3. A Flexible Architecture to Store Multimedia Data
3. A Flexible Architecture to Store Multimedia Data
When applications deal with sets of video and images, the usual approach is to store all of them in a single repository. Common examples, both on commercial and research-based systems, are the QBIC (http://wwwqbic.almaden.ibm.com/) [34], VisualSEEk (http://www.ctr.columbia.edu/VisualSEEk/) [35], Virage (http://www.virage.com/) [36], CueVideo [37] (http://www.almaden.ibm.com/cs/cuevideo/), Chabot [38], etc. Another class of image repositories are the Picture Archiving and Communications Systems (PACS) based on the DICOM image format, widely used in hospital equipments and medical applications [39]. Images in PACS are tagged in the DICOM format [40], and stored in a centralized repository. Images obtained from different kinds of exams and/or equipments are stored together, and classified by tags set individually at each image.
The aforementioned systems store all images in a single dataset. In other words, the logical separations recognized over the full set of images, such as classes or groupings, are recorded through tags set individually at each image. This approach is not suitable to process image retrieval operations in large datasets, because each request for a subset of images tagged in a given way requires processing the full image set, filtering the required images looking for the tag values at each image. A more effective way to store images considering their natural, semantic partitioning is adopting the architecture of relational databases.
Relational Database Management Systems (RDBMS) store large amount of information in tables (also called relations), which are composed by attributes of various types. The use of RDBMS or database management systems (DBMS) for short leads to flexible, expansible and highly maintainable information systems. Each line of a table is called a tuple in the relational jargon, and corresponds to a real world entity. Each column of a table is called an attribute, which can have at most one value in each tuple. Each column has its values chosen from a specific data domain, although many attributes can have their values picked from the same domain. For example, the set of grad students in a school could be stored in a students table, having as attributes their names, ages, the course they are enrolled in and their advisor. The name attribute gets its value from the domain of people names, its age from the set of integer numbers that are valid ages for humans, the course from the courses offered by the school and the advisor attribute from the domain of people names. The attributes name and advisor are taken from the same domain, because both correspond to people names. They can be compared for identification of the same person, and they can indistinctly be used to find personal data in other tables.
Using these relational concepts, one could want to add two attributes in the Students table to store their mugshots, called Frontview and Profile. As frontal images are completely different from side images of a human face, there is no meaning in comparing a pair of them, and if they are to be used to find data in other tables, the proper image should be selected. Therefore, it is worth to consider FrontView and Profile as two non-intersecting sets of images, and consequently as elements from distinct domains. Consequently, both sets can be stored as separated sets of images, and whenever an operation is executed to select some images from one set, it would not retrieve images from the other set. This approach is much more effective than considering the whole set of images, as accounted by the traditional image repositories.
Unfortunately, the common RDBMS do not support images adequately. They only enable to store images as Binary Large OBjects - BLOB data. Images are retrieved by identifying the tuple where they are stored using other textual or numeric attributes, which are stored together in the same tuple.
In the next section we show how an RDBMS can be extended to support content-based image retrieval in a relational database. Despite enabling the construction of more efficient image storage systems, the relational approach makes it easy to extend existing applications, which already use relational databases, to support images. The usual image repositories are monolithic systems, whose integration with other systems requires cumbersome, and typically inefficient, software interfaces. On the other hand, the relational approach, as described next, affords a modular system that is simple, efficient, expansive and easy to be maintained.
3.1 Extending RDBMS Table Infrastructure to Support Images
The standard relational database access language is the Structured Query Language -SQL. It is a declarative retrieval language; that is, it allows the user to declare what he/she wants, and the system decides how to retrieve the required data. This property allows the system to optimize the query execution process, taking advantage of any resource the database manager has, in order to accelerate the retrieval process. To be able to automatically design the query retrieval plan, the RDBMS must have a description of the application data structure, which is called the application schema. The schema includes the structure of the tables and the attribute domains. The SQL commands can be divided in at least two subsets:
-
the Data Definition sub-Language (DDL),
-
the Data Manipulation sub-Language (DML).
The DML commands allow to query and to update the application data. They are the most used commands during the normal operation of the information system. The DDL commands allow the description of the schema, including the description of the table's structures, attribute's domains, user's access authorizations, etc. Typical RDBMS store the application schema in system-controlled tables, usually called the database dictionary. These tables are defined following the modeling of the relational model itself, so the relational model is called a meta-model. An important consequence is that the modeling of the relational model is independent of the modeling of the application data, and therefore both can be maintained in the same database, without interfering with each other. Since both modelings are maintained in the same database, the DML commands can be seen as those that query and update the data stored in the application tables, and the DDL commands can be seen as those that query and update the data stored in the meta tables.
Considering that the same relational database stores tables for more than one purpose, Figure 29.5 shows the operations executed over each set of tables, to execute DDL and DML commands. In this figure, the schema tables are identified as RDB (the meta tables), following the common practice of using the prefix RDB$ preceding the names of these tables. The application tables are identified as the ADB (application tables) in Figure 29.5. The different sets of tables are accessed and maintained independently from each other, so they can be seen as conceptually separated databases inside the same physical database. Hence, in the rest of this chapter we call them logical databases.
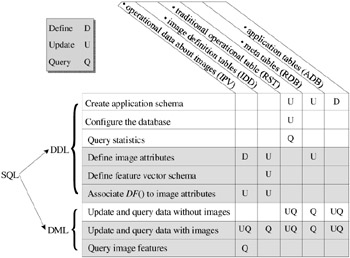
Figure 29.5: Operations executed over each logical database by each command in SQL. The definition (D), update (U) and query (Q) operations are performed to process the issued commands. The grey rows of the table refer to image related operations.
Traditional RDBMS deal with simple data types, letting the attributes be defined only as numbers, small character strings, dates and BLOBs. Therefore, those RDBMS do not support the retrieval of images based on their content. However, a software layer can be developed atop the database system, which monitors the communication stream between the applications and the database server. We describe here the main ideas that enable us to build a generic Content-based Image Retrieval Core Engine - CIRCE. This is a software layer that recognizes an extended version of SQL, which supports not only the storage of images as a new data type, but also the indexing and retrieval of images based on their content. Such operations are the basis to support similarity searching. The language extensions were designed aiming to minimize the modifications in the language and at the same time maximizing its power to express image retrieval conditions.
As a software layer that intercepts every command between the applications and the database server, CIRCE is able to extend any RDBMS that can store BLOB data types to support images and, with few modifications, also to support the storage and content-based retrieval over any kind of complex data, including long texts, audio and video. Therefore, although in this section we are describing a generic module to extend SQL to support image storage and content-based retrieval, the same concepts can be applied to support the storage and retrieval by content on any kind of multimedia data.
The extensions in SQL to support images are made both in DML and in DDL, which is presented in the grey rows of Figure 29.5. The extensions for update commands in DML correspond to new syntaxes to allow insertion, substitution and deletion of images in attributes of the type image in the application tables. Also, the extension in the query command in DML corresponds to the creation of new search conditions, to allow expressing range and nearest neighbors conditions in the query command. The extensions in the DDL commands require the modeling of the image support, the creation of a new schema to support the description of image definitions, as well as the definition of how the attributes should compose the application tables. The modeling of images is independent both from the relational meta-modeling and from the application modeling. Thus, the image modeling does not interfere with the existing ones. Moreover, as any other modeling, the image modeling also requires specific tables to be created in the database, to store the image definitions and parameters issued by the user through the new image-related DDL commands.
Therefore, two new logical databases are included in a RDBMS, identified as IPV and IDD in Figure 29.5. They will be explained in the next sub-section.
Besides the meta and the application logical databases, a traditional RDBMS stores operational data that helps to improve query processing. Although usually considered as part of the dictionary (and in some cases sharing the same physical tables), operational data in fact correspond to different information from that in the meta schema. The meta schema describes the application's data, like the tables and the attributes that constitutes each table, the domain of each attribute, etc. The operational data usually consist of statistics about the size of the tables, frequency of access, and so on. Therefore, they are stored in another logical database, identified in Figure 29.5 as the traditional operational tables (RST - relational statistics). The main purpose of this logical database is to provide data to create good query plans to execute the DML commands. As the operational data are gathered internally by the system and are used to optimize the query plans, there is no need of commands in SQL to update or retrieve the operational data (although high-end RDBMS usually provide commands for the database administrator to monitor and to fine-tune the database behavior through the operational data).
When dealing with data much more complex than numbers and small character strings, such as images, a more extensive set of operational data is required. Therefore, when an RDBMS is extended to support images, a new logical database is required to store operational data about the images. Differently from the traditional operational data, the end user may be interested in some operational data about the images. Consequently, it is interesting to provide constructs in the DML query command that allow users to query the operational data about images.
Therefore, tables managed by an RDBMS extended to support content-based image retrieval must comprise five logical datasets, as shown in Figure 29.6. The meta tables and the traditional operational data constitute the data dictionary. These five sets of tables are accessed and maintained independently from each other; consequently they are five conceptually separated logical databases inside the same physical database. The next section explains in more detail the two new logical databases IPV and IDD intended to support images, and how they are used in CIRCE to implement the "image data type" in a RDBMS.
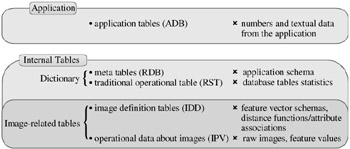
Figure 29.6: The five logical databases required to support the application data and content-based image retrieval in an RDBMS.
3.2 A Relational Database Architecture to Support Images
A content-based image retrieval (CBIR) system is built taking advantage of image processing algorithms that we call extractors, each one getting values from a set of one or more features from each image. The extracted features, also called "ground features" [12], can be applied not only to compose the feature vectors used in comparison operations, but also as parameters to control the execution of other extractors. The extracted features can be arranged to create one or more feature vectors for each image, each one following a predefined schema, that is, the structure of the feature vector. Different feature vector schemas aim to explore different ways to compare images. For example, images can be compared by their histograms, or by their texture, or by the combination of both of them. For each kind of comparison a different feature vector schema must be used, although some schemas can share the same features already extracted.
Each feature vector schema must be associated to one distance function DF(), in order to allow image comparison operations. The main concept in the feature extraction technique is that comparisons between pairs of real images are approximated by comparisons between their feature vectors. Feature vectors create a base to define distance functions that assign a dissimilarity value to each pair of images in a much more efficient way than processing the real images. A metric DF() must obey the non-negativity, symmetry and the triangular inequality properties, as it was stated in section 2.2. Maintaining the images in a metric domain authorizes the use of metric access methods accelerating greatly the image retrieval operations.
Figure 29.7 depicts the steps involved in the feature extraction technique in a data flow diagram. The whole process can be described as follows. Given a set of images from the same domain, they will have their features obtained by extractors. As the extractors are general-purpose algorithms, a given DF() may only use some of the features extracted by each extractor, discarding those not necessary in a particular situation. Moreover, some of the features extracted can be used as parameters to control other extractors executed in sequence. The most interesting features from a set of extractors are merged to create a feature vector. As the same sequence of extractors is used to process every image, we call this sequence and the resulting set of features is a feature vector schema. Two feature vectors can be compared only if they have the same feature vector schema. The feature arrays conform to a feature vector schema and from the same image domain can be indexed by a MAM, e.g., the Slim-tree, creating an index structure. At the querying time, the query image given by the user will have its features extracted and the search will be done in the corresponding index structure. The results will return the indication of the images that match the searching criteria specified by the user.
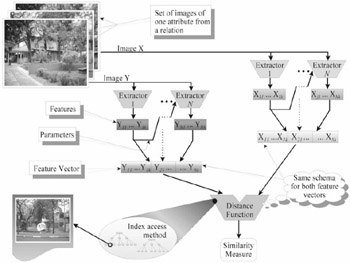
Figure 29.7: Structure of the operations needed to support content-based retrieval operations in a set of images.
To support similarity queries in CBIR, the extensions of SQL must enable the definition of the following concepts:
-
the definition of images as a native data type;
-
the definition of the feature vectors and the corresponding DF();
-
the similarity conditions based on the k-nearest neighbor and range operators.
The main idea is to consider images as another data type supported natively by the DBMS. Therefore, images are stored as attributes in any table that requires them, and each table can have any number of image attributes.
The general architecture of CIRCE, a generic module to enable RDBMS to support CBIR, is shown in Figure 29.8. Three logical databases are represented in this figure: the ADB, IPV and IDD. The ADB corresponds to the existing application database, the IPV corresponds to the operational data about images and IDD corresponds to the image definition database. Applications that do not support images keep the attributes of the tables stored in the ADB as numbers and/or texts. The ADB can be queried using either the standard SQL or the extended SQL. However, when an application is developed using image support, or when an existing one is expanded to support images, the application must use the extended SQL through CIRCE.
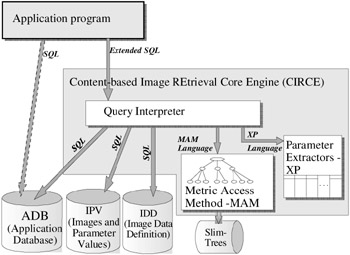
Figure 29.8: Architecture of the image support core engine.
Each image attribute defined in a table establishes a set of images disjointed from the set established by the other attributes. That is, each image attribute in each tuple stores only one image. If a query command uses only non-image attributes, the command is sent untouched to the ADB. Whenever an image attribute is mentioned in a query command, CIRCE uses the IPV and IDD databases, together with the metric access methods and the parameter extractors (XP), to modify the query command attending images. This approach effectively implements image retrieval by content.
The IPV database (that stores operational data about images) has one table for each attribute of type image defined in the application database. Each table holds at least two attributes: a blob attribute storing the actual image, and an Image Identifier (ImId) created by the system. The identifier is a code number, unique for every image in the database, regardless of the table and particular attribute where it is stored. Each "create table" command referencing image attributes is modified, so a numeric data type replaces the image data type in the modified command sent to the ADB. The corresponding table in the IPV database is named after the concatenation of the table and attribute names of the original image attribute. Consequently, occurrences of this attribute in further query commands are intercepted by CIRCE and translated accordingly. For example, the students table with two image attributes generates two tables in the IPV database named Students_FrontView and Students_Profile, each one with two attributes: the image and the ImId.
The comparison of two images requires a metric distance function definition. This is done through the new command in the extended SQL: the "create metric" command. It is part of the Data Definition Language (DDL) of SQL, and enables the specification of the DF() by the domain specialist. Each metric DF() is associated with at least one image attribute, and an image attribute can have any number of metrics DF(). Image attributes that do not have a DF() cannot be used in searching conditions; so these attributes are just stored and retrieved in the traditional way. However, if one or more metric DF() is defined, it can be used both in content-based search conditions and in metric access methods. Image attributes associated with more than one DF() can be used both in searching conditions and in indexing structures. If more than one DF() is associated to an indexed image attribute, then each DF() will create an independent indexing structure. Comparison operations always use just one DF(). Therefore, comparisons involving attributes associated with more than one DF() must state which one is intended to be used (although a default one can be defined for each attribute).
A DF() definition enrolls one or more extractors and a subset of the features retrieved by each extractor. Here we consider as features only numbers or vectors of numbers. If the extractors used in a DF() return only numbers, the feature vectors of every image stored in the associated attribute have the same quantity n of elements. Thus, each feature vector is a point in a n-dimensional space. However, extractors returning vectors may generate feature vectors with different quantity of elements, resulting in a non-spatial domain. This domain can be metric if the DF() is metric. To assure this property, we consider the definition of Lp-norm DF() over the elements of feature vectors, as defined in section 2.2. The power p of the norm can be specified as zero (Chebychev), one (Manhattan) or two (Euclidean). Each element i in the feature vector has its individual weight wi. Those elements corresponding to vectors have the difference calculated as the double integral of the curve defined by the vectors [3].
Whenever a DF() is defined for an image attribute, the corresponding table in the IPV database is modified to include the elements of the feature vector as numeric attributes. Therefore, whenever an image is stored in the database as the value for an image attribute, every extractor enrolled by each DF() associated to the corresponding image attribute is executed, and the extracted features are stored in the corresponding table in the IPV database. The resulting feature vectors used by each DF() are inserted in each corresponding indexing structure. This enables the retrieval of images based on more than one similarity criterion, allowing the user to choose which criterion is required to answer each query. Each index structure (built upon a metric access method) stores the ImId and the corresponding feature vector extracted from each image. The set of index structures allows the execution of the k-nearest neighbors and range search procedures using the feature vectors as input, and returning the set of ImId that answer the query.
The IDD database is the image definition database, that is, the schema for the image attributes. It stores information about each extractor and its parameters. Therefore, whereas the IPV database store the actual image and the values of its features, it is the IDD database that guides the system to store and retrieve the attributes in the IPV database. Whenever a tuple containing image attributes is stored, each image is processed by the set of extractors in the Parameter Extractor module (XP), following the definitions retrieved from the IDD database. Subsequently, its ImId is created and stored, together with the image and the feature vector, in the IPV database. The original tuple from the application is stored in the ADB, exchanging the images with the corresponding ImId identifiers.
Whenever a query has to be answered, the feature vectors of the involved images are used in place of the real image. If the query refers to images not yet stored in the database (images given directly inside the query), the same feature vectors associated to the image attribute being compared are extracted from this image and used to search the database. This feature vector is sent to the corresponding index structure, which retrieves the ImId of the images that answer the query. Using these ImId, the IPV database is sought to retrieve the actual images that, in turn, are passed as the answer to the requester process.
EAN: 2147483647
Pages: 393