9.1. .NET's Regex Flavor .NET has been built with a Traditional NFA regex engine, so all the important NFA related lessons from Chapter 4, 5, and 6 are applicable . Table 9-1 on the facing page summarizes .NET's regex flavor, most of which is discussed in Chapter 3. Certain aspects of the flavor can be modified by match modes (˜110), turned on via option flags to the various functions and constructors that accept regular expressions, or in some cases, turned on and off within the regex itself via 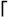 (? mods-mods ) (? mods-mods )  and (? mods-mods :‹ ) constructs. The modes are listed in Table 9-2 on page 408. and (? mods-mods :‹ ) constructs. The modes are listed in Table 9-2 on page 408. In the table, "raw" escapes like \w are shown. These can be used directly in VB.NET string literals ("\w) , and in C # verbatim strings (@"\w") . In languages without regex-friendly string literals, such as C++, each backslash in the regex requires two in the string literal ( "\\w" ) . See "Strings as Regular Expressions"(˜101). The following additional notes augment Table 9-1: -
\b is a character shorthand for backspace only within a character class. Outside of a character class, \b matches a word boundary (˜133). \x ## allows exactly two hexadecimal digits, e.g., \xFC ber matches ' ¼ ber '. \u #### allows exactly four hexadecimal digits, e.g., \u00FC ber matches ' ¼ ber ', and \u20AC matches '‚'. -
As of Version 2.0, .NET Framework character classes support class subtraction , such as [ a-z-[aeiou] ] for non-vowel lowercase ASCII letters (˜125). Within a class, a hyphen followed by a class-like construct subtracts the characters specified by the latter from those specified before the hyphen. -
‚ \w , \d , and \s (and their uppercase counterparts) normally match the full range of appropriate Unicode characters, but change to an ASCII-only mode with the RegexOptions.ECMAScript option (˜412). In its default mode, \w matches the Unicode properties \p{Ll}, \p{Lu},\p{Lt}, \p{Lo}, \p{Nd} and \p{Pc} . Note that this does not include the \p{Lm} property. (See the table on page 123 for the property list.) In its default mode, \s matches [ \f\n\r\t\v\x85\p{Z}] . U+0085 is the Unicode NEXT LINE control character, and \p{Z} matches Unicode "separator" characters (˜122). Table 9-1. Overview of .NET's Regular-Expression Flavor | Character Shorthands | | ˜115 (c) | \a [\b] \e \f \n \r \t \v octal \x ## \u #### \c char | | Character Classes and Class-Like Constructs | | ˜118 | Classes: [ ‹ ] [ ^‹ ] | | ˜119 | Any character except newline: dot (sometimes any character at all) | | ˜120 (c) | Class shorthands: ‚ \w \d \s \W \D \S | | ˜121 (c) | Unicode properties and blocks:ƒ \p{ Prop } \P{ Prop } | | Anchors and Other Zero-Width Tests | | ˜129 | Start of line/string: ^ \A | | ˜129 | End of line/string: $ \z \Z | | ˜130 | End of previous match: \G | | ˜133 | Word boundary: \b \B | | ˜133 | Lookaround: (?= ‹) (?! ‹) (?< =‹) (?< !‹) | | Comments and Mode Modifiers | | ˜135 | Mode modifiers: (? mods-mods ) Modifiers allowed: x s m i n (˜408) | | ˜135 | Mode-modified spans : (? mods-mods : ‹ ) | | ˜136 | Comments: (?# ‹ ) | | Grouping, Capturing, Conditional, and Control | | ˜137 | Capturing parentheses: ( ‹ )\1 \2 ... | | ˜436 | Balanced Grouping (? < name- name >‹ ) | | ˜409 | Named capture, backreference: (?< name > ‹ ) \k < name > | | ˜137 | Grouping-only parentheses: (?: ‹ ) | | ˜139 | Atomic grouping: (? >‹ ) | | ˜139 | Alternation: | | ˜141 | Greedy quantifiers: * + ? {n} {n,} {x,y} | | ˜141 | Lazy quantifiers: *? +? ?? {n}? {n,}? {x,y}? | | ˜409 | Conditional: (? if then else ) "if" can be lookaround, ( num ) , or ( name ) | | (c) may also be used within a character class ‹ see text |
-
ƒ \p{‹} and \P{‹} support standard Unicode properties and blocks, as of Unicode version 4.0.1. Unicode scripts are not supported. Block names require the 'Is' prefix (see the table on page 125), and only the raw form unadorned with spaces and underscores may be used. For example, \p{Is_Greek_Extended} and \p{Is Greek Extended} are not allowed; \p{IsGreekExtended} is required. Only the short property names like \p{Lu} are supported long names like \p{Lowercase_Letter} are not supported. Single-letter properties do require the braces (that is, the \pL shorthand for \p{L} is not supported). See the tables on pages 122 and 123. The special composite property \p{L&} is not supported, nor are the special properties \p{All}, \p{Assigned} , and \p{Unassigned} . Instead, you might use (?s:.) , \P{Cn} , and \p{Cn} , respectively. -
\G matches the end of the previous match, despite the documentation's claim that it matches at the beginning of the current match (˜130). -
Both lookahead and lookbehind can employ arbitrary regular expressions. As of this writing, the .NET regex engine is the only one that I know of that allows lookbehind with a subexpression that can match an arbitrary amount of text (˜133). -
The RegexOptions.ExplicitCapture option (also available via the (?n) mode modifier) turns off capturing for raw (‹) parentheses. Explicitly named captures like (?<num> \d+ ) still work (˜138). If you use named captures, this option allows you to use the visually more pleasing (‹) for grouping instead of (?:‹) . Table 9-2. The .NET Match and Regex Modes | RegexOptions option | (? mode ) | Description | | .Singleline | s | Causes dot to match any character (˜111). | | .Multiline | m | Expands where ^ and $ can match (˜111) | | .IgnorePatternWhitespace | x | Sets free-spacing and comment mode (˜72). | | .IgnoreCase | i | Turns on case-insensitive matching. | | .ExplicitCapture | n | Turns capturing off for (‹) , so only (?< name >‹) capture. | | .ECMAScript | | Restricts \w , \s , and \d to match ASCII characters only, and more (˜412). | | .RightToLeft | | The transmission applies the regex normally, but in the opposite direction (starting at the end of the string and moving toward the start). Unfortunately, buggy (˜411). | | .Compiled | | Spends extra time up front optimizing the regex so it matches more quickly when applied (˜410). |
9.1.1. Additional Comments on the Flavor A few issues merit longer discussion than a bullet point allows. 9.1.1.1. Named capture .NET supports named capture (˜138), through the (?< name >‹) or (?' name '‹) syntax. Both syntaxes mean the same thing and you can use either freely , but I prefer the syntax with <‹> , as I believe it will be more widely used. You can backreference the text matched by a named capture within the regex with \k< name > or \k 'name' . After the match (once a Match object has been generated; an overview of .NET's object model follows , starting on page 416), the text matched within the named capture is available via the Match object's Groups ( name ) property. (C # requires Groups [ name ] instead.) Within a replacement string (˜424), the results of named capture are available via a $ { name } sequence. In order to allow all groups to be accessed numerically , which may be useful at times, named-capture groups are also given numbers. They receive their numbers after all the non-named ones receive theirs: 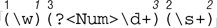 The text matched by the \d+ part of this example is available via both Groups("Num) and Groups(3) . It's still just one group , but with two names. 9.1.1.1.1. An unfortunate consequence It's not recommended to mix normal capturing parentheses and named captures, but if you do, the way the capturing groups are assigned numbers has important consequences that you should be aware of. The ordering becomes important when capturing parentheses are used with Split (˜425), and for the meaning of '$+' in a replacement string (˜424). 9.1.1.2. Conditional tests The if part of an (? if then else ) conditional (˜140) can be any type of lookaround, or a captured group number or captured group name in parentheses. Plain text (or a plain regex) in this location is automatically treated as positive lookahead (that it, it has an implicit (?=‹) wrapped around it). This can lead to an ambiguity: for instance, the (Num) of ‹(?(Num) then else )‹ is turned into (?=Num) (lookahead for 'Num ) if there is no (?<Num>‹) named capture elsewhere in the regex. If there is such a named capture, whether it was successful is the result of the if . I recommend not relying on "auto-lookaheadication." Use the explicit (?=‹) to make your intentions clearer to the human reader, and also to avert a surprise if some future version of the regex engine adds additional if syntax. 9.1.1.3. "Compiled" expressions In earlier chapters, I use the word "compile" to describe the pre-application work any regex system must do to check that a regular expression is valid, and to convert it to an internal form suitable for its actual application to text. For this, .NET regex terminology uses the word "parsing." It uses two versions of "compile" to refer to optimizations of that parsing phase. Here are the details, in order of increasing optimization: -
Parsing The first time a regex is seen during the run of a program, it must be checked and converted into an internal form suitable for actual application by the regex engine. This process is referred to as "compile" elsewhere in this book (˜241). -
On-the-Fly Compilation RegexOptions.Compiled is one of the options available when building a regex. Using it tells the regex engine to go further than simply converting to the default internal form, but to compile it to low-level MSIL (Microsoft Intermediate Language) code, which itself is then amenable to being optimized even further into even faster native machine code by the JIT ("Just-In-Time" compiler) when the regex is actually applied. It takes more time and memory to do this, but it allows the resulting regular expression to work faster. These tradeoffs are discussed later in this section. -
Pre-Compiled Regexes A Regex object (or objects) can be encapsulated into an assembly written to disk in a DLL (a Dynamically Loaded Library, i.e., a shared library). This makes it available for general use in other programs. This is called "compiling the assembly." For more, see "Regex Assemblies" (˜434). When considering on-the-fly compilation with RegexOptions.Compiled , there are important tradeoffs among initial startup time, ongoing memory usage, and regex match speed: | Metric | Without RegexOptions.Compiled | With RegexOptions.Compiled | | Startup time | Faster | Slower (by 60x) | | Memory usage | Low | High (about 515k each) | | Match speed | Not as fast | Up to 10x faster |
The initial regex parsing (the default kind, without RegexOptions.Compiled ) that must be done the first time each regex is seen in the program is relatively fast. Even on my clunky old 550MHz NT box, I benchmark about 1,500 complex compilations/ second. When RegexOptions.Compiled is used, that goes down to about 25/second, and increases memory usage by about 10k bytes per regex. More importantly, that memory remains used for the life of the programthere's no way to unload it. It definitely makes sense to use RegexOptions.Compiled in time-sensitive areas where processing speed is important, particularly for expressions that work with a lot of text. On the other hand, it makes little sense to use it on simple regexes that aren't applied to a lot of text. It's less clear which is best for the multitude of situations in betweenyou'll just have to weight the benefits and decide on a case-by-case basis. In some cases, it may make sense to encapsulate an application's compiled expressions into its own DLL, as pre-compiled Regex objects. This uses less memory in the final program (the loading of the whole regex compilation package is bypassed), and allows faster loading (since they're compiled when the DLL is built, you don't have to wait for them to be compiled when you use them). A nice byproduct of this is that the expressions are made available to other programs that might wish to use them, so it's a great way to make a personal regex library. See "Creating Your Own Regex Library With an Assembly" on page 435. 9.1.1.4. Right-to-left matching The concept of " backwards " matching (matching from right to left in a string, rather than from left to right) has long intrigued regex developers. Perhaps the biggest issue facing the developer is to define exactly what "right-to-left matching" really means. Is the regex somehow reversed ? Is the target text flipped ? Or is it just that the regex is applied normally from each position within the target string, with the difference being that the transmission starts at the end of the string instead of at the beginning, and moves backwards with each bump-along rather than forward? Just to think about it in concrete terms for a moment, consider applying \d+ to the string '123 and 456 . We know a normal application matches '123' , and instinct somehow tells us that a right-to-left application should match '456' . However, if the regex engine uses the semantics described at the end of the previous paragraph, where the only difference is the starting point of the transmission and the direction of the bump-along, the results may be surprising. In these semantics, the regex engine works normally ("looking" to the right from where it's started), so the first attempt of \d+ , at '‹45  6, doesn't match. The second attempt, at '‹45 6 does match, as the bump-along has placed it "looking at" the '6' , which certainly matches \d+ . So, we have a final match of only the final '6 . 6, doesn't match. The second attempt, at '‹45 6 does match, as the bump-along has placed it "looking at" the '6' , which certainly matches \d+ . So, we have a final match of only the final '6 . One of .NET's regex options is RegexOptions.RightToLeft . What are its semantics? The answer is: "that's a good question." The semantics are not documented, and my own tests indicate only that I can't pin them down. In many cases, such as the '123 and 456' example, it acts surprisingly intuitively (it matches '456' ). However, it sometimes fails to find any match, and at other times finds a match that seems to make no sense when compared with other results. If you have a need for it, you may find that RegexOptions.RightToLeft seems to work exactly as you wish, but in the end, you use it at your own risk. 9.1.1.5. Backslash-digit ambiguities When a backslash is followed by a number, it's either an octal escape or a backreference. Which of the two it's interpreted as, and how, depends on whether the RegexOptions.ECMAScript option has been specified. If you don't want to have to understand the subtle differences, you can always use \k<num> for a backreference, or start the octal escape with a zero (e.g., \08 ) to ensure its taken as one. These work consistently, regardless of RegexOptions.ECMAScript being used or not. If RegexOptions.ECMAScript is not used, single-digit escapes from \1 through \9 are always backreferences , and an escaped number beginning with zero is always an octal escape (e.g., \012 matches an ASCII linefeed character). If its not either of these cases, the number is taken as a backreference if it would "make sense" to do so (i.e., if there are at least that many capturing parentheses in the regex). Otherwise , so long as it has a value between \000 and \377 , it's taken as an octal escape. For example, \12 is taken as a backreference if there are at least 12 sets of capturing parentheses, or an octal escape otherwise. The semantics for when RegexOptions.ECMAScript is specified is described in the next section. 9.1.1.6. ECMAScript mode ECMAScript is a standardized version of JavaScript [  ] with its own semantics of how regular expressions should be parsed and applied. A .NET regex attempts to mimic those semantics if created with the RegexOptions.ECMAScript option. If you dont know what ECMAScript is, or don't need compatibility with it, you can safely ignore this section. ] with its own semantics of how regular expressions should be parsed and applied. A .NET regex attempts to mimic those semantics if created with the RegexOptions.ECMAScript option. If you dont know what ECMAScript is, or don't need compatibility with it, you can safely ignore this section. [ ] ECMA stands for "European Computer Manufacturers Association," a group formed in 1960 to standardize aspects of the growing field of computers. When RegexOptions.ECMAScript is in effect, the following apply: -
Only the following may be combined with RegexOptions.ECMAScript : RegexOptions.IgnoreCase RegexOptions.Multiline RegexOptions.Compiled
-
\w , \d , and \s (and \W , \D , and \S ) change to ASCII-only matching. -
When a backslash-digit sequence is found in a regex, the ambiguity between backreference and octal escape changes to favor a backreference, even if that means having to ignore some of the trailing digits. For example, with (‹)\10 , the \10 is taken as a backreference to the first group, followed by a literal '0 . |