3. Generating Video Surrogates Automatically
3. Generating Video Surrogates Automatically
The concept of summarization has existed for some time in areas such as text abstraction, video editing, image storyboards and other applications. In Firmin's evaluation of automatic text summarization systems, he divides summaries into three categories: 1) Indicative, providing an indication of a central topic, 2) Informative, summaries that serve as substitutes for full documents, and 3) Evaluative, summaries that express the author's point of view [42]. For video, the function of a summary is similar, but there are additional opportunities to express the result as text, imagery, audio, video or some combination. They may also appear very different from one application to the next. Just as summaries can serve different purposes, their composition is greatly determined by the video genre being presented [32]. For sports, visuals contain lots of information; for interviews, shot changes and imagery provide little information; and for classroom lecture, audio is very important.
Summarization is inherently difficult because it requires complete semantic understanding of the entire video (a task difficult for the average human). The best image understanding algorithms can only detect simple characteristics like those discussed in Section 2. In the audio track we have keywords and segment boundaries. In the image track we have shot breaks, camera motion, object motion, text captions, human faces and other static image properties.
3.1 Multimodal Processing for Deriving Video Surrogates
A video can be represented with a single thumbnail image. Such a single image surrogate is not likely to be a generic, indicative summary for the video in the news and documentary genres. Rather, the single image can serve as a query-relevant indicative summary. News and documentary videos have visual richness that would be difficult to capture with a single extracted image. For example, viewers interested in a NASA video about Apollo 11 may be interested in the liftoff, experiences of the astronauts on the moon or an expert retrospective looking back on the significance of that mission. Based on the viewer's query, the thumbnail image could then be a shot of the rocket blasting off, the astronauts walking on the moon or a head shot of the expert discussing the mission, respectively. Figure 9.5 illustrates how a thumbnail could be chosen from a set of shot key frame images.
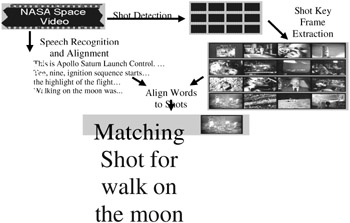
Figure 9.5: Thumbnail selection from shot key frames.
Given the NASA video, speech recognition breaks the dialogue into time-aligned sequences of words. Image processing breaks the visuals down into a sequence of time-aligned shots. Further image processing then extracts a single image, i.e., frame, from the video to represent each shot. When the user issues a query, e.g., "walk on the moon," language processing can isolate the query terms to emphasize (e.g., walk and moon), derive additional forms (e.g., "walking" for "walk"), and identify matching terms in the dialogue text. In the case illustrated in Figure 9.5, the query walk on the moon matches most often to the shot at time 3:09 when the dialogue includes the phrase Walking on the moon. The shot at time 3:09 is represented by a black and white shot of two astronauts on the moon, and this shot's key frame image is then chosen as the image surrogate for this video given this query context. Speech, image and language processing each contribute to the derivation of a single image to represent a video document.
3.2 Feature Integration
The features described in previous sections may be used with rules that describe a particular type of video shot to create an additional set of content-based features [52]. By experimentation and examples from video production standards, we can identify a small set of heuristic rules for assessing a "summary rank" or priority to a given subset of video. Once these subsets are identified, a summary may be generated based on the application and user specifications. In most cases these rules involve the integration of image processing features with audio and language features. Below is a description of four rule-based features suitable for most types of video.
Image and Audio Selection
The first example of a video surrogate is the selection or ranking of audio based on image properties, and vice versa. Audio is parsed and recognized through speech recognition, keyword spotting and other language and audio analysis procedures. A ranking is added to the audio based on its proximity to certain imagery. If an audio phrase with a certain keyword value is within some short duration of a video caption, it will receive a higher summary rank than an audio phrase with a similar keyword value. An example of this is shown in Figure 9.6.

Figure 9.6: Audio with unsynchronized imagery.
Introduction Scenes
The shots prior to the introduction of a person usually describe their accomplishments and often precede shots with large views of the person's face. A person's name is generally spoken and then followed by supportive material. Afterwards, the person's actual face is shown. If a shot contains a proper name or an on-screen text title, and a large human face is detected in the shots that follow, we call this an Introduction Scene. Characterization of this type is useful when searching for a particular human subject because identification is more reliable than using the image or audio features separately. This effect is common in documentaries based on human recognition or achievement.
Inter-cut Scenes
In this example, we detect an inter-cutting sequence to rank an adjacent audio phrase. This describes the selection of the inter-cutting shot. The color histogram difference measure gives us a simple routine for detecting similarity between shots. Shots between successive imagery of a human face usually imply illustration of the subject. For example, a video producer will often interleave shots of research between shots of a scientist. Images that appear between two similar scenes that are less than Tss seconds apart are characterized as an adjacent similar scene. An example of this effect is shown in Figure 9.7a. Audio near the inter-cut receives a higher rank than subsequent audio.

Figure 9.7a: Inter-cut shot detection for image and audio selection.
Short Successive Effect
Short successive shots often introduce an important topic. By measuring the duration of each scene, SD, we can detect these regions and identify short successive sequences. In practice, summary creation involves selecting the appropriate keywords or audio and choosing a corresponding set of images. Candidates for the image portion of a summary are chosen by two types of rules: 1) Primitive Rules, independent rules that provide candidates for the selection of image regions for a given keyword, and 2) Meta-Rules, higher order rules that select a single candidate from the primitive rules according to global properties of the video. For some cases, the image selection portion will supersede an audio keyphrase for summary selection. An example of this effect is shown in Figure 9.7b, where each thumbnail represents approximately 10 frames, or 1/3 a second of video. The first image appears at a normal pace. It is followed by three short shots and the normal pace resumes with the image of the temple.

Figure 9.7b: Short successive effects.
3.3 Summary Presentations
The format for summary presentation is not limited to shortened viewing of a single story. Several alterations to the audio and image selection parameters may result in drastically different summaries during playback. Summary presentations are usually visual and textural in layout. Textual presentations provide more specific information and are useful when presenting large collections of data. Visual, or iconic, presentations are more useful when the content of interest is easily recalled from imagery. This is quite often the case in stock footage video where there is no audio to describe the content. Many of the more common formats for summarizing video are described below. Section 5 describes recent applications that use multimodal features for visualizing video summaries.
Titles - Text Abstracts
Titles have a long history of research through text abstraction and language understanding [38]. The basic premise is to represent a document by a single sentence or phrase. With video, the title is derived from the transcript, closed-captions, production notes or on-screen text.
Thumbnails and Storyboards - Static Filmstrips
The characterization analysis used for selecting important image and audio in summaries may be applied to select static poster-frames. These frames may be shown as a single representative image, or thumbnail; or as a sequence of images over time, such as a storyboard.
Duration Control
For various applications, a user will want to vary the compaction level during playback. This flexibility should exist in much the same that videocassette editors allow for speed control with a roll bar. Such a feature is implemented for variable rate summarization as an option for the user interface.
Skims - Dynamic Summaries
Skims provide summarization in the form of moving imagery. In short, they are subsets of an original sequence placed together to form a shorter video. They do not necessarily contain audio [50].
User Controlled Summaries
For indexing, an interactive weighting system is used to allow for personal text queries during summary creation. A text query may be entered and used during the TF-IDF weighting process for keyword extraction or during speech alignment.
Summarizing Multiple Documents
A summary is not limited to coverage of a single document or video. It may encompass several sets of data at an instant or over time. In the case of news, it is necessary to analyze multiple stories to accurately summarize the events of a day.
EAN: 2147483647
Pages: 393