4.2 Integer Arithmetic Instructions
| We elect to describe integer arithmetic instructions, which are among the type A instructions for ALU operations, as the first systematic discussion of the Itanium instruction set. We will refer back to the SQUARES program where some of these were used. 4.2.1 Addition and SubtractionComputer architectures universally provide for basic arithmetic operations where two source operands are combined appropriately into a destination value. AdditionWe have already mentioned the addition instruction in previous chapters. This Itanium instruction is implemented in several forms: add r1=r2,r3 // r1 < r2 + r3 add r1=r2,r3,1 // r1 < r2 + r3 + 1 adds r1=imm14,r3 // r1 < sext(imm14) + r3 addl r1=imm22,r3 // r1 < sext(imm22) + r3 add r1=imm,r3 // r1 < sext(imm) + r3 where sext denotes that the immediate constant operand is sign-extended to a full width of 64 bits before it is used in the arithmetic operation. The register designations r1, r2, and r3 refer to the particular encoding found in fields in the bit layout of an instruction (Section 4.1.2). Each designation may specify any one of the Itanium general registers Gr0 through Gr127. The addl instruction is an exception, where r3 can refer only to Gr0 through Gr3 for reasons explained later. An immediate constant can be represented in the same manner as constants in the C programming language, such as 0x1f, 32, or 073 (octal). The second form of the add instruction may be called "plus 1" and is useful in instruction sequences for extended-precision addition (e.g., adding numbers wider than 64 bits). The last form of the add instruction with imm as the first source operand is an example of an assembler pseudo-op that is, a convenient form which the assembler will adapt according to circumstance. If the constant can be represented in 14 or fewer bits as a two's complement integer, the assembler will construct an adds instruction that can include any general register as the other source operand. But if the constant is wider, the assembler will construct an addl instruction that constricts the choice of general register for the other source operand. SubtractionThe Itanium architecture offers fewer choices for subtraction than for addition, namely just the following: sub r1=r2,r3 // r1 < r2 - r3 sub r1=r2,r3,1 // r1 < r2 - r3 - 1 sub r1=imm8,r3 // r1 < sext(imm8) - r3 where the conventions for notation are the same as for addition, but with only one narrow representation for an immediate constant. The second form of the sub instruction may be called "minus 1" and is useful for extended-precision subtraction (e.g., subtracting numbers wider than 64 bits). Register direct and immediate addressingThese arithmetic instructions illustrate two addressing modes. When a source or destination operand is a named register, we call that the register direct form of addressing. When a source operand is a constant encoded into certain spans of bits within the instruction itself, we call that the immediate form of addressing. We will later see that Itanium instructions that call for other ALU operations (such as Boolean logic) use these two forms of addressing for the operands. RISC architectures have analogous instruction and addressing forms. 4.2.2 Arithmetic OverflowArithmetic operations can result in overflow, because all numeric representations in a computer are finite. Most simply, overflow arises when the true mathematical result cannot fit within the size of the register or information unit. With addition and subtraction, the apparent result then has the wrong sign. To see this, consider adding 2 plus 2 in a 3-bit two's complement representation:
Notice in this illustration that there was not a "carry" outside of the 3-bit storage field when this operation was performed from right to left. Overflow is generally different from carryout for operations on signed numbers. Overflow can easily occur with multiplication because the product of two N-bit numbers may need as many as 2N bits of storage. Most RISC systems require extra clock cycles to detect and report overflow, giving the programmer a choice between rapid calculations ignoring error conditions or slower calculations with tracking of exceptions. Some PA-RISC instructions have "trap on overflow" versions, but the Itanium integer instructions do not detect or report overflow. Any algorithm being programmed should be analyzed for possible overflow conditions and, if overflow may arise, modified to safeguard against it. The C language does not define an action to be taken when arithmetic overflow occurs. In fact, most versions of C ignore overflow. Versions of other languages, such as FORTRAN, may provide compiler options to produce programs that do detect overflow. 4.2.3 Shift Left and Add InstructionThe Itanium architecture includes a third integer-arithmetic operation, besides addition and subtraction, which involves a combination of shifting the bits within one source operand to the left by a certain count and then adding another source operand: shladd r1=r2,count2,r3 // r1 < 2count2 * r2 + r3 where count2 specifies how far the bits within the first source operand will be shifted to the left. The extent of shifting can range from a minimum of one to a maximum of four bit positions. From the discussion of two's complement binary representation in Chapter 1, you should appreciate that each shift to the left by one bit position multiplies the value by 2. This works for both positive (001 > 010, +1 becomes +2 as represented in a 3-bit two's complement field) and negative (111 > 110, 1 becomes 2) values. Special cases of integer multiplicationWhen the second source register (r3) is specified to be Gr0, which always contains zero, the shladd instruction can compute 2, 4, 8, or 16 times the value contained in the first source register (r2). When the two source registers (r2, r3) are specified to be the same general register, Grn, the shladd instruction can compute 3, 5, 9, or 17 times the value contained in Grn. Now consider sequences of two Itanium arithmetic instructions. If we were to compute some value multiplied by 3 using the appropriate shladd instruction, we could then compute 6 times the original value by using either shladd or add to double the intermediate computed value. Can you propose one or more ways to compute 7 times an original value using two Itanium arithmetic operations in sequence? Array indexingThe shladd instruction has an application to compute in one step the address of a given element of an array: address = (element number) * (size of information unit) + (address of array origin) shladd raddress = rnumber,log2size,rorigin where raddress is a general register to hold the computed address, rnumber is a general register holding the element number (counting them from 0), log2size is the number of bit positions to shift (1, 2, 3, 4) corresponding to the size of the data elements (2, 4, 8, 16 bytes), and rorigin is a general register holding the address of the array origin or base. One can thus work with the whole array by allocating two general registers, one fixed (the base) and one varying (the index to an element). 4.2.4 Special-Case Arithmetic OperationsIn Section 4.2.1, we saw one example of a pseudo-op in the form of an Itanium add instruction that the assembler expands into one of two forms of immediate addressing. Pseudo-ops arise from situations where an instruction set will have general cases that subsume some very useful special cases. Those special cases may be simple, familiar operations; they may also correspond to actual machine operations in some other architectures. Here we give a few examples that derive from the Itanium arithmetic instructions. CopyingIn the SQUARES program, we used mov instructions just as though they were actual Itanium instructions. The Itanium ISA lacks a machine instruction called mov to move data between general registers, or to move a simple constant into a register. Instead, the assembler recognizes a pseudo-op version of the mov instruction, implementing the two forms: mov r1=imm22 becomes addl r1=imm22,r0 mov r1=r3 becomes adds r1=0,r3 These mov pseudo-ops copy data nondestructively. That is, the second form results in having copies of the same data value in registers r1 and r3. NegationArithmetic negation of integers in two's complement representation is a commonly supported ISA operation. For the Itanium ISA, however, there is neither a machine instruction nor a pseudo-op called neg. Nevertheless, consider the following special cases of subtraction: sub r1=0,r3 // r1 = 0 - r3 = -r3 sub r1=r0,r3 // r1 = 0 - r3 = -r3 (note r0 is 0) Because of the semantics for the Itanium sub instruction, the value originally contained in the source register r3 is subtracted from zero. The negated value is placed into register r1, while the original value remains in register r3. ComplementationThe one's complement operation (Section 1.8.3) is tantamount to "toggling" individual 0 and 1 bit values. Such bitwise complementation implements the unary NOT operation in Boolean logic. The two- and three-operand versions of subtraction in the Itanium architecture can perform this operation: sub r1=-1,r3 // = -1 - r3 (definition of 1's complement) sub r1=r0,r3,1 // r1 = 0 - r3 - 1 = -1 - r3 This achievement of complementation and the previous achievement of arithmetic negation help to explain why the syntax of the Itanium sub instruction specifies that the variable in register r3 be subtracted from the immediate constant. PA-RISC architecture works similarly. (Some architectures subtract the immediate constant from the variable; those architectures would need different ways to accomplish complementation or negation.) ClearingThe Itanium ISA lacks a machine operation like clr to zero out a general register. Consider the following instructions: mov r1=0 // adds r1=0,r0 (with r0 for r3) sub r1=rn,rn // choose the same rn for r2 and r3 shladd r1=r0,count2,r0 // the value of count2 is irrelevant Each of these will leave the register schematically shown as r1 containing the value zero. The mov form seems to be the most self-evident. 4.2.5 Multiplication of 16-Bit Signed IntegersImplementation of integer multiplication at the digital logic level presents a greater challenge than addition or subtraction, especially in the temporal dimension. For a given targeted execution time, the width of numbers multiplied may have to be less than the width of numbers added or subtracted. Conversely, if multiplication works with the same width of numbers as addition or subtraction, then it may require more time. RISC and EPIC architectural designs try to make the execution time as consistent as possible across the entire instruction set. The Itanium integer execution units do not perform full 64-bit multiplication. Instead, because of the trade-off between width and execution time, two instructions perform simultaneous multiplications on two pairs of 16-bit signed integers, giving two independent 32-bit signed products: pmpy2.l r1=r2,r3 // left form pmpy2.r r1=r2,r3 // right form For pmpy2.r, the right form, the product from multiplying bits <47:32> from the two source registers r2 and r3 appears in bits <63:32> of the destination register r1, while the product from bits <15:0> of both sources appears in bits <31:0> of the destination. For pmpy2.l, the left form, the product from multiplying bits <63:48> from the two source registers r2 and r3 appears in bits <63:32> of the destination register r1, while the product from bits <31:16> of both sources appears in bits <31:0> of the destination. The two independent products do not conflict in storage because the product of two signed integers represented in N bits can always fit within 2N bits. The product of two unsigned integers represented in N bits can also fit within 2N bits. (Try simple 3- or 4-bit examples to convince yourself of this.) At first we shall use the pmpy2.r instruction to multiply two single 16-bit integers in sample programs. Later we shall show methods of multiplying wider integers. 4.2.6 Full-Width Multiplication and DivisionIn a binary computer, multiplication and division are more difficult to implement than addition and subtraction. Think back to your experience learning the mechanics of addition, subtraction, multiplication, and division in school. When you add two multidigit decimal numbers, you only have to manage "carries" of zero or one as you work from right to left. When you multiply two multidigit decimal numbers, you probably think of "long multiplication" and thus are faced with a final operation that involves summing more than two multidigit numbers. The "carries" can mount up larger than zero or one, and the result requires space for more digits for its representation than the nominal width of either of the two numbers that have been multiplied together. The process of "long division" is even more difficult because it essentially involves trial and error. Moreover, division produces two results (quotient and remainder), in contrast to the other three simple arithmetic operations, which produce only one result and perhaps an indication of overflow. A multiply or divide instruction in a binary computer will require more stages at the digital logic level than an add or subtract instruction. For RISC-like architectures, it is undesirable to have some instructions take longer than others, especially the integer operations that are used so frequently. Some RISC architectures implement division in software. The Itanium architecture provides a special instruction for integer multiplication using floating-point registers, while integer division requires a sequence of floating-point operations. Accordingly, algorithms that require multiplication and division in their most general forms will be explored later in this book. |
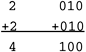
EAN: N/A
Pages: 223