Chapter 3: Variables and Objects
Overview
Variables as "data containers" with names . Values as data - simple (innate or elementary) data, structures, and objects. Referencing variables through pointers. Unnamed "data containers" and their referencing through pointers. The dual role of pointers as address holders and binary code "interpreters". Various interpretations of the contents of a piece of memory. Pointer arithmetic. Why C/C++ cannot be interpreted in a platform-free manner like Java can. Why C/C++ cannot have a garbage collector.
During the execution of a program, a variable of the program corresponds to a location in memory, and the address of that location replaces all symbolic references to the variable in the load module. This is one of the important facts touched upon in Chapter 2 when we discussed why we can behave as if the program in its source form executes in the memory. In this chapter we will refine this notion and discuss its consequences.
The idea of variable as "data container" is very natural. In its crudest form we can imagine a variable to be a box, and whatever is in the box is the value of that variable. If we want to evaluate the variable (i.e., find its value), all we need do is look in the box and see what is in there; when we want to store something in the variable, we simply put it into the box. In fact, this crude notion is not that far from reality.
Instead of a box, a variable corresponds to a segment in memory. The contents of that segment - or, more precisely, the binary code stored in that segment - is the value of the variable. If a program needs to evaluate the variable, it must fetch or read the binary code stored in that memory segment and then interpret it as the appropriate value. If a program needs to store a value in a variable, is must first convert the value to the appropriate binary code and then store the binary code in the memory segment that corresponds to the variable.
There are several important issues to ponder in the previous paragraph alone.
The first important issue concerns binary codes. Memory can store only binary codes. Yet even the C language requires several different data types: characters , integers, floats, and so forth. Thus, different kinds of data must be converted to binary code in different ways. This is why a compiler, when dealing with a particular data type, must first include instructions to perform the conversion (or do the conversion itself if possible) to the appropriate binary code before it can include instructions for storing it in memory or using it in any way.
The second important issue concerns the size of the memory segment that corresponds to a variable, and hence the length of the binary code stored there. As stated previously, each symbolic reference in the source code is replaced by an address reference of the the beginning of the segment that corresponds to it (we will refer to this as the "address of the variable"). But there is no record of where the segment ends, so how does the computer know if it is to fetch 1 bit, 10 bits, or 100,000 bits? The solution is rather simple, though with poignant consequences. Each particular data type has a definite size. That size may differ from platform to platform, but for a particular platform it is fixed and unchangeable. For example, char has the size of 1 byte on any machine, while int may have the size of 2 bytes on the old 16-bit machines or the size of 4 bytes on today's most common 32-bit machines (and will be the size of 8 bytes on the coming 64-bit machines). We will use the term "size of variable" for the size of the memory segment that corresponds to it, which in turn is determined by the data type of the variable.
One of the major consequences of a definite size for each data type is a kind of "physical" aspect of the behavior of variables. Just like a physical box, a memory segment of a definite size cannot be used to store something that is "bigger". With a box it is physically impossible (without either breaking the box or the item being stored therein), but with a segment of memory the situation is different. We could choose different strategies for attempting to store a binary code longer than the size of the variable, a problem commonly referred to as overflow. One strategy for dealing with overflow is to prevent it by truncating the code to fit the space; another is to treat it as an error or exception; and yet another is simply to let it happen and try to store the longer binary code at that address anyway.
The C and C++ languages employ a mixed strategy: should overflow occur as a result of a numeric operation ( sort of left-end overflow), it is prevented by truncation ; otherwise (sort of right-end overflow), it is allowed to happen and the binary code is stored "as is", regardless of the consequences (for which the programmer is held ultimately responsible).
Thus, the result of incrementing a value of a variable may be larger than the variable and hence truncated. Let us discuss the following simple for -loop.
char i; ... for(i = 0; i < 256; i++) printf("%d\n",i); Though seemingly correct, it is an infinite (i.e., never-ending ) loop. The problem is caused not by the logic of the loop nor by the mathematical abstraction of the loop but rather by the "physicality" of the variable i as represented by a memory segment. Since i is of data type char , it follows that i has the size of 1 byte. Hence i attains the value of 255 when the binary code stored in it is 11111111. When i is incremented by 1, the code 11111111 should be replaced by 100000000, but the leftmost bit is truncated and so 00000000 is stored in i . The value of i ranges from 0 to 255, and after reaching 255 the next value is zero again (like odometers in cars ). Thus, i will never reach the terminating value of 256 and so the loop goes on for ever and ever, or until the program is terminated from the outside (a more likely scenario). A good compiler should alert us to the possible danger and give a warning message that we are comparing distinct data types ( char on the left-hand side is being compared to int on the right-hand side in the expression i < 256 ) and that it could be risky (or better yet, that the expression is always true). But not all compilers are good, and many programmers completely ignore warning messages or leave too many seemingly harmless warning messages unattended, so that an occasional important warning message is overlooked. Furthermore, the operator < may be overloaded for this particular combination of data types and hence no warning message will be produced by any compiler (of course the overloading of < could not be done in C++ for this trivial example, since classes or enumerated types would have to be involved instead of elementary data types, but the principle is the same).
The same problem can manifest itself in an even more innocuous form that would not be detected by a compiler unless it is set to report all potential overflow errors. The code
char i; int j; ... i = 255; ... i++; ... j = 510/i;
will crash the program (i.e., the operating system will terminate its execution) because the value of the variable i is 0 when the division is performed. Syntactically, everything is absolutely correct; there is nothing obvious a compiler could flag as potentially dangerous. Logically and mathematically it is correct. The only trouble is the definite size of i as a piece of memory, which results in i inadvertently having a zero value owing to overflow.
We have just illustrated that n incremented by 1 does not necessarily have the value of n+1 . This is something that we all take for granted. Thus, numbers as they are represented in memory are not a very faithful model of the abstract numbers we are used to. They are sufficient for a wide variety of applications, but they must be treated with respect and understanding to prevent programs from being unreliable in their performance and in the results they produce. The notion of variables as "data containers" or "memory segments" of definite sizes is helpful for avoiding errors like the ones just shown.
The other C/C++ strategy - of right-end overflows being ignored - is even more significant. Consider the following fragment of a simple program:
char i; int* p = (int*) &i; ... *p = 1234567892; ...
No compiler will complain; everything seems fine. Yet clearly we are storing a binary code for the integer value 1234567892 that takes 32 bits (01001001100101100000001011010100) at the address of the variable i that has the size of 8 bits (see Figure 3.1).
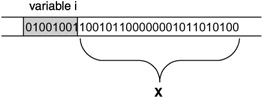
Figure 3.1: Overflow
There are several possible outcomes .
-
If the whole part X of the memory in Figure 3.1 belongs to the running program (process), then:
-
if X does not contain any data important for the rest of the execution of the program, then the program runs fine and there is no apparent problem;
-
if X does contain important data that are overridden by the 100101100000001011010100 tail of the binary code but by pure chance this does not change anything (as the data stored therein just happened to be the same), then the program runs fine and there is no apparent problem;
-
if X does contain important data that are overridden and thus changed, then
-
incorrect results may be produced or
-
the program may crash with all kinds of possible error messages.
-
-
-
If all or part of X belongs to some other process, then the program is terminated by the operating system for a memory access violation (the infamous UNIX segmentation fault error).
Any of these situations could occur at any time during execution, and the program's user has no control over the circumstances. Such a program exhibits erratic behavior: sometimes runs fine, sometimes runs wrong, sometimes crashes for one reason, another time crashes for a different reason. In fact, an erratically behaving program should immediately be suspected of a hidden problem with memory access.
All these troubles just for trying to store an int value at the location of a char variable? A most emphatic Yes! The notion of variables as "data containers" or "memory segments" is again helpful in preventing such problems.
The sizeof operator can be used to calculate the size in bytes either of the result of an evaluation of an expression ( sizeof expr ) or a data type ( sizeof( type ) ). The size calculation is performed during compilation and hence according to whatever platform the program is being compiled on, and this becomes an important aspect of portability. In particular, the size of a variable x can be calculated by sizeof x or sizeof(x) expressions. On a typical 32-bit machine, the C/C++ innate (or built-in or elementary or fundamental ) data types have the following sizes:
-
char and unsigned char values and variables have the size of 1 byte;
-
short and unsigned short values and variables have the size of 2 bytes;
-
int and unsigned int values and variables have the size of 4 bytes;
-
long and unsigned long values and variables have the size of 4 bytes;
-
float values and variables have the size of 4 bytes;
-
double values and variables have the size of 8 bytes;
-
any pointer value or variable has the size of 4 bytes.
In C/C++ programs one can define more complex data values and "data containers" (commonly called structures or records, though the latter term has lately become obsolete) using the struct construct. This construct can be used recursively (hierarchically), allowing us to explicitly describe how a structure consists of simpler or elementary components .
struct { char a; int b; }x; The structure variable x consists of two components: the first, named x.a , has data type char and so has a size of 1 byte; the second, named x.b , has data type int and so has the size of 4 bytes. The memory of a structure is contiguous. This simple example brings us to the topic of padding.
The memory usually cannot be accessed one bit or byte at a time. Its physical realization most commonly allows an access by one "machine word" at a time. Thus, when the computer is fetching the value of x.a from memory, it must in fact fetch the whole machine word of which x.a is a part. The same is true for storing; when the computer is storing a new value in x.a , the whole machine word must be stored anew in memory.
If the structure x were placed in the memory improperly (see Figure 3.2) then access to x.b would be rather inefficient, for fetching the value from or storing a value in x.b would require fetching or storing two machine words, even though x.b on its own would fit into a single machine word. It is much more efficient to waste some memory and align the components with machine-word boundaries in the physical memory, as indicated in Figure 3.3.
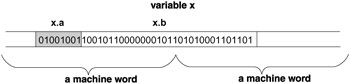
Figure 3.2: A structure improperly placed in memory
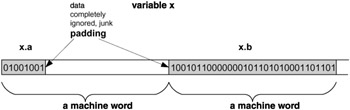
Figure 3.3: A structure properly placed in memory with the use of padding
Now, access to x.a or x.b requires a single memory access. The inclusion of this extra (otherwise unused) memory by the compiler is called padding, and the data stored in it are never accessed by the program and thus are complete junk, so in that respect the memory is wasted . The only purpose of padding is to align items of the structure with machine-word boundaries for efficient memory access. From a logical point of view the padding does not matter. But it does affect the size of a structure, and since it depends on the platform and the compiler, the same structure may have different sizes on different machines or when compiled by different compilers.
A frequent error of ignoring padding is illustrated by the following fragment of code. Such an error may lead to erratic behavior of the program due to an overflow, as discussed previously.
struct mystruct { char a; int b; }; ... ... void copy(void*,void*); /* prototype */ ... ... char* p; struct mystruct x; ... p = malloc(5); ... copy(p,&x); ... The programmer has calculated the size of mystruct to be 5 bytes, yet with padding the size of mystruct is 8 bytes. In the program, 5 bytes are allocated for a copy of the variable x , but when the contents of x are copied to the location that p points to, this causes an overflow because the function copy() correctly copies 8 bytes.
It should be noted that the previous code fragment also illustrates the common programming problem of using inconsistent conceptual levels. The programmer of the code fragment is dealing inconsistently with mystruct on two distinct conceptual levels: as a structure consisting of various components, and as a contiguous segment of memory or buffer. The function copy() is dealing with mystruct in a consistent manner, as a buffer with size 8 bytes.
Using the sizeof operator would remedy the overflow problem,
struct mystruct { char a; int b; }; ... ... void copy(void*,void*); /* prototype */ ... ... char* p; struct mystruct x; ... p = malloc(sizeof(struct mystruct)); ... copy(p,&x); ... though it does not address the problem of using inconsistent conceptual levels. The most consistent and hence the safest approach is to deal with mystruct as a structure only and leave the compiler to deal with it entirely:
struct mystruct { char a; int b; }; ... ... struct mystruct* p; struct mystruct x; ... p = malloc(sizeof(struct mystruct)); ... *p=x; ... The following code shows another error of ignoring padding (and using inconsistent conceptual levels) that may lead to incorrect results:
struct mystruct { char a; int b; }; ... ... void bytecopy(void*,void*,int); ... ... char* p; struct mystruct* p1; struct mystruct x; ... p = malloc(sizeof(struct mystruct)); ... bytecopy(p,(char*)&x.a,1); bytecopy(p+1,(char*)&x.b,4); p1 = (struct mystruct*) p; ... Here the value of item p1->a is correct (the same as x.a ), but the value of p1->b is incorrect because bytecopy(s1,s2,n) copies n bytes from s2 to s1 .
We have illustrated that improper programming and ignoring padding can lead to errors. However, ignoring padding can itself lead to inefficient use of memory:
struct mystruct1 { char a; int b; char c; } requires 12 bytes on a typical 32-bit machine, while
struct mystruct2 { char a; char c; int b; } requires only 8 bytes.
In Chapter 8 we will discuss classes and objects of C++ and their relation to memory in detail. At this point let us state that objects without methods are in fact very much like structures created by the struct construct. In fact, struct in C++ is treated as a class with no explicit methods and with all members being public. Nevertheless, for the purpose of our discussion of the memory aspects of variables, this has no relevance and thus all we have said about structures almost fully applies to objects as well.
Memory can never be empty. Therefore, when a variable is created as a "data container", it cannot be empty. The value of the variable is then arbitrary because the contents of the container are arbitrary, depending on circumstances that are totally beyond the programmer's control or prediction. It is a common error to leave a variable uninitialized or unset and then use it in an expression, which leads to incorrect results or crashing programs. A good compiler, though, can detect the first use of an uninitialized or unset variable in an expression and issue a warning message.
It may be important to know the logical address of a variable (e.g., in C it is used to emulate passing of arguments by reference; see Chapter 5). Of course, the address can only be known at the time of compilation. A C/C++ address operator & allows us to obtain that address in the form of an appropriate pointer (more about pointers later). We used it to pass the address of x.a or the address of x.b in the call to bytecopy() and to pass the address of x in the call to copy() in the previous code samples.
In order for a program to work with a "data container" it must know three attributes of that container: its address, its size, and its coding. The last two are determined by the data type of the container, so in a sense we need only two attributes: address and data type. During compilation, the compiler keeps tabs on variables in its symbol section and consequently knows all the attributes. Since each symbolic reference is ultimately replaced by an address reference, it is natural to consider whether we could reference the data containers directly by address and so avoid giving them explicit names. Having data containers without explicit names is crucial if we want to create them dynamically during program execution. For that we must somehow supply both attributes. This is the main purpose and role of the special values and variables in C and C++ called pointers. A pointer as a value is a simple address, and a pointer as a variable is a simple data container to hold an address. Moreover, the data type of the pointer determines the type of the data container being referenced via that pointer. The exception is void* , which represents just a plain address with no data type reference. We say that a pointer points to address x if the value of the pointer is x (see Figure 3.4).
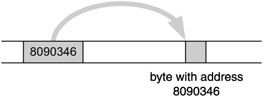
Figure 3.4: A pointer points to a memory location
Notice the subtle distinction: a pointer points to an address (a single byte), not to a data container of any kind. To determine what "lies at the end of the arrow" we must know the data type of the pointer, and (as indicated in Figure 3.5) a "virtual data container" of the same type is expected at the end of the arrow.
Figure 3.5: A pointer points to a "virtual data container"
Referencing of a data container through its pointer is done by the indirection operator * , and this operation is often called dereferencing of the pointer. If used as a so-called l-value ( roughly speaking, a value that can occur on the left-hand side of the assignment expression, indicating storage), then dereferencing translates as "store the appropriate binary code for the data type at the address the pointer is pointing to":
char* p; ... *p = 'A';
More precisely, this example translates as "store the 8-bit ASCII binary code for character 'A' at the address stored in p ". In any other context, dereferencing translates as "fetch the binary code of the appropriate length from the address the pointer is pointing to":
char* p; char x; ... x = *p;
More precisely, this code translates as "fetch the binary code of length 1 byte from the address stored in p and store it in the variable x ".
Pointers and their dereferencing are powerful programming features. Not only do they make it possible to access any memory location, they also make it possible to interpret the binary code stored in a certain memory location in different ways. My favorite "tricky" question for beginning computer science students is depicted in Figure 3.6.

Figure 3.6: What is the value stored in the four bytes starting at address 802340?
If you, dear reader, did not answer "I cannot tell", then you should brush up on the fundamentals of C programming. The truth is that the binary code stored in the four bytes starting at location 802340 can be interpreted in various ways; that is, the value is "in the eye of beholder". The value could be interpreted as two short integer values 16916 and 17475 in a row, or as an integer value of 1145258561, or as a float value of 781.035217, or as four consecutive characters 'A' , 'B' , 'C' , and 'D' in a row, and so on. Somebody may run the program code given next and come up with different values than given here.
This discrepancy is related to byte order - the order of significance of bytes. Imagine a 2-byte short integer with value 1. One byte contains all 0s, while the other byte contains all 0s and a single 1. In the big endian byte order, the byte with all 0s (the more significant byte) is on the left, while the byte with 1 (the less significant byte) is on the right. The little endian byte order is reversed : the less significant byte is on the left, while the more significant byte is on the right. The same applies to data of more than 2 bytes such as long integers.
For networking purposes (to establish in what order to transfer data across a network), the standard network byte order is defined as the big endian order. For the reasons just discussed, we have included a run-time check for "endianess" in the following sample program, which illustrates the technique of interpreting the contents of memory in different ways.
#include <stdio.h>char* Bits(char c); int AmBigEndian(); /* create a segment of static memory with the right data */ char a[4] = {'A','B','C','D'};/* function main ------------------------------------------- */ int main() { char* b = a; /* b points to the beginning of a */ short* s = (short*) s; /* s points to the beginning of a */ int* p = (int*) a; /* p points to the beginning of a */ float* f = (float*) a; /* f points to the beginning of a */ if (AmBigEndian()) printf("I am big endian\n"); else printf("I am little endian\n"); /* show the data as a sequence of bits */ printf("%s",Bits(a[0])); printf("%s",Bits(a[1])); printf("%s",Bits(a[2])); printf("%s",Bits(a[3])); putchar('\n'); /* show the data as 4 characters */ printf("'%c','%c','%c','%c'\n",*b,*(b+1),*(b+2),*(b+3)); /* show the data as 2 short integers */ printf("%d,%d\n",*s,*(s+1)); /* show the data as 1 integer */ printf("%d\n",*p); /* show the data as 1 float */ printf("%f\n",*f); return 0;}/*end main*//* function Bits ------------------------------------------- */ char* Bits(char c) { static char ret[9]; int i; i = (int) c; if (!AmBigEndian()) i=i>>24; ret[0] = ((c&128) == 128)+'0' ret[1] = ((c&64) == 64)+'0' ret[2] = ((c&32) == 32)+'0' ret[3] = ((c&16) == 16)+'0' ret[4] = ((c&8) == 8)+'0' ret[5] = ((c&4) == 4)+'0' ret[6] = ((c&2) == 2)+'0' ret[7] = ((c&1) == 1)+'0' ret[8] = ' #include <stdio.h>char* Bits(char c); int AmBigEndian(); /* create a segment of static memory with the right data */ char a[4] = {'A','B','C','D'};/* function main ------------------------------------------- */ int main() { char* b = a; /* b points to the beginning of a */ short* s = (short*) s; /* s points to the beginning of a */ int* p = (int*) a; /* p points to the beginning of a */ float* f = (float*) a; /* f points to the beginning of a */ if (AmBigEndian()) printf("I am big endian\n"); else printf("I am little endian\n"); /* show the data as a sequence of bits */ printf("%s",Bits(a[0])); printf("%s",Bits(a[1])); printf("%s",Bits(a[2])); printf("%s",Bits(a[3])); putchar ('\n'); /* show the data as 4 characters */ printf("'%c','%c','%c','%c'\n",*b,*(b+1),*(b+2),*(b+3)); /* show the data as 2 short integers */ printf("%d,%d\n",*s,*(s+1)); /* show the data as 1 integer */ printf("%d\n",*p); /* show the data as 1 float */ printf("%f\n",*f); return 0;}/*end main*//* function Bits ------------------------------------------- */ char* Bits(char c) { static char ret[9]; int i; i = (int) c; if (!AmBigEndian()) i=i>>24; ret[0] = ((c&128) == 128)+'0' ret[1] = ((c&64) == 64)+'0' ret[2] = ((c&32) == 32)+'0' ret[3] = ((c&16) == 16)+'0' ret[4] = ((c&8) == 8)+'0' ret[5] = ((c&4) == 4)+'0' ret[6] = ((c&2) == 2)+'0' ret[7] = ((c&1) == 1)+'0' ret[8] = '\0'; return ret; }/* end Bits *//* function AmBigEndian ------------------------------------ */ int AmBigEndian() { long x = 1; return !(*((char *)(&x))); }/* end AmBigEndian */ '; return ret; }/* end Bits *//* function AmBigEndian ------------------------------------ */ int AmBigEndian() { long x = 1; return !(*((char *)(&x))); }/* end AmBigEndian */ When executed on a big endian machine (most UNIX boxes), this program will give the following output:
I am big endian 'A','B','C','D' 01000001010000100100001101000100 16706,17220 1094861636 12.141422
while on a little endian machine (Intel processors) the output is
I am little endian 'A','B','C','D' 01000001010000100100001101000100 16961,17475 1145258561 781.035217
A crude yet useful analogy can be made: a pointer has two attributes. First, it points to a memory location, and second, it wears "data type glasses" - wherever it points, there it sees (through these "glasses") a virtual data container of the data type of the " glasses ". The pointer "sees" the data container there no matter what, which is why we call it a "virtual" data container. This segment of memory might have been defined as that kind of data container or it might not; it makes no difference, as the sample program shows. The pointer b looks at the address 802340 and through its char "glasses" sees a char data container of 1 byte there (see Figure 3.7). The pointer s looks at the address 802340 and through its short "glasses" sees a short data container of 2 bytes (Figure 3.8). The pointer p looks at the address 802340 and through its int "glasses" sees a int data container of 4 bytes (Figure 3.9). The pointer f looks at the address 802340 and through its float "glasses" sees a float data container of 4 bytes (Figure 3.10).

Figure 3.7: Looking through char* "glasses" at a char virtual data container
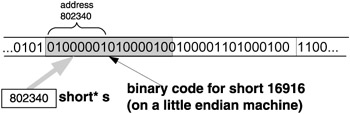
Figure 3.8: Looking through short* "glasses" at a short virtual data container
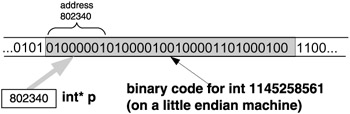
Figure 3.9: Looking through int* "glasses" at an int virtual data container
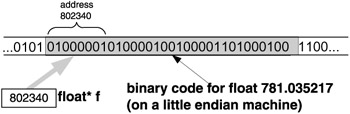
Figure 3.10: Looking through float* "glasses" at a float virtual data container
The analogy of virtual data containers makes the pointer arithmetic relatively simple and clear. Pointer arithmetic expressions should always have the form of "pointer ± nonnegative integer". The semantics of p+n is: "the address of the beginning of n th data container to the right of where p is pointing now"; more formally , the address is calculated as p+n*sizeof(X) , where X is the data type of the pointer p . Likewise, the semantics of p-n is: "the address of the beginning of n th data container to the left of where p is pointing now"; more formally, the address is calculated as p-n*sizeof(X) . Thus, the arrow where a pointer points can only move in discrete steps, from the beginning of one virtual data container to the beginning of another. It should come as no surprise that void* pointers cannot be involved in pointer arithmetic (of course, there are some compilers that may complain but still evaluate pointer arithmetic expressions involving void* , which they treat as if it were char* ).
How are the pointers set? There are many ways to do it, but four are rather common, basic, and relatively safe.
-
A pointer is set with an address of a dynamically allocated memory segment either through malloc() , calloc () ,or realloc() (in both C and C++) or through new or new[] (in C++) - mostly used to create dynamic objects and linked data structures.
-
A pointer is set with an address of a named object through the address operator & - mostly used to emulate passing by reference in C function calls.
-
A pointer is set with an address calculated from its own value and/or value(s) of another pointer(s) -mostly used to traverse linked data structures.
-
A pointer is set with a special address - mostly used in system programming for memory-mapped I/O operations and the like.
What do we mean by "relatively safe"? If a pointer points to a location in memory that does not belong to the running program and if an attempt is made to store any value there, then most modern operating systems will terminate the program immediately for a memory access violation. It is clear that pointers set in ways 1 and 2 are safe in the sense that they point to a location within the program's own memory space (as long as the allocation is properly checked for failure). Number 4 is possibly dangerous, as the pointer is set to a literal value and hence could be set to anything. But system programming is not that common and is usually done in a well- understood context by specialized system programmers; also, it is usually easy to detect such errors, so in this sense number 4 is not a source of big problems. It is number 3 that constitutes the biggest source of possible memory access violations: the calculations may be incorrect, leading to incorrect locations being pointed to. Since the actual value of the pointer that caused the violation may only be known at the moment of executing the expression of which it is a part, these errors can only be detected and debugged at run time.
There are two common situations associated with pointers that lead to memory access violations. In the first, the uninitialized pointer, a pointer is not initialized or set and so it can point to any random location (as discussed previously for uninitialized or unset variables). An attempt to store something at the location the pointer is pointing to may result in a memory access violation. The other situation is the dangling pointer (or dangling reference ). If a pointer is pointed to an object that is later deallocated, the pointer is left dangling (i.e., pointing to a previously meaningful address that is no longer meaningful). There are two ways for dangling to happen, explicit and implicit. In the explicit way, the pointer is first pointed to a dynamically allocated segment that is later explicitly deallocated without resetting the pointer appropriately. In the implicit way, the pointer is first pointed to a local object that is then later deallocated (as a part of the activation frame) when its function terminates, again without appropriate resetting of the pointer.
It has already been mentioned that a memory segment cannot ever be empty. This brings us to the notion of a null pointer, a pointer that points nowhere. An "empty" pointer would be ideal but is not possible, so we must find a possible address to mean null. Since it is standard to reserve the lowest memory addresses for the operating system, no application program ever stores anything at the very first byte - the byte with address zero. Thus we can (and do) use the value of 0 as meaning "no address whatsoever". The C language makes a conceptual distinction: in the stdio.h header file, a value NULL is defined (to be actually '\0' ). We can thus compare the value of pointer p with NULL or set p to NULL , because the compiler expands '\0' to the appropriate value. However, the stricter C++ compilers treat such expressions as a type mismatch, and thus it is usually the best to simply use for null pointers; it does not stand out as nicely as NULL , but at least it does not irritate the compiler. Lately the definitions of NULL have started to vary, using or (void*)0 . In such cases, strict ANSI or C++ compilers have no problems dealing with NULL .
A program written in a programming language does not necessarily have to be compiled before it can be executed; instead, it may be interpreted. The interpretation is done by a special program (interpreter) that reads the source statements, parses them, understands them, and executes the necessary instructions to achieve the same goals as the original source statements. It is clear that interpretation imposes certain restrictions on the expressiveness of the language (the language constructs can only allow actions that the interpreter is capable of) and that it is slower in execution when compared with compiled programs (the parsing and understanding of the source statements is done at run time rather than compile time). On the other hand, as long as you have the right interpreter on a machine, any program can be run there. The Java designers opted for this platform-free portability. To alleviate the problem with the speed of execution, Java programs are first compiled to byte code and then interpreted by the Java virtual machine interpreter, which greatly improves the speed of execution. Nevertheless, our comment about restrictions imposed on a language designed for interpretation still applies.
There is a price to pay for the power of pointers and dereferencing: it allows so much flexibility that it would be virtually impossible to design an interpreter capable of dealing with them. Their use makes C/C++ programs possibly too platform-oriented. For instance, special address locations for memory-mapped I/O operations are highly dependent on the particular platform and could be totally meaningless on any other platform. Such a program cannot and should not be made portable. Thus, any possible C/C++ interpreter would have to be platform-specific in its capabilities, voiding the main advantage of interpretation while leaving the disadvantages in place.
In Chapter 4 we will discuss dynamic memory allocation in more detail. From our discussion of pointers it should be clear that explicit dynamic memory allocation is fraught with a number of perils . In Chapter 10 we will discuss memory leaks resulting from improper memory deallocation. Simply put, having explicit memory allocation and deallocation gives C/C++ programs immense flexibility while keeping overhead to a minimum, but it opens the door to many possible problems.
The Java designers opted for a different strategy. Java does not allow any explicit memory allocation and deallocation, all allocations are done implicitly through reference variables, and the deallocation takes place automatically through garbage collection. The principles of garbage collection are simple: every portion of dynamically allocated memory has been allocated through a symbolic reference and so, as long as it is being referenced by an object, the garbage collector leaves it intact. But when memory is no longer referenced by any "live" object, the garbage collector can deallocate it. This strategy removes quite a few problems with memory access, but it requires explicit symbolic referencing (and hence no pointers). Besides that, the garbage collector can kick in any time more memory is needed, degrading the performance of a program at unpredictable moments.
Thus pointers prevent C/C++ from having a built-in garbage collector. This does not mean that you cannot write your own garbage collector (or download somebody else's) and then have all your programs written in compliance with the requirements of the garbage collector. Rather, this means that garbage collection cannot be a generic feature of C/C++ compilers that is transparent to programmers as it is, for example, in Java.
EAN: 2147483647
Pages: 64