3. The Multi-Modal Two-Level Framework
3. The Multi-Modal Two-Level Framework
3.1 Structure of News
Most news videos have rather similar and well-defined structures. Figure 44.1 illustrates the structure of a typical news video. It typically begins with several Introduction/highlight shots that give a brief introduction of the upcoming news items to be reported. The main body of news contains a series of stories organized in terms of different geographical interests (such as international, regional, and local) and in broad categories of social political, business, sports, entertainment and weather. Each news story normally begins and ends with anchorperson shots and several in-between live-reporting shots. Most news ends with reports on sports, finance, and weather. In a typical half an hour news, there will be several periods of commercials, covering both commercial product and self-advertisement by the broadcasting station.
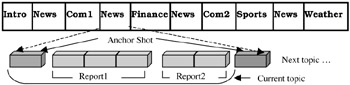
Figure 44.1: The structure of local news video under study
Although the ordering of news items may differ slightly from broadcast station to station, they all have similar structure and news categories. In order to project the identity of a broadcast station, the visual contents of each news category, like the anchorperson shots, finance and weather reporting etc., tends to be highly similar within a station, but differs from that of other broadcast stations. Hence, it is possible to adopt a learning-based approach to train the system to recognize the contents of each category within each broadcast station.
3.2 The Design of News Classification and Segmentation System
To tackle the problem effectively, we must address three basic issues. First, we need to identify the suitable units to perform the analysis. Second, we need to extract an appropriate set of features to model and distinguish different categories. Third, we need to use a good technique to perform the classification and identify the boundaries between stories. To achieve these, we adopt the following strategies as shown in Figure 44.2.
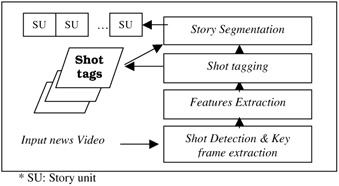
Figure 44.2: Overall system components
-
We first segment input video into shots and extract the representative key frame for each shot using mature techniques.
-
We extract a suitable set of features to model the contents of shots. The features include low level visual and temporal features, and high-level features like faces. We select only those features that can be automatically extracted in order to automate the entire classification process.
-
We employ a learning-based approach that uses multi-modal features to classify the shots into the set of well-defined subcategories. This is known as the shot tagging process.
-
Finally, given a sequence of shots in respective subcategories, we use a combination of shot categories, content, and temporal features to identify story boundaries using the HMM technique. This process is referred to as the story segmentation process as shown in Figure 44.2.
The detailed design of the system is illustrated in Figure 44.3. Further details of the system components are discussed in Section 4 and Section 5.
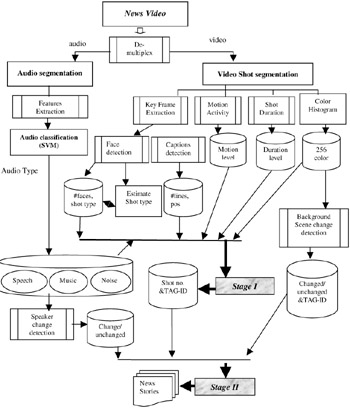
Figure 44.3: The detailed design system components
EAN: 2147483647
Pages: 393