3.4 XML Document Logical Structure
| The logical structure of an XML document consists of declarations, elements, character references, comments, and processing instructions.
3.4.1 The XML DeclarationTwo types of declarations exist: the XML declaration and a DTD. If you use both, the XML declaration must precede the DTD. Although the XML declaration is optional, the W3C specification suggests that you include it so that the appropriate parser, or parsing process, can interpret the document correctly. XML version information is required in an XML declaration. The version number indicates that the document conforms to that version of the XML specifications, although 1.0 is the only version defined to date.
The XML declaration and all processing instructions begin with less than question mark ("<?") and end with question mark greater than ("?>"). XML allows you to also specify a "standalone" attribute and an "encoding" attribute that gives the character encoding in use. The XML Recommendation requires that all parsers support UTF-8 and UTF-16; parsers can support additional encodings as well. Thus the XML declaration might look something like the declarations shown in Example 3-4. Example 3-4 XML declarations<?xml version = "1.0"?> <?xml version = "1.0" standalone="yes" encoding = "UTF-8"?> The "standalone" document declaration is optional. A "standalone" value of "yes" indicates that the document does not depend on an external DTD; "no" indicates that the document may depend on an external DTD. The encoding declaration is optional and describes the character encoding currently in use. An appendix to the XML Recommendation gives heuristics whereby a parser may recognize many encodings, including UTF-8 and UTF-16, even in the absence of an encoding attribute.
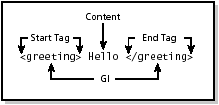
3.4.2 ElementsAn element consists of a start tag/end tag pair and any data found in between them. The start tag includes the name of an element type enclosed by a less than symbol ("<") and a greater than symbol (">"), as shown in Figure 3-2. The name of an element type is known as a generic identifier (GI). Figure 3-2. An element with content
XML documents contain data marked up with element start and end tags. Element start tags may have attributes. Elements are the most common form of markup and are extensible.
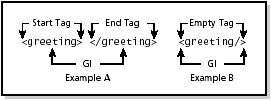
Each XML document contains one or more elements, which can be classified into one of two categories: empty elements and elements with content. Empty elements are simply markers where something occurs. To denote an empty element, you can use start and stop tags with no content or use an "empty tag" that ends with a slash greater than ("/>"). For example, the XML equivalent to HTML's "<HR>" is "<HR/>". The trailing "/>" tells the processor that the element is empty and no matching end tag exists. See Figure 3-3. Figure 3-3. Two examples of empty elements
The content of an element can consist of one or more elements, mixed content, simple text content or, as described above, no content. In Example 3-5, the <book> element contains other elements. Conversely, the <chapter> element contains mixed content both text and other elements. The <title> and <section> elements are examples of simple content; they contain only text. The relationships between XML elements are named according to parent and child nomenclature. In Example 3-5, <book> is the root element, whereas <title> and <chapter> are child elements of <book>. Note that <book> is also the parent element of both <title> and <chapter>. Example 3-5 Element contents and relationships in an XML document<book> When creating names of elements, you should avoid using a colon (" : ") because it is reserved for use by namespaces (as described in Section 3.5). You can use any name you want because the XML Recommendation reserves no words. You should, however, try to keep element names simple and descriptive. A name can contain letters, numbers, and other characters. Do not start a name with a number, punctuation characters, or the letters "xml" in any capitalization (i.e., Xml, XML, xMl), and do not include any spaces in an element name.
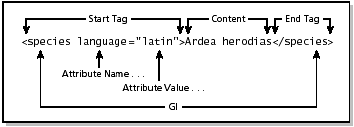
3.4.3 AttributesXML elements can have attributes in the start tag, just as in HTML. Attributes provide additional information for elements but do not constitute part of the element's content. Attributes have both a name and a value. In XML, the attribute value must always be quoted. You can use either single or double quotes, but double quotes are more common. Attribute specifications may appear only within start tags and empty-element tags. Figure 3-4 identifies the parts of an element that denote an attribute. Example 3-6 shows the attribute language="latin" incorporated into an XML document. Chapter 4 discusses specifying attributes in a DTD in more detail. Figure 3-4. Example of an attribute
Example 3-6 Attributes in an XML document<classification> <order>Ciconiformes</order> <family>Ardeidae</family> <species/> <name language="latin">Ardea herodias</name> <name language="english">Great Blue Heron</name> <foe>Raccoon</foe> <foe>Red-shouldered Hawk</foe> </classification> 3.4.4 Special Attributes xml:space and xml:langThe XML Recommendation defines the attributes xml:lang and xml:space. The xml:lang attribute facilitates the use of documents containing human-language dependent text, especially if they employ multiple languages. The xml:space attribute allows elements to declare to an application whether their white space is "significant." LanguageYou can insert the special attribute xml:lang in elements to specify the default language that the application will use in the contents and attribute values of that element in an XML document. If it is present and you are using a validating parser, you must have declared the xml:lang attribute in the DTD. The IETF [RFC 1766] specification, "Tags for the Identification of Languages," or its successor on the IETF Standards Track, defines the values of the xml:lang attribute. By convention, the language code appears in lowercase and the country code (if any) appears in uppercase.
White SpaceThe use of white space in documents varies. For example, you can use spaces, tabs, and blank lines when writing code or creating markup to make them easier to read. Such white space is typically not intended to be part of the delivered version of the document. Even so, white space in the actual source code can be significant as white space in a poem is. The XML Recommendation requires that an XML processor pass all characters that are not markup through to the application. When you attach the xml:space attribute to an element, it provides information to the application about handling white space found in that element.
You must declare the xml:space attribute if you use it with a validating parser. When declared, this attribute must be given as an enumerated type whose values are "default", "preserve", or both. For example: <!ATTLIST poem xml:space (default preserve) 'preserve'> <!ATTLIST pre xml:space (preserve) #FIXED 'preserve'> In this example, the value "default" indicates that applications' default white-space processing modes are acceptable for this element. The value "preserve" indicates that applications should preserve all of the white space. Chapter 4 provides more information about declarations and attributes in an XML document. The xml:space behavior is inherited from parent elements. If an element containing an xml:space value contains other elements, they also inherit the xml:space behavior from the parent element, unless they have a xml:space attribute of their own. 3.4.5 CDATA SectionsCDATA character data is a mechanism typically used to include blocks of special characters as character data. CDATA sections provide a way to protect information from a parser. Specifically, a CDATA section specifies that all characters within it should be considered character data, whether or not they look like a tag or entity reference. A CDATA section can appear anywhere in a document where you can have character data. CDATA sections begin with the string <![CDATA[ and end with the string ]]> The character string "]]>" is, of course, not allowed within a CDATA section because it would signal the end of the section. Example 3-7 shows a CDATA section that treats "<greeting>" and "</greeting>" as character data, not markup.
Example 3-7 A CDATA section<![CDATA[<greeting>Hello, world!</greeting>]]> 3.4.6 CommentsComments are used to annotate an XML document, but are not part of the document's text content. In addition, you can use them to comment out tag sets. Although an XML processor generally ignores comments, a processor may make it possible for an application to retrieve the text of comments. Comments begin with <!-- and end with --> HTML uses the identical syntax for inserting comments into a document. For compatibility, the string "--" (double-hyphen) must not occur in a comment. Comments may appear anywhere in a document, provided the comment remains outside other markup. Example 3-8 gives several examples of comments. Example 3-8 Comments<!-- This is a comment --> <!-- This is also a comment --> <!-- Begin the contributing author names --> <name>George W. Archibald</name> <name>James C. Lewis</name> <!-- End the contributing author names --> <!-- Comment out other contributing author names! <name>Able B. Charlie</name> <name>Delta E. Foxtrot</name> End commenting out other contributing author names. --> When using comments, observe the following guidelines:
3.4.7 Character Sets and Encoding[ISO 10646] is the native character set of XML. Every ISO character corresponds to a number between 0x0 to 0x10FFFF (in the hexadecimal system). Legal characters in XML are the tab, carriage return, line feed, and legal characters of [Unicode] or [ISO 10646] in the ranges 0x20 to 0xD7FF, 0xE000 to 0xFFFD, and 0x10000 to 0x10FFFF hexadecimal (i.e., all characters except for the surrogate blocks, 0xFFFE and 0xFFFF). Note, however, that some changes in this system have been proposed [XML 1.1]. All XML processors must accept the UTF-8 and UTF-16 encoding of ISO 10646. Special Character StringsText in an XML document consists of intermingled character data and markup. All text that is not markup constitutes the character data of the document. The XML Recommendation specifies that the ampersand character ("&") and the left and right angle brackets ("<" and ">") may appear in their literal form only when used as follows:
If you use these characters outside of markup, you must "escape" them using either numeric character references or special escape strings, as defined in the XML Recommendation. In addition, the XML Recommendation specifies special escape strings to allow attribute values to contain both single and double quotes (see Table 3-5). You must escape the right angle bracket (">") using ">" or a numeric character reference when it appears in the string "]]>" in content and when that string does not mark the end of a CDATA section. Numeric Character ReferencesNumeric character references allow you to insert into your document any legal Unicode characters including those that satisfy the following criteria:
Character references take one of two forms: decimal references that start with "&#" and hexadecimal references that start with "&#x". For example, "©" is the decimal representation of the standard copyright symbol ("©"). You can represent the Greek letter pi in an XML document using the decimal representation "π" or the hexadecimal representation "π". An XML processor must expand numeric character references immediately on parsing them and must treat them as character data.
3.4.8 Processing InstructionsA processing instruction (PI) is an explicit mechanism for embedding information in a document intended for an application rather than for the XML parser or browser. PIs are not part of an XML document's character data. A processing instruction begins with a target that identifies the application to which the instruction is directed. The XML processor must pass PIs on to the appropriate application. The application then decides how to handle the instructions. Applications that do not recognize the instructions simply ignore them. Processing instructions have the following form: <?APPLICATION_NAME INSTRUCTIONS?> Notice that the XML declaration that appears on the first line of an XML document looks like a processing instruction (see Example 3-4) but is not. See Example 3-9 for another example of a processing instruction. You can declare the PI target beforehand using a NOTATION declaration as shown in this example. Chapter 4 discusses NOTATION declarations in more detail. The PI data for the PI target application should appear in a format that the application can interpret. Note that PIs are not required to have data after the target. Only the application recognizes data following the PI target. The XML Recommendation reserves the target name "xml" in any capitalization, including mixed capitalization, for standardization in future versions of the specification. Example 3-9 Sample processing instruction<!NOTATION mybirdapp SYSTEM file://mydir/birdapp.exe> <?mybirdapp Do_this?>
|


EAN: 2147483647
Pages: 186