Understanding Relational Databases
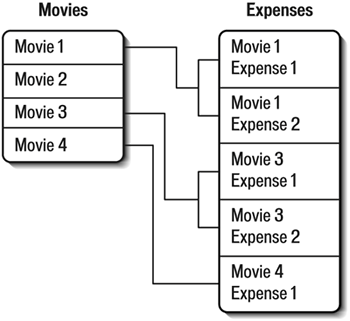
| The solution to your problem is to break the movie list into multiple tables. Let's start with the movie expenses. The first table, the movie list, remains just thata movie list. To link movies to other records, you add one new column to the list, a column containing a unique identifier for each movie. It might be an assigned movie number or a sequential value that is incremented as each new movie is added to the list. The important thing is that no two movies have the same ID. TIP It's generally a good idea never to reuse record-unique identifiers. If the movie with ID number 105 is deleted, for example, that number should never be reassigned to a new movie. This policy guarantees that there is no chance of the new movie record getting linked to data that belonged to the old movie. Next, you create a new table with several columns: movie ID, expense date, expense description, and expense amount. As long as a movie has no associated expenses, the second tablethe expenses tableremains empty. When an expense is incurred, a row is added to the expenses table. The row contains the movie that uniquely identifies this specific movie and the expense information. The point here is that no movie information is stored in the expenses table except for that movie ID, which is the same movie ID assigned in the movie list table. How do you know which movie the record is referring to when expenses are reported? The movie information is retrieved from the movie list table. When displaying rows from the expenses table, the database relates the row back to the movie list table and grabs the movie information from there. This relationship is shown later in this chapter, in Figure 5.8. Figure 5.8. The foreign key values in one table are always primary key values in another table, which allows tables to be related to each other.
This database design is called a relational database. With it you can store data in various tables and then define links, or relationships, to find associated data stored in other tables in the database. In this example, a movie with two expenses would have two rows in the expenses table. Both of these rows contain the same movie ID, and therefore both refer to the same movie record in the movie table. NOTE The process of breaking up data into multiple tables to ensure that data is never duplicated is called normalization. Primary and Foreign KeysPrimary key is the database term for the column(s) that contains values that uniquely identify each row. A primary key is usually a single column, but doesn't have to be. There are only two requirements for primary keys:
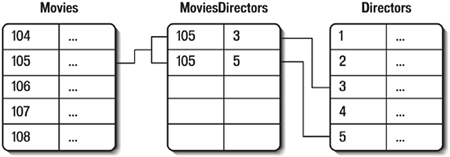
When you are asked for a list of all expenses sorted by movie, you can instruct the database to build the relationship and retrieve the required data. The movie table is scanned in alphabetical order, and as each movie is retrieved, the database application checks the expenses table for any rows that have a movie ID matching the current primary key. You can even instruct the database to ignore the movies that have no associated expenses and retrieve only those that have related rows in the expenses table. TIP Many database applications support a feature that can be used to auto-generate primary key values. Microsoft Access refers to this as an Auto Number field, SQL Server uses the term Identity, and other databases use other terms for essentially the same thing. Using this feature, a correct and safe primary key is automatically generated every time a new row is added to the table. NOTE Not all data types can be used as primary keys. You can't use columns with data types for storing binary data, such as sounds, images, variable-length records, or OLE links, as primary keys. The movie ID column in the expenses table isn't a primary key. The values in that column are not unique if any movie has more than one expense listed. All records of a specific movie's expenses contain the same movie ID. The movie ID is a primary key in a different tablethe movie table. This is a foreign key. A foreign key is a non-unique key whose values are contained within a primary key in another table. To see how the foreign key is used, assume that you have been asked to run a report to see which movies incurred expenses on a specific date. To do so, you instruct the database application to scan the expenses table for all rows with expenses listed on that date. The database application uses the value in the expenses table's movie ID foreign key field to find the name of the movie; it does so by using the movie table's primary key. This relationship is shown in Figure 5.8. The relational database model helps overcome scalability problems. A database that can handle an ever-increasing amount of data without having to be redesigned is said to scale well. You should always take scalability into consideration when designing databases. Now you've made a significant change to your original database, but what you've created is a manageable and scalable solution. Your boss is happy once again, and your database management skills have saved the day. Different Kinds of RelationshipsThe type of relationship discussed up to this point is called a one-to-many relationship. This kind of relationship allows an association between a single row in one table and multiple rows in another table. In the example, a single row in the movie list table can be associated with many rows in the expenses table. The one-to-many relationship is the most common type of relationship in a relational database. Two other types of relational database relationships exist: one-to-one and many-to-many. The one-to-one relationship allows a single row in one table to be associated with no more than one row in another table. This type of relationship is used infrequently. In practice, if you run into a situation in which a one-to-one relationship is called for, you should probably revisit the design. Most tables that are linked with one-to-one relationships can simply be combined into one large table. The many-to-many relationship is also used infrequently. The many-to-many relationship allows one or more rows in one table to be associated with one or more rows in another table. This type of relationship is usually the result of bad design. Most many-to-many relationships can be more efficiently managed with multiple one-to-many relationships. Multi-Table RelationshipsNow that you understand relational databases, let's look at the directors problem again. You will recall that the initial solution was to add the directors directly into the movie table, but that was not a viable solution because it would not allow for multiple directors in a single movie. Actually, an even bigger problem exists with the suggested solution. As I said earlier, relational database design dictates that data never be repeated. If the director's name was listed with the movie, any director who directed more than one movie would be listed more than once. Unlike expenseswhich are always associated with a single moviedirectors can be associated with multiple movies, and movies can be associated with multiple directors. Two tables won't help here. The solution to this type of relationship problem is to use three database tables:
For example, if movie number 105 was directed by director ID number 3, a single row would be added to the third table. It would contain two foreign keys, the primary keys of each of the movie and director tables. To find out who directed movie number 105, all you'd have to do is look at that third table for movie number 105 and you'd find that director 3 was the director. Then, you'd look at the directors table to find out who director 3 is. That might sound overly complex for a simple mapping, but bear with methis is all about to make a lot of sense. If movie number 105 had a second director (perhaps director ID 5), all you would need to do is add a second row to that third table. This new row would also contain 105 in the movie ID column, but it would contain a different director ID in the director column. Now you can associate two, three, or more directors with each movie. You associate each director with a movie by simply adding one more record to that third table. And if you wanted to find all movies directed by a specific director, you could do that too. First, you'd find the ID of the director in the directors table. Then, you'd search that third table for all movie IDs associated with the director. Finally, you'd scan the movies table for the names of those movies. This type of multi-table relationship is often necessary in larger applications, and you'll be using it later in this chapter. Figure 5.9 summarizes the relationships used. Figure 5.9. To relate multiple rows to multiple rows, you should use a three-way relational table design.
To summarize, two tables are used if the rows in one table might be related to multiple rows in a second table and when rows in the second table are only related to single rows in the first table. If rows in both tables might be related to multiple rows, however, three tables must be used. IndexesDatabase applications make extensive use of a table's primary key whenever relationships are used. It's therefore vital that accessing a specific row by primary key value be fast. When data is added to a table, you have no guarantee that the rows are stored in any specific order. A row with a higher primary key value could be stored before a row with a lower value. Don't make any assumptions about the actual physical location of any rows within your table. Now take another look at the relationship between the movie list table and the expenses table. You have the database scan the expenses table to learn which movies have incurred expenses on specific dates; only rows containing that date are selected. This operation, however, returns only the movie IDsthe foreign key values. To determine to which movies these rows are referring, you have the database check the movie list table. Specific rows are selectedthe rows that have this movie ID as their primary-key values. To find a specific row by primary-key value, you could have the database application sequentially read through the entire table. If the first row stored is the one needed, the sequential read is terminated. If not, the next row is read, and then the next, until the desired primary key value is retrieved. This process might work for small sets of data. Sequentially scanning hundreds, or even thousands of rows is a relatively fast operation, particularly for a fast computer with plenty of available system memory. As the number of rows increases, however, so does the time it takes to find a specific row. The problem of finding specific data quickly in an unsorted list isn't limited to databases. Suppose you're reading a book on mammals and are looking for information on cats. You could start on the first page of the book and read everything, looking for the word cat. This approach might work if you have just a few pages to search through, but as the number of pages grows, so does the difficulty of locating specific words and the likelihood that you will make mistakes and miss references. To solve this problem, books have indexes. An index allows rapid access to specific words or topics spread throughout the book. Although the words or topics referred to in the index are not in any sorted order, the index itself is. Cat is guaranteed to appear in the index somewhere after bison, but before cow. To find all references to cat, you would first search the index. Searching the index is a quick process because the list is sorted. You don't have to read as far as dog if the word you're looking for is cat. When you find cat in the index list, you also find the page numbers where cats are discussed. Databases use indexes in much the same way. Database indexes serve the same purpose as book indexesallowing rapid access to unsorted data. Just as book indexes list words or topics alphabetically to facilitate the rapid location of data, so do database table indexes list the values indexed in a sorted order. Just as book indexes list page numbers for each index listing, database table indexes list the physical location of the matching rows, as shown in Figure 5.10. After the database application knows the physical location of a specific row, it can retrieve that row without having to scan every row in the table. Figure 5.10. Database indexes are lists of rows and where they appear in a table.
There are two important differences between an index at the back of a book and an index to a database table. First, an index to a database table is dynamic. This means that every time a row is added to a table, the index is automatically modified to reflect this change. Likewise, if a row is updated or deleted, the index is updated to reflect this change. As a result, the index is always up to date and always useful. Second, unlike a book index, the table index is never explicitly browsed by the end user. Instead, when the database application is instructed to retrieve data, it uses the index to determine how to complete the request quickly and efficiently. The database application maintains the index and is the only one to use it. You, the end user, never actually see the index in your database, and in fact, most modern database applications hide the actual physical storage location of the index altogether. When you create a primary key for a table, it's automatically indexed. The database assumes the primary key will be used constantly for lookups and relationships and therefore does you the favor of creating that first index automatically. When you run a report against the expenses table to find particular entries, the following process occurs. First, the database application scans the expenses table to find any rows that match the desired date. This process returns the IDs of any matching expenses. Next, the database application retrieves the matching movie for each expense row it has retrieved. It searches the primary key index to find the matching movie record in the movie list table. The index contains all movie IDs in order and, for each ID, lists the physical location of the required row. After the database application finds the correct index value, it obtains a row location from the index and then jumps directly to that location in the table. Although this process might look involved on paper, it actually happens very quickly and in less time than any sequential search would take. Using IndexesNow revisit your movies database. Movie production is up, and the number of movies in your movies table has grown, too. Lately, you've noticed that database operations are taking longer than they used to. The alphabetical movie list report takes considerably longer to run, and performance drops further as more movies are added to the table. The database design was supposed to be a scalable solution, so why is the additional data bringing the system to its knees? The solution here is the introduction of additional indexes. The database application automatically creates an index for the primary key. Any additional indexes have to be explicitly defined. To improve sorting and searching by rating, you just need an index on the rating column. With this index, the database application can instantly find the rows it's looking for without having to sequentially read through the entire table. The maximum number of indexes a table can have varies from one database application to another. Some databases have no limit at all and allow every column to be indexed. That way, all searches or sorts can benefit from the faster response time. CAUTION Some database applications limit the number of indexes any table can have. Before you create dozens of indexes, check to see whether you should be aware of any limitations. Before you run off and create indexes for every column in your table, you have to realize the tradeoff. As we saw earlier, a database table index is dynamic, unlike an index at the end of a book. As data changes, so do the indexesand updating indexes takes time. The more indexes a table has, the longer write operations take. Furthermore, each index takes up additional storage space, so unnecessary indexes waste valuable disk space. So when should you create an index? The answer is entirely up to you. Adding indexes to a table makes read operations faster and write operations slower. You have to decide the number of indexes to create and which columns to index for each application. Applications that are used primarily for data entry have less need for indexes. Applications that are used heavily for searching and reporting can definitely benefit from additional indexes. In our example, you should probably index the movie list table by rating because you often will be sorting and searching by movie rating. Likewise, the release date column might be a candidate for indexing. But you will seldom need to sort by movie summary, so there's no reason to index the summary column. You still can search or sort by summary if the need arises, but the search will take longer than a rating search. Whether you add indexes is up to you and your determination of how the application will be used. TIP With many database applications, you can create and drop indexes as needed. You might decide that you want to create additional temporary indexes before running a batch of infrequently used reports. They enable you to run your reports more quickly. You can drop the new indexes after you finish running the reports, which restores the table to its previous state. The only downside to doing so is that write operations are slower while the additional indexes are present. This slowdown might or might not be a problem; again, the decision is entirely up to you. Indexing on More than One ColumnOften, you might find yourself sorting data on more than one column; an example is indexing on last name plus first name. Your directors table might have more than one director with the same last name. To correctly display the names, you need to sort on last name plus first name. This way, Jack Smith always appears before Jane Smith, who always appears before John Smith. Indexing on two columnssuch as last name plus first nameisn't the same as creating two separate indexes (one for last name and one for first name). You have not created an index for the first name column itself. The index is of use only when you're searching or sorting the last name column, or both the last name and first name. As with all indexes, indexing more than one column often can be beneficial, but this benefit comes with a cost. Indexes that span multiple columns take longer to maintain and take up more disk space. Here, too, you should be careful to create only indexes that are necessary and justifiable. |

EAN: N/A
Pages: 282