 
This hack is a little different. It shows you how to convert plain text to XML using Dave Pawson's Java program, Uphill. Along the way, Dave also explains how and why he developed the software, which may be helpful for those developing their own text-to-XML packages in Java. Text without any formatting is boring and repetitive to mark up XML just the sort of problem that a computer is good at, except that most text is not regular, which is the cost side of automation. I decided to try to create a solution in which the cost would be less for any automated solution over a by-hand conversion. That's why I wrote Uphill (http://www.dpawson.co.uk/java/uphill/), a Java program for converting plain text into XML. The goal for the program was to output a new file containing the XML markup for headings, paragraphs, and acronyms (needed for Braille output). First, I prototyped a solution with Python (http://www.python.org/) because Python has dictionaries that can be preloaded. I had a list of acronyms that I quickly converted into a Python structure to initialize a dictionary. The match I used was: if acrs.has_key(str[i:i+4]):
I walked the input string, testing for four-letter, then three-letter, then two-letter acronyms. It worked, and though it was weak, it gave me enough confidence to move on. A line from my acronym file looks like this: USA:<acr>USA</acr>
That is, the acronym USA is marked up with the acr tag. I realized that some acronyms may be generalized. If the first two letters can be captured, any remaining uppercase letters were probably a part of the acronym. I came up with this as an entry: BD:*
This tells me that if I spot BD, I can keep on looking for more uppercase letters, up until a terminal. 2.10.1 Trying It Out Download, unzip, and install Uphill in the working directory. Type this command: java -jar uphill.jar
You will then see this usage information: No Input File available; Quitting Uphill 1.2 from Dave Pawson Usage: java Uphill [options] {param=value}... Options: -a filename Take Acronyms from named file -o filename Send output to named file -i filename Take text input from named file -s filename State machine input from named file -t Display version information -? Display this message
There are sample files in Uphill's src directory (in the ZIP archive). One is shown below. You can use them to produce some output with this command: java -jar uphill.jar -a src/acronyms.txt -i src/test.txt -s src/state.txt -o test.xml
The program outputs this report: ChxState: Using 1 ChxState: Using 1 ChxState: Using 0 ChxState: Using 0 ChxState: Using 2 ChxState: Using 1 ChxState: Using 2 ChxState: Using 2 ChxState: Using 0 ChxState: Using 1 ChxState: Using 0 ChxState: Using 1 Done; Output written to file
The resulting file should look like this: <?xml version="1.0" encoding="utf-8"?> <!-- Uphill 1.2 from Dave Pawson --> <dtbook> <head> <title>Main title</title> <link style="text/css" href="location.css"/> <meta name="dc:author" content="Uphill"/> </head> <book> <frontmatter> <docauthor></docauthor> <doctitle></doctitle> </frontmatter> <bodymatter><dtbook> <p>A starter para</p> <p>Para < we need to talk! I would prefer, if at all possible to take some time out beforethe end of the year to do this as I would want to concentrate on my new role from January (we'll need someContinuationPara. time to go into each project in enough detail). You also need to talk to Tony re project proioritisation.</p> <h2>Head. this to test SHAKESPEARE <acronym>SH</acronym> <acronym>ATW </acronym> <acronym>ATW</acronym>xxx acronym markup Stood (stood) </h2> <p>Para. this to test shakespeare sh atw atwxxx acronym markup</p> <h2>Heading by itself</h2> <h2>Testing block structure. This is a headingthis is a heading continuation</h2> <p>This is a paraThis is the same para continued</p> <p>this is another para</dtbook> </bodymatter> </book> </dtbook>
2.10.2 How the Code Works The following explanations are for Java programmers who might be interested in how the code works. Uphill's acronyms class builds the hash table of acronyms from a plain-text file of the format mentioned in the previous section, and provides get() and test() methods to retrieve and test for the presence of an acronym in the table. The main method allowed easy testing of this class in isolation. I then moved on to a quick port to Java, and new thoughts about the markup of paragraphs. I realized that the software needed to be state-aware if it was to differentiate between a paragraph and a heading. My state diagram looked something like Figure 2-23. Figure 2-23. Uphill state diagram 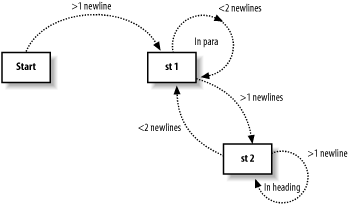
The number of linefeed characters determines the state change I decided to use: one newline between paragraphs, and more than one newline to change state to a heading. Thus, having two successive headings would require two newline separators. A later development enabled me to abstract this into a separate class that implements the state table. Although the trigger is hardcoded, the state is defined by an external text file, which has a format for an example input document with markup as shown below. It shouldn't be hard to generalize it even more. # StateTable for 'AS you like it: Shakespeare' # Format is # currentState : InputCountofNewLineChars : OutPutString : NextState # Note that no additional spaces are allowed. # Note, output string, n represents newLine character # para = state 1 0:1:n<p>:1 1:1:</p>n<p>:1 1:0::1 1:2:</p>n<h2>:2 # head = state 2 2:0::2 2:1:</h2>n<p>:1 2:2:</h2>n<h2>:2
Comments are preceded by the # symbol. Otherwise, each line represents four colon-delimited fields: a state transition from current state; trigger conditions detected, in this case a count of newline characters (minimum); an output string; and the new state. States are represented by integer values. In order to obtain nicely formatted XML output, I used the character n to represent a newline character. For example, the line: 2:2:</h2>n<h2>:2
represents a state change from state 2 (heading), with a trigger of two or more occurrences, the output string, and the new state (again 2). In addition to the state table, there are two other pieces used for managing state: stateTable.java codes the state, and state.java loads and implements the state transitions through the methods initStateTable and chxState. 2.10.2.1 The markup class This class does the bulk of the work. It holds the state machine variable, which keeps track of the state. The prFile() method processes each line of the file one at a time, first counting newline characters (remember this is a plain-text file), and then using the prLine() method to process the line. The process line method, prLine( ), first replaces any characters that need escaping for XML (ampersand and less-than symbols) with their entity values. Acronyms are replaced with their markup, using the findAcrs() method. The state is updated and any required markup is generated using the chxState() method. Support routines are needed for whitespace treatment and to replace an acronym once detected. 2.10.2.2 The uphill class The main class is used for the command-line interface. It provides a usage method, validation for input parameters, and calls on the version class (which records the software version). The produceXML() method writes out the XML header and any wrappers needed. The example uses heading material for the DAISY book format (http://www.daisy.org) for which I developed this software. 2.10.3 Summary The basic approach seems viable, and presents a tradeoff between using an XML editor to mark up bare text and reformatting plain text by inserting newline characters. I find the latter to be less work on a large file. I'm certainly gaining benefit from the acronym markup, and using the XML editor that I do, it's very easy both to add structure to the file and to change markup tags (e.g., replace paragraph tags with list tags), rather than mark up plain text within a well-formed document. This is probably a case of choosing the right XML editor, since not all editors support working with partially well-formed and occasionally invalid documents. There are still a few things to do. The state table is too closely linked to the output text generated by a state change, but this isn't hard to uncouple. There are probably one or two areas where greater generalization is possible, but I've not found them yet, and since I'm not working with an XML-aware tool, they may prove more trouble than they are worth. I'll leave it until the need is greater. So far, I've created a small tool that helps me do a job. I hope you've learned a little from it and maybe even found it useful, too. 2.10.4 See Also Chaperon converts structured text to XML using Java; it provides a lexical scanner, a parser generator, a parser, a tree builder, and an XML generator: http://chaperon.sourceforge.net/
Dave Pawson |