Document Navigation
| only for RuBoard |
One of the primary benefits of the XmlDocument class is that you can easily navigate through its contents. Whereas the XmlReader implementations are forward only and non-cached, the XmlDocument allows forward and reverse navigation, as well as querying.
Navigating with XmlNode
The XmlNode object provides methods for navigating the document. As you saw in the section, "XmlNode," you can navigate the nodes in the DOM by using the ChildNodes collection, and you can iterate the attributes using a For Each loop with the Attributes collection. You can also use NextSibling , FirstChild , ParentNode , and PreviousSibling properties in a similar manner. Listing 6.8 demonstrates using these properties to navigate through a document.
Listing 6.8 The Use of Context Nodes and Navigation
private void Page_Load(object sender, System.EventArgs e) { StringBuilder sb = new StringBuilder(); sb.Append("<BULLDOGS xmlns=\"urn:uga:bulldogs\">"); sb.Append("<NICKNAME>Hairy Dawgs</NICKNAME>"); sb.Append("<ANNOUNCER>Larry Munson</ANNOUNCER>"); sb.Append("</BULLDOGS>"); XmlDocument doc = new XmlDocument(); doc.LoadXml(sb.ToString()); DisplayContext(doc); //Document node XmlNode node = doc.DocumentElement; DisplayContext(node); //BULLDOGS node = node.ChildNodes[0]; DisplayContext(node); //NICKNAME node = node.NextSibling; DisplayContext(node); //ANNOUNCER node = node.ChildNodes[0]; DisplayContext(node); //#Text - Larry Munson node = node.ParentNode.ParentNode; DisplayContext(node); //BULLDOGS } private void DisplayContext(XmlNode node) { Response.Write("Context node is " + node.Name + " with type " + node.NodeType ); if (node.Value != null) { Response.Write( " and value " + node.Value); } Response.Write("<br>"); } Besides navigating by using the preceding methods, the XmlDocument class also supports XPath queries through the SelectNodes and SelectSingleNode methods. In Listing 6.9, we alter the Bulldogs example to show querying using XPath. The code shows how you can use XPath to navigate through an XML document.
Listing 6.9 Using XPath to Navigate Through an XML Document
<%@ Page language="c#" Debug="true"%> <%@ Import Namespace="System.Xml"%> <%@ Import Namespace="System.Text"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" > <html> <head> <title>WebForm1</title> <meta name="GENERATOR" Content="Microsoft Visual Studio 7.0"> <meta name="CODE_LANGUAGE" Content="C#"> <meta name=vs_defaultClientScript content="JavaScript"> <meta name=vs_targetSchema content="http://schemas.microsoft.com/intellisense/ie5"> <link rel="stylesheet" href="SystemXML.css" > </head> <body MS_POSITIONING="GridLayout> <script language="C#" runat="server" > private void Page_Load(object sender, System.EventArgs e) { StringBuilder sb = new StringBuilder(); sb.Append("<BULLDOGS>"); sb.Append("<NICKNAME>Hairy Dawgs</NICKNAME>"); sb.Append("<ANNOUNCER>Larry Munson</ANNOUNCER>"); sb.Append("<HIGHLIGHTS>"); sb.Append("<GAME DESCRIPTION=\"Beat Tennessee at Tennessee\"/>"); sb.Append("<GAME DESCRIPTION=\"Comeback versus Kentucky\"/>"); sb.Append("</HIGHLIGHTS>"); sb.Append("</BULLDOGS>"); XmlDocument doc = new XmlDocument(); doc.LoadXml(sb.ToString()); String expression = ""; expression = "descendant-or-self::*"; DisplayXPathResults(expression,doc.SelectNodes(expression)); expression = "BULLDOGS/NICKNAME"; DisplayXPathResults(expression,doc.SelectSingleNode(expression)); expression = "BULLDOGS/HIGHLIGHTS/GAME/@DESCRIPTION"; DisplayXPathResults(expression,doc.SelectNodes(expression)); expression = "BULLDOGS/HIGHLIGHTS/GAME[@DESCRIPTION='Beat Tennessee at  Tennessee']"; DisplayXPathResults(expression,doc.SelectSingleNode(expression)); } private void DisplayXPathResults(string expression, XmlNodeList nodeList) { Response.Write("<h3>" + expression + " yields: </h3>"); foreach(XmlNode node in nodeList) { Response.Write(node.Name + " (" + node.NodeType + ")"); if (node.Value != null) { Response.Write( " = " + node.Value); } Response.Write("<br>"); } } private void DisplayXPathResults(string expression, XmlNode node) { Response.Write("<h3>" + expression + " yields: </h3>"); Response.Write(node.Name + " (" + node.NodeType + ")"); if (node.Value != null) { Response.Write( " = " + node.Value); } Response.Write("<br>"); } </script> </body> </html>
Tennessee']"; DisplayXPathResults(expression,doc.SelectSingleNode(expression)); } private void DisplayXPathResults(string expression, XmlNodeList nodeList) { Response.Write("<h3>" + expression + " yields: </h3>"); foreach(XmlNode node in nodeList) { Response.Write(node.Name + " (" + node.NodeType + ")"); if (node.Value != null) { Response.Write( " = " + node.Value); } Response.Write("<br>"); } } private void DisplayXPathResults(string expression, XmlNode node) { Response.Write("<h3>" + expression + " yields: </h3>"); Response.Write(node.Name + " (" + node.NodeType + ")"); if (node.Value != null) { Response.Write( " = " + node.Value); } Response.Write("<br>"); } </script> </body> </html> Notice that both the SelectNodes and SelectSingleNode methods are being used to retrieve data based on the XPath expression. The DisplayXPathResults method is overloaded: When using the SelectNodes method, the first overload is called. When using SelectSingleNode to query the document, the second overload is called instead.
Navigating Using SelectNodes and SelectSingleNode
When you use a namespace in your document, the nodes within the scope of the namespace need to be qualified when using the SelectNodes and SelectSingleNode methods.
For example, look at the following XML document, xmlfile1.xml :
<?xml version="1.0" encoding="utf-8"?> <COLLEGES xmlns="urn:schools:universities"> <COLLEGE STATE="Georgia"> <NAME>University of Georgia</NAME> <NAME xmlns="urn:schools:abbreviations">UGA</NAME> <MASCOT xmlns="urn:schools:data">Bulldog</MASCOT> </COLLEGE> </COLLEGES>
If you attempt the following code using the xmlfile1.xml previously shown, it does not output the text UGA to the debug window as expected. In fact, it throws an error because the XmlNode object returned from the SelectSingleNode method is a null reference (nothing in Visual Basic):
Imports System.Xml Imports System.Diagnostics Public Class XmlDocNamespaces Inherits System.Web.UI.Page Private Sub Page_Load(ByVal sender As System.Object, ByVal e As System.EventArgs)
Why is this? Blame it on your use of namespaces. Three namespaces are represented in xmlfile1.xml , and no namespace prefixes are associated with any of them. To query this document, you must specify the namespaces and a prefix that you can use to identify each namespace URI within the XPath expression. Do this by using the XmlNamespaceManager object.
The XmlNamespaceManager object simply manages a list of namespaces that is associated with a given document. It atomizes the namespace prefix and namespace URI to be used in comparison with the namespaces in the document itself, as shown in the following code:
Imports System.Xml Imports System.Diagnostics Public Class XmlDocNamespaces Private Sub Page_Load(ByVal sender As System.Object, ByVal e As System.EventArgs)
By using the XmlNamespaceManager class, you add the namespace URIs to the class and associate a prefix with each namespace. Then, the XPath query is changed in the SelectSingleNode to use the new prefix that's associated with each namespace URI, and the namespace manager is passed in as well, like this:
Dim node As XmlNode = doc.SelectSingleNode("univ:COLLEGES/univ:COLLEGE/abbrev:NAME/text()", nsmgr) Debug.WriteLine(node.Value) End Sub End Class Again, using xmlfile1.xml , this code returns the proper text node, and outputs the string UGA to the output window as expected.
Navigating with XmlNavigator
Besides the methods exposed by the XmlNode class (and inherited by the XmlDocument class), you can use the XPathNavigator class to navigate the XmlDocument class.
The XPathNavigator class provides the ability to use XPath queries over any data store. It uses a read-only cursor over the data store, so you cannot use the XPathNavigator class to update nodes. However, the class provides an efficient means of querying data. Besides issuing XPath queries (as you can already do with the XmlDocument class' SelectSingleNode and SelectNodes methods), XPathNavigator provides the means to test whether the current node matches an XPath query, to execute compiled queries, and to compare the current navigator against another.
To navigate an XML document, create an XPathNavigator and iterate over its results by using an XPathNodeIterator . You need to create an XML file, samples.xml , in the same directory to make the code for this sample work correctly. Listing 6.10 shows the code used to iterate the results.
Listing 6.10 Using XPathNodeIterator and XPathNavigator
<%@ Page language="c#" Debug="true"%> <%@ Import Namespace="System.Xml"%> <%@ Import Namespace="System.Xml.XPath"%> <%@ Import Namespace="System.Text"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" > <html> <head> <title>WebForm1</title> <meta name="GENERATOR" Content="Microsoft Visual Studio 7.0"> <meta name="CODE_LANGUAGE" Content="C#"> <meta name=vs_defaultClientScript content="JavaScript"> <meta name=vs_targetSchema content="http://schemas.microsoft.com/intellisense/ie5"> <link rel="stylesheet" href="SystemXML.css" > </head> <body MS_POSITIONING="GridLayout"> <script language="C#" runat="server" > private void Page_Load(object sender, System.EventArgs e) { XmlDocument doc = new XmlDocument(); doc.Load(Server.MapPath("sample.xml")); XPathNavigator nav = doc.CreateNavigator(); XPathNodeIterator iterator = nav.SelectDescendants(XPathNodeType.All, true); Response.Write("<table>"); Response.Write("<tr>"); Response.Write("<th>NodeType</th>"); Response.Write("<th>LocalName</th>"); Response.Write("<th>Prefix</th>"); Response.Write("<th>NamespaceURI</th>"); Response.Write("<th>Value</th>"); Response.Write("</tr>"); while (iterator.MoveNext()) { WriteNavigator(iterator.Current); } Response.Write("</table>"); } private void WriteNavigator(XPathNavigator current) { Response.Write("<tr>"); WriteTD(current.NodeType.ToString()); WriteTD(current.LocalName); WriteTD(current.Prefix); WriteTD(current.NamespaceURI); WriteTD(current.Value); Response.Write("</tr>"); } private void WriteTD(String cellData) { Response.Write(String.Concat("<td>", cellData , "</td>")); } </script> </body> </html> This example begins by using the CreateNavigator method of the XmlDocument class to create the navigator class. This method is exposed through the IXPathNavigable interface, which has only the CreateNavigator method as a member. This interface is implemented by the XmlNode object, from which the XmlDocument object inherits. The implication of this is that any object inheriting from XmlNode , such as what we saw in Figure 6.3, supports the CreateNavigator method. The XpathDocument object also supports the IXPathNavigable interface, which means it supports the CreateNavigator method as well.
This example uses the SelectDescendants method with a Boolean true, which indicates that you want a deep query. This has the same effect as issuing the following XPath query:
descendant-or-self::*
The SelectDescendants method of the XPathNavigator returns an XPathNodeIterator object. This class is optimized to iterate over a set of nodes. It also provides a set of methods to navigate further through the returned nodes.
You can use the MoveNext method of the XPathNodeIterator to iterate through the node set returned by the XPath query. For each accessed node, you use the Current method to return a new XPathNavigator object to access the properties of the current node. Table 6.9 shows the properties of the XPathNavigator class.
Table 6.9. Properties of the XPathNavigator Class
| Property Name | Description |
|---|---|
| BaseURI | Retrieves the base URI of the node, which indicates from where the node was loaded. |
| HasAttributes | Retrieves a Boolean that indicates if the current node has any attributes. |
| HasChildren | Returns a Boolean that indicates if the current node has any child nodes. The root can have element, comment, or processing instruction child nodes. An element can have element, text, comment, whitespace, or significant whitespace child nodes. Any other node type cannot have child nodes. |
| IsEmptyElement | Indicates if the current node is an empty element, such as <Customers/> . |
| LocalName | Gets the name of the current node without a namespace prefix. |
| Name | Gets the qualified name of the current node. |
| NamespaceURI | Gets the namespace URI of the current node. |
| NameTable | Gets the XmlNameTable associated with this implementation. |
| NodeType | Returns the XmlNodeType of the current node. Use the ToString method to return its text representation. |
| Prefix | Gets the namespace prefix associated with the current node. |
| Value | Gets the value of the current node. If the current node is an element whose child elements have child text nodes, the text of the descendant nodes is returned as a concatenated string. |
| XmlLang | Gets the xml:lang scope for the current node. |
Look at the HasChildren property description in Table 6.9. Attribute nodes are not considered child nodes. The example in Listing 6.10 does not return the attributes for the current node. For this reason, you have to explicitly retrieve the attributes from the XPathNavigator by using the MoveToFirstAttribute method to move to the first attribute, then iterate through the attributes using the MoveToNextAttribute method, like this:
private void Page_Load(object sender, System.EventArgs e) { XmlDocument doc = new XmlDocument(); doc.Load(Server.MapPath("sample.xml")); XPathNavigator nav = doc.CreateNavigator(); XPathNodeIterator iterator = nav.SelectDescendants(XPathNodeType.All, true); Response.Write("<table>"); Response.Write("<tr>"); Response.Write("<th>NodeType</th>"); Response.Write("<th>LocalName</th>"); Response.Write("<th>Prefix</th>"); Response.Write("<th>NamespaceURI</th>"); Response.Write("<th>Value</th>"); Response.Write("</tr>"); while (iterator.MoveNext()) { WriteNavigator(iterator.Current); if (iterator.Current.MoveToFirstAttribute()) { WriteNavigator(iterator.Current); while(iterator.Current.MoveToNextAttribute()) { WriteNavigator(iterator.Current); } iterator.Current.MoveToParent(); } } Response.Write("</table>"); } The MoveToParent method was used to move from the attributes back to the parent element. This seems to contradict the fact that attributes are not considered child nodes, yet elements are parent nodes of elements. But, you need to call the MoveToParent method to navigate back to the element; otherwise , you can not properly access all the nodes.
Table 6.10 details the MoveToParent method and the other methods of the XPathNavigator class.
Table 6.10. Methods of the XPathNavigator Class
| Method Name | Description |
|---|---|
| Clone | Creates a new XPathNavigator positioned at the same node as this XPathNavigator . |
| ComparePosition | Compares the position of the current XPathNavigator with the position of the specified XPathNavigator . Returns XmlNodeOrder enumeration member ( Before , After , Same , Unknown ). |
| Compile | Compiles the XPath string expression and returns an XpathExpression object. |
| Equals | Determines if two object instances are equal. |
| Evaluate | Evaluates the given expression and returns the typed result. Use this to return strongly typed values ( numbers such as integer or double, Boolean, string, or node set). |
| GetAttribute | Returns the value of the attribute specified by the local name and namespace URI. If no namespace is associated with the attribute, specify String.Empty . The current node must be an element node that contains the attribute, or String.Empty is returned. |
| GetHashCode | Serves as a hash function for a particular type, suitable for use in hashing algorithms and data structures such as a hash table. |
| GetNamespace | Returns the value of the namespace node corresponding to the specified local name. |
| GetType | Gets the Type of the current instance. |
| IsDescendant | Returns a Boolean that indicates if the specified XPathNavigator is a descendant of the current XPathNavigator . |
| IsSamePosition | Returns a Boolean that indicates if the specified XPathNavigator is positioned the same as the current XPathNavigator . |
| Matches | Determines whether the current node matches the specified XSLT pattern. |
| MoveTo | Moves to the same position as the specified XPathNavigator. |
| MoveToAttribute | Moves to the attribute of the current node that has the local name and namespace URI specified. |
| MoveToFirst | Moves to the first sibling of the current node. |
| MoveToFirstAttribute | Moves to the first attribute. |
| MoveToFirstChild | Moves to the first child node. Refer to the HasChildren property description in Table 6.9 for information on child nodes. |
| MoveToFirstNamespace | Moves to the first namespace node with the specified local name. |
| MoveToId | Moves to the node with an ID attribute that has a value matching the specified string. |
| MoveToNamespace | Moves the XPathNavigator to the namespace node with the specified local name. |
| MoveToNext | Moves to the next sibling of the current node. Similar to the following-sibling XPath axis. |
| MoveToNextAttribute | Moves to the next attribute for the current node. |
| MoveToNextNamespace | Moves to the next namespace node. |
| MoveToParent | Moves to the parent node of the current node. Use this when accessing attributes to return to the containing element. |
| MoveToPrevious | Moves to the previous sibling of the current node. Similar to the preceding-sibling XPath axis. |
| MoveToRoot | Moves to the current node's root node. |
| Select | Returns an XPathNodeIterator that is used to iterate over the nodes returned by the given XPath expression. |
| SelectAncestors | Returns an XPathNodeIterator that is used to iterate over the ancestor nodes of the current node with the specified XmlNodeType . Accepts a Boolean parameter that indicates if the current node is also matched. Similar to the ancestor or ancestor-or- self XPath axis. |
| SelectChildren | Returns an XPathNodeIterator that is used to iterate over the child nodes of the current node with the specified XmlNodeType . Similar to the child XPath axis. |
| SelectDescendants | Returns an XPathNodeIterator that is used to iterate over the descendant nodes of the current node with the specified XmlNodeType . Accepts a Boolean parameter that indicates if the current node is also matched. Similar to the descendant or descendant-or-self XPath axis. |
| ToString | Gets the text value of the current node. Equivalent to calling the Value property. |
The XPathDocument Object
At the beginning of this section, we mentioned the XPathDocument class and the IXPathNavigable interface. XPathDocument provides yet another means of working with and querying XML data. The XPathDocument class is a fast, read-only cache for document processing using XSLT. It can, however, also be used to take advantage of its extremely fast XPath capabilities. In fact, according to Fadi Fakhouri, the Microsoft Core XML Framework project manager, the XPathDocument class gives an order of magnitude performance gain over other XPath implementations, such as XmlDocument.SelectSingleNode .
The XPathDocument object has few members . But, it is optimized for XPath querying and highly performant because it does not maintain node identity (notice that it has no properties, unlike the XmlReader and XmlDocument classes) and does not perform rule checking that is required for the DOM implementation specified by the W3C.
Table 6.11 lists the methods of the XPathDocument class.
Table 6.11. Methods of the XPathDocument Class
| Method Name | Description |
|---|---|
| CreateNavigator | Creates a new XPathNavigator for this document. |
| Equals | Determines whether two object instances are equal. |
| GetHashCode | Serves as a hash function for a particular type, suitable for use in hashing algorithms and data structures, such as a hash table. |
| GetType | Gets the Type of the current instance. |
| ToString | Returns a String that represents the current Object . |
Looking at the available methods for the class, only one method is notable: the CreateNavigator method. This method simpy creates an XPathNavigator object for the data contained in the current document. This is so useful because of the way that the XPathDocument can be instantiated .
Remember that the XmlReader class supports forward-only access to its underlying data; it does not support random access to its nodes. Using XmlReader as the source of the XpathNavigator , however, allows you to run random-access queries against an XmlReader , the following example shows.
For this example, let's use a lengthy XML document called sample.xml , which is shown in Listing 6.11.
Listing 6.11 The sample.xml File
<?xml version="1.0" encoding="utf-8" ?> <Customers xmlns="urn:foo:bar"> <Customer id="ALFKI"> <CompanyName>Alfreds Futterkiste</CompanyName> <Contact> <FirstName>Maria</FirstName> <LastName>Anders</LastName> <Title>Sales Representative</Title> </Contact> </Customer> <Customer id="LOWES"> <CompanyName>Lowe's</CompanyName> <Contact> <FirstName>Keth</FirstName> <LastName>Bunn</LastName> <Title>Assistant Manager</Title> </Contact> </Customer> <Customer id="VELVE"> <CompanyName>The Velvet Room</CompanyName> <Contact> <FirstName>Rodney</FirstName> <LastName>Wade</LastName> <Title>Bar Manager</Title> </Contact> </Customer> <Customer id="GABST"> <CompanyName>Georgia's Best Pressure and Stain</CompanyName> <Contact> <FirstName>Steve</FirstName> <LastName>Durling</LastName> <Title>Owner</Title> </Contact> </Customer> <Customer id="VBDNA"> <CompanyName>Kirk Allen Evans Consulting, Inc.</CompanyName> <Contact> <FirstName>Kirk Allen</FirstName> <LastName>Evans</LastName> <Title>Owner</Title> </Contact> </Customer> </Customers>
You probably recognize much of this data: It comes from the Northwinds database that ships with Access and SQL Server. Now that you have a base document, look at how you can query this document. Listing 6.12 shows how to navigate the document by using XPathNavigator .
Listing 6.12 Navigating with XPathNavigator
<%@ Page Language="vb" Debug="true"%> <%@ Import Namespace="System.Xml"%> <%@ Import Namespace="System.Xml.XPath"%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head> <title>WebForm3</title> <meta name="GENERATOR" content="Microsoft Visual Studio.NET 7.0"> <meta name="CODE_LANGUAGE" content="Visual Basic 7.0"> <meta name=vs_defaultClientScript content="JavaScript"> <meta name=vs_targetSchema content="http://schemas.microsoft.com/intellisense/ie5"> <link rel="stylesheet" href="SystemXML.css"> </head> <body MS_POSITIONING="GridLayout"> <script language="visualbasic" runat="server" > Private Sub Page_Load(ByVal sender As System.Object, ByVal e As System.EventArgs)
This example almost mirrors the preceding example using the XPathNavigator object. The difference is how you create the XPathNavigator object using the XPathDocument.CreateNavigator method. The XPathDocument is created with an XmlTextReader as its source, which enables you to access nodes using XPath syntax over an XmlReader object.
Using the sample.xml file shown in Listing 6.11, the results of this example are shown in Figure 6.7.
Figure 6.7. The sample output shown when using the XPathNavigator .
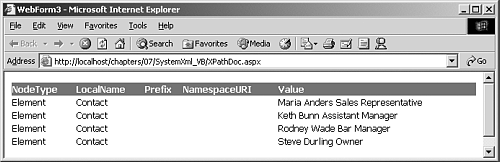
The Evaluate method was used to retrieve the node list from the XPath expression. However, you could also use the Evaluate method to return a strongly-typed value, as shown here:
Private Sub Page_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load Dim file As IO.FileStream = New IO.FileStream (Server.MapPath("sample.xml"), IO.FileMode.Open) Dim reader As XmlTextReader = New XmlTextReader(file) Dim xpathdoc As XPathDocument = New XPathDocument(reader, XmlSpace.Preserve) Dim nav As XPathNavigator = xpathdoc.CreateNavigator() Dim expression As XPathExpression = nav.Compile ("count(Customers/Customer/ Contact)") Dim contactCount as Integer = CType(nav.Evaluate(expression),Integer) Response.write ("The count of Contact nodes is " &contactCount.ToString()) reader.Close() file.Close() End Sub Here's the part that is really worth mentioning:You are not limited to a single expression evaluation. The following code is also legal:
Dim expression As XPathExpression = nav.Compile ("count(Customers/Customer/Contact)") Dim contactCount as Integer = CType(nav.Evaluate(expression),Integer) Dim expression As XPathExpression = nav.Compile ("Customers/Customer/Contact") Dim iterator As XPathNodeIterator = nav.Evaluate(expression) Notice that the evaluate expression was called twice, where the underlying data is provided by a forward-only XmlTextReader . This means that random access is provided to stream-based implementations, providing lightweight and performant operations for querying large XML documents.
You've seen how to populate an XmlDocument with data and how to navigate through the document. Now it's time to see how to manipulate the document's contents.
| only for RuBoard |
EAN: N/A
Pages: 184