XSLT
| only for RuBoard |
XSLT has begun to play a vital role in the adoption of XML. We no longer think of XML simply as data. With XSLT, we begin to think how to change that data into something more usable. XSLT enables you to transform XML documents into a variety of formats, such as HTML, XHTML, PDF, other XML documents, or even other XSLT documents. The majority of this chapter focuses on XSLT and its practical uses.
XSLT processes XML documents and transforms them into other documents. The term documents is used here because an XML document is simply a set of well- formed XML tags (refer to Chapter 1). Recall, however, that XML does not need to be stored in a file. You can use this technique to pull XML data from a variety of sources that might or might not be file based.
The XSL recommendation also makes use of the XPath recommendation. Before jumping into using XSLT, you need to get a firm grasp on XPath. Then you can use XPath and XSLT to process XML trees.
XPath
XML is simply markup for data. That's it. XML is not a magic wand; it does not specify how data is transmitted over the wire, it does not specify how data is stored. XML simply determines the format of the data: What you do with the data is up to you. That said, the real power behind XML is not solely its ability to represent data: XML's real power lies in ancillary technologies that, when combined with XML, provide robust solutions, and XPath is one of those ancillary technologies.
Version 1.0 of the XML Path Language became a World Wide Web Consortium (W3C) recommendation on November 16th, 1999. You can view the W3C recommendation for XPath 1.0 at http://www.w3.org/TR/xpath. This document shows all information relating to XPath including an overview of XPath and a description of its components .
XPath grew out of efforts to share a common syntax between XSL Transformations (XSLT) and XPointer. It allows for the search and retrieval of information within an XML document structure. XPath is not an XML syntax: rather, it uses a syntax that relates to the logical structure of an XML document.
An Analogy to SQL
Consider a relational database. Is the real power of a database the ability to simply store data, index the data, and specify relations between tables of data? After all, a database is supposed to hold data, so is the capability of persisting data the real advantage behind a relational database? If so, a simple file would suffice for this. It is easy to see that the real power of a database the ability to use Structured Query Language (SQL) statements to retrieve subsets of data. To take this example one step further, the fact that SQL is an ANSI standard makes your knowledge of SQL applicable to different databases running on different platforms.
Using this same logic, XML would simply be a format for data storage without a prescribed way of retrieving that data. This is exactly what XPath is: XPath is the query language for XML documents. XPath is the common name used for XML Path Language. Using XPath statements, you can retrieve complex subsets of data from XML documents using a syntax that is universal across implementations . The same XPath statements that work within the System.Xml and System.Xml.XPath namespaces should work exactly the same as XPath statements in the MSXML Parser, and both should work exactly the same as other parsers that implement the W3C XPath recommendation.
An Analogy to a File Path
Computers are built around files and the organization of those files. To access files, you need to be able to navigate to different portions of the file system. One way to navigate a file system is to use the Uniform Naming Convention (UNC) for specifying the location of resources on a local-area network (LAN). UNC separates folders and files using a backslash ( \ ) character. In the good ol' DOS days before point-and-click, file systems were navigated using command-line syntax. Go to the Start button on your computer; choose Run, and type cmd in the text box to bring up a DOS command shell window.
You will see the following text:
Microsoft Windows 2000 [Version 5.00.2195] (C) Copyright 1985-2000 Microsoft Corp. C:\>
At the command prompt, change directories from the C: root all the way to the Program Files\Microsoft Visual studio directory.
C:\>cd Program Files\Microsoft Visual Studio
To change directories, you specified a path for the file system to navigate. More to the point, you specified a series of location steps used to navigate to a new folder based on the current folder. XPath uses a very similar syntax. Imagine your file system as an XML document.
<?xml version="1.0" encoding="utf-8" ?> <C> <INETPUB> <WWWROOT> <ASPNET_CLIENT/> </WWWROOT> </INETPUB> <C>
We could easily represent this as an XPath statement:
C/INETPUB/WWWROOT/ASPNET_CLIENT
If we are currently positioned at the very beginning of the document there are four location steps made. But what if we were currently positioned on the WWWROOT element and wanted to reposition to the ASPNET_CLIENT element? We would specify the following XPath statement:
./ASPNET_CLIENT
The period ( . ) at the beginning of the XPath statement represents the expression "the context node", meaning the node that we originally started from. Instead of specifying that we are navigating based on the context node, we can also use a short form of XPath that specifies a path relative to the context node:
ASPNET_CLIENT
A location path is composed of 3 parts : the axis, the node-test, and zero or more predicates.
XPath Axis
The axis component of an XPath query determines the direction of the node selection in relation to the context node. An axis can be thought of as a directional query. The axes listed in Table 3.3 are provided in XPath.
Table 3.3. XPath Axes
| Axis | Description |
|---|---|
| ancestor | The context node's parent, the parent's parent, and so on. |
| ancestor-or-self | The context node as well as its ancestors . |
| attribute | The attributes of the context node. |
| child | All children of the context element (attributes cannot have children). |
| descendant | All descendants of the context: children, children's children, and so on. |
| descendant-or-self | All descendants as well as the context node. |
| following | All nodes in the same document as the context node that are after the context node. This does not include descendants, attribute nodes, or namespace nodes. |
| following-sibling | All the following siblings of the context node. A sibling is an element occurring at the same level in the tree. |
| namespace | The namespace nodes of the context node. |
| parent | The parent of the context node. |
| preceding | All nodes in the same document as the context node that are immediately before the context node. |
| preceding-sibling | Contains the preceding siblings. If the context node is either an attribute or a name-space node, the preceding-sibling axis is empty |
The examples so far have used forward axes: that is, we have only navigated to nodes that are descendants of the context node. Let's look at some examples of XPath statements using reverse axes, or axes that navigate up the document hierarchy. Consider the following representation of a file system, with drives A, C, and D, and D has a backup copy of the contents of the C drive. The context node is highlighted. This document is represented in listing 3.8. Note that the line numbers are represented only for explanation and are not actually part of the XML document.
Listing 3.8 An XML Representation of a File System
1 <?xml version="1.0" encoding="utf-8" ?> 2 <FILESYSTEM> 3 <DRIVE LETTER="A"/> 4 <DRIVE LETTER="C"> 5 <FOLDER NAME="INETPUB"> 6 <FOLDER NAME="WWWROOT"> 7 <FOLDER NAME="ASPNET_CLIENT" /> 8 </FOLDER> 9 </FOLDER> 10 <FOLDER NAME="Program Files"> 11 <FOLDER NAME="Microsoft Visual Studio .NET"> 12 <FOLDER NAME="Framework SDK"> 13 <FOLDER NAME="BIN"></FOLDER> 14 </FOLDER> 15 </FOLDER> 16 </FOLDER> 17 </DRIVE> 18 <DRIVE LETTER="D"> 19 <FOLDER NAME="INETPUB"> 20 <FOLDER NAME="WWWROOT"> 21 <FOLDER NAME="ASPNET_CLIENT" /> 22 </FOLDER> 23 </FOLDER> 24 <FOLDER NAME="Program Files"> 25 <FOLDER NAME="Microsoft Visual Studio .NET"/> 26 </FOLDER> 27 </DRIVE> 28 </FILESYSTEM> Working with the preceding XML structure, we introduce the following XPath statement:
parent::*
This XPath query translates to "retrieve all parent nodes of the context node", which would return the element FOLDER on line 10.
ancestor-or-self::*
This query would return a more complex structure, which is depicted in listing 3.9. The returned nodes are highlighted.
Listing 3.9 An XML Representation of a File System
<?xml version="1.0" encoding="utf-8" ?> <FILESYSTEM> <DRIVE LETTER="A"/> <DRIVE LETTER="C"> <FOLDER NAME="INETPUB"> <FOLDER NAME="WWWROOT"> <FOLDER NAME="ASPNET_CLIENT" /> </FOLDER> </FOLDER> <FOLDER NAME="Program Files"> <FOLDER NAME="Microsoft Visual Studio .NET"> <FOLDER NAME="Framework SDK"> <FOLDER NAME="BIN"></FOLDER> </FOLDER> </FOLDER> </FOLDER> </DRIVE> <DRIVE LETTER="D"> <FOLDER NAME="INETPUB"> <FOLDER NAME="WWWROOT"> <FOLDER NAME="ASPNET_CLIENT" /> </FOLDER> <FILE NAME="test.xml" size="10 Kb"/> </FOLDER> <FOLDER NAME="Program Files"> <FOLDER NAME="Microsoft Visual Studio .NET"/> </FOLDER> </DRIVE> </FILESYSTEM>
As you can see in listing 3.8, a path is depicted from the context node directly to the root node, hence the name "XPath".
Our examples of axes used an axis with an accompanying asterisk. The asterisk is considered a wildcard that translates to "all nodes within the specified path". There are several special characters in XPath syntax, listed in Table 3.4.
Table 3.4. XPath Special Characters
| Axis | Description |
|---|---|
| / | When used at the beginning of an expression, selection begins at the root node. When used within an expression, it acts as a path separator. |
| // | Performs a recursive search for the matching pattern throughout the entire document. |
| . | The context node. |
| * | Wildcard operator. |
| @ | Prefix for an attribute name. |
| @* | Wildcard match for attributes. |
| : | Namespace separator. |
| ( ) | Grouping operator, for establishing logical precedence within statements. |
| [ ] | Predicate container (also referred to as a filter pattern container). See the following section, "Predicates" for more information on predicates. Also used in abbreviated notation as a subscript operator. |
| + | Addition operator. |
| Subtraction operator. | |
| div | Floating-point division operator. |
| * | Multiplication operator. |
| mod | Modulus operator. |
| = | Equality. |
| != | Inequality. |
| < | Less than. XSLT documents typically contain the < entity reference, but this is evaluated in the XSLT parser as < . |
| > | Greater than. XSLT documents typically contain the > entity reference, but this is evaluated in the XSLT parser as > . |
| <= | Less-than or equal to. |
| => | Greater-than or equal to. |
| and | Logical and. |
| or | Logical or. |
| not() | Boolean not. |
Location paths can be relative or absolute. Relative location paths consist of one or more location paths separated by backslashes. Absolute location paths consist of a backslash optionally followed by a relative location path. In other words, relative location paths navigate relative to the context node. Absolute paths specify the absolute position within the document. An absolute location path would then be:
/FILESYSTEM/DRIVE[@LETTER='C']/FOLDER[@NAME='Program Files']
Using an absolute location path, the current context node is ignored when evaluating the XPath query, except for the fact that the path being searched exists in the same document.
XPath Node Test
The XPath node test does just what its name implies: it tests nodes to determine if they meet a condition. We already used one test, the asterisk character, which specified all nodes should be returned. We can limit the nodes that are returned by specifying names . Using the document in listing 1 again, we want to retrieve all ancestor elements that are named DRIVE .
ancestor::DRIVE
By specifying the node name in the node test component of the XPath statement, we limit the results so that only a single node is returned, the DRIVE element on line 4.
Besides using names for node-tests, we can also use node types. In Table 3.4, we saw that one of the axes is an attribute axis, which retrieves an attribute based on the specified node test. Again, using the document in Listing 3.8, the following node test would return the attribute NAME for the context node (highlighted in Listing 3.8):
attribute::NAME
If we wanted to select all attributes for the context node, we could also issue a wildcard node test:
attribute::*
So, the type of node returned depends partially on the axes specified. Attributes are not children of elements, so using the following XPath statement would not return any nodes:
child::NAME
This is because there is no child element of the context node that is named NAME . We can also use XPath functions as node tests to return certain nodes. The available node tests are listed in Table 3.5.
Table 3.5. Available XPath Function Node Tests
| Axis | Description |
|---|---|
| comment() | Returns True if the matched node is a comment node. |
| node() | Returns True for any matched node, or False if no match was found. |
| processing-instruction() | Returns True if the matched node is a processing-instruction. |
| text() | Returns True if the matched node is a text node. |
Considering the analogy of an XPath statement to a SQL statement, we have looked at the equivalent in XPath to a SQL SELECT statement. Now, let's look at the equivalent to a SQL WHERE clause in XPath: the predicate.
XPath Predicates
Predicates filter the resulting node sets of an XPath query with respect to an axis, producing a new node set. A predicate is the logical equivalent of a WHERE clause in SQL: it filters the selection based on certain criteria. A predicate can be evaluated as a Boolean or a number. When evaluated as a number, nodes matching the positional number are returned, where the index of nodes is 1-based. Listing 3.10 shows the same document as in Listing 3.8, but highlights a new context node on line 18.
Listing 3.10 An XML representation of a file system
1 <?xml version="1.0" encoding="utf-8" ?> 2 <FILESYSTEM> 3 <DRIVE LETTER="A"/> 4 <DRIVE LETTER="C"> 5 <FOLDER NAME="INETPUB"> 6 <FOLDER NAME="WWWROOT"> 7 <FOLDER NAME="ASPNET_CLIENT" /> 8 </FOLDER> 9 </FOLDER> 10 <FOLDER NAME="Program Files"> 11 <FOLDER NAME="Microsoft Visual Studio .NET"> 12 <FOLDER NAME="Framework SDK"> 13 <FOLDER NAME="BIN"></FOLDER> 14 </FOLDER> 15 </FOLDER> 16 </FOLDER> 17 </DRIVE> 18 <DRIVE LETTER="D"> 19 <FOLDER NAME="INETPUB" READONLY="TRUE"> 20 <FOLDER NAME="WWWROOT"> 21 <FOLDER NAME="ASPNET_CLIENT" /> 22 </FOLDER> 23 <FILE NAME="test.xml" size="10 Kb"/> 24 </FOLDER> 25 <FOLDER NAME="Program Files"> 26 <FOLDER NAME="Microsoft Visual Studio .NET"/> 27 </FOLDER> 28 </DRIVE> 29 </FILESYSTEM> We can use predicates to filter results based on an expression, and the expressions allowed range from simple comparisons to complex expressions. We will begin by using simple filters and comparisons, and work up to more complex node-set functions.
Filters
Filters are a means of filtering a node set based on a condition. Filters and predicates are synonymous, except that filters provide an abbreviated syntax for node-tests. For instance, we may wish to filter based on the existence of a node within a query. An example of this is to filter based on the existence of an attribute. To do this, we simply provide the filter for the attribute:
child::FOLDER[@READONLY]
This statement retrieves only the FOLDER elements that are children of the context node (depicted on line 18) that contain an attribute named READONLY . This statement would return the FOLDER element on line 19. Similarly, we could retrieve only those children that have a specified child element:
child::*[FILE]
This statement returns only the FOLDER element on line 19: It is the only child of the context node that itself contains a child element called FILE .
Comparisons
Besides testing for the existence of nodes, we can also test the values of nodes. This statement retrieves a child element named FOLDER that contains an attribute named NAME with a value of INETPUB .
child::FOLDER[@NAME="INETPUB"]
The node returned from this statement would be the FOLDER element on line 19. Besides testing equality, we can also check for inequality:
child::FOLDER[@NAME != "INETPUB"]
This statement returns the child elements named FOLDER that do not have an attribute named NAME with a value of INETPUB .
We can also use the less-than and greater-than operators to evaluate numeric expressions. This statement queries using an absolute path from the root node to retrieve the list of drives that have no folders created in them:
/FILESYSTEM/DRIVE[count(FOLDER) = 0]
The less-than and greater-than operators are implemented for numeric use: for text comparisons, you should revert to the string XPath functions such as contains() or substring() .
As mentioned previously, predicates can be evaluated as a number or as a Boolean. Let's take a look at how we can use the relative position of a node within a predicate.
position()
The position() function returns the relative position (also referred to as an index) of the node within its parent. We can use the position function to simply retrieve a node by its ordinal position, or we can use it as a comparison.
Using the position() function in the XPath statement's predicate, we can return the FOLDER element on line 19 using the following XPath:
child::*[position() = 1]
The statement translates to "select all the children of the context node where the indexed position is 1". This statement simply retrieves the first child node of the context node. We can also use an abbreviated syntax to specify the same result:
child[1]
Besides using numeric position related to the context node, we can also use compound predicates to express complex Boolean results. The modulus operator is a common mechanism to test a value to see if it is even or odd. We can retrieve the even numbered child elements of the context node:
child::*[position() mod 2 = 0]
If we wanted to return only the last node, we can use the XPath function last() to test if the position of a node is the same as the position of the last node, returning the last node:
child::*[position()=last()]
Besides complex predicates, we can also specify complex location steps using axes, node tests, and predicates. If we wanted to find out all the drives on the current machine using the document in Listing 3.10, we could issue the following:
parent::FILESYSTEM/child::DRIVE
count()
Another common function used in predicates is the count() function. This function returns the count of nodes in the specified node-set.
FOLDER[count(child::*)=1]
This expression returns all FOLDERs that are children of the context node that have only one child element. We can use any of the axes to generate the node set used as the parameter to the count() function. For instance, we can retrieve the list of child FOLDER elements that are not the first child of the context node:
FOLDER[count(preceding-sibling::*)> 0]
Of course, there are many ways to approach the same statement: We have already seen the position() function can handle the equivalent statement:
FOLDER[position() != 1]
Abbreviated Location Path Syntax
Because XPath statements can become quite verbose, there also exists an abbreviated version of XPath statements. Using abbreviated syntax, the preceding XPath query is equivalent to:
parent::FILESYSTEM/DRIVE
Another abbreviation uses the backslash character to notate the root node of the document containing the context node. We saw this previously explained as an absolute location path. As an example, this XPath statement returns the FOLDER element on line 19.
/FILESYSTEM/DRIVE[@LETTER='D']/FOLDER[@NAME='INETPUB']
Using two backslashes successively indicates that the entire document should be searched recursively. This is a common misconception for developers used to UNC notation for working with directory paths. While useful in certain situations where an element pattern may occur anywhere in the current document, it is rarely used in this context.
//FOLDER[@NAME="INETPUB"]/FOLDER[@NAME="WWWROOT"]/FOLDER
This notation, while seemingly simple, becomes very complex when dissected. We begin by searching the entire document for an element called FOLDER with a child named FOLDER and a grandchild named FOLDER . We further limit the location paths by specifying the valued of the NAME attribute for each FOLDER element. Finally, we return all matching grandchild FOLDER elements. This example would return the FOLDER elements on lines 7 and 21. Note that this is not the same as the query parent::FILESYSTEM/DRIVE , where we limit the search to a specified path and not the entire document.
Attributes and Predicates
We have seen examples of using attributes as predicates, but have not formally addressed attributes. Attributes can be retrieved using the attribute axis or by using the abbreviated syntax, an at( @ ) symbol. Referring to listing 3.10 again, where the context node is represented on line 18, we can retrieve all attributes where the name of the attribute is LETTER :
attribute::*[name()='LETTER']
This syntax can be abbreviated to specify searching only the LETTER attribute and no other attributes:
attribute::LETTER
This syntax can be abbreviated further using the at symbol:
@LETTER
XPath Functions
We have mentioned Boolean expressions in the context of predicates, but let's take a look how we can leverage Boolean expressions in predicates. There are 29 different XPath functions relating to strings, numbers, node-sets , and Booleans. We will not list all 29 functions here: rather, you are encouraged to visit the W3C recommendation documentation at http://www.w3.org/TR/xpath.
We have already looked at two of the functions, position() and count() . Without listing all 29 XPath functions here, we will focus on the Boolean function not() . The not() function returns True if the argument is false, False if the argument is true. Let's take a look at what this really means by looking at an example. Here, we will select ourselves only if we contain an attribute named LETTER .
self::*[@LETTER]
What if we wanted to select ourselves only if we did not contain an attribute named LETTER? One way is to use the XPath function not() .
self::*[not(@LETTER)]
This statement can be misleading, so let's think about what is really being queried. It would be easy to misinterpret this statement as "return the context node's children that are not an attribute named LETTER ." Recall from Table 3.3 that the self-axis returns the context node. So, we actually return the DRIVE element if the predicate matches. The not() function tests to see if a LETTER attribute is present. If the LETTER attribute is present, the node-test returns false, and the context node is not selected.
XPath functions cannot be used as statements themselves . For instance, the following XPath statement is not legal:
not(@LETTER)
This is because the statement must evaluate as a node-set. In other words, we omitted two parts of the location step: the axis and the node test, we skipped right to the predicate.
Logical and , Logical or
Hand-in had with the not() function are the logical and and logical or operators. The best way to explain logical expressions is to see examples of them.
This example returns the child FOLDER elements that contain both a FOLDER and a FILE element:
FOLDER[FOLDER and FILE]
This example selects from the root node all drives that have a drive letter of A or C:
/FILESYSTEM/DRIVE[@LETTER='A' or @LETTER='C']
Unions
We have implicitly worked with and mentioned node sets throughout this section. Working with sets implies the capability of unions to join sets of data. XPath supports the concept of unions using the pipe ( ) character.
/FILESYSTEM/DRIVE[@LETTER='A'] /FILESYSTEM/DRIVE[@LETTER='D']
This example retrieves the union of DRIVE elements having either a drive letter A or D. Unions are very useful in XPath, and are used in many advanced XSLT operations involving keys. XSLT and keys are explained later in the section "XSLT" as well as in Appendix C.
The stylesheet Element
Because each XSLT document is an XML document, XSLT follows the same well- formedness rules as any other XML document. That means requiring one and only one root element. The root element for an XSLT stylesheet is the <xsl:stylesheet> element. This element declares the namespaces used for the document and the namespace used for the XSLT processor.
Namespaces
Namespaces are discussed in Chapters 1 and 2. This is a critical point to grasp prior to using XSLT beause the concept of namespaces is embedded throughout XSLT.
During the early working draft of XSL, Microsoft developed many products that used a technology similar to XSL. Because XSL was still a working draft and was not yet formally called XSL, Microsoft used this term to denote its implementation. This early implementation can be found in earlier versions of products such as Internet Explorer and BizTalk. The namespace associated with these early versions is the following:
http://www.w3.org/TR/WD-xsl
MSXML 4.0, which is the parser version that comes with IE 6, does not support this namespace. Instead, you can convert stylesheets by using this namespace to the W3C recommendation syntax using the XSL to XSLT Converter 1.1, which is available from Microsoft at http://msdn.microsoft.com/downloads/sample.asp?url=/MSDN-FILES/027/000/540/msdncompositedoc.xml&frame=true .
The correct XSLT namespace to use is www.w3.org/1999/XSL/Transform.
This is the namespace that's used in Visual Studio .NET and the MSXML 4.0 parser.
Using the XSL Namespace
Each XSLT stylesheet begins with the stylesheet declaration. XSLT stylesheets are also XML documents, so the stylesheet element is the root node of the XML document:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> . . . </xsl:stylesheet>
Note
The xsl:transform element is an allowable synonym for the xsl:stylesheet element, but the xsl:transform root element is not commonly used. See Appendix C for more information on the xsl:stylesheet and xsl:transform elements.
The XSL namespace is now referenced by using the qualified element prefix xsl . You might want to use other namespaces in your document. For example, you might use the XHTML namespace to create XHTML output.
XHTML is a W3C Recommendation that imposes XML well-formedness rules on HTML documents. For example, the following code is perfectly legal in HTML:
<p>This is some text<br>
With XHTML, this would not be valid because each element must have a corresponding ending element and be properly nested. The following would be required to meet XHTML's well-formedness restriction:
<p>This is some text<br/></p>
XHTML uses a specific namespace for validation, which is highlighted in this code snippet:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xhtml="http://www.w3.org/TR/xhtml1/strict"> . . . </xsl:stylesheet> You can now refer to each XHTML element using the xhtml element prefix to qualify the namespace for the element. This can lead to less-readable documents, however, so you might want to use the default namespace for the output document, as shown here:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://www.w3.org/TR/xhtml1/strict"> . . . </xsl:stylesheet> Notice the omission of the xhtml namespace prefix. The omission of the xhtml namespace prefix associates the XHTML namespace with the default namespace. In other words, unless otherwise specified, anything in the result tree will be an XHTML element.
XSLT provides control over a multitude of different settings used for transformations. For example, you can transform XML into a variety of mediums ”text, HTML, or other XML documents. You can specify this by using the <xsl:output> element as a child of the <xsl:stylesheet> element, as shown here:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://www.w3.org/TR/xhtml1/strict"> <xsl:output method="html"/> . . . </xsl:stylesheet> Other facets that you might want to control can include what namespaces are excluded from the result document, what version of a particular namespace is used, what elements, if any, are excluded from the result tree, or even how whitespace is handled. Appendix C, "XSLT Reference," lists the different XSLT elements and provides usage for each of the elements in the form of a short example. Rather than list the different control elements here, we suggest that you browse Appendix C and look through the element listings.
Understanding Template Processing
A key concept to understand when working with XSLT is the concept of template processing . XSLT uses a pull method to process XML documents. The pull and push methodologies are covered in Chapter 5. Instead of the procedural approach to programming, where each function calls another function, XSLT responds to events as they occur. More appropriately, XSLT templates are actually a set of node-tests that are called when the node test applies. XSLT stylesheets usually start with a match for the root element:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> . . . </xsl:template> </xsl:stylesheet>
Inside this template rule, you are now pointing to the root node. In other words, you now have context for the root node.
As previously mentioned, XSLT is not concerned with generating text, but instead generating a result tree. As you process the source document, you output the results. Specifically , you add nodes to the result tree. Those nodes can be HTML nodes associated with the XHTML namespace. They might be structured vector graphics XML elements. The nodes can be XSL-FO elements, text, MathML elements, or a host of other outputs. The result tree might also be a combination of any of these. The point, however, is that XSLT generates result trees, not text.
Let's reuse the following pitchers.xml document:
<?xml version="1.0" ?> <PITCHERS> <PITCHER> <FNAME>John</FNAME> <LNAME>Rocker</LNAME> <TEAM>Indians</TEAM> <CITY>Cleveland</CITY> <ERA></ERA> </PITCHER> <PITCHER> <FNAME>Tom</FNAME> <LNAME>Glavine</LNAME> <TEAM>Braves</TEAM> <CITY>Atlanta</CITY> <ERA></ERA> </PITCHER> <PITCHER> <FNAME>Greg</FNAME> <LNAME>Maddux</LNAME> <TEAM>Braves</TEAM> <CITY>Atlanta</CITY> <ERA></ERA> </PITCHER> <PITCHER> <FNAME>Randy</FNAME> <LNAME>Johnson</LNAME> <TEAM>Diamondbacks</TEAM> <CITY>Arizona</CITY> <ERA></ERA> </PITCHER> </PITCHERS>
How would you logically use node-tests to work with a hierarchical document? Start by testing the root node, as you did earlier, to gain context to the document. Then set up a series of tests for the nodes in the XML document. Begin by setting up a test for the PITCHER element, as follows:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> . . . </xsl:template> <xsl:template match="PITCHER"> </xsl:template> </xsl:stylesheet>
When this template is fired , you will have a pointer to the <PITCHER> element, and will have access to its related nodes through the use of XPath. Because you now have a context node of a PITCHER element, you can access the values of its children, as shown here:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <TABLE> <xsl:apply-templates/> </TABLE> </xsl:template> <xsl:template match="PITCHER"> <tr> <td><xsl:value-of select="FNAME"/></td> <td><xsl:value-of select="LNAME"/></td> <td><xsl:value-of select="TEAM"/></td> <td><xsl:value-of select="CITY"/></td> </tr> </xsl:template> </xsl:stylesheet>
In this example, notice the highlighted elements. Because the context node in this template rule is a PITCHER element, you can simply navigate to its child nodes without navigating from the root node.
Recursion in XSLT
Recursion is typically used with hierarchical structures and trees, so it's no wonder that XSLT makes heavy use of recursion. Recursion is the capability of a function to call itself to perform a task. The following stylesheet uses two recursive calls:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <TABLE> <xsl:apply-templates/> </TABLE> </xsl:template> <xsl:template match="PITCHER"> <tr> <xsl:apply-templates/> </tr> </xsl:template> <xsl:template match="FNAME"> <td><b><xsl:value-of select="."/></b></td> </xsl:template> <xsl:template match="LNAME"> <td><xsl:value-of select="."/></td> </xsl:template> <xsl:template match="TEAM"> <td><i><xsl:value-of select="."/></i></td> </xsl:template> <xsl:template match="CITY"> <td><xsl:value-of select="."/>, </td> </xsl:template> </xsl:stylesheet>
The first call is found in the template that processes the root node. After the root node is found, a TABLE element is created. A call to <xsl:apply-templates> is then made with no select statement. The effect of this call is that the XSLT processor then begins processing with the next node in the document, traveling the descendant axes if possible and then recursing through its parent and any descendant axes to process each node in the tree. The next node in the document is the PITCHER node because it is a child element of the context element. The PITCHER node now becomes the context element and the second template matching the PITCHER element is fired. A table row tag is emitted , and again the processor is instructed to process child nodes. This recursion allows each node in the tree to be processed , while allowing the developer to easily separate node tests for each node type.
Here's a more complex recursive example. Suppose that you are processing an XML file that contains carriage returns. You'd like to replace each instance of the carriage return with an HTML <br> tag. The input HTML looks like this:
<?xml version="1.0" encoding="utf-8" ?> <DATA> <test> this,is,a,test this,is,another,test this,is,yet another,test hello,world,from,xslt </test> <test> this is a set of sentences that you want to preserve formatting on </test> </DATA>
One way to preserve formatting in HTML is to simply use the <pre> tag, indicating that the data contained within the tag is pre-formatted. There are many situations, however, where using the <pre> tag does not suffice for formatted output and a pure HTML solution is desired. Let's look at an example of how to use recursion with string parsing to manipulate text nodes. Our example will replace each carriage-return contained in an XML document with an HTML <br> tag.
To replace each carriage-return with a line-feed, you must set up a template to match the root node. This template tells the processor to begin recursing. Because there is no select attribute for the <xsl:apply-templates> element, processing will continue recursively.
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <xsl:apply-templates /> </xsl:template>
Then declare a template rule to match the named document element. This template tells the processor to continue recursing remaining through the nodes as well:
<xsl:template match="DATA"> <xsl:apply-templates /> </xsl:template>
The next node in the document to match is the <test> element. You can declare a template rule to handle this element as well. Because this element contains the text that you want to transform, grab the text from the element and pass it to a named template function:
<xsl:template match="test"> <xsl:call-template name="replacecrwithbr"> <xsl:with-param name="data" select="." /> </xsl:call-template> </xsl:template>
The purpose of the named template function is to grab all data up to the first carriage-return, add it to the result tree, add a <br> element to the result tree, and call itself recursively until all the text is processed. This template rule is difficult at first, but it makes a lot of sense once you break it apart. We pass in a parameter, data . We then assign a variable, this , that contains all the nodes up until the first carriage-return. We then assign all nodes from the parameter following the first carriage-return to a variable called rest.
<xsl:param name="data" /> <xsl:variable name="this" select="substring-before($data,' ')" /> <xsl:variable name="rest" select="substring-after($data,' ')" />
Now, we have all the nodes before the first carriage-return and all the nodes following the first carriage-return. Our next step is to test if either variable holds data, which is performed using an <xsl:if> test. We first test the this variable to see if there is any text before the first carriage-return. If there is any text, we output it and append an HTML <br /> tag to the output.
<xsl:if test="$this"> <xsl:value-of select="$this" /> <br /> </xsl:if> The next step is to test if any data follows the first carriage-return. Again, we use an <xsl:if> test to determine this condition. If any data follows the first carriage-return, we recurse back into our template rule, passing the rest of the data following the first carriage-return:
<xsl:if test="$rest"> <xsl:call-template name="replacecrwithbr"> <xsl:with-param name="data" select="$rest" /> </xsl:call-template> </xsl:if>
When the template rule recurses back into itself, the operation is repeated until there is no more data following a carriage-return. The entire template rule appears as follows:
<xsl:template name="replacecrwithbr"> <xsl:param name="data" /> <xsl:variable name="this" select="substring-before($data,' ')" /> <xsl:variable name="rest" select="substring-after($data,' ')" /> <xsl:if test="$this"> <xsl:value-of select="$this" /> <br /> </xsl:if> <xsl:if test="$rest"> <xsl:call-template name="replacecrwithbr"> <xsl:with-param name="data" select="$rest" /> </xsl:call-template> </xsl:if> </xsl:template> </xsl:stylesheet> Using this method, you can begin to envisage very powerful transformations. For instance, you can use this method to process comma-separated value files or fixed-length field files, simply by modifying the replacecrwithbr template rule. This is a common design pattern in XSLT that can be manipulated for a variety of tasks .
Another useful transformation pattern is the identity transformation . This transformation matches all attributes and a node of any type, copies it, and begins processing again with the next attribute or node:
<xsl:template match="@* node()"> <xsl:copy> <xsl:apply-templates select="@* node()" /> </xsl:copy> </xsl:template>
We have looked at recursion and the identity transformation, two common (yet unintuitive) design patterns in XSLT.
A very common task in XSLT is to select a distinct set of nodes. There is no built-in mechanism in XSLT to do this. There is no distinct() function or xsl:distinct element, so we must construct a set of template rules to approach this. Because the approach includes the use of keys, we will first look at keys in XSLT.
Keys in XSLT
XSLT provides the xsl:key element to declare a named key for easier access to complex XML documents. Keys are a directory of specific nodes from a source document, identified by a friendly name. Keys must be declared as a top-level element and cannot be declared within templates.
Conceptually, keys are difficult to grasp at first. Suppose that you wanted to refer often to a list of elements within an XML document. Instead of requerying the document each time for the nodes, you can build a list of elements and associate them with a friendly name. This is done using the <xsl:key> element.
The <xsl:key> element has 3 attributes:
-
name ” A friendly name to identify the key.
-
match ” The pattern to be matched within the document. The pattern is matched on a node-by-node basis, so global match patterns are not used. These are the nodes that we want to group .
-
use ” Provides the values of the key: The expression is matched once for each node satisfying the match pattern. This is the key's value for each matched node.
The concept of the match and use attributes seems like it is the same thing, but they are not. Think of a key as a Dictionary object, where a dictionary has a name, and the objects within the dictionary are associated name/value pairs.
One way that keys are useful is to retrieve a list of nodes that match a criteria. For instance, recall back to our PITCHERS.XML document in listing 3.4. We can define a key in an XSLT stylesheet that will return all of the pitchers on the Atlanta Braves roster:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:key name="Pitchers" match="PITCHER" use="TEAM"/> <xsl:template match="/"> <html> <body> <xsl:for-each select="key('Pitchers','Braves')"> <xsl:value-of select="LNAME"/> <br/> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet> The output for this stylesheet is as follows:
<html> <body>Glavine<br>Maddux<br></body> </html>
Besides matching specific values, we can also use a key to generate a list of all pitchers.
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:key name="Pitchers" match="TEAM" use="."/> <xsl:template match="/"> <html> <body> <xsl:apply-templates/> </body> </html> </xsl:template> <xsl:template match="PITCHER"> <xsl:for-each select="key('Pitchers',TEAM)"> <xsl:value-of select="."/> <br/> </xsl:for-each> </xsl:template> </xsl:stylesheet> The call to the key function indicates that the stylesheet is to retrieve nodes from the Pitchers key, passing in the child TEAM element of the context node. The TEAM element matches the pattern defined in the match attribute (defined in the <xsl:key> element), so the text node for the key is returned. This stylesheet produces the following output (formatted for readability):
<html> <body> Indians<br> Braves<br> Braves<br> Braves<br> Braves<br> Diamondbacks<br> </body> </html>
Notice that we retrieved all teams defined in the XML document, and team names repeated. If we wanted to instead retrieve just the distinct teams , how would we accomplish this? It turns out that there are several ways to do this. We could use a template rule that uses the preceding-sibling axis to determine if the current node matches any of the nodes on the same level.
TEAM[not(. = preceding-sibling::TEAM)]
However, this type of search involves searching the preceding-sibling axis each time a TEAM node is encountered . The preceding-sibling axis can be quite expensive in terms of processing for a document of significant size once we approach the end of the document. Steve Muench, Oracle's lead XML Technical Evangelist and development lead for Oracle XSQL Pages, developed an efficient method of grouping using keys to retrieve unique items. This method is called the "Muenchian Method".
The Muenchian Method uses an XPath union, described earlier in the section on XPath. It checks to see if the union of the current node and the first node-match in the key is one node or two nodes. Node sets cannot contain repeated nodes: If the call to the count function returns 1, then the node is distinct and is returned from the XPath expression.
Here is the basic syntax:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <xsl:key name="distinct" match="TEAM" use="."/> <xsl:template match="PITCHERS"> <html><body><xsl:apply-templates/></body></html> </xsl:template> <xsl:template match="PITCHER"> <xsl:for-each select="./TEAM[count(.key('distinct',.)[1]) = 1]"> <xsl:value-of select="."/> <br/> </xsl:for-each> </xsl:template> </xsl:stylesheet> Remember that the ( . ) special character in XPath refers to the context node. So, the key matches a TEAM element and has the value of the child text node of the TEAM element. The XPath expression in the for-each loop matches the distinct child text nodes of TEAM elements. The output is as follows:
<html><body>Indians<br>Braves<br>Diamondbacks<br></body></html>
A number of common design patterns are available for using XSLT, including variations on both the identity transformation for copying nodes and using the Muenchian method for multiple levels. For more information on XSLT, visit the XSL-List mailing list archive at www.mulberrytech.com/xsl/xsl-list.
For a great description of the Muenchian Method and some of its variations, see http://www.jenitennison.com. Finally, Marrowsoft's Xselerator, available at http://www.topxml.com, has a great wizard for generating distinct groupings using the Muenchian Method.
Combining XSLT and CSS
As previously shown, XSLT is good at parsing documents, and CSS is good at defining styles within HTML documents. When XSLT is combined with CSS to produce HTML, the maintainability of a site is hugely improved. Want to change how a page is laid out? Change the XSLT. Want to change the data in a page? Change the XML. Want to change a specific font or the border for tables? Change the CSS. By abstracting the changes into separate locations, the amount of cut-and-paste coding is reduced, which yields a more efficient website.
To associate a CSS document with an XSLT stylesheet's output, simply reference the stylesheet as a result element, as shown here:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns="http://www.w3.org/TR/xhtml1/strict"> <xsl:template match="/"> <html> <head> <link rel="stylesheet" type="text/css" href="myfile.css"/> </head> <body> <xsl:apply-templates /> </body> </html> </xsl:template> <xsl:stylesheet>
XSLT Extension Functions
While XSLT is powerful, it is a template-based language built on tests to nodes. This can be counter-intuitive to procedural programmers that are used to controlling flow of execution. As we saw in the section on keys, seemingly routine tasks can yield complex template rules. There are some tasks that can be handled in XSLT, but can be handled more efficiently using a procedural language.
Microsoft's implementation of XSLT allows for the creation of extension functions. One method of extending XSLT is through the use of JavaScript, using the < msxsl :script> element.
You can develop many functions by using a script extension. For example, numbering in XSLT is not intuitive for procedural programmers. Instead of using the xsl:number element, you might choose to implement this by using a script element. Extend the stylesheet from earlier in the chapter and call this new version ExtendingXSLT.xslt . Listing 3.10 shows the code for this XSLT file.
Listing 3.10 ExtendingXSLT.xslt
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:msxsl="urn:schemas-microsoft-com:xslt" xmlns:tns="urn:thisnamespace:tns" exclude-result-prefixes="tns xsl msxsl"> <xsl:param name="sortBy" select="'CITY'"/> <msxsl:script language="JavaScript" implements-prefix="tns"> var m_intVal = 0; function Iterate() { m_intVal += 1; return(m_intVal); } </msxsl:script> <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> <xsl:template match="PITCHERS"> <TABLE border="1"> <tr> <th bgcolor="teal">Number</th> <th bgcolor="teal">First Name</th> <th bgcolor="teal">Last Name</th> <th bgcolor="teal">City</th> <th bgcolor="teal">Team</th> <th bgcolor="teal">ERA</th> </tr> <xsl:for-each select="PITCHER"> <xsl:sort select="*[name()=$sortBy]"/> <tr> <td><xsl:value-of select="tns:Iterate()"/></td> <td><xsl:value-of select="FNAME"/><br/></td> <td><xsl:value-of select="LNAME"/></td> <td><xsl:value-of select="CITY"/></td> <td><xsl:value-of select="TEAM"/></td> <td><xsl:value-of select="ERA"/></td> </tr> </xsl:for-each> </TABLE> </xsl:template> </xsl:stylesheet> The relevant parts to notice in Listing 3.10 are the additional namespaces used, the JavaScript function addition, and the call to the Iterate function. Also the namespace prefixes were omitted by using the exclude-result-prefixes attribute of the stylesheet element.
Note
Using the msxsl:script element does not output the JavaScript in the result document. Instead, it is a specially recognized element that the Microsoft XSL parsers recognize for extension functions. The JavaScript in Listing 3.10 is not output with the result tree. Instead, it generates the result tree.
Call this stylsheet using Pitchers.xml as the input XML file. Create a new .aspx page called ExtendingXSLT.aspx . Remove all HTML from the .aspx page except the Page directive. In the code-behind file, enter the code shown in Listing 3.11.
Listing 3.11 ExtendingXSLT.aspx.vb
Public Class ExtendingXSLT Inherits System.Web.UI.Page #Region " Web Form Designer Generated Code " 'This call is required by the Web Form Designer. <System.Diagnostics.DebuggerStepThrough()> Private Sub InitializeComponent() End Sub Private Sub Page_Init(ByVal sender As System.Object, ByVal e As System.EventArgs)Handles MyBase.Init 'CODEGEN: This method call is required by the Web Form Designer 'Do not modify it using the code editor. InitializeComponent() End Sub #End Region Private Sub Page_Load(ByVal sender As System.Object, ByVal e As System.EventArgs)
The output of this extension is shown in Figure 3.3.
Figure 3.3. Using an extension element to number items.
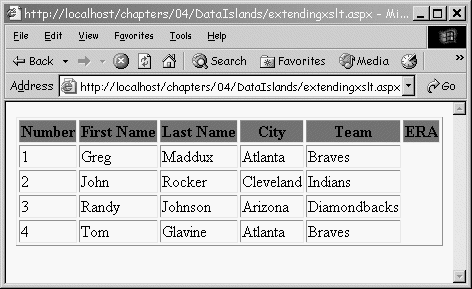
Because you defined the UI using XSLT, you now have the ability to change where the XSLT transformation occurs. Listing 3.9 used MSXML to perform the transformation in the client. You might, however, decide to perform the transformation on the server to avoid browser compatibility issues, as shown in the following code:
private void Page_Load(object sender, System.EventArgs e) { if (!IsPostBack) { XPathDocument doc = new XPathDocument(Server.MapPath("pitchers.xml")); XslTransform xsl = new XslTransform(); xsl.Load(Server.MapPath("extendingxslt.xslt")); XsltArgumentList args = new XsltArgumentList(); args.AddParam("sortBy", "", "FNAME"); XmlWriter writer = new XmlTextWriter(Response.Output); xsl.Transform(doc, args, writer); writer.Close(); } } The server-side code began by loading the XML document, pitchers.xml . Then the XSLT stylesheet was loaded, ExtendingXSLT.xslt . Because your stylesheet uses a parameter, you can use the XsltArgumentList object to create a parameter and add it to the list of arguments. Finally, you can designate the output target as the response object's output stream, and perform the transformation.
The classes used in this example are dicussed in more detail in Chapter 6, "Exploring the System.Xml Namespace."
Although XSLT is extremely flexible, tasks can be greatly simplified by not generating a series of complex template rules. For these instances, you might want to create a simple extension function to achieve the same task. You saw how this is done using the msxsl:script element and JavaScript, but it is impossible to debug using this approach. Another method of extending XSLT is to create your own extensions through the use of compiled libraries that are referenced directly from XSLT. Instead of creating script code that's impossible to debug, create compiled components that are called from XSLT to generate the XSLT output.
In the following code, the XSLT stylesheet was changed only slightly by removing the JavaScript function. The MSXSL namespace was removed because it is not needed for the revised example:
<?xml version="1.0" encoding="UTF-8" ?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:tns="urn:thisnamespace:tns"> <xsl:param name="sortBy" select="'CITY'"/> <xsl:template match="/"> <xsl:apply-templates/> </xsl:template> <xsl:template match="PITCHERS"> <TABLE border="1"> <tr> <th>Number</th> <th>First Name</th> <th>Last Name</th> <th>City</th> <th>Team</th> <th>ERA</th> </tr> <xsl:for-each select="PITCHER"> <xsl:sort select="*[name()=$sortBy]"/> <tr> <td><xsl:value-of select="tns:Iterate()"/></td> <td><xsl:value-of select="FNAME"/><br/></td> <td><xsl:value-of select="LNAME"/></td> <td><xsl:value-of select="CITY"/></td> <td><xsl:value-of select="TEAM"/></td> <td><xsl:value-of select="ERA"/></td> </tr> </xsl:for-each> </TABLE> </xsl:template> </xsl:stylesheet>
In the XSLT file, we added a call to a function called tns:Iterate() . This function is a member of the tns namespace. Because we declared our own function, we now must tell the XSLT processor how to handle this function. To do this, use the XsltArgumentList object to add an extension object and associate it with a specific namespace.
Create a new .aspx page called ServerExtension.aspx and remove all HTML from the .aspx page. In the code-behind file ServerExtension.aspx.vb , enter the following code. Listing 3.12 shows the complete code-behind for the page.
Listing 3.12 ServerExtension.aspx.vb
Imports System.Xml Imports System.Xml.Xsl Imports System.Xml.XPath Public Class ServerExtension Inherits System.Web.UI.Page #Region " Web Form Designer Generated Code " 'This call is required by the Web Form Designer. <System.Diagnostics.DebuggerStepThrough()> Private Sub InitializeComponent() End Sub Private Sub Page_Init(ByVal sender As System.Object, ByVal e As System.EventArgs)
When you embedded the JavaScript extension by using the <msxsl:script> element, no way existed to debug the JavaScript contained within it. With compiled code on the server, however, you can set a breakpoint in the Iterate function and easily debug the code.
Declarative Programming with ASP.NET Versus XSLT Processing
XSLT is good for making tranformation tasks possible. But there are limitations to what it can currently do. For example, complex business logic and operations, such as transactional database processing and Microsoft Message Queue (MSMQ) manipulation, are not possible with XSLT. You can easily see, however, that many of the mundane display tasks that have polluted ASP server-side scripts in the past are greatly simplified with XSLT processing.
Declarative programming describes the way that programming is done in ASP.NET applications involving coding tasks. Within code, you declare variables and create instances of classes to perform tasks. Declarative programming involves some type of control flow, such as looping and conditional tests.
Prior to ASP.NET, web programming with ASP yielded difficult-to-maintain code. This is largely because of the presentation of data was intermingled with the logic surrounding the data. Custom COM components could be written to ease some of this maintainability, but this potentially put presentation logic in compiled code.
With the advent of ASP.NET, many of the limitations of the past are potentially removed. For example, elegant UIs can be developed using web forms controls, and the code that manipulates and interacts with the UI elements can be separated into a code-behind file. This reduces the amount of logic intermingled with presentation code, reduces complexity, and increases maintainability. In addition, ASP.NET performs many of the mundane tasks behind the scenes, such as browser compatibility and execution of script code on the client to avoid server posts.
XSLT offers a great way to separate presentation from the data. But, a great many tasks cannot be performed with XSLT, such as database updates and interaction with MSMQ. For this type of operation, custom logic must be used.
However, the two technologies are not mutually exclusive. In fact, they complement each other. The asp:xml web forms control, for example, provides quick access to performing transformations on a web form page.
WAP and WML
By using XSLT, you can also create WAP and WML documents on the fly from ordinary XML documents. WML is a form of markup that is specifically targeted for handheld devices that use WAP. Development with WML is similar to HTML in some respects:You designate markup for the content. But the similarities end there. In HTML, you can specify images and very complex formatting rules. In WML, you don't have this luxury because the display surface for WML browsers is extremely small. Some WAP browsers enable you to change aspects of a font, such as underlining, bold, italics, and relative size, but support for this is not standard across devices. At best, you have support for simple text.
Chapter 13, "Sample Application: Mobile Device Programming with WAP," discusses WAP, WML, and XHTML Basic and shows you how a single XML document can be rendered as HTML, WML, or XHTML Basic by applying different XSLT transformations.
| only for RuBoard |
EAN: N/A
Pages: 184