Database Design
| for RuBoard |
Even if you develop a complete understanding of ADO.NET, the applications you write might still suffer performance, security, and data integrity lapses if the database on which the data resides isn't designed optimally. In many organizations, the initial database design falls on the development team (the architect and developers) and only later is reviewed by a database administrator (DBA). In other organizations, developers are expected to do all the database design, sometimes without the proper background. In either case, if the database design isn't done well, by the time it is realized, it's usually too late or very costly to make the fundamental changes that are necessary.
To that end, this section explores several key areas that you need to consider when designing a database in SQL Server.
Note
Where appropriate, I'll point out which features or constructs are available only in SQL Server 2000 because the SqlClient provider can access both SQL Server 2000 and SQL Server 7.0.
Schema Design
| | Typically, the first step a designer takes when designing a relational database is to create a logical model of the data to be represented before actually creating the physical database. Modeling at the logical or conceptual level enables designers to leave implementation details to later stages and to concentrate on what data needs to be represented and how it's related to other data. Traditionally, many designers have chosen to use a database modeling methodology referred to as entity-relationship (ER) modeling to graphically produce logical and physical designs represented through an entity relationship diagram (ERD). Even though all the ins and outs of database modeling are beyond the scope of this book, a few key points to help you understand the methodology are in order. |
| | An ERD consists of entities and attributes arranged in the diagram. An entity is simply a thing or object that has significance in the problem domain such as a Title or Customer. An attribute is information about the entity that describes, identifies, classifies, or quantifies the entity. The attribute or set of attributes that uniquely identifies an entity is referred to as the identifier. |
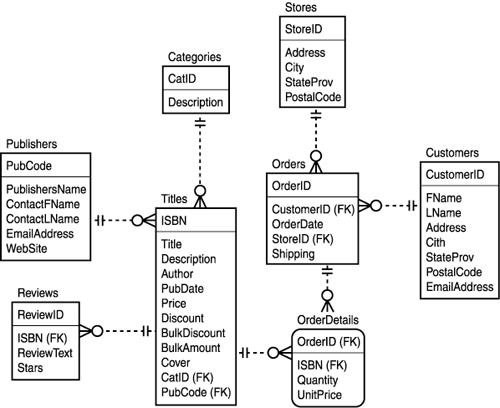
| | Multiple entities are then connected through relationships. The relationships indicate how the entities relate to each other and specifically provide the cardinality. The cardinality indicates the numerical relationship between entities as in each Title is related to zero or more Reviews or each Order is related to one or more Order Details. These relationships are signified by a specific set of symbols. Although there are several different sets of symbols and notations that can be used ”including Bachman, Chen ERD, Martin ERD, and Express-G ”one of the most common simply uses the IDEF1X symbol set for the entities with the Information Engineering notation's crow's feet notation for the relationships. Figure 13.2 presents the ERD for the ComputeBooks database using this notation. |
In Figure 13.2 you'll notice, for example, that the relationship between the Publishers and Titles entities indicates that a publisher can be related to zero or more titles (indicated by the circle and the crow's feet), whereas a title is related to one and only one publisher (indicated by the double barred line).
Figure 13.2. ComputeBooks ERD. This is the entity relationship diagram for the ComputeBooks database.
Note
| | A variety of software packages, such as Erwin and Visio 2000 (from which Figure 13.2 was created), provide the tools necessary to create logical data models and even reverse-engineer the physical database from a variety of sources into a logical diagram. This makes viewing the structure of an already existing database easy for documentation or rework . Most of these tools then enable you to change the model and update the database (referred to as round-tripping ). |
| | Although understanding ER modeling and the notations used isn't difficult, Microsoft has recently invested much effort in developing a conceptual modeling approach referred to as Object Role Modeling (ORM). Simply put, ORM seeks to make the relational design process simpler by using a natural language approach through intuitive diagrams in which you can place sample data, and by distilling the model into a series of elementary facts. ORM makes relational database design more approachable for developers and others not formally trained in database design. As a result, Microsoft is making ORM available in Microsoft Visio for Enterprise Architects and the VS .NET Enterprise Architect release. |
Note
For more information on ORM, see the article "Object Role Modeling: An Overview" by Microsoft's Terry Halprin on MSDN at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnvs700/html/vsea_ormoverview.asp.
| | Regardless of which techniques you use to create the logical model, eventually, the physical database objects (collectively referred to as the schema ) must be created. The schema consists chiefly of tables, views, columns , and constraints. A few of the most important aspects of the schema design you should look for follow. |
Normalizing the Schema
| | One of the most powerful concepts in relational database theory is normalization. Normalization can be thought of as the process of removing ambiguous and repetitive information from the schema by creating related tables. The sign of a normalized database is that it contains well-focused tables with a reasonable number of columns that are related through foreign keys, rather than one or several tables that contain a large number of columns. By designing a normalized database in SQL Server, you'll maximize the performance of sorting, index creation, and data modifications as well as minimize the storage required. |
| | As you're probably aware, various forms of normalization have been codified in relational theory. These forms specify an increasing and more restrictive level of normalization from First to Fifth Normal Form (and including Boyce-Codd Normal Form). Typically, designers don't attempt to implement anything higher than Third Normal Form ( 3NF ), the rules for which follow. |
A schema is in 3NF if
-
Each table (entity) must contain a primary key (identifier) that uniquely identifies a row in the table. In some instances, picking the primary key is simple because one column or a combination of the columns will naturally lend itself to uniqueness, such as PubCode in the Publishers entity or ISBN in the Titles entity in Figure 13.2. In other cases, you'll need the help of the database to assign a system- generated key to ensure uniqueness. All the other entities in Figure 13.2 use system-assigned keys defined with the uniqueidentifier (GUID) data type in SQL Server. As you might expect, the primary key isn't allowed to contain null values. In SQL Server, you'll use a primary key constraint in the CREATE TABLE statement to define the primary key.
-
Each column in each table is atomic, meaning that it stores one piece of information. In the ComputeBooks model in Figure 13.2, for example, the customer name is split into two columns because it consists of two pieces of information. A good rule of thumb is to avoid storing data in a column that will have to be parsed when it is retrieved.
-
Each nonkey column in each table is functionally dependent on the primary key. In other words, all the columns must directly describe the primary key. This is sometimes difficult to see but, for example, if the Reviews table in Figure 13.2 also contained the title of the book, it would violate this rule because the title really describes the ISBN and not the review. Another way to think of this rule is that your tables shouldn't contain repeated data that could be placed in its own table. A symptom of not following this rule is that a change to a single piece of data requires changes to scores of rows because the data is repeated a number of times. It follows , then, that all columns that aren't dependent on the primary key should be placed in their own tables. This rule is fairly strict and would require, for example, that in Figure 13.2 a separate table be created to hold the City and StateProv columns for each store because these columns are actually dependent on PostalCode and not on StoreID . However, reading or designing a model with this rule in mind can help you reduce redundant data.
Tip
As you learned on Day 4, "DataSet Internals," SQL Server also supports IDENTITY columns as a means of creating system-assigned keys. Each table can have one column marked as the IDENTITY column and it will be populated automatically in auto-incrementing fashion based on the seed and increment it's created with. The downside of the IDENTITY values is that they're database dependent and so aren't recommended for distributed database scenarios. However, it's relatively simple to create a stored procedure that inserts a row into a table and returns the new IDENTITY value using the @@IDENTITY global variable. You can then create a SqlParameter object to catch the return value with its SourceColumn property set appropriately in order to populate the new key back into the DataTable .
| | Although these rules make a great deal of sense conceptually, in practice, designers choose a level of normalization to fit the needs of the situation. For example, in the ComputeBooks model in Figure 13.2, the Author column of the Titles table is used to store multiple author names in a comma-delimited list. This violates the second rule because the column isn't atomic. A more normalized design would mean that an Authors entity should be created and each author stored there with a primary key that is referenced by the Titles entity. In fact, this design would call for a many to many relationship because authors can write many books and books can be written by many authors. This would result in the creation of an additional table to hold the relationship. This design would be more complicated and result in more joins between tables in my queries. I decided not to normalize this column because of the added complexity and because there is no other information I'm storing about authors. In other words, the increased complexity of normalization wasn't justified based on how the data is used. |
Note
However, keep in mind that this design isn't as flexible, so if data about authors needed to be collected in the future, the changes needed would greatly impact the schema. By normalizing early, you typically avoid major changes to the schema down the road.
In general, designers don't fully normalize a schema because doing so would hurt performance. In SQL Server, you should strive for designs in which you aren't regularly joining more than four tables. For example, if one of your most frequent queries must join six tables to retrieve the required information, you should think about denormalizing the schema so that fewer joins are required. In some cases, this might mean keeping your original tables intact but duplicating data in a table that's easier to query. Behind the scenes, you can then write triggers that keep the data in sync. Of course, this approach optimizes query performance at the cost of performance during an insert, update, or delete.
That having been said, not normalizing at all results in very wide tables (tables with many columns) that are difficult to maintain because of repeating data and that perform very poorly when queried.
Choosing Names and Data Types
A second aspect of schema design involves choosing appropriate table and column names as well as data types. As you can see in Figure 13.2, the names in your schema should use a simple naming convention that is human readable, if possible. In this case, each table name is the plural version of the data it stores and each column name is a human-readable identifier of less than 20 characters . In my designs, I prefer to avoid using underscores in favor of capitalizing each word in a compound name and to avoid embedding any data type information in the column name. Some designers will also insist that each column have a unique name in the schema. Even though I follow this dictate for primary keys (rather than simply calling each one ID), if the column names actually have the same meaning (such as Description ), there is no problem with using the same name because they can be fully qualified in SQL statements using the table name.
A more important issue, however, is the data types you choose. In SQL Server, there are more than 25 data types that you can use in your tables. In many cases, SQL Server supports several versions of the same basic data type; for example, datetime and smalldatetime . The rule of thumb is that you should pay attention to the ranges of data that the data type supports and then pick the smallest data type that spans the entire range of data you expect. This makes sense because you want to minimize the amount of storage for each table, which, more than simply conserving disk space, speeds up queries, index creation, and modifications on the table because less data needs to be considered .
In particular, you can use Table 13.1 as your guide.
Table 13.1. SQL Server data types. This table pairs the most common data type decisions designers have to make when creating tables in SQL Server.
| Comparison | Choice |
|---|---|
| datetime and smalldatetime | datetime (8 bytes) can store data from 1753 to 9999 with an accuracy of one three-hundredth of a second, whereas smalldatetime (4 bytes) ranges from 1900 to 2079 with an accuracy to the minute. datetime is appropriate for historical dates and those recording the specific time of a transaction. smalldatetime is useful for recording current dates. |
| tinyint and bit | tinyint ranges from 0 to 255, whereas bit is only 0 or 1. bit is useful for Boolean representations, whereas tinyint is more appropriate for values fixed in a natural range, such as number of children. |
| float and real | Both float and real are used to store floating point numeric data, but float can specify the precision and thus the storage size up to 53. real is defined as float(24) and uses 4 bytes, whereas float uses 8 bytes with a mantissa above 24. |
| money and smallmoney | Both money and smallmoney have the same accuracy, but smallmoney only ranges from +/- approximately 214,750 and uses 4 bytes instead of 8. You should take into account the currency when deciding which to use. |
| decimal and numeric | decimal and numeric are equivalent and can be used to represent numbers with a fixed but configurable precision and scale. The data can take from 5 to 17 bytes, depending on the precision specified. |
| char , varchar and nchar , nvarchar | char and nchar store fixed-length strings, whereas varchar and nvarchar store variable-length strings. char and varchar use non-Unicode characters, whereas nchar and nvarchar use Unicode. All can store up to 8,000 bytes, so nchar strings, for example, can only be of length 4,000. Use char and nchar when the data will be consistently the same length because they perform better. Use varchar and nvarchar for longer strings that vary greatly in order to conserve space. Use nchar and nvarchar when you need to store text from multiple languages in the same database. |
| varchar , nvarchar and text , ntext | text and ntext can support sizes of more than 2 billion bytes, whereas varchar and nvarchar are restricted to 8,000 bytes. text and ntext aren't stored with the row, so queries are slower. Use text and ntext when storing entire documents in the database. |
| binary and varbinary | binary can store fixed-length binary data from 1 to 8,000 bytes, whereas varbinary can store a variable amount of data up to 8,000 bytes. Use binary when the amount of data is fixed and the same for each row. |
| varbinary and image | varbinary can only store up to 8,000 bytes of data, whereas image is like text and can store more than 2 billion bytes in a data structure that is separate from the row. You can use image to store not just graphics, but any binary data that is large and variable, such as Word or Excel documents. |
| timestamp and uniqueidentifier | timestamp stores an automatically generated database-wide unique 8-byte binary value when a row changes or is inserted. You shouldn't use it as a primary key because it changes. You can use this value to determine whether the row has changed. uniqueidentifier stores a 16-byte globally unique identifier (GUID) typically generated with NEWID function. You can use it as a system-assigned primary key. |
Of course, as you have already learned, each of the SQL Server data types is represented in the System.Data.SqlTypes namespace and in the System.Data.SqlClient. SqlDbType enumeration. These can be used to read data directly from SQL Server using a SqlDataReader and to specify the data type for SqlParameter objects, respectively.
For SQL Server in particular, you should also try to minimize the number of columns that are nullable in the table. Tables with many nullable columns don't perform as well when queried. They are also more difficult to work with for developers who then need to check for the presence of null values using the IsDBNull method of the data reader, for example. One strategy you can use to avoid a lot of nullable columns is to factor them into their own table that has a one-to-one relationship with the table from which they came. In that way, this optional data can be queried only when it's needed.
User -Defined Data Types
| | One additional construct that you should consider when designing a database in SQL Server is the user-defined data type (UDT). Simply put, a UDT is a database-wide identifier that you create and that maps to one of the intrinsic SQL Server data types. You can use UDTs to standardize the way that certain pieces of information are stored and then reuse the UDTs across tables. |
For example, if you want to make sure that e-mail addresses are always represented as nvarchar(200) in your database, you can create a UDT called EmailAddress using the system stored procedure sp_addtype like so:
EXEC sp_addtype EmailAddress, 'nvarchar(200)', 'NULL'
Now that the EmailAddress UDT exists, you can use it in a CREATE TABLE statement in place of nvarchar(200) . If all your tables, such as Publishers and Customers , use the UDT consistently, you'll be assured that e-mail addresses are always stored in the same way.
You can also use UDTs to abstract the definitions one step further. For example, e-mail addresses and Web site addresses store the same kinds of information, so you could create a more general URI (uniform resource identifier) UDT that both the EmailAddress and WebSite columns will use.
UDTs also have the advantage of allowing rules (which we'll discuss later) to be bound to them so that the same rule can apply to multiple tables.
Tip
The downside to UDTs is that you must define them before you start creating tables, and they apply only to the database you create them in. However, if you create UDTs in the model system database, they'll be copied to any new databases you create on the server.
Using Constraints and Triggers
After you've created a schema with the proper level of normalization and chosen the data types for your columns carefully , you can begin to apply additional constructs to enhance data integrity to the schema. These include foreign keys, defaults, checks, and triggers.
Note
For this entire discussion, constraints can be applied directly in the CREATE TABLE statement or with the ADD CONSTRAINT clause of the ALTER TABLE statement. For more information on the specific syntax, see the SQL Server books online documentation.
Foreign Key Constraints
| | Foreign key constraints (also referred to as declarative referential integrity, or DRI) enforce the relationships between tables by ensuring that each row in the child table matches to a row in the parent table and that by default, you can't delete a row from the parent table that has child rows related to it. These simple rules go a long way toward ensuring the data integrity of the data that is captured. In SQL Server, foreign key constraints work the same way as the constraints you can add to a DataSet , as you learned on Day 4. In other words, the foreign key constraint between Titles and Publishers ensures that each title (the child) is related to a publisher (the parent) and that a publisher can't be deleted if there are titles associated with it. |
Just as with foreign key constraints in a DataSet , you can create cascade rules in SQL Server 2000 (although not in SQL Sever 7.0, in which you have to use triggers to get the same effect) using the ON DELETE and ON UPDATE clauses. For example, when the constraint is defined, you can specify that if the parent row is deleted, the child rows are deleted as well, and if the primary key of the parent table is updated, the foreign key column in the child table is updated as well. This ability comes in handy for relationships in which the child table is fully dependent on the parent. In ER modeling, this is often seen when the foreign key attribute is either a part of or the entire primary key, as is the case with the OrderDetails entity in Figure 13.2 (the rounded corners of the OrderDetails entity also denote this fact). In this case, an OrderDetails row means nothing without an Order row, so you should cascade the delete of the Order row to the OrderDetails row.
Tip
Foreign key constraints, along with all sorts of other changes, can be made graphically using a database diagram in the SQL Server Enterprise Manager.
A good schema design dictates that you create foreign key constraints for all your relationships. In most designs, almost every table will be related to at least one other through a foreign key constraint.
Default Constraints
Default constraints can be attached to a column in a table and automatically populate that column with a value when a row is inserted into the table. This is analogous to the DefaultValue property of the DataColumn , although it's more powerful because it isn't restricted to literal values. Default constraints come in very handy for populating non-nullable columns that have standard values and then perhaps change at a later time. For example, the BulkAmount column of the Titles table could have a default constraint placed on it of 50 because the bulk rate typically kicks in at 30. Used in this way, default constraints free the client from having to know the amount, which is better placed closer to the data. Coupled with using optional parameters in stored procedures, the client can create a new row without specifying all the columns.
Note
Remember that you learned on Day 10 that when using SqlClient, you don't have to define all the SqlParameter objects for a SqlCommand object that references a stored procedure if the procedure defaults their values to NULL in the declaration.
Default constraints can be specified using literal values such as numbers or strings (as in the case just specified) or using Transact -SQL functions or values that return a single value. A typical example is to place two non-nullable columns on each table, called CreateDate and CreateUser , whose default constraints are set to the functions GETDATE() and USER , respectively. In this way, the date and time the row was created and the user who created it are captured automatically when each row is added. These columns are very useful for troubleshooting and analysis.
Another good use for defaults ”and one that is used heavily in the ComputeBooks database ”is to use a default constraint to assign a new uniqueidentifier to inserted rows. The primary keys of all the tables except Publishers and Titles are defined as uniqueidentifier with a default constraint of NEWID() . This ensures that if the client doesn't generate a GUID, one will be created on the server.
Default constraints can be added to a table using the CREATE TABLE or ALTER TABLE statements as well as graphically in the table editor or database diagram with the SQL Server Enterprise Manager.
Note
SQL Server also supports default objects for backward compatibility because default constraints weren't supported before SQL Server 7.0. Default objects are created with the CREATE DEFAULT statement, and then can be bound to columns or user-defined data types using the sp_bindefault system stored procedure. Default objects aren't recommended because they don't perform as well as default constraints.
Check Constraints
Both check constraints and rules are used to restrict the range of values (the domain) in a column or set of columns during both an insert and an update. Basically, check constraints were introduced in SQL Server 7.0 and offer better performance, whereas rules (like default objects) are a backward-compatibility feature and offer a little added flexibility.
Typically, check constraints are used to check for boundary conditions on columns to make sure that data integrity is maintained . For example, the Price , BulkDiscount , BulkAmount , and Discount columns in the Titles table could also have individual (or column-level ) check constraints placed on them so that negative values are rejected. Even though these types of checks are done on the client, it's always desirable to place them on the server as well. This is because multiple applications might be using the data, and the server is the final gatekeeper of the data and is therefore ultimately responsible for data integrity issues.
| | However, check constraints (and rules) can also apply to more than one column (referred to as table-level constraints ) in order to make sure that the data in the columns is synchronized. This is similar to using the RowUpdating and RowUpdated events of the data adapter to ensure that column values are compatible. This might be necessary, for example, to make sure that the BulkDiscount falls within a certain percentage of the Price when a title is updated or inserted. As with defaults, check constraints maintain data integrity and should be used in addition to checking down on the client. |
Note
Although they don't perform as well as check constraints, rules have the advantage of being able to be created once and then applied to multiple tables or user-defined data types. They're created with the CREATE RULE statement and bound to a table or UDT using the system stored procedure sp_bindrule . Check constraints must be created separately on each column or table.
Triggers
Although not a constraint by definition, a trigger is the most flexible way to maintain data integrity because it's basically an event-driven stored procedure that has access to the data that is being inserted, updated, or deleted before the change is committed. In other words, triggers fire during a transaction (either implicit or explicit), whereas constraints are checked before the transaction begins. This allows triggers to make dynamic decisions but decreases performance. In fact, poorly designed triggers can bring a SQL Server database to its knees. For that reason, you should use constraints whenever possible and resort to triggers for added or special functionality.
Note
SQL Server 2000 introduced the concept of INSTEAD OF triggers, which can be used to explicitly perform the modification. This gives you complete control over how the modification is made and to which tables it applies.
As an example of a trigger, suppose you want to maintain in a table a column called UpdateUser that tracks the last user to modify the row. Although you can place a default constraint on the column to populate the column when the row is created, the constraint won't update the column when the row is modified. To allow the server to handle this automatically, you could create a trigger on the update event as shown in Listing 13.1.
Listing 13.1 Using triggers. This simple trigger updates the UpdateUser column with the current user when a row in the Titles table is updated.
CREATE TRIGGER upd_Titles ON dbo.Titles FOR UPDATE AS UPDATE Titles SET UpdateUser = USER FROM inserted b JOIN Titles ON b.ISBN = Titles.ISBN GO
| | In Listing 13.1, you can see that the trigger is defined with a name, the table it operates on, and the events ( UPDATE in this case, but they can fire for more than one) it will fire for. When it fires, it issues a correlated UPDATE statement against the internal inserted table and changes the UpdateUser value for those rows updated by the UPDATE statement. The inserted table is a logical table of the same structure as the table on which the trigger is firing which holds the values that are about to be used to update the row. There is also a deleted logical table that holds the old values. |
Note
One of the trickiest aspects of using triggers is that they fire only once even if the statement that caused them results in multiple rows being inserted, updated, or deleted. In other words, the logical inserted and deleted tables can contain more than one row. Any statements you write in the trigger need to take this into account and not assume that only one row is being processed . In Listing 13.1 this is done by using a JOIN within the UPDATE statement.
Although there are several rules for triggers that you should consult in the online documentation before using them, the rule of thumb is to perform the minimum amount of work necessary and then get out. This is the case because the trigger fires in the middle of the transaction, so any work you do in the trigger will delay the statement completion and thus the transaction completion. You should keep in mind that, by default, triggers can also be recursive and nested so that if a trigger on table A updates table B, the triggers on table B will fire, and so on up to 32 levels. Nested triggers can be turned off at the database level as well. Recursive triggers can also be turned off and, as the name implies, allow triggers to perform update statements either directly or indirectly (through other triggers) on the table that started the process. Triggers should also not return result sets because the client program won't be expecting it.
Another typical use for triggers is to maintain denormalized data. For example, if I regularly performed queries that counted the total number of books sold and revenue for each title, I might denormalize the Titles table by adding these columns and then use a trigger to update them.
Note
Because triggers fire in the middle of a transaction, they can also cause the implicit or explicit transaction to be rolled back by issuing a ROLLBACK TRANSACTION statement. When this occurs, the trigger should also issue a RAISERROR statement to ensure that the client is notified that the transaction was rolled back.
Finally, one of the other advantages of triggers is that they can reference objects outside the database in which they are defined. Using DRI, you can reference only tables inside the current database; with triggers, you can ensure that data in a separate database on the same or a remote server is synchronized. However, keep in mind that referencing objects outside the current database slows performance ”particularly if you're going to reference remote objects.
Note
Remote server can be referenced using linked server through SQL Server Enterprise Manager or the sp_addlinkedserver system stored procedure.
Because triggers are so flexible, they can also be used to implement business rules as an alternative to placing the rules in a .NET class. The decision of whether to use triggers in this way is chiefly based on whether the business rule is directly related to the data, and whether it's application specific (in addition, of course, to the portability needs of the application). For example, assume the ComputeBooks has a business rule that states that when a customer's orders total a certain amount, they are entitled to an enhanced status. A trigger could be used to check for this when a new order is inserted in the OrderDetails table and then another table updated with the CustomerID . Although this isn't the only way to accomplish the business rule (for example you could use a stored procedure called from the procedure that inserts the order), it's an example of one that's directly related to the data and applies for the entire organization.
Of course, the alternative is to place business rules in a .NET class in the business services tier of a multi-tiered application. Typically, these business classes rely on the fa §ade design pattern to control an entire process, such as the placing of an order. However, allowing SQL Server to implement relatively simple data-related business rules allows the business classes to concentrate on more complex rules (actually processes) that are application specific and that perhaps span more than just SQL Server.
Stored Procedure Layer Design
After the schema itself has been created, and all the appropriate constraints and triggers have also been created, you can concentrate on the database objects that the code you write in ADO.NET will access directly. In SQL Server, this means creating a stored procedure layer that ADO.NET code will access. The stored procedures are used primarily for data access, but can also implement business rules and processes as well.
There are several reasons why you would want all your clients to use stored procedures rather than inline SQL:
-
Abstraction . By allowing access only through stored procedures, you abstract the schema from the clients that are accessing it. As a result, you can change the underlying schema (perhaps to denormalize) without affecting the clients as long as the interface for the stored procedure (its name and parameters) remains the same. In this way, you can think of your stored procedures as application programming interface (API) to the data. As a side benefit, they also force you to think about clients that will be accessing the data.
-
Simplification . By creating an API that developers can use to access the database, you also simplify the process of working with the database. This is the case because the stored procedures can do the complex work of joining the appropriate tables and can simply return result sets with the appropriate columns based on the parameters passed into the procedure. At the same time, stored procedures that perform the updates can provide a consistent API that developers can use to maintain the data.
-
Performance . In SQL Server, the procedures are certain to take advantage of cached execution plans whereas inline (or batch) SQL statements must attempt to be matched to an existing execution plan each time they're called. Not only is the actual execution faster, but network traffic is also reduced because large amounts of SQL aren't encoded in TDS packets and sent to the server. Finally, using stored procedures as the "official" way of executing SELECT statements makes it simpler to apply the appropriate indexes to speed up queries. This is because the statements that are ultimately executed are restricted.
-
Security . Accounts in SQL Server can be given permissions to execute views but denied permissions to access the underlying tables directly. This ensures that developers must use the stored procedures rather than writing inline SQL. This only works, however, if the stored procedure or view is owned by the same account that owns the table.
What About Views and Functions?
|
When creating the stored procedure layer, you should take the approach of designing the procedures for the specific application you have in mind. In other words, the stored procedures should be application specific. By following this approach, you'll create stored procedures that streamline the coding process in .NET and make the database very approachable. At the same time, you'll likely see that the way in which one application needs to work with the data is very similar to others. As a result, there will be significant reuse of the procedures.
Tip
As with any abstraction, procedures introduce additional maintenance, so versioning of the procedures in a source code control system such as Microsoft Visual SourceSafe is recommended.
When you create the procedures, you should do so with a naming convention in mind. The convention that you'll see most often will prefix the procedure with usp_ for user stored procedure followed by the name of the procedure without underscore and each word capitalized.
As an example of this approach, consider the usp_GetTitles stored procedure in Listing 13.2.
Listing 13.2 Application-specific stored procedure. This procedure retrieves titles based on optional parameters.
CREATE PROCEDURE usp_GetTitles @ISBN [nvarchar](10) = NULL, @Title [nvarchar](100) = NULL, @Author [nvarchar](250) = NULL, @PubDate [smalldatetime] = NULL, @CatID [uniqueidentifier] = NULL, @Publisher [nchar](5) = NULL AS DECLARE @where nvarchar(250) declare @title_w nvarchar(100) DECLARE @author_w nvarchar(100) DECLARE @pubdate_w nvarchar(100) DECLARE @CatID_w nvarchar(100) DECLARE @Publisher_w nvarchar(100) DECLARE @sql nvarchar(500) SET @title_w = '' SET @author_w = '' SET @pubdate_w = '' SET @CatID_w = '' SET @Publisher_w = '' SET @where = 'WHERE' IF @isbn IS NOT NULL SET @where = @where + ' isbn = ''' + @isbn + '''' + ' and ' IF @title IS NOT NULL SET @title_w = ' title like ''%' + @title + '%''' + ' and ' IF @author IS NOT NULL SET @author_w = ' author like ''%' + @author + '%''' + ' and ' IF @pubdate IS NOT NULL SET @pubdate_w = ' pubdate > ''' + convert(nchar(10), @pubdate, 101) + ''' and ' IF @catid IS NOT NULL SET @catid_w = ' CatID = ' + convert(nchar(40), @catid) + '''' + ' and ' IF @publisher IS NOT NULL SET @publisher_w = ' Publisher = ''' + @publisher + '''' + ' and ' SET @sql = 'SELECT * FROM Titles ' + @where + @title_w + @author_w + @pubdate_w + @catid_w + @publisher_w SET @sql = substring(@sql,1, LEN(@sql)-4) EXEC sp_executesql @sql GO
| | The usp_GetTitles stored procedure in Listing 13.2 is a more complex procedure that's used to retrieve rows from the Titles table based on the parameters passed into it. You'll notice that all the parameters have default values of NULL . As a result, the SqlParameter objects needn't be created if they aren't used because the SqlCommand object uses named rather than positional arguments. The rest of the procedure then builds clauses that can be added to the WHERE clause to retrieve the appropriate rows. The entire SELECT statement is then finally executed using the sp_executesql system stored procedure. |
This procedure abstracts, simplifies access to, and secures access to the Titles table. The key benefit, however, is that on the client side, the ADO.NET code is simplified because it can simply call a single procedure and create the parameters as needed, as shown in Listing 13.3.
Listing 13.3 Calling the usp_GetTitles stored procedure. This code calls the procedure and adds the parameters as appropriate.
Private Function _getTitles(ByVal author As String, ByVal title As String, _ ByVal isbn As String, ByVal lowPubDate As Date, _ ByVal catID As Guid) As DataSet Dim da As New SqlDataAdapter("usp_GetTitles", MyBase.SqlCon) Dim titleDs As New DataSet() da.SelectCommand.CommandType = CommandType.StoredProcedure Try If Not isbn Is Nothing AndAlso isbn.Length > 0 Then da.SelectCommand.Parameters.Add(New SqlParameter( _ "@isbn", SqlDbType.NVarChar, 10)) da.SelectCommand.Parameters(0).Value = isbn Else If Not title Is Nothing AndAlso title.Length > 0 Then da.SelectCommand.Parameters.Add(New SqlParameter( _ "@title", SqlDbType.NVarChar, 100)) da.SelectCommand.Parameters(0).Value = title End If If Not author Is Nothing AndAlso author.Length > 0 Then da.SelectCommand.Parameters.Add(New SqlParameter( _ "@author", SqlDbType.NVarChar, 250)) da.SelectCommand.Parameters(0).Value = author End If If lowPubDate.Equals(Nothing) Then da.SelectCommand.Parameters.Add(New SqlParameter( _ "@pubDate", SqlDbType.DateTime)) da.SelectCommand.Parameters(0).Value = lowPubDate End If If Not catID.Equals(Guid.Empty) Then da.SelectCommand.Parameters.Add(New SqlParameter( _ "@catId", SqlDbType.UniqueIdentifier)) da.SelectCommand.Parameters(0).Value = catID End If End If da.Fill(titleDs) Return titleDs Catch e As SqlException da = Nothing titleDs = Nothing Call _throwComputeBookException("GetTitles Failed, passed in " & isbn, e) End Try End Function | | As you can see in Listing 13.3, the method is used to call the stored procedure based on the arguments passed into it. The method checks each one and, if it has an invalid value, the SqlParameter isn't created. In this way, this one method in .NET can query based on several parameters. As you'll see on Day 17, "ADO.NET in the Data Services Tier," this method can then be called by overloaded public methods that clients can use to retrieve titles. |
Index Design
Even if you apply all the design techniques and concepts discussed today, your applications will still perform badly if the server can't get the data fast enough. As the amount of data grows, the issue of indexes on the tables becomes the most important aspect of an application that is to perform well. At the most basic level, whenever SQL Server executes a query, the query optimizer analyzes the query and assigns costs to the various methods it can use to satisfy the query. By building indexes, you allow SQL Server to consider a new way of accessing the data so that it won't fall back to a table scan, which reads the table row by row until the query is satisfied.
Although indexes are a complicated subject and should be applied on enterprise databases by someone with experience, the following are some guidelines to consider:
-
What you should index .
You should consider indexing columns used in WHERE clauses and those that are specified in JOIN clauses. These are the columns that define which rows are accessed in the table and can be used most effectively by the optimizer. In addition, if all the columns requested in a SELECT statement are in an index (referred to as a covered query ), the data can be read directly from the index, which will increase performance.
-
What you shouldn't index . You shouldn't index columns that aren't used in WHERE clauses or JOIN clauses. The more indexes there are on a table, the slower INSERT , UPDATE , and DELETE statements will execute. In addition, creating indexes on small tables, such as simple lookup tables, might actually decrease performance. This is because a table scan will be faster and SQL Server will waste time considering and possibly using the index.
-
What kinds of indexes there are .
Basically, you can create clustered and nonclustered indexes. Clustered indexes actually rearrange the data on the disk in the order of the index. As a result, you can have only one clustered index per table. Clustered indexes are useful when the columns indexed will be queried in a range (as with a BETWEEN clause) or frequently sorted by with a SORT clause. Nonclustered indexes create the index in a separate data structure and therefore multiple nonclustered indexes can be created per table. Within these, the indexes can be unique. A unique index is like a primary key (in fact, creating a primary key creates an index automatically) in that duplicate values within the index aren't allowed. Indexes can also be composite and contain multiple columns. The order of the columns is important, so you should place more frequently queried column at the front of the index. -
Whether your indexes are correct . SQL Server provides the Index Tuning Wizard, accessible from SQL Server Enterprise Manager. This utility can analyze traffic captured by the SQL Profiler and suggest indexes based on the queries it is seeing. You can use this during testing to make sure that you've created the appropriate indexes for your application.
The bottom line is that there is no formula you can apply to decide which indexes you create. The determination comes from the combination of your application, the workload, the amount of data, and the tradeoff you're willing to make between query and modification performance.
Security
To ease the administration of permissions for the objects in the database, you need to apply a sound security design. In SQL Server, the simplest way to accomplish this is to make sure that all your objects are owned by the database owner ( dbo ) account. This is the built-in SQL Server account that the owner of the database automatically uses when accessing the database. This simplifies your applications in two ways.
First, if all the objects are owned by dbo , you needn't reference the owner in SQL statements. For example, the statement
SELECT * FROM Titles
will actually default to
SELECT * FROM dbo.Titles
This is the case because the owner wasn't specified and the account that's currently being used to execute the statement ostensibly doesn't have a table of its own named Titles .
Second, having all objects owned by the same account means that the ownership chain will be unbroken; for example, when a stored procedure or view accesses a table. This is important so that permissions can be revoked from the underlying table while allowing particular accounts to access the stored procedure or view. Developers needing to create objects can do so as an alias, as mentioned on Day 2, "Getting Started."
In addition to having dbo own the objects, you also need to assign permissions to the objects for particular accounts. In a typical Web application, the application will use a single account (either a Windows account or a standard account) that all users will share so that connection pooling will occur. This account, then, can be assigned to particular database roles such as db_denydatareader or assigned permissions directly using the GRANT and REVOKE statements. For example, to revoke permissions to the Titles table and grant permissions to the usp_GetTitles stored procedure, you would invoke the following statements:
REVOKE ALL ON Titles to publicsite GRANT EXECUTE ON usp_GetTitles to publicsite
where publicsite is a standard account that the ComputeBooks public ASP.NET Web site uses to log in to SQL Server.
| for RuBoard |
EAN: 2147483647
Pages: 158