5.1 Understanding TCPIP Networking
5.1 Understanding TCP/IP NetworkingThe term "TCP/IP" is shorthand for a large collection of protocols and services that are used for internetworking computer systems. In any given implementation, TCP/IP encompasses operating system components, user and administrative commands and utilities, configuration files, and device drivers, as well as the kernel and library support upon which they all depend. Many of the basic TCP/IP networking concepts are not operating system-specific, so we'll begin this chapter by considering TCP/IP networking in a general way. Figure 5-1 depicts an example TCP/IP network including several kinds of network connections. Assuming that these computers are in reasonably close physical proximity to one another, this network would be classed as a local area network (LAN).[1] In contrast, a wide area network (WAN) consists of multiple LANs, often widely separated geographically (see Figure 5-5, later in this chapter). Different physical network types are also characteristic of the LAN/WAN distinction (e.g., Ethernet versus frame relay).
Each computer system on the network is known as a host[2] and is identified by both a name and an IP address (more on these later). Most of the hosts in this example have a permanent name and IP address. However, two of them, italy and chile, have their IP address dynamically assigned when they first connect to the network (typically, at boot time), using the DHCP facility (indicated by the highlighted final element in the IP address).
Figure 5-1. TCP/IP local area network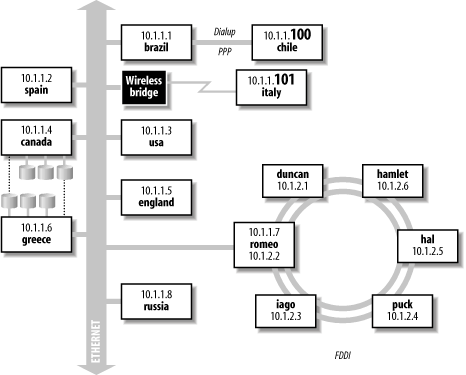 If I am logged in to, say, spain (either by direct connection or via a modem), spain is said to be the local system, and brazil is a remote system with respect to processes running on spain. A system that performs a task for a remote host is called a server; the host for whom the task is performed is called the client. Thus, if I request a file from brazil, that system is a server for the client spain during that transfer. In our example, the network is divided into two subnets that communicate via the host romeo. The systems named for countries are all connected to an Ethernet backbone, and those named for Shakespearean characters are connected via FDDI. The host romeo serves as a gateway between the two subnets. It is part of both subnets and passes data from one to the other. In this case, the gateway is a computer with two network interfaces (adapters). However, it is probably more common to use a special-purpose computer known as a router for this purpose. The host named italy connects to the network using a wireless connection. The wireless bridge (colored black in the illustration) accepts wireless connections and connects their originating computers to the hosts in the LAN by serving as the conduit to the Ethernet. Host chile connects to the network by dialing up a modem connected to brazil, using the PPP facility. Unlike a regular dialup session, which simply starts a normal login session on the server, dialup networking connections like this one allow full network participation by the dialing-in host, as if that computer were directly connected to the network. Once the initial connection is made, the fact that the connection actually goes through brazil will be transparent to users on chile. Finally, the illustration shows Unix disk sharing via the Network File System (NFS) facility. NFS allows TCP/IP hosts to share disks, with remote filesystems merged into the local directory tree. Users on canada and greece potentially have access to four disk drives, even though both systems only have three disks physically connected to them. 5.1.1 Media and TopologiesTCP/IP networks can run over a variety of physical media. Traditionally, most networks have used some sort ofcoaxial cable (thick or thin), twisted pair cable, orfiber optic cable. Network adapters provide the interface between a computer and the physical medium comprising the network connection. In hardware terms, they usually consist of a single board. Network adapters support one or more communication protocols, which specify how the computers use the physical medium to exchange data. Most protocols are not media-specific. For example,Ethernet communications can be carried over all four of the media types mentioned previously, and FDDI networks can run over either fiber optic or twisted pair cable. Such protocols specify networking characteristics, such as the structure of the lowest level data unit, the way that data moves from host to host across the physical medium, how multiple simultaneous network accesses are handled, and the like. Currently, Ethernet accounts for more than 80% of all networks. Figure 5-2 illustrates the various types of connectors you may see on Ethernet network cables. These days, the one at the bottom is the most prevalent: unshielded twisted pair (UTP) cable with an RJ-45 connector. The type of cable required for 100 Mb/sec communication is known as Category 5. Category 5E cable is used for 1000 Mb/sec (Gigabit) Ethernet. Figure 5-2. Ethernet connectors The other items in Figure 5-2 illustrate older cable types, which you may still run into. The top item is the most common connector for RG-11 coax. The middle two items are connectors used for RG-58 coax (Thinnet). The upper item in the pair is a simple connector. The lower item illustrates the tap design used for a computer connector. The connector is part of aT junction attached to the coaxial cable. In the illustration, there is aterminator on the right side of the tap, but a continuation of the cable could also be placed there. Table 5-1 summarizes some useful characteristics of the various Ethernet media. Note that the maximum cable length for UTP at any speed is 100 meters. Longer distances require fiber optic cable, of which there are two main varieties. Single-mode fiber equipment is technically more complex than multimode fiber because it uses a laser to force the light traveling within the cable to a single frequency ("mode"), making the optical system and the connectors much more expensive to produce. However, single-mode fiber also works reliably for cable lengths measured in kilometers instead of just meters.
All of the hosts within a given network segment a portion of the network separated from the rest by switches or routers use the same type of Ethernet. Connecting segments with different characteristics requires special hardware that can use both types and translate between them. 5.1.1.1 Identifying network adaptersAll network adapters have a Media Access Control (MAC) address , which is a numerical identifier that is globally unique to that individual adapter. For Ethernet devices, MAC addresses are 48-bit values expressed as twelve hexadecimal digits, usually divided into colon-separated pairs: for example, 00:00:f8:23:31:a1. There are thus over 280 trillion distinct MAC addresses (which ought to be enough, even for us). MAC addresses were formerly referred to as Ethernet addresses and are occasionally called hardware addresses. The first 24 bits of the MAC address is a hardware vendor-specific prefix called an Organizationally Unique Identifiier (OUI). Knowing the OUI can be helpful if you ever have to figure out which device corresponds to a specific MAC address. OUIs are assigned by the IEEE, which maintains the master database of OUI-to-vendor mappings. You can find the MAC address for an adapter on a Unix system using these commands:[4]
There is also a special network interface present on every computer, known as the loopback interface. There is no physical network adapter corresponding to the loopback interface, but even so, it is sometimes called the loopback device. The loopback interface allows a computer to send network packets to itself: implemented in software, it intercepts the packets and redirects them back to the local host, as if they had arrived from an external source. Hosts within a local area network can be connected in a variety of arrangements known as topologies. For example, the 10.1.1 subnet in Figure 5-1 uses a bus topology in which each host taps into a backbone, which is standard for coax Ethernet networks. Often, the backbone is not a cable at all but merely a junction point where connections from the various hosts on the network converge, commonly known as a hub or a switch, depending on its capabilities. The 10.1.2 subnet uses a ring topology. One of the fundamental characteristics ofEthernet is also illustrated in the diagram. Each host on an Ethernet is logically connected to every other host: to communicate with any other host, a system sends a message out on the Ethernet, where it arrives at the target host directly. By contrast, for the other network, messages between duncan and puck must be handled by two other hosts first. At typical network speeds, however, this difference is not significant. Networking protocols may include a required topology as part of their specification, as in the 10.1.2 subnet in Figure 5-1. For example, full FDDI networks are composed of two counter-rotating rings (two duplicate rings through which data flows in opposite directions), an arrangement designed to enable a network to easily bypass breaks in one ring and to scale well as network load increases.
The Ethernet protocol is based on a communication strategy known asCarrier Sense Multiple Access/Collision Detection (CSMA/CD). On an Ethernet, a device that wants to transmit a message is able to determine if any other device is already using the medium (carrier sense). In other words, a device waits until there is a lull in activity before trying to "talk." If two or more devices both start to talk at the same time, both of them stop (collision detection), and they each wait a semi-random amount of time before trying again in the hopes of avoiding a second collision. "Multiple access" refers to the fact that any host is able to use the communication medium. This is a lightweight protocol that works very well for most common networking uses. Its one disadvantage is that it does not perform as well under heavy loads as do some other topologies (e.g., token rings). In fact, under heavy network loads, the overhead caused by frequent collisions and the resulting wait times can become a significant factor in actual network throughput (although this is less true of current UTP-based 100 Mb networks than it is of older, coax-based 10 Mb networks). 5.1.2 Protocols and LayersNetwork communication is organized as a series oflayers. With the exception of the layer referring to the physical transmission medium, these layers are logical or conceptual rather than literal or physical, and they are implemented in the networking software running on computers and other network devices. Every network message moves down through the layers on its originating system, travels across the physical medium, and then moves up through the same stack of layers on the destination system. In addition, as it passes through various network devices, it may travel partway up and down the stack (as we'll see). No discussion of any network architecture is complete without at least a brief mention of the Open Systems Interconnection (OSI) Reference Model. This description of networking has seldom been the basis of actual network implementations, but it can be quite helpful in clearly identifying the distinct functions necessary for network communications to occur. Things are not really divided up according to its specification in real networks, because many of the distinct communication phases and functions that it identifies are handled equally well or more efficiently by a single network layer (with correspondingly lower overhead). The OSI Reference Model is probably best thought of as an after-the-fact, generalized, logical description of network communications. Figure 5-3 lists the layers in the OSI Reference Model and those actually used in TCP/IP implementations, including the most important protocols defined for each layer. Figure 5-3. Idealized and real network protocol stacks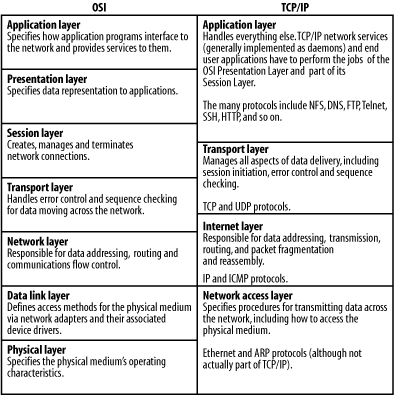 When a network operation is initiated by a user command or program, it travels down theprotocol stack on the local host (via software), across the physical medium to the destination host, and then back up the protocol stack on the remote host to the proper recipient process. For example, a network transmission originating from a user program like rcp moves down the stack on the local system from the Application layer to Network Access layer, travels across the wire to the destination system, and then moves up the stack from the Network Access layer to the Application layer, finally communicating with a daemon process in the latter. Replies to this message travel the same route in reverse. Each network layer is equipped to handle data in particular predefined units. The traditional names of these units for the two main transport protocols are listed in Table 5-2.
The term packet is also used generically to refer to any network transmission (including in this book). On the originating end, each layer adds a header to the data it receives from the layer above it until the data reaches the bottom layer for transmission; this process is called encapsulation. Similarly, on the receiving end, each layer strips off its own header before passing the data to the next higher layer (combining multiple units together if appropriate), so that what is finally received is the same as what was originally sent. In addition, network data may in some cases be divided into parts that are transmitted separately, a process known as fragmentation. For example, different network hardware and media types have somewhat different characteristics that can give rise to different values of the maximum transmission unit (MTU) network parameter: the largest data unit that can be transmitted across a network segment. As it travels, if a packet encounters a network segment that has a lower MTU than the one in use where it originated, it is fragmented for transmission and reassembled at the other end. A typical MTU for an Ethernet segment is 1500 bytes. A more typical example occurs when a higher-level protocol passes more data than will fit into a lower-level protocol packet. The data in a UDP packet can easily be larger than the largest IP datagram, so the data would need to be divided into multiple datagrams for transmission. These are some of the most important lower-level protocols in the TCP/IP family:
We'll consider other protocols when we look at network services in Chapter 8. 5.1.3 Ports, Services, and DaemonsNetwork operations are performed by a variety ofnetwork services, consisting of the software and other facilities needed to perform a specific type of network task. For example, the ftp service performs file transfer operations using the FTP protocol; the software program that does the actual work is the FTP daemon (whose actual name varies). A service is defined by the combination of a transport protocol TCP or UDP and a port: a logical network connection endpoint identified by a number. The TCP and UDP port numbering schemes are part of the definition of these protocols.
Various configuration files in the /etc directory indicate the standard mappings between port numbers and TCP/IP services:
Individual TCP/IP connections are defined by a pair of host-port combinations, each known as a socket, which is unique during the connection's lifetime: source IP address, source port, destination IP address, destination port (as seen from the client's point of view). For example, when a user first connects to a remote host using ssh, it contacts that computer on the standard port 22 (such ports are commonly referred to as well-known ports). The process is assigned a random (dynamically allocated or ephemeral) port which is used as the source (outgoing) port by the client. Multiple simultaneous ssh sessions on the destination system are possible using this scheme since each one will have a different source port/source IP address combination and thus a unique socket. For example, the first ssh connection might use port 2222 as the source port. The next ssh connection might use port 3333. In this way, the messages intended for the two sessions can be easily distinguished, even if they came from the same user on the same remote system. Most standard services usually use ports below 1024, and such ports are restricted to root (at least on Unix systems). Table 5-3 lists some common services and their associated ports. In most cases, both the TCP and UDP ports are assigned to the service; for the few exceptions, the protocol follows the port number (as in /etc/services entries). The shaded portion of the table contains port numbers for commonly used services from non-Unix operating systems.
5.1.4 Administrative CommandsUnix operating systems include a number of generic TCP/IP user commands that may be used to display various network-related information, including the following:
We'll see examples of many of these commands later in this chapter. 5.1.5 A Sample TCP/IP ConversationAll of these concepts will come together when we look at a sampleTCP/IP conversation. We'll consider what must happen in order for the following command to be successfully executed: hamlet> finger chavez@greece Login name: chavez In real life: Rachel Chavez Directory: /home/chem/new/chavez Shell: /bin/csh On since Apr 28 08:35:42 on pts/3 from puck No Plan. This finger command causes a network connection to be formed between the hosts hamlet and greece, and more specifically between the finger client process running on hamlet and the fingerd daemon on greece (which will be started by greece's inetd process). The finger service uses the TCP transport protocol (number 6) and port 79. TCP connections are always created via a three-step handshaking process. Here is a dump of the packet corresponding to Step 1, in which the most important fields have been highlighted:[6]
ETH: ====( 60 bytes recd on en0 )====Sun Apr 28 13:38:27 1996 ETH: [ 32:21:a6:e1:7f:c1 18:33:e4:2a:43:2d ] type 800 (IP) IP: < SRC = 192.168.2.6 (hamlet) IP: < DST = 192.168.1.6 (greece) IP: ip_v=4, ip_hl=20, ip_tos=0, ip_len=44, ip_id=56107, ip_off=0 IP: ip_ttl=60, ip_sum=f84, ip_p = 6 (TCP) TCP: <source port=1031, destination port=79(finger)> TCP: th_seq=d83ab201, th_ack=0 TCP: th_off=6, flags<SYN> TCP: th_win=16384, th_sum=3577, th_urp=0 data in ASCII data: 00000000 020405b4 |.... | Each line of this packet display is labeled with the protocol that created it: ETH lines were created at the Ethernet level (Network Access layer), IP lines by the IP protocol (Internet layer), and TCP lines by the TCP protocol (Transport layer). Lines labeled as data are used by whatever layer is sending data in the packet. The data is dumped in hex and ASCII (the latter at the extreme right between the two vertical bars). In this case, the data consists of TCP options (negotiating a maximum segment length of 1460 bytes) and not finger-related data. The initial ETH line is actually created by the packet dumping software, and it lists the date and time of the message. The actual data from the packet begins with the second ETH line, which lists the MAC addresses of the two hosts. The IP lines indicate that the packet comes from the TCP transport protocol (ip_p), as well as its source and destination hosts. The TCP header indicates the destination port, allowing the network service to be identified. The th_seq field in this header indicates the sequence number for this packet. The TCP protocol requires that all packets be acknowledged by the receiving host (although not necessarily individually). The SYN flag (for synchronize) by itself indicates an attempt to create a new network connection, and in this case, the sequence number is an initial sequence number for the conversation. It will be incremented by one for each byte of data transmitted. Here are the next two packets in the sequence, which complete the handshake: ETH: ====( 60 bytes trans on en0 )====Sun Apr 28 13:38:27 1996 ETH: [ 18:33:e4:2a:43:2d -> 32:21:a6:e1:7f:c1 ] type 800 (IP) IP: < SRC = 192.168.1.6 > (greece) IP: < DST = 192.168.2.6 > (hamlet) IP: ip_v=4, ip_hl=20, ip_tos=0, ip_len=44, ip_id=54298, ip_off=0 IP: ip_ttl=60, ip_sum=1695, ip_p = 6 (TCP) TCP: <source port=79(finger), destination port=1031 > TCP: th_seq=d71b9601, th_ack=d83ab202 TCP: th_off=6, flags<SYN | ACK> TCP: th_win=16060, th_sum=c98c, th_urp=0 data: 00000000 020405b4 |.... | ETH: ====( 60 bytes recd on en0 )====Sun Apr 28 13:38:27 1996 ETH: [ 32:21:a6:e1:7f:c1 -> 18:33:e4:2a:43:2d ] type 800 (IP) IP: < SRC = 192.168.2.6 > (hamlet) IP: < DST = 192.168.1.6 > (greece) IP: ip_v=4, ip_hl=20, ip_tos=0, ip_len=40, ip_id=56108, ip_off=0 IP: ip_ttl=60, ip_sum=f87, ip_p = 6 (TCP) TCP: <source port=1031, destination port=79(finger) > TCP: th_seq=d83ab202, th_ack=d71b9602 TCP: th_off=5, flags<ACK> TCP: th_win=16060, th_sum=e149, th_urp=0 In the packet with sequence number d71b9601, sent from greece back to hamlet, both the SYN and ACK (acknowledge) flags are set. The ACK is the acknowledgement of the previous packet, and the SYN establishes communication from greece to hamlet. The contents of the th_ack field indicate the last byte of data that has been received (one byte so far). The th_seq field indicates greece's starting sequence number. The next packet simply acknowledges greece's SYN, and the connection is complete. Now we are ready to get some work done (packets are abbreviated from here on): IP: < SRC = 192.168.2.6 > (hamlet) IP: < DST = 192.168.1.6 > (greece) TCP: <source port=1031, destination port=79(finger) > TCP: th_seq=d83ab202, th_ack=d71b9602 TCP: th_off=5, flags<PUSH | ACK> TCP: th_win=16060, th_sum=4c86, th_urp=0 data: 00000000 61656C65 656E3A29 |chavez | This packet sends the data "chavez" to fingerd on greece (the final characters don't print); user data is indicated by the presence of the PUSH flag. In this case, the data is from the Application layer. The packet also acknowledges the previous packet from greece. This data is passed up the various network layers, to be delivered ultimately to fingerd. greece acknowledges this packet and eventually sends fingerd's response: IP: < SRC = 192.168.1.6 > (greece) IP: < DST = 192.168.2.6 > (hamlet) TCP: <source port=79(finger), destination port=1031 > TCP: th_seq=d71b9602, th_ack=d83ab20c TCP: th_off=5, flags<PUSH | ACK> TCP: th_win=16060, th_sum=e29b, th_urp=0 data: |Login name: chavez ..In real life: Rachel Chavez..Director| data: |y: /home/chem/new/chavez ..Shell:/bin/csh. On since Apr 28| data: | 08:35:42 on pts/3 from puck..No Plan... | The output from the finger command constitutes the data in this packet (the hex version is omitted). The packet also acknowledges data received from hamlet (10 bytes since the previous packet). All that remains is to close down the connection: IP: < SRC = 192.168.1.6 > (greece) IP: < DST = 192.168.2.6 > (hamlet) TCP: th_off=5, flags<FIN | ACK> IP: < SRC = 192.168.2.6 > (hamlet) IP: < DST = 192.168.1.6 > (greece) TCP: th_off=5, flags<FIN | ACK> IP: < SRC = 192.168.1.6 > (greece) IP: < DST = 192.168.2.6 > (hamlet) TCP: th_off=5, flags<ACK> The FIN flag indicates that a connection is to be terminated. greece indicates that it is finished first. hamlet sends its own FIN (also acknowledging that packet), which greece acknowledges. 5.1.6 Names and AddressesEvery system on a network has a hostname. When fully qualified, this name must be unique within the relevant naming space. Hostnames let users refer to any computer on the network by using a short, easily remembered name rather than the host's network address. Each system on a TCP/IP network also has an IP address that is unique for all hosts on the network. Systems with multiple network adapters usually have a separate IP address for each adapter. When an actual network operation occurs, the hostnames of the systems involved are used to determine their numerical IP addresses, either by looking them up in a table or requesting translation from a server designated for this task. A traditional Internet network address is a sequence of 4 bytes[7] (32 bits). Network addresses are usually written in the form a.b.c.d, where a, b, c, and d are all decimal integers: e.g. 192.168.10.23. Each component is 8 bits long and thus runs from 0 to 255. The address is split into two parts: the first part highest-order bits identifies the local network, specifically those hosts that may be connected directly (without the need for any routing information. The second part of the IP address (i.e., all remaining bits) identifies the host within the network.
The size of the two parts vary. The first byte of the address (a) determines the address type (called its class), and hence the number of bytes allocated to each part. Table 5-4 gives more specific details about how this scheme traditionally works.
Class A addresses provide millions of hosts per network, since 24 bits can be used for host addresses: 1 through 224-1 (0 is not allowed as a host address). There are, however, only a total of 126 of them (these network numbers were typically assigned to major national networks and very large organizations). At the other extreme, Class C addresses traditionally support only 254 hosts per network (since only 8 bits are used for the host address), but there are over two million of them. Class B addresses fall in between these two types. Multicast addresses are part of the reserved range of addresses (a=224-254). They are used to address a group of hosts as a single entity and are designed for applications such as video conferencing. They are assigned on a temporary basis. Normal IP addresses are sometimes referred to as unicast addresses in contrast to multicast addresses. Some values of the various network address bytes have special meanings:
Network addresses for networks connected to the Internet must be obtained from some official source. These days, network addresses for new sites are obtained from one of the ISPs that is authorized to assign them. Every host that will communicate directly with a host on the Internet must have an officially assigned IP address. Networks that are not directly connected to the Internet also use network addresses that obey the Internet numbering conventions. The following IP address blocks are reserved for private networks:[8]
Sites that connect to the Internet via an ISP or other dedicated gateway frequently use Network Address Translation (NAT) to map internal IP addresses to their external ("real") IP address space. NAT can be performed by a computer and many routers. It is often used to map a large number of private addresses to a small number of real IP addresses, often just one. NAT processes all Internet-bound packets, transforming their original source addresses into the address appropriate for use on the Internet. This may be done to translate private addresses to the organization's actual assigned IP address space or to conflate/hide the internal network structure from the outside world. It also keeps track of this mapping data so that it can perform the reverse translation process for incoming packets (responses).
5.1.7 Subnets and SupernetsA site can divide its block of addresses also known as its address space in any way that makes sense. For example, consider the block of addresses that begin with 192.168. Traditionally, this is a Class C address and so would be interpreted as 256 networks of 254 hosts each: the networks are 192.168.0.0, 192.168.1.0, 192.168.2.0, ..., 192.168.255.0, and the hosts are numbered 1 through 254 for each network. However, this is not the only way of dividing the 16 site-specific bits. In this case, the theoretical possibilities range from one network with over two million hosts (all 16 bits are used for the host part) to 16,384 networks of 2 hosts each (only the lowest two bits are used for the host part, and the remaining 14 bits are used for the subnet). NOTE The number of hosts per subnet is always 2n-2 where n is the number of bits in the host part of the IP address. Why -2? We must exclude the invalid host addresses consisting of all zeros and all ones. A subnet mask specifies how the 32-bit IP address is divided between the network part (including the subnet) and the host part, and all computers participating in a TCP/IP network have one assigned to them. Computers and other devices on the same subnet always use the same subnet mask. The subnet mask is a 32-bit value constructed by placing 1 in each bit location for the network portion of the IP address and 0 in all the bit locations for the host part of the address. This results in a string of ones followed by a string of zeros. For example, a traditional Class A IP address would use a subnet mask of 11111111000000000000000000000000, conventionally written as 4 period-separated decimal integers: 255.0.0.0. Similarly, traditional Class B and Class C addresses would use a subnet mask of 255.255.0.0 and 255.255.255.0, respectively. The subnet mask can also be used to further subdivide one network ID among several local networks. For example, if you use a subnet mask of 255.255.255.192 for the network 192.168.10.0, you are making the highest 2 bits of the final address byte part of the network address (the final byte is 11000000), thereby subdividing the 192.168.10 network into 4 subnets, each of which can have up to 62 hosts on it (since the host ID is coded into the remaining 6 bits). Contrast this with the normal interpretation, which yields 256 networks of 254 hosts each.
You can also use fewer than the standard number of bits for the network part of the address (this strategy is known as supernetting). For example, for the network address 192.168.0.0, you could use only 4 bits for the subnet part rather than the usual 8, yielding 16 subnets of up to 1022 hosts each. NOTE Memorizing all the powers of 2 from 20 to 216 makes all of this much easier. Classless Inter-Domain Routing (CIDR, usually pronounced like apple cider) addressing is the more common way of expressing the subnet mask these days.[9] CIDR appends a suffix indicating the number of bits in the host part to the IP address. For example, 192.168.10.212/24 designates a subnet mask of 255.255.255.0, and the /27 suffix specifies a subnet mask of 255.255.255.224.
Table 5-5 shows how this works in detail. In the first example, we divide the 192.168.10 network into 8 subnets of 30 hosts each. In the second example, we organize a block of 256 traditional Class C addresses into 64 subnets of 1022 hosts each with supernetting by assigning the upper 6 bits of the third IP address byte to the network address, thereby leaving 10 bits for the host part.
Note that some of the host addresses in the second part of Table 5-5 have 255 as their last byte. These are legal host addresses with the specified subnet mask since the entire host part is not all ones (write one of these addresses, say 192.168.0.255/22, out in binary if you're not sure). With CIDR addresses, there is nothing special about the byte boundaries, and classes really are irrelevant. Table 5-6 lists commonly used CIDR suffixes and their associated subnet masks.
If you'd rather avoid the math, there are tools that can help with these calculations. Figure 5-4 illustrates the output from a Perl script named ipcalc.pl (this one is from http://jodies.de/ipcalc/, written by krischan@jodies.de; there are several versions of the script by different authors[12]). It takes a CIDR address as its input and prints a variety of useful information about the local network that can be derived from it. The Wildcard field displays the inverted netmask (used by Cisco).
Figure 5-4. Output from the ipcalc.pl Script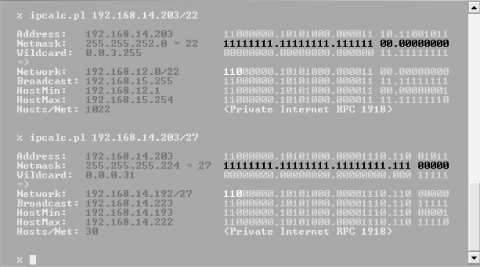 5.1.7.1 Introducing IPv6 host addressesAt some point in the future, Internet addresses may switch over to the next-generation design, IPv6 (the current one is IPv4). IPv6 was designed in the 1990s to address the perceived future shortage of Internet addresses (which fortunately has not yet arrived). In this brief subsection, we'll take a look at the major features of IPv6 addresses. All the vendors we are considering support IPv6 addresses. IPv6 addresses are 128 bits long, expressed as a series of 8 colon-separated 16-bit values written in hexadecimal, e.g., 1111:2222:3333:4444:5555:6666:7777:8888. Each value runs from 0x0 to 0xFFFF (from 0 to 65535 in decimal). The network host boundary is fixed at 64 bits, and there is some additional internal structure defined, described in Table 5-7.
As the table indicates, sites get 16 bits for subnetting. The entire initial prefix of 48 bits is provided by the ISP. One advantage of IPv6 is that host addresses may be automatically derived from the device's MAC address, so that aspect of host configuration can be eliminated (optionally). IPv6 allows for backward compatibility with IPv4 by assigning addresses of the form 0:0:0:FFFF:a.b.c.d to IPv4-only devices, where a.b.c.d is the IPv4 address. This is generally written as ::FFFF:a.b.c.d, where :: replaces a contiguous block of zeros (any length) in the IPv6 address (but the double colon may be used only once). Finally, the loopback address is always defined as ::1, and the broadcast address is FF02::1. 5.1.8 Connecting Network SegmentsAt the physical level, individual networks can be organized, subdivided and joined in a variety of ways, as illustrated in Figure 5-5 (constructed to include many different connectivity examples and not as a general model for network design). Figure 5-5. A wide area network and its component LANs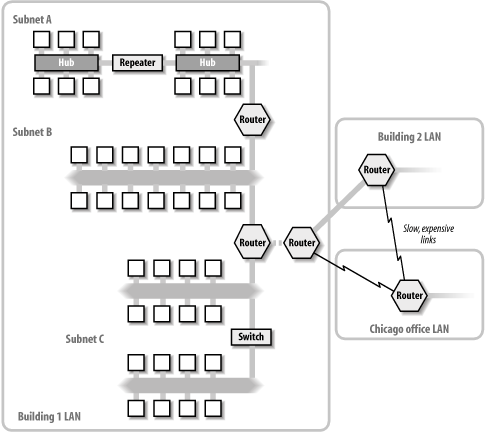 The Chicago office LAN in the figure is geographically separated from the organization's main site in San Francisco the Building 1 and Building 2 LANs and it is connected to it via relatively slow links. The two LANs at the main site are connected via high-speed fiber optic cable, so that site's entire network runs at the same speed, despite the separation of the two buildings. Collectively, these three LANs comprise the WAN for this organization. The Building 1 LAN illustrates several hardware networking devices. All the hosts in Subnet A are connected to devices called hubs. Traditional hubs serve as an Ethernet backbone, linking all of the connected hosts together. In this case, there are two hubs in this network segment, as well as a repeater. The latter device connects hosts that are farther apart than the maximum cable length, passing all signals from one wire to the other. Actually, a repeater is also a hub; in this case, it has only two ports. Ethernet imposes a maximum number of four hubs between the most distant hosts. Subnet A follows this rule. Subnet B is another network segment, connected to the other two subnets by routers. Although its internal structure is not shown, the various hosts in this subnet are all connected to hubs or switches. The same is true for the two parts of subnet C. The two branches of subnet C are connected by a switch, a somewhat more intelligent device than a hub, which selectively passes only the data destined for the other segment between the two. A hub is just a point where connections come together, while a switch includes some ability to decide which "side" a given packet is destined for. Two-port switches like the one in the figure are sometimes called bridges.
More complex switches can handle more than one media type or have the ability to filter the traffic in a variety of ways, and some are capable of connecting networks of different types say, TCP/IP and SNA by translating or encapsulating the data from one protocol family to/within the other as it is passed across. These tasks, performed by such devices, overlap those traditionally assigned to routers. The various subnets and the three local LANs in Figure 5-5 are connected to one another via routers, a still more sophisticated network linking device that is essentially a small computer. In addition to selectively handling data based on its destination, routers also have the ability to determine the current best path to that destination; finding a path to a destination is known as routing.[13] The best routers are highly programmable and can also perform very complex filtering of the data they receive, accepting or rejecting it based upon criteria specified by the network administrator.
The routers that connect our three locations are arranged so that there are multiple paths to every destination; losing any one of them will cause no harm to communications between the two unaffected networks. Hubs/repeaters, switches/bridges, and routers can be distinguished by where their operations fall within the TCP/IP protocol stack. Repeaters operate at the Network Access layer, bridges use the Internet layer,[14] and routers operate within the Transport layer. A full network host, which obviously supports all four TCP/IP layers, can thus perform the functions of any of these types of devices. Note that many devices labeled with one name may actually function like lower-end versions of the next higher device (e.g., high end switches are simple routers).
NOTE Although inexpensive dual-speed (e.g., 10BaseT and 100BaseT)switches exist, I don't recommend using them. The network will provide better performance if you segregate devices by speed and don't mix speeds on the same (low-end) switch.[15] The low-speed switch will thus be the only low-speed device on the high speed switch.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


EAN: 2147483647
Pages: 162