Section 9.1. Partitioning
9.1. PartitioningDividing operations management tasks across multiple management groups is called partitioning . The peer production and preproduction management group configuration is an example of partitioning operations management tasks across management groups for reasons of functionality. For larger, more complex environments that have tens of thousands of machines to be monitored, or hundreds of machines to be monitored that are separated by slow WAN links, monitoring duties would probably be divided across multiple management groups. Each management group is responsible for monitoring some portion of the environment. That portion could be a section of the network, a geographic location, or a particular set of applications. For example, say there is a company called Drippy Sink with two major offices in New York and Los Angeles. There are 1,000 servers to monitor in New York and 1,500 in Los Angeles. From a business perspective, the two locations operate fairly autonomously, but from an IT perspective they are administered as a single environment. All IT administration is performed in the Los Angeles office and the two offices are linked via a single heavily used T1 circuit, so available bandwidth is limited. Even though there are only 2,500 servers to monitor, a quantity that fits comfortably into the capacity of a single management group, the network connection cannot support the traffic of 1,000 reporting agents. So, Drippy Sink deploys production management groups in Los Angeles and New York and a preproduction management group in Los Angeles. Drippy Sink has three independent management groups that must be managed. There are two separate Operator consoles and no single interface that shows what is going on in each one's environment right now. To make matters worse, there are AD domain controllers, Exchange servers, and shared ISA servers used by staff from both sites. So, for an administrator to monitor AD, she has to watch both Operator consoles, which only show a fraction of the operations management picture. This example illustrates a situation where centralized monitoring is needed. MOM 2005 supports a tiered architecture, where one destination management group can receive the alerting and discovery data from up to 10 source management groups . Between management groups, this is done via the MOM-to-MOM Product Connector (MMPC). To permit centralized monitoring of distributed management groups , Drippy Sink implements a fourth management group that both New York and Los Angeles production management groups will forward their alerts to. Figure 9-1 is a schematic of this architecture. The New York and Los Angeles management groups are the source management groups that are forwarding their alert and discovery data to the top-tier destination management group. When an administrator changes the resolution state of an alert in the top-tier management group, this change can be synchronized back to the source management group that it came from. The diagnostic tools in the top-tier Operator console can be used against the managed computers in the New York and Los Angeles source management groups as well. Configuration and functionality details for the MMPC are covered in the "Connecting MOM to MOM" section later in this chapter. Figure 9-1. An example of a tiered architecture at Drippy Sink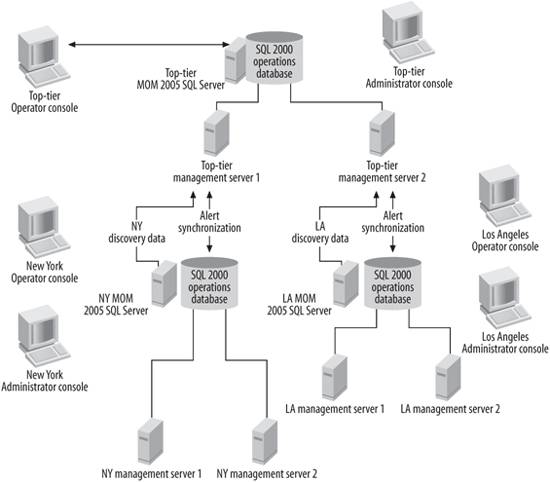 This is just one example of a situation in which partitioning is useful. Some of the other reasons for partitioning include capacity, administration, functionality, and configuration. 9.1.1. CapacityThe need for additional operational data processing capacity is the number-one reason that companies choose to create multiple management groups and arrange them in a tiered architecture. If there is insufficient processing capacity in your overall system (and this includes available network bandwidth between agents and their management servers), you can deploy additional management groups that are appropriately placed to overcome this. The insufficient capacity issue is another way of saying that you have found a bottleneck between your agents and Operator console that is slowing down operational data processing to an unacceptable level. The best way to tell if your management group is at, or near, capacity is to track the Alert Logging Latency and Event Logging Latency reports in the reporting console. These measurements take into account the capacity of the agent, management server, and OnePoint database system as a whole. Many factors influence the performance of this system and determine the volume of data coming in and how fast your management server and OnePoint database can process that data. These reports are found in the Home Before deciding to deploy a tiered architecture, be diligent about reducing capacity bottlenecks in the management servers and, most importantly, the database server. Deal with hardware bottlenecks firstfor example, a slow disk subsystem on the database machine, a high percent processor utilization, or a server having a high number of page faults/second, which can indicate a memory bottleneck. Then, look at the percent utilization and overall size of the OnePoint database. If it is near or has exceeded the 60%/18 GB limit, you need to configure more aggressive grooming. Remember, the smaller the database is, the better it will perform. Other good indicators that can help determine if you have reached capacity are the repeated occurrence of alerts that say: "The incoming MOM server queue is full," "The outgoing MOM server queue is full," and "The outgoing agent queue is full." The outgoing "MOM server queue is full" alert is an indicator that the OnePoint database isn't moving data quickly enough. If you have already tuned the database server and the OnePoint database, and you are still getting these alerts, then it is time to look at deploying additional management groups. In initial planning stages, there are obvious indicators to keep track of. For example:
When partitioning for reasons of capacity, remember to build in some extra bandwidth so that spikes in data volume, which can occur with the deployment of a new or greatly revised management pack, don't tank your system. You don't need to wait until the queues are consistently full and alert latency is at 300 seconds to justify the deployment of multiple management groups in a tiered architecture. 9.1.2. AdministrationMOM 2005 management groups can be partitioned along administrative divisions. This is done when peer IT groups in a company require autonomy in how they run their MOM 2005 management group. Looking at the tiered hierarchy of Drippy Sink, let's say the administrative model changes and the Los Angeles IT shop has full administrative control of the Los Angeles office and the New York IT shop has full control of the New York office. In addition to this, the New York and Los Angeles offices are in separate AD domains in the same tree. Figure 9-2 shows the domain configuration. Figure 9-2. The Drippy Sink AD domain hierarchy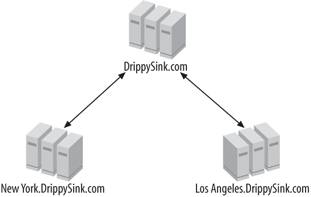 Because domain administrative responsibilities have been divided between the two locations, they want to divide their MOM management groups along the same lines. This enables Drippy Sink to use different DAS and management server action accounts and different global settings at the management group level and still synchronize alerts and forward discovery data to the top-tier management group for a centralized, all-encompassing view of the environment. In addition, each group of administrators can work with their own alerts at the source management group layer if they choose to. When alert synchronization is configured to be bidirectional, the alert can be resolved in one layer and that change will be reflected in the other layer.
Partitioning for administrative reasons can just as easily be in the same domain rather than between domains. The main requirement is that there are administrative needs, not necessary technical needs, for the partitioning. For example, another common monitoring practice is the creation of a separate management group for the purposes of collecting security events for auditing and control purposes. This security and audit management group is run by a group of IT security administrators and the managed servers are multihomed into it. Its sole reason for existence is to collect events from the Windows Security event log. Because it has been implemented as an IT audit control, the Windows administration team has no access to it, thus enabling external, independent audit control. This partitioning also makes sense for capacity planning because it is very likely that with auditing enabled the Windows security logs will generate a high volume of data. To fill out this configuration , the security management group may have its own separate MOM 2005 Reporting solution and forward any alerts to a destination management group. 9.1.3. FunctionalityThe top-tier management group is another example of partitioning management groups along functionality lines. The top-tier group is used as a concentration point for discovery and alert data, as well as a point for centralized management. Because it has this special purpose, it isn't normally used to manage computers, except for its own management servers and database server. 9.1.4. ConfigurationA MOM 2005 management group has certain configuration settings that are global they apply across all the management servers and managed computers that are in the management group. Most of these settings at the global level can be overridden at the individual, agent, or management server level. These types of global settings are like defaults that you can choose to accept or override on an agent-by-agent (or management server) basis. However, some of these settings cannot be overridden. These management group global settings are the equivalent of the password group policy that is set at the domain level in Active Directory. If you have established a password expiration policy and applied it to all of the organizational units, then all passwords on all accounts in that domain will expire according to that policy. The only way to accommodate any other password expiration policy is to create a different AD domain and set the desired policy there. Similarly, if requirements exist for more than one configuration for these settings, a different management group must be created to meet those requirements. The following are the management group global settings that that can't be overridden:
Any one of these reasons is enough to justify additional management groups. For example, if you need to create an additional management group for added capacity, that additional management group will also serve a specific function as wellto monitor the extra servers that can't be monitored by the first management group alone. Use that observation when you need to build your business case to justify the additional cost. |
 Microsoft Operations Manager Reporting
Microsoft Operations Manager Reporting 
EAN: 2147483647
Pages: 107