13.3 The Original Itanium Processor
| Previous chapters of this book have steadfastly focused on Itanium architecture, with only the occasional clarification about details of implementation, where necessary. As long as the architecture does not change, the material you have learned should remain applicable to new implementations. We now illustrate the factors influencing the evolution of implementations of computer architectures by comparing features and characteristics of the original Itanium processor to the more widely known Itanium 2 processor. 13.3.1 Comparison to the Itanium 2 ProcessorTable 13-1 compares the first Itanium processor and the Itanium 2 processor along several key dimensions. We will not define or discuss every entry in this table, but we wanted to present a diverse set of measures customarily used for comparisons in the industry, as well as a few Itanium-specific characteristics to contrast the two implementations. Many of the quantitative comparisons in Table 13-1 are self-evident evolutionary modifications, but we draw your attention to the very few instruction differences. The architecture has remained intact. The Itanium 2 processor implements the brl and chk instructions more fully in hardware, but a program that ran on the original Itanium processor will run on an Itanium 2 processor. In a different way, the change involving the brp instruction is also benign, since the Itanium 2 processor uses different heuristics to predict branches and does not require the same type of compile-time assistance.
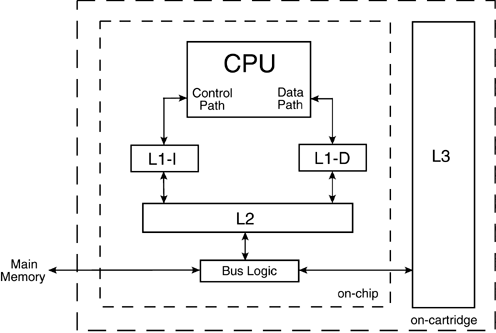
13.3.2 Cache HierarchyThe original Itanium processor contained slower cache structures of different sizes than the Itanium 2 processor implementation (Section 4.5.1). Table 13-2 gives some characteristics of the components of the original Itanium cache hierarchy. As compared to the Itanium 2 processor (Table 4-3), all of the cache access times were slower, the line sizes were smaller, and the L2 cache was smaller. Although the L3 cache could be larger, its accessibility was poorer. The L3 cache structure was manufactured separately and connected to the main processor chip inside a cartridge assembly, and the access bus between cache levels L2 and L3 was within-cartridge (Figure 13-1). Figure 13-1. Original Itanium system cache relationships
In contrast to fixed response times for the original Itanium processor, the latency for response from the L2 and L3 cache structures in the Itanium 2 processor varies (Table 4-3) because the cache line sought might be held in a bank of the cache that is busy satisfying another request from the processor. A compiler can mitigate this effect by the way it arranges data and especially through very careful scheduling of load instructions. This provides another illustration of the increased burden on compiler technology as the full impact of EPIC principles and the consequences of parallelism come into play. The new cache design illustrates the extraordinary impact of a breakthrough cache implementation. Benchmarks have shown that the Itanium 2 processor achieves roughly twice the instruction throughput of its predecessor, although it operates at less than a factor of two increase in clock frequency (Table 13-1). 13.3.3 Execution Units and Issue PortsThe original Itanium processor had two M-type execution units, while the internal parallelism of the Itanium 2 processor was increased by adding two more M-type units. The number of issue ports was 9 for the original Itanium processor, but is 11 for the Itanium 2 processor (refer to Figure 10-2). Code sequences that were previously limited by memory access can utilize more of the parallelism of the Itanium 2 processor. For example, a loop sequence in a software pipeline can potentially load four floating-point source values using the load pair instruction (Section 8.3.3), execute two independent two-operand floating-point operations (add, subtract, or multiply), and store two floating-point results per cycle of register rotation. Alternatively, since all four M-units and the two I-units can execute type A instructions, the superscalar degree for selected integer operations is six. Compilers can exploit this high superscalar degree and the large integer register set to build instruction groups for compute-intensive integer code sequences. Again, it is easiest to envision fully exploiting the parallelism of the processor using software pipelining. Having four, instead of only two, M-units makes possible a dual issue of many more pairings of bundle templates, as summarized in Table 13-3. Remember that nop instructions must have an execution unit assigned to them, even though nothing productive occurs. The very large number of cells containing "I2" in Table 13-3 gives compilers substantial latitude in composing templates for large instruction groups. 13.3.4 PipelinesThe general pipeline of the original Itanium processor, which was two stages longer than that in the Itanium 2 processor (Table 10-1), can be described using the stages briefly outlined in Table 13-4. The 10 stages can be grouped into four larger phases: front-end (IPG, FET, ROT); instruction delivery (EXP, REN); operand delivery (WLD, REG); and finally execution, and change of machine state (EXE, DET, WRB).
The floating-point pipeline was two stages longer than the integer pipeline. In effect, four execution stages for floating-point operations replaced stages 8 and 9 (EXE, DET) for integer operations. A correctly predicted branch taken incurred one to three cycles of overhead. Additional delays might result if the I-cache structures could not deliver a bundle from the address shown in the instruction pointer when the cycle returned from stage 10 (WRB) to stage 1 (IPG). Only a correctly predicted fall-through incurred no penalty at all. When a branch was mispredicted, the first-generation Itanium processor incurred a nine-cycle penalty because all eight of the following instructions already in the pipeline had to be abandoned without having been allowed to affect the machine state. 13.3.5 Latency FactorsThe Itanium 2 processor implementation contains numerous optimizations in its pipelines, which in conjunction with the efficient cache design, result in reduced latencies for many kinds of producer consumer situations between instructions. Table 13-5 summarizes such latencies for the initial Itanium processor implementation (values in parentheses) and the Itanium 2 processor.
The best-case L1-D cache delay for loading integers (R) has dropped from two cycles to one cycle. The best-case L2 cache delay for loading floating-point data (F) has dropped from nine cycles to six cycles; at least one additional cycle is always needed to convert floating-point data from the 32- or 64-bit memory representation to the 82-bit register representation. Noncyclic instruction sequences in an Itanium 2 processor thus obtain their data much more quickly, while the software pipelines for cyclic situations can be tightened up considerably. 13.3.6 Branch PredictionThe great cost of mispredicted branches motivates the computer industry to invent techniques for avoiding branches altogether, through mechanisms such as conditional moves and predication, as well as techniques for conveying branch hints and branch history information to the execution pipelines in contemporary processors. The Itanium architecture not only provides branch hint completers on branch instructions themselves (Section 5.3.1), but also includes a branch predict instruction that could help attain optimal performance with the original Itanium processor: brp.ipwh.ih target25,tag13 // IP-relative form brp.indwh.ih b2,tag13 // Indirect form brp.ret.indwh.ih b2,tag13 // Return form where the tag13 operand is encoded by the assembler from the symbolic address of the branch instruction itself and where the target25 is encoded by the assembler to match the symbolic destination address represented in the branch instruction itself. The indirect forms are used when the target address has been placed in a general register, possibly in one of several predicated ways. The return form indicates that the branch will be a return. There are four values for ipwh (the IP-relative predict whether hint). A completer sptk or dptk specifies that the branch should be predicted static taken or dynamically taken, respectively. The completer loop specifies that the branch will be one of br.cloop, br.ctop, or br.wtop. The completer exit specifies that the branch will be either br.cexit or br.wexit. There are two values for indwh (the indirect predict whether hint): A completer sptk or dptk specifies that the branch should be predicted static taken or dynamically taken, respectively. There are two possibilities for ih (the importance hint): none at all indicates that the branch is relatively unimportant, while imp indicates that the branch is one of a small number of very important branches (e.g., a branch in an inner loop). An implementation of the Itanium architecture may provide various associated hardware support elements for these implied capabilities for branch prediction. The brp instruction operates as a nop instruction except for its performance effects, such as prefetching instructions at the new predicted branch destination into the cache structures. The Itanium 2 processor exploits different and more powerful technologies for hardware branch prediction, but does use information from a brp instruction to improve I-cache performance. 13.3.7 Other Differences and FeaturesOn the initial Itanium processor implementation, which lacked hardware support for the brl instruction, an exception would occur and system software was expected to provide a fault handler with emulation to complete the jump. There could be a severe time penalty for that fault recovery, thus illustrating how implementation-specific details can affect the performance of code. Likewise, the implementation of chk instructions was not as complete, and operating system assistance was needed in order to branch to the recovery code. We have not attempted an exhaustive review of features where the Itanium 2 processor has improved upon its predecessor. In all, the Itanium 2 processor refines the implementation of the architecture in a manner that an engineer or physicist might call good impedance matching of its many powerful but complex component parts. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
EAN: N/A
Pages: 223