Service-Centric Architectures
| The previously discussed trends have driven each other over time. The drive towards more componentized and distributable services drives the need for greater bandwidth, which enables and encourages even more flexibility and choice of distribution. This has resulted in the service-oriented architectures that are implemented today. They are the ultimate expression of the trend away from server-centric applications to network-centric services. SOAs are typically characterized in terms of services and of how they interact, rather than the platform on which they run. A service can be a complete business service, such as an online book store, or it can be a part of that service (for example, a database service, a directory lookup service, or a stock control service). Services in SOAs:
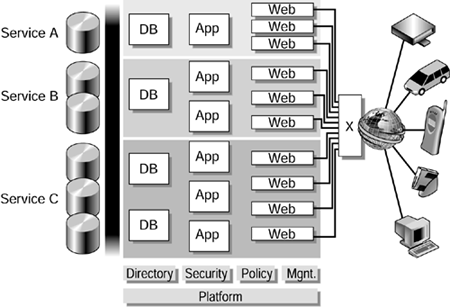
These services communicate with each other through platform-independent and language-independent message passing (for example, using XML documents). Dependent services can be discovered dynamically, enabling seamless scaling, rolling upgrades, and the ability for a consumer service to choose between a number of possible provider services. Web services are a realization of SOAs. Underneath these services, the data center becomes a fabric, or pool, of resources racks of processors, memory, storage, and other elements. These resources can be combined into servers (using dynamic system domains) with operating systems, which can be collected into clusters of servers to provide availability and scaling (for example, through traditional high-availability clustering or through load balancing). The clusters can likewise be aggregated into larger groupings that support complete multitier services (FIGURE 2-2). Figure 2-2. Typical Multitier Architecture
Providers of network-distributed services have great flexibility in how they choose to deploy their service components to meet their business goals. Tightly coupled service components, which still demand low latency for sharing state or data, are typically deployed on large multiprocessor computers and are often said to be vertically scaling. These often achieve availability through failing over the service component from one computer to another if the primary computer fails. An example is a data warehouse service. Loosely coupled components, which are typically less stateful or which store their state elsewhere, scale and achieve resilience through replication. They can be deployed across many single processor or small multiprocessor computers and are often said to be horizontally scaling. This is typical of web server farms, proxies, and identity servers. These deployments are the ends of a spectrum. For example, some application server tiers are deployed across a small number of mid-range multiprocessor systems because they share enough state between some components to benefit from a single large server-based deployment. Nonetheless, their workload is still partitionable enough to achieve scaling and a great deal of resilience through replication. Ultimately, any specific implementation is a compromise between:
Managing DeploymentsAlthough the architectures described above enable a great deal of flexibility in terms of deploying services to deliver the desired service attributes, they are also very complex to design, install, and manage. Managing and tracking the mapping of service components onto operating systems and, in turn, onto underlying servers or system domains becomes increasingly time consuming as the number and variety of components increases. Likewise, the TCO increases as the cost of management is driven by complexity based on the number and variety of the servers, operating system instances and configurations, tools, and services, as well as the various interdependencies and relationships between all of these components. In data centers with thousands of computers, the sets of dependencies become overwhelming and impossible to manage. Change becomes increasingly problematic, time consuming, and expensive as complexity leads to potentially brittle environments in which one mistake can affect an entire data center. The standard mechanism for addressing these problems is to divide and conquer, essentially siloing the data center (see FIGURE 2-2), based on:
|
EAN: N/A
Pages: 144