack, the heap does not allocate memory linearly. The heap also doesn t store return addresses for functions. The heap tends to be somewhat less predictable than the stack at the first casual glance. A full discussion of the heap is beyond the scope of this chapter. You can find more information about Win32 heaps at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dngenlib/html/msdn_heapmm.asp .
Many people have said that overwriting heap buffers is not exploitable for particular cases but were later proved wrong by real attackers. The truth is that they didn t know how to exploit the particular situation.
| Important | Just because someone cannot think of a way to accomplish an attack doesn t mean the attack cannot be done. |
One way to exploit the heap is by overwriting a function pointer that happens to be allocated on the heap. Another way is by freeing overrun heap memory next to an unused heap block. There might be other ways to exploit the heap, depending on how the heap implements heap control blocks and metadata about the allocations. For example, some heap implementations can be exploited if the free function is called too many times.
| More Info | One good example of a double free bug is the LBL traceroute Exploit described at http://synnergy.net/downloads/exploits/traceroute-exp.txt . |
Looking at the heap is less straightforward than examining the stack is. The main reason isn t so much that the heap is harder to understand, but rather that so many different heaps are used, each heap varies somewhat from each other heap, and some debuggers use their own instrumented heaps that behave differently from the runtime heap. If you are lucky, the heap might even tell you when you hit an overflow.
It should be noted that many (although not all) heap overflow exploits somehow also take advantage of the structure of the stack, return addresses, exception handlers on the stack, ordata on the stack to complete the exploit. Perhaps the main reason is because the locationof the data on the heap is typically not as predictable as on the stack. Attackers have a number of strategies at their disposal for attempting to manipulate how the heap allocates memory, but the specifics are beyond the scope of this book.
| More Info | There are some fairly good resources on heap overruns out there, such as these:
One example of a heap overrun vulnerability with a description of how it works is JPEG COM Marker Processing Vulnerability in Netscape Browsers, which can be found at http://nvd.nist.gov/nvd.cfm?cvename=CVE-2000-0655 . |
Other Attacks
Attackers can exploit various other permutations on the simple buffer overflow. One worth calling out happens when the program does not properly validate the offset referenced in the data before using the offset to compute where to write a value. A simple case might occur when there is enough memory allocated for, say, 10 items in a list, but the program then reads in more than 10 items. In this example, the reference to each new item is implicitly 11, 12, and so on. Sometimes the reference is more explicit, perhaps when the coordinates are specifically called out.
Once you understand what overruns are, the next step is understanding how to find them.
EAN: 2147483647
Pages: 156