14.2 Perl: An Alternate Administrative Language
| Perl[3] is a free programming language created by LarryWall and currently developed and maintained by a core group of talented programmers (see http://www.perl.org, http://www.perl.com and http://www.cpan.org for more information). Perl has become quite popular in recent years. It contains many features that make it very well suited to writing scripts for system administrative tasks, including the following:
Perl features come from a variety of sources, including standard shells, C, Fortran, Basic, Pascal, awk, and sed. I don't think Larry's managed to use any COBOL features yet, but I've been wrong before. To get started using Perl, I recommend the following books:
14.2.1 A Quick IntroductionThe best way to see what Perl has to offer is to look at a few Perl programs. We'll begin with dr, a Perl script I wrote to make theAIX dosread command worth using. By default, dosread copies a single file from a DOS diskette, and it requires that you specify both the DOS filename and the local filename (and not just a target directory). Of course, what one often wants to do is to copy everything on a diskette; this Perl script copies all the files on a diskette to the current directory, translating the destination filenames to lowercase: #!/usr/bin/perl -w Executable location varies. # dr - copy all the files on a DOS diskette # store the list of files on the diskette @files = `dosdir | egrep -v "^(Free|There)"`; foreach $f (@files) { # loop over files chop $f; # remove newline char $g = $f; $g =~ tr/A-Z/a-z/; # translate to lowercase print $f,"*",$g,"\n"; system("dosread -a -v $f ./$g"); } The first command looks almost like a C shell command. It runs the command in back quotes and stores the output in the array @files (the AIX dosdir command lists the files on a diskette, and the egrep command throws away the summary line). Names of numerically indexed arrays begin with an @ sign when the entire array is referenced as a whole. Note also that Perl statements end with a semicolon. Perl scalar variable names always begin with a dollar sign, as the next few commands illustrate; no special syntax is needed to dereference them. The remainder of the script is a foreach loop; the commands within the loop are enclosed in curly braces (as in C). The loop variable is $f, and $g eventually holds a lowercase version of the name in $f. The final two commands do the actual work. The print command displays a string like the following for each file on the diskette: PROPOSAL.TXT*proposal.txt The purpose of this display is mostly to provide that warm-and-comfortable feeling while AIX's excruciatingly slow diskette commands run. The system command is used to run a Unix command from Perl, in this case dosread. This version of dr is leisurely paced and is designed to emphasize the similarities between Perl and other languages. However, a native speaker might write it more like this: #!/usr/bin/perl # dr - terse version foreach (`dosdir | egrep -v "Free|Total"`) { chop; system("dosread @ARGV $_ \L$_"); } The foreach statement is still intelligible, but the other commands require some explanation. Perl provides a default variable that is used in commands where a variable is needed but none is specified; the name of this variable is $_ (dollar-underscore). $_ is being used as the loop variable and as the argument to chop. The \L construct in the system command translates $_ to lowercase. This system command is more general than the one in the previous version. It passes any arguments specified to the script stored in the array @ARGV on to dosread and uses $_ as both of dosread's arguments; filenames on diskette aren't case-sensitive, so this works fine. The two versions of dr illustrate an important Perl principle: there's more than one way to do it (the Perlslogan). 14.2.2 A Walking Tour of Perlwgrep is a tool I wrote for some users still longing for the VMS Search command they used years previously. wgrep stands for windowed grep, and the command searches files for regular expression patterns, optionally displaying several lines of context around each matching line. Like the command it was designed to imitate, some of its options will strike some purists as excessive, but it will also demonstrate many of Perl's features in a more complex and extended context. Here is the usage message for wgrep: Usage: wgrep [-n] [-w[b][:a] | -W] [-d] [-p] [-s] [-m] regexp file(s) -n = include line numbers -s = indicate matched lines with stars -wb:a = display b lines before and a lines after each matched line (both default to 3) -W = suppress window; equivalent to -w0:0 -d = suppress separation lines between file sections -m = suppress file name header lines -p = plain mode; equivalent to -W -d -h = print this help message and exit Note: If present, -h prevails; otherwise, the rightmost option wins in the case of contradictions. Here is a sample of wgrep's most baroque output format, including line numbers and asterisks indicating matched lines, in addition to headers indicating each file containing matches and separators between noncontiguous groups of lines within each file: wgrep -n -s -w1:1 chavez /etc/passwd /etc/group ********** /etc/passwd ********** 00023 carnot:x:231:20:Hilda Carnot:/home/carnot:/bin/bash * 00024 chavez:x:190:20:Rachel Chavez:/home/chavez:/bin/csh 00025 claire:x:507:302:Theresa Claire:/home/claire:/bin/csh ********** /etc/group ********** * 00001 wheel:*:0:chavez,wang,wilson 00002 other:*:1: ********** 00014 genome:*:202: * 00015 dna:*:203:chavez * 00016 mktg:*:490:chavez 00017 sales:*:513: After initializing several variables related to output formats, wgrep begins by dealing with any options that the user has specified: #!/usr/bin/perl -w # wgrep - windowed grep utility $before = 3; $after = 3; # default window size $show_stars = 0; $show_nums = 0; $sep = "**********\n"; $show_fname = 1; $show_sep = 1; # loop until an argument doesn't begin with a "-" while ($ARGV[0] =~ /^-(\w)(.*)/) { $arg = $1; # $arg holds the option letter This while statement tests whether the first element of @ARGV (referred to as $ARGV[0] because array element references begin with a $ sign) the array holding the command-line arguments matches the pattern contained between the forward slashes: ^-(\w)(.*). Most of the elements of the pattern are standard regular expression constructs; \w is a shorthand form for [a-zA-Z0-9_]. Within a regular expression, parentheses set off sections of the matched text that can be referred to later using the variables $1 (for the first matched section), $2, and so on. The next line copies the first matched section the option letter to the variable $arg. The next portion of wgrep forms the remainder of the body of the while loop and processes the available options:[5]
if ($arg eq "s") { $show_stars = 1; } elsif ($arg eq "n") { $show_nums = 1; } elsif ($arg eq "m") { $show_fname = 0; } elsif ($arg eq "d") { $show_sep = 0; } elsif ($arg eq "w") { # parse 2nd matched section at colon into default array @_ split(/:/,$2); $before = $_[0] if $_[0] ne ''; $after = $_[1] if $_[1] ne ''; } elsif ($arg eq "p") { $before = 0; $after = 0; $show_sep = 0; } elsif ($arg eq "W") { $before = 0; $after = 0; } elsif ($arg eq "h") { &usage(""); } else { &usage("wgrep: invalid option: $ARGV[0]"); } # end of if command shift; # go on to next argument } # end of foreach loop The foreach loop contains a long if-then-else-if construct, illustrating Perl's eclectic nature. In general, conditions are enclosed in parentheses (as in the C shell), and they are formed via Bourne shell-like operators (among other methods). No "then" keyword is required because the commands comprising the if body are enclosed in curly braces (even when there is just a single command). Most of the clauses in this if statement set various flags and variables appropriately for the specified options. The clause that processes the -w option illustrates a very nice Perl feature, conditional assignment statements: split(/:/,$2); $before = $_[0] if $_[0] ne ''; The split command breaks the second matched section of the option indicated by $2 into fields using a colon as a separator character (remember the syntax is, for example, -w2:5), storing successive fields into the elements of the default array @_. The following line sets the value of $before to the first element, provided that it is not null: in other words, provided that the user specified a value for the window preceding a matched line. The final else clause calls the usage subroutine when an unrecognized option is encountered (the ampersand indicates a subroutine call). The shift command following the if statement works just as it does in standard shell, sliding the elements of @ARGV down one position in the array. The next section of wgrep processes the expression to search for: &usage("missing regular expression") if ! $ARGV[0]; $regexp = $ARGV[0]; shift; $regexp =~ s,/,\\/,g; # "/" --> "\/" # if no files are specified, use standard input if (! $ARGV[0]) { $ARGV[0] = "STDIN"; } If @ARGV is empty after processing the command options, the usage subroutine is called again. Otherwise, its first element is assigned to the variable $regexp, and another shift command is executed. The second assignment statement for $regexp places backslashes in front of any forward slashes that the regular expression contains (since the forward slashes are the usual Perl pattern delimiter characters), using a syntax like that of sed or ex. After processing the regular expression, wgrep handles the case where no filenames are specified on the command line (using standard input instead). The next part of the script forms wgrep's main loop: LOOP: foreach $file (@ARGV) { # Loop over file list if ($file ne "STDIN" && ! open(NEWFILE,$file)) { print STDERR "Can't open file $file; skipping it.\n"; next LOOP; # Jump to LOOP label } $fhandle = $file eq "STDIN" ? STDIN : NEWFILE; $lnum = "00000"; $nbef = 0; $naft = 0; $matched = 0; $matched2 = 0; &clear_buf(0) if $before > 0; This foreach loop runs over the remaining elements of @ARGV, and it begins by attempting to open the first file to be searched. The open command opens the file specified as its second argument, defining the file handle a variable that can be used to refer to that file in subsequent commands specified as its first argument (file handles are conventionally given uppercase names). open returns a nonzero value on success. If the open fails, wgrep prints an error message to standard error (STDIN and STDERR are the file handles for standard input and standard error, respectively) and the file is simply skipped. The variable $fhandle is set to "STDIN" or "NEWFILE", depending on the value of $file, using a C-style conditional expression statement (if the condition is true, the value following the question mark is used; otherwise, the value following the colon is used). This technique allows the user to specify STDIN on the command line anywhere within the file list. Following a successful file open, some other variables are initialized, and the clear_buf subroutine is called to initialize the array that will be used to hold the lines preceding a matched line. The call to clear_buf illustrates an alternate form of the if statement: &clear_buf(0) if $before > 0; The file is actually searched using a while loop. It may be helpful to look at its logic in the abstract before examining the code: while there are lines in the file if we've found a match already if the current line matches too print it and reset the after window counter but if the current line doesn't match if we are still in the after window print the line anyway otherwise we're finally out of the match window, so reset all flags and save the current line in the before buffer otherwise we are still looking for a matching line if the current line matches print separators and the before window print the current line set the match flag but if the current line doesn't match save it in the before buffer at the end of the file, continue on to the next file Here is the part of the while loop that is executed once a matching line has been found. The construct <$fhandle> returns each line in turn from the file corresponding to the specified file handle: while (<$fhandle>) { # loop over the lines in the file ++$lnum; # increment line number if ($matched) { # we're printing the match window if ($_ =~ /$regexp/) { # if current line matches pattern $naft = 0; # reset the after window count, &print_info(1); # print preliminary stuff, print $_; # and print the line } else { # current line does not match if ($after > 0 && ++$naft <= $after) { # print line anyway if still in the after window &print_info(0); print $_; } else { # after window is done $matched = 0; # no longer in a match $naft = 0; # reset the after window count # save line in before buffer for future matches push(@line_buf, $_); $nbef++; } # end else not in after window } # end else curr. line not a match } # end if we're in a match The while loop runs over the lines in the file corresponding to the file handle in the $fhandle variable; each line is processed in turn and is accessed using the $_ variable. This section of the loop is executed when we're in the midst of processing a match: after a matching line has been found and before the window following the match has been finished. This after window is printed after the final matched line that is found within the window; in other words, if another matching line is found while the after window is being displayed, it gets pushed down, past the new match. The $naft variable holds the current line number within the after window; when it reaches the value of $after, the window is complete. The print_info subroutine prints any stars and/or line numbers preceding lines from the file (or nothing if neither one is requested); an argument of 1 to print_info indicates a matching line, and 0 indicates a nonmatching line. Here is the rest of the while loop, which is executed when we are still looking for a matching line (and therefore no lines are being printed): else { # we're still looking for a match if ($_ =~ /$regexp/) { # we found one $matched = 1; # so set match flag # print file and/or section separator(s) print $sep if $matched2 && $nbef > $before && $show_sep && $show_fname; print "********** $file **********\n" if ! $matched2++ && $show_fname; # print and clear out before buffer and reset before counter &clear_buf(1) if $before > 0; $nbef = 0; &print_info(1); print $_; # print current line } elsif ($before > 0) { # pop off oldest line in before buffer & add current line shift(@line_buf) if $nbef >= $before; push(@line_buf,$_); $nbef++; } # end elseif before window is nonzero } # end else not in a match } # end while loop over lines in this file } # end foreach loop over list of files exit; # end of script proper Several of the print commands illustrate compound conditions in Perl. In this section of the script, the variable $nbef holds the number of the current line within the before window; by comparing it to $before, we can determine whether the buffer holding saved lines for the before window is full (there's no point in saving more lines than we need to print once a match is found). The array @line_buf holds these saved lines, and the push command (which we saw earlier as well) adds an element to the end of it. The immediately preceding shift(@line_buf) command shifts the elements of this array down, pushing off the oldest saved line, making room for the current line (stored in $_). Here is the subroutine print_info, which illustrates the basic structure of a Perl subroutine: sub print_info { print $_[0] ? "* " : " " if $show_stars; print $lnum," " if $show_nums; } Any arguments passed to a subroutine are accessible via the default array @_. This subroutine expects a zero or one as its argument, telling it whether the current line is a match or not and hence whether to print a star or all spaces at the beginning of the line when $show_stars is true. The subroutine's second statement prints line numbers if appropriate.[6]
Subroutine clear_buf is responsible for printing the before window and clearing the associated array, @line_buf: sub clear_buf { # argument says whether to print before window or not $print_flag = $_[0]; $i = 0; $j = 0; if ($print_flag) { # if we're printing line numbers, fiddle with the counter to # account for the before window if ($show_nums) { $target = $lnum - ($#line_buf + 1); } $lnum = "00000"; # yes, we're really counting back up to the right number # to keep correct number format -- cycles are cheap while ($i++ < $target) { ++$lnum; } } while ($j <= $#line_buf) { # print before window &print_info(0); print $line_buf[$j++]; $lnum++ if $show_nums; } # end while } # end if print_flag @line_buf = ( ); # clear line_buf array } # end of subroutine The final subroutine is usage. Its first line prints the error message passed to it as its single argument (if any), and the remaining lines print the standard usage message and then cause wgrep to terminate: sub usage { print STDERR $_[0],"\n" if $_[0]; print STDERR "Usage: wgrep [-n] ..." many more print commands exit; } 14.2.3 Perl ReportsBesides being a powerful programming language,Perl can also be used to generate attractive reports. Here is a fairly simple example: Disk Username (UID) Home Directory Space Security -------------------------------------------------------- lpd (104) / skipped sanders (464) /home/sanders 725980K stein (0) /chem/1/stein 4982K ** UID=0 swenson (508) /chem/1/Swenson deleted vega (515) /home/vega 100K ** CK PASS ... This report was produced using format specifiers, which state how records written with the write command are to look. Here are the ones used for this report: #!/usr/bin/perl -w # mon_users - monitor user accounts # header at the top of each page of the report format top = Disk Username (UID) Home Directory Space Security ----------------------------------------------------------- . # format for each line written to file handle STDOUT format STDOUT = @<<<<<<<<<<<<< @<<<<<<<<<<<<<<<<< @>>>>>> @<<<<<<<<< $uname, $home_dir $disk, $warn . The first format statement is the header printed at the top of each page, and the second format statement is used for the lines of the report. Format specifications are terminated with a single period on a line. The second format statement indicates that the variables $uname, $home_dir, $disk, and $warn will be written on each output line, in that order (the variables are defined elsewhere in the script). The line containing the strings of greater-than and less-than signs indicates the starting positions, lengths, and internal justification of the report's fields (text within a field is justified the way the angle bracket points). Here is the rest of the script used to produce the report: open (PASSWD, "/etc/passwd") || die "Can't open passwd: $!\n"; USER: while (<PASSWD>) { # loop over passwd file lines chop; # lists are enclosed in parentheses ($uname,$pass,$uid,$gid,$junk,$home_dir,$junk) = split(/:/); # remove newline, parse line, throw out uninteresting entries if ($uname eq "root" || $uname eq "nobody" || substr($uname,0,2) eq "uu" || ($uid <= 100 && $uid > 0)) { # Change UID cutoff if needed next USER; } # set flags on potential security problems $warn = ($uid == 0 && $uname ne "root") ? "** UID=0" : ""; $warn = ($pass ne "!" && $pass ne "*") ? "** CK PASS" : $warn; # .= means string concatenation $uname .= " ($uid)"; # add UID to username string # run du on home directory & extract total size from output if (-d $home_dir && $home_dir ne "/") { $du = `du -s -k $home_dir`; chop($du); ($disk,$junk) = split(/\t/,$du); $disk .= "K"; } else { $disk = $home_dir eq "/" ? "skipped" : "deleted"; } write; # write out formatted line } exit; This script introduces a couple of new Perl constructs which are explained in its comments. 14.2.4 Graphical Interfaces with PerlUsers greatly prefergraphical interfaces to traditional, text-based ones. Fortunately, it is very easy to produce them with Perl using the Tk module. Here is a simple script that illustrates the general method: #!/usr/bin/perl -w use Tk; # Use the Tk module. # Read message-of-the-day file. open MOTD, "/usr/local/admin/motd.txt" || exit; $first_line=1; while (<MOTD>) { if ($first_line) { # Extract the date from line 1. chop; ($date,@junk)=split( ); $first_line=0; } else { $text_block .= $_; } # Concatenate into $text_block. } my $main = new MainWindow; # Create a window. # Window title. $label=$main->Label(-text => "Message of the Day"); $label->pack; # Window's text area. $text=$main->Scrolled('Text', -relief => "sunken", -borderwidth => 2, -setgrid => "true"); $text->insert("1.0", "$text_block"); $text->pack(-side=>"top", -expand=>1, -fill=>"both"); # Window's status area (bottom). $status = $main->Label(-text=>"Last updated on $date", -relief=>"sunken", -borderwidth=>2, -anchor=>"w"); $status->pack(-side=>"top", -fill=>"x"); # Add a Close button. $button=$main->Button(-text => "Close Window", # exit when button is pushed: -command => sub{exit}); $button->pack; MainLoop; # Main event loop: wait for user input. The script has three main parts: processing the text file, creating and configuring the window, and the event loop. The first section reads the text file containing the message of the day, extracts the first field from the first line (assumed to hold the data the file was last modified), and concatenates the rest of its contents into the variable $text_block. The next section first creates a new window (via the new MainWindow function call) and then creates a label for it (assigning text to it), a text area in which text will be automatically filled, a button (labeled "Close Window"), and a status area (again, text is assigned to it). Each of these components is activated using the pack method (function). Finally, the third section, consisting only of the MainLoop command, displays the window and waits for user input. When the user presses the button, the routine specified to the button's command attribute is called; here, it is the Perl exit command, so the script exits when the button is pushed. Figure 14-1 illustrates the resulting window. Figure 14-1. Example Perl/Tk output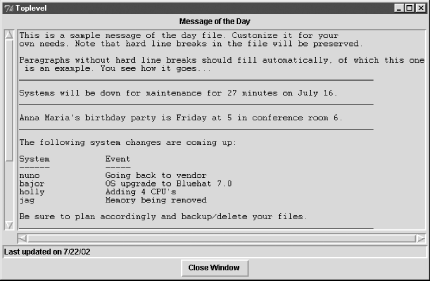 Note that the fill algorithm used for a simple text area is imperfect. More complex Perl/Tk programs, including ones accepting user input, are not fundamentally different from this one. |
EAN: 2147483647
Pages: 162