P2P Architectures
| What makes Gnutella and other P2P applications interesting is the ease with which large networks of cooperating nodes can be assembled, and that these nodes live on the edge of the network. The nodes are common PCs that dynamically assemble to form a distributed file system . The network is constantly changing many nodes are behind firewalls and one-way Network Address Translation (NAT) routers; the computers may be turned off at night, and they enter and leave the network at will. This is antithetical to the network organization and typical filesystems found on business networks. In a client/server model, the server controls and manages the relationship clients have with resources, such as databases, files, networks, and other clients. The server functions as a higher-level citizen within the computing community. It is given special privileges and functionality to control its subjects. Node equality has a dramatic impact on the way we architect and build systems. What has been solved by traditional hierarchical systems is now unraveled, and up for debate and re-evaluation in the peer-to-peer world. How do we identify and locate entities? Who controls access to resources? Although these questions are difficult to answer in any environment, they are at least well understood. In P2P systems, this is not the case. This is the new frontier of computing. The rules have not been defined, and the opportunity still exists to engage in design and development on the edge. P2P may be the first wave of delivering post Web-browser Internet content. Interestingly, the definition of the verb tense of the word peer is "to look intently, searchingly, or with difficulty." This definition can be applied to the actions required by P2P nodes when you remove hierarchical relationships. How do you search for peers and form groups of cooperating entities? The first generation of P2P applications grappled with the problems inherent in this question. As a result, they exposed the strengths and weaknesses of early P2P systems. You can learn a lot about P2P by studying early systems like Napster, Gnutella, and Freenet. Applications such as these revealed common characteristics of P2P systems. P2P systems have a dynamic element that enables them to form or discover groups and communities. Early systems used this primarily for searching, or to solve a common problem. P2P systems require virtual namespaces to augment current addressing technology. A virtual namespace provides a method for persistent identification, which would otherwise not be possible. For the moment, think of this as your email address that uniquely identifies you, regardless of what computer you use to access your mail. Peers in a P2P system are considered equals in terms of functional capabilities. Equality means you no longer need an intermediary to help you participate in a network. If you're connected to the Internet, you can get involved. Peers can appear anywhere on the network. They can be your PC, or the Palm Pilot that you hold in your hand. If you can connect it to the network, you can "peer" it. Peers need not be permanent; they have a transient capability to appear and disappear on the network. Intermittent connectivity in many P2P systems is the norm rather than the exception. Early P2P systems were comprised of dial-up users who established connectivity, joined the network, and then disconnected and left the network. P2P systems had to account for this type of membership. Peers have a wide array of processing, bandwidth, and storage capabilities. While they are all equal, some are more equal than others. A laptop computer can connect to the Internet through a dial-up connection and become a peer. A Sun Enterprise 10000 with fiber optic pipes can also become a peer on the same network. Functionally, in the P2P system they are equal. However, their performance capabilities are quite different. P2P is changing the way we build systems that exploit the global network, and the characteristics of this evolution will teach us many lessons. How P2P Forms Dynamic NetworksDynamic networks are fundamental to P2P systems. The Internet is a dynamic network with a number of static properties. For example, each machine that connects to the Internet is assigned a unique IP address. IPv4, the predominant protocol today, uses 32-bit addresses. Values are represented in decimal notation separated by dots; for example, 172.16.1.2. This configuration limits the possible addresses that are available. The proliferation of user machines and devices requiring IP addresses has gone beyond the original creators' vision. We are running out of addresses. The IPv6 protocol has been defined to extend the range of possible addresses, and to be backward compatible with IPv4. IPv6 uses 128-bit addresses. Values are represented as hexadecimal numbers separated by colons; for example, FEDC: B978:7654:3210:F93A: 8767:54C3:6543. IPv6 will support 1012 (1 trillion) machines and 109 (1 billion) individual networks. However, how soon IPv6 will be widely available is still not clear. Because humans remember names more easily that numbers, the Internet provides a way for us to use names to identify machines. The Domain Name Service provides the mechanism that helps users identify or map a machine name to an IP address. As a result, we can use http://java.sun.com rather than http://192.18.97.71/. Although you can use IP and DNS to identify and find certain machines on the network, there still exist challenges for P2P systems. The limited number of IP addresses available using IPv4 has resulted in additional identification mechanisms. NAT makes it possible to assign a pool of reserved IP addresses to machines on a local network. When connecting to the Internet, the machines share a "public" IP address. Because the reserved pool has been set aside for use in private networks, they will never appear as public addresses. Consequently, they can be reused. Although these mechanisms do wonders to conserve addresses, they make discovering real machine addresses difficult, especially in dynamic environments. The next-generation Internet, which will use IPv6, is designed to address this problem, but it's also likely years in the future. In the meantime, dynamic IP assignment on the Internet is still common, and creates an inherent identification problem. How do you recognize a peer that no longer has the same identity? Peer-to-peer networks must be able to uniquely identify peers and resources that are available. As a result, P2P systems have had to define their own naming schemes independent of IP addresses or DNS. They have had to create virtual namespaces, enabling users to have persistent identities on their systems. Rather than being predefined or preconfigured such as in DNS, the nodes within the network "find" or "discover" each other using IP and DNS as a navigational aid to build a dynamic or virtual network. Dynamic network formation is typical of P2P networks. Chapter 5, "System Topics Explained," covers discovery in great depth. DiscoveryHow peers and resources of the P2P system are discovered has generated a substantial amount of press and dialogue. To date, it has been the elusive measure of success for peer-to-peer systems. You can think of discovery on two levels. First, the discovery process is associated with finding a peer. In this case, a peer refers to a computing entity that is capable of understanding the protocol of the messages being exchanged. It is an entity that "speaks" the same language it understands the semantics of the dialogue. Peer discovery is required to find a service or help divide and conquer many problems associated with information processing. If we didn't understand what we were exchanging, we couldn't progress beyond digital babble. The second level of discovery is associated with finding resources of interest. The early P2P applications dealt with file sharing and searching. In contrast to popular search engines, P2P applications define new techniques to discover files and information on the Internet. The massive amount of information available on the Internet and its exponential growth is outpacing traditional information indexing techniques. In addition, the delay between content availability and content discovery continues to grow despite parallelism in popular search engines. P2P resource discovery provides a more real-time solution to information searching. However, the discovery techniques and protocols required have come at a price. The Gnutella story has been well documented. A popular file sharing and search program, Gnutella uses an unconventional broadcast mechanism to discover peers, as illustrated in Figure 1.2. The broadcast technique grows exponentially the more users, the more broadcasts. When the size of the user base grew too quickly, the system came crashing to a halt, flooding networks with Gnutella requests. The success of the software highlighted the limitations of its discovery architecture. Figure 1.2. Gnutella discovery quickly ran into the "broadcast storm" problem once the network grew beyond initial expectations.
An effective discovery mechanism is critical to the successful design and deployment of a peer-based network. To be effective, a discovery mechanism must be efficient in different execution environments. It should be efficient in discovering peers and resources regardless of the size of the network. It should also be resilient enough to ward off attacks and security breaches that would otherwise jeopardize the viability of the technology. Centralized methods of discovery often break down when applied to large peer-based networks. They often fail to scale or present single points of failure in the architecture. There are a number of decentralized discovery methods in use that use a variety of designs and architectures. All of these methods have various strengths that make them attractive for certain circumstances. However, they all have tradeoffs in large peer-based networks. Simple BroadcastSimple broadcast sends a request to every participant within the network segment or radius. When used for discovery, it can reach a large number of potential peers or find a large number of resources. The drawback to this approach is that as the user base grows linearly, the number of requests grows exponentially. This approach can result in huge bandwidth requirements. At some point, the network will be saturated with requests and trigger timeouts and re-transmissions, which just aggravates the already dire situation. There are also security and denial-of-service implications. A malicious peer can start flooding the network with a number of requests disproportionate to the true size of the user base. This can interrupt the network and reduce its effectiveness. Also, simple broadcast is only viable in small networks. Selective BroadcastA variation on simple broadcast is selective broadcast. Instead of sending a request to every peer on the network, peers are selected based on heuristics such as quality of service, content availability, or trust relationships. However, this type of broadcast requires that you maintain historical information on peer interactions. Discovery requests are sent to selected peers, and the response is evaluated against the criteria that you have defined for peer connections. For instance, you might only send discovery requests to peers that support a certain minimum bandwidth requirement. Or you might send requests for resources only to peers likely to have that content. Of course, the more you need to know about the participants, the less dynamic the system can become. This can quickly eliminate the benefits of P2P if fixed and static relationships are not mitigated through some mechanism. Security is still a concern with selective broadcast. It is important that each one of the peers be reputable for this operation to be effective. Adaptive BroadcastLike selective broadcast, adaptive broadcast tries to minimize network utilization while maximizing connectivity to the network. Selection criteria can be augmented with knowledge of your computing environment. For instance, you can set the amount of memory or bandwidth you will consume during discovery operations. You can limit the growth of discovery and searching by predefining a resource tolerance level that if exceeded will begin to curtail the process. This will ensure that excessive resources are not being consumed because of a malfunctioning element, a misguided peer, or a malicious attack. Adaptive broadcast requires monitoring resources, such as peer identity, message queue size, port usage, and message size and frequency. Adaptive broadcast can reduce the threat of some security breaches, but not all. Resource IndexingFinding resources is closely tied to finding peers. However, the difference is that peers have intelligence; they are processes capable of engaging in digital conversations through a programming interface. A resource is much more static, and only requires identity. Discovering resources can be done using centralized and decentralized indexing. Centralized indexes provide good performance, at a cost. The bandwidth and hardware requirements of large peer networks can be expensive. Centralized indexes hit the scalability wall at some point, regardless of the amount of software and hardware provided. Decentralized index systems attempt to overcome the scalability limitations of centralized systems. To improve performance, every document or file stored within the system is given a unique ID. This ID is used to identify and locate a resource. IDs easily map to resources. This approach is used by FreeNet. The drawback to this approach is that searches have to be exact. Every resource has a single and unique identifier. Another problem with decentralized indexing systems is keeping cached information consistent. Indexes can quickly become out of sync. Peer networks are much more volatile, in terms of peers joining and leaving the network, as well as the resources contained within the index. The overhead in keeping everything up to date and efficiently distributed is a major detriment to scalability. Because peer networks are so volatile, knowing when a peer is online is required to build efficient and user-centric distributed systems. P2P systems use the term presence, and define it as the ability to tell when a peer or resource is online. The degree to which this situation affects your environment is application-dependent; however, you must understand the implications. Node AutonomyP2P systems are highly decentralized and distributed. The benefits of distribution are well-known. You generally distribute processing when you need to scale your systems to support increased demand for resources. You also distribute for geographic reasons, to move resources and processes closer to their access point. Other reasons to distribute are to provide better fault resistance and network resilience, and to enable the sharing of resources and promote collaboration. Decentralization gives rise to node autonomy, and in a peer-to-peer system, peers are highly autonomous. Peers are independent and self-governing. As mentioned, in a client/server model, the server controls and manages the relationship clients have with resources, such as databases, files, networks and other clients. This has many advantages in the operation, administration, and management of a computing environment. One of the advantages of centralization is central administration and monitoring. Knowing where resources are and how they are behaving is a tremendous advantage. Resources can be secured and administered from a central location. Functionality can be deployed to complement the physical structure of the network topology. For instance, servers can act as gatekeepers to sensitive technology assets. With decentralization comes a number of significant challenges: The management of the network is much more difficult. In a distributed environment, failures are not always detected immediately. Worse yet, partial failures allow for results and side effects that networks and applications are not prepared to deal with. Response time and latency issues introduced as a result of remote communication can be unpredictable. The network can have good days and bad days. Peer-to-peer interaction can become unstable as error paths and timeouts get triggered excessively. Synchronization often strains available bandwidth. Any solution that is based on distribution should be able to eliminate or mitigate these issues. P2P systems are built under the assumption that services are distributed over a network, and that the network is unreliable. How P2P systems cope with unreliable networks differentiates one system from another. Peer of EqualsPeers in a peer-to-peer system have the capability to provide services and consume services. There is no separation of client versus server roles. Any peer is capable of providing a service or finding a peer that can provide the service requested. A peer can be considered a client when it is requesting a service, and can be considered a server when it is providing a service. Peers are often used in systems that require a high level of parallelism. Parallelism is not new to computing. In fact, much of what we do in computing is done in parallel. Multiprocessor machines and operating systems rely on the capability to execute tasks in parallel. Threads of control enable us to partition a process into separate tasks. However, to date, parallelism has not been the norm in application development. While applications are designed to be multithreaded, this generally has involved controlling different tasks required of a process, such as reading from a slow device or waiting for a network response. We have not defined many applications that run the same tasks in parallel, such as searching a large database, or filtering large amounts of information concurrently. Parallelism can provide us with a divide-and-conquer approach to many repetitive tasks. The SETI@Home project demonstrated that personal computers could be harnessed together across the Internet to provide extraordinary computing power. The Search for Extraterrestrial Intelligence project examines radio signals received from outer space in an attempt to detect intelligent life. It takes a vast amount of computing power to analyze the amount of data that is captured and the computations involved. People volunteered for the project by downloading a screensaver from the SETI Web site. The screensaver was capable of requesting work units that were designed to segment the mass amount of radio signals received. In the first week after the project launched, more than 200,000 people downloaded and ran the software. This number grew to more than 2,400,000 by the end of 2000. The processing power available as a result of this network outpaced the ASCI White developed by IBM, the fastest supercomputer built at the time. P2P systems are designed to meet this growing trend in divide-and-conquer strategies. The SETI project is typical of system architectures that require a certain degree of centralization or coordination. Networks can be classified by their topology, which is the basic arrangement of nodes on the network. Different types of network configurations exist for network designers to choose from. A decentralized topology is often augmented with a centralized component, which creates a mixed model, or hybrid architecture. With Napster, it's the centralized file index component that's capable of identifying and locating files. With SETI, it's the centralized task dispatcher that allocates work units. Supporting Mixed ModelsMany P2P technologies are now adopting a network-based computing style that supports a mixed model. The predominant decentralized model is augmented with centralized control nodes at key points. The architectures define central control points for improving important performance characteristics of P2P systems, such as discovery and content management. Hybrid architectures can also enhance system reliability and improve the fault tolerance of systems. Let's review network topologies in order to understand the implications for P2P systems. This will also serve to highlight that there are many alternatives and design options to building P2P systems one size does not fit all. Nelson Minar of MIT and co-founder of Popular Power, recommends we look at topologies from a logical perspective, rather than physical. In other words, use these patterns as a descriptive technique for information flow, rather than for physical cabling. Five common topologies will be explained here:
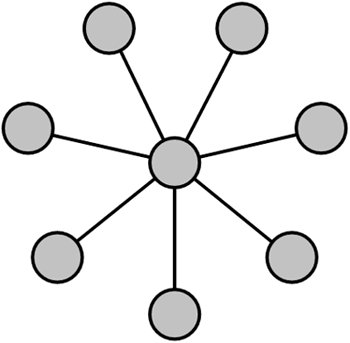
Star TopologyThe star network connects each device or node to a central point of control. All traffic in the network flows through this central point. A star network is usually easier to troubleshoot than most topologies. Figure 1.3 shows a typical configuration for client/server systems. Figure 1.3. A star network topology has a central point of communication control.
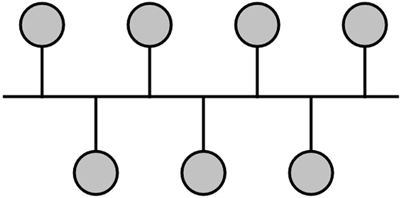
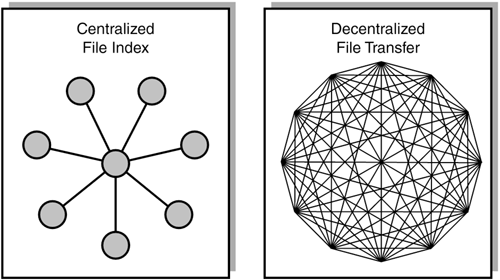
The Napster file index resembled a star topology. Of course, having a central access or control point exposes a potential single point of failure, which might have catastrophic consequences in a P2P network. Bus TopologyA bus topology connects all devices or nodes to the same physical medium. There is no central control point, but rather a common backbone. The backbone is used to interconnect devices on the network, as seen in Figure 1.4. Figure 1.4. A bus network topology has no central point of communication control. Each node inspects the message to determine whether it's the intended destination.
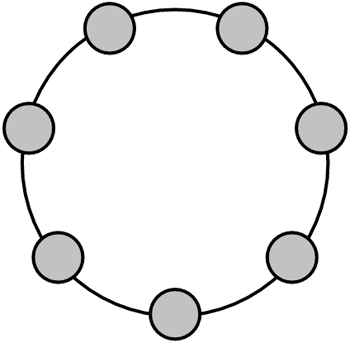
The bus topology does not have a central control point problem; however, a problem in the message bus can affect the entire network. Ring TopologyIn a ring topology, each device or node is connected to two other nodes, forming a loop, as in Figure 1.5. Data is sent from node to node around the loop in the same direction until it reaches its destination. Rings tend to have a predictable response time, because the distance a request must travel is consistent. Figure 1.5. A ring network topology has no central point of communication control. Messages pass from one node to the next until the receiver is found.
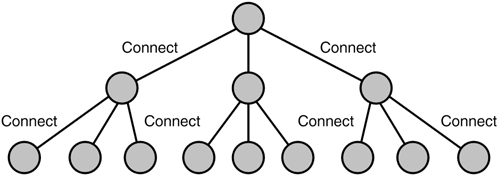
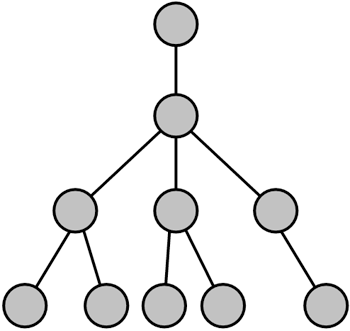
Ring networks still suffer from the problem of a single node malfunction disrupting the entire network. Hierarchical TopologyA hierarchical network like the one shown in Figure 1.6 is similar to a cascading star topology. In other words, many nodes are connected to single nodes that in turn connected to other single nodes. These networks form parent child relationships or resemble inverted trees. Figure 1.6. A hierarchical network topology resembles a tree. The nodes above each node act as a central point of control for nodes directly below. This resembles the DNS structure of an inverted tree.
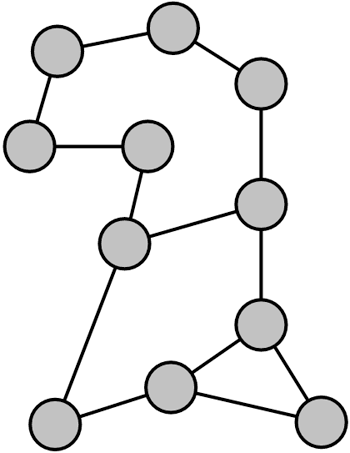
Mesh TopologyA mesh topology such as the one seen in Figure 1.7 requires all network devices or nodes to have dedicated paths to all other devices on that network. Figure 1.7. A mesh network topology resembles the Internet routing topology.
These networks typically exhibit resilience because more than one pathway exists between nodes. However, the fault tolerance is dependent on the integrity of the pathways. Gnutella is probably the most "pure" mesh system used in practice today, states Minar, with only a small centralized function to bootstrap a new host. Many other file sharing systems are decentralized, such as Freenet. Mixed ModelsMost of the systems that we will investigate are far more complex than the simple topologies referenced in this section. However, systems are often composed of multiple topologies that complement and extend one or more network patterns. In Napster for example, there is a centralized file index node, but the file transfer or exchange resembles the point-to-point network of a meshed topology (see Figure 1.8). Figure 1.8. Napster represents a P2P hybrid topology in which certain functions are centralized, while others are highly decentralized.
In addition, you can begin to map these patterns to key components or services in your P2P architecture. For instance, to build in fault tolerance and redundancy in your centralized file index, you can implement a ring topology. Each node in the ring serves as an access point to the index structure. If you lose connectivity to one index node, another node is there to service your request. This is a common failover technique. This works well for simple search applications; however, supporting transactional systems can involve a significant amount of complexity. Minar states that "there are many possibilities in combining various kinds of architectures. Topology is a useful simplifying tool in understanding the architecture of distributed systems," in his article on distributed systems at www.openp2p.com/pub/a/p2p/2001/12/14/topologies_one.html. Mapping key services into one or more communication models can highlight service constraints, vulnerabilities, and weaknesses in system design. The different topologies can be used as an evaluation aid in determining those strengths and weaknesses. Key measures to consider when building P2P systems include extensibility, information coherence, and fault tolerance. |