| We'll complete this appendix by looking at how we can alter the operation of regexes with the various suffixes listed in Table C-8, including /g used in the double-word substitution in the previous section. Table C-8. Match and substitution suffix modifiers | Suffix | Description | | /i | Matches ignore alphabetic case, so m/http/i will pick up http , Http , HTTp, and HTTP , as well as every other possible combination of these letters . | | /g | Matches: Used in matches for globally parsing strings into sub-units. Substitutions: Used within substitutions for globally replacing all matches found, as well as the first one found in the left-most position. | | /s | Most often used with data that contains embedded \n newline characters . The /s suffix allows the . (dot) character to match \n newlines in addition to everything else. All input therefore effectively becomes a single line. (Use this suffix with care, especially in combination with greedy multipliers.) | | /m | Often used in combination with /s . The /m suffix modifies the behavior of the ^ and $ end anchors. Instead of being fixed to the ends of the match, /m allows these anchors to occur wrapped around \n newlines, with $ coming just before \n , and ^ coming just after \n . This allows a single-line data entry to be treated as multiple lines. An extended example of this, in combination with /s , can be found in Figure C-9. | | /o | There are usually two parse operations associated with each regular expression. The first expands any embedded variables that may make up the matches and replacements . The second then computes the actual regular expression. Both of these operations possess a processing hit, which you may wish to avoid on a regex within a million-row loop. To compile a regex only once, the first time it is used you can use the /o suffix. | | /e | Only used within substitutions. This evaluates the replacement on the right-hand side, as if it were an ordinary code expression. | | /x | Used to make regexes clearer. This suffix ignores most whitespace, allowing indentation, and also allows comments within the match pattern. | /i ” Ignore Case The /i suffix simply makes the match ignore the alphabetic case on the match side of the equation. Consider the following example. We have the following file to process: http Http HTtp HTTp HTTP hTTP htTP httP We'll work this through following code snippet, which has yet to use the /i suffix: while(<>){ print if /http/; # No /i suffix } This processes the file to produce: http Now we'll change the code snippet to include the /i suffix: while(<>){ print if /http/ i ; # /i suffix in place } The code now totally ignores case, and prints the following list: http Http HTtp HTTp HTTP hTTP htTP httP /g ” Global Matching When used with the match operator, the global suffix /g will gradually break down a string into parsed components , as shown in Example C-4. Global matching ” parseGlobal.pl #!perl -w $_ = "/usr/local/apache/conf/httpd.conf"; while (m#/([\w.]+)# g ){ print , "\n"; } When executed, parseGlobal.pl breaks down the input string into its wordy components: $ perl parser.pl usr local apache conf httpd.conf Let's look at some examples of global replacements: -
The global suffix is more often used with substitution, as with its sed program ancestor , to replace all matches found. This usually occurs in the following way: s/$match/$replacement/ g -
The following code snippet has yet to use the global suffix to deal with the two major fortresses of Morgoth, Sauron's old master, in the First Age of Middle-Earth: $_ = "Angband Angband Angband"; s/Angband/ Utumno /; print; -
When executed, this returns: Utumno Angband Angband -
The following code is identical, except for the addition of the /g suffix: $_ = "Angband Angband Angband"; s/Angband/ Utumno / g ; print; -
This returns: Utumno Utumno Utumno /s & /m ” Single- and Multiple-Line Matching The /s and /m suffixes are often used in combination, especially when many lines of data have been packed into a single scalar variable. Their combined use can best be seen in Figure C-9. Figure C-9. Single- and multiple-line suffixes 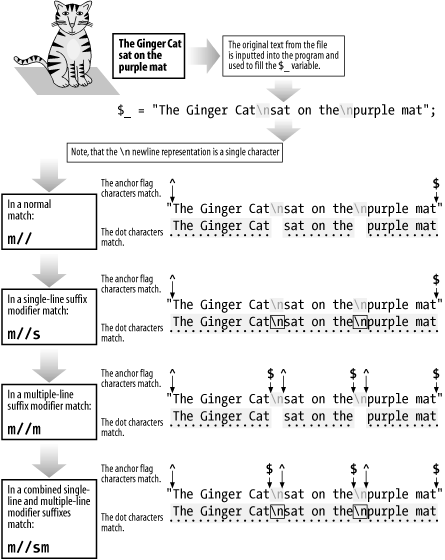 /o ” Compile Only Once To avoid recompiling regexes unnecessarily, you can use the /o suffix. A typical usage of /o is shown in the following example: -
We have the following constantly changing diary file: Wed: Mow Lawn Mon: Sell Donuts Sun: Meet President Sat: Save World Tue: This must be Belgium Thu: Shred Evidence Sun: Change Oil on Car Fri: Buy Monkey Nuts -
Every day we run the following program to work out our daily routine. This had been taking three nanoseconds too long, so we added the /o suffix to get the regex compile time down a bit, as the regex needs compiling only once within the loop: #!perl -w @time_array = localtime; @day_array = ('Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat'); $today_match = $day_array[ $time_array[6] ]; print "Appointments for ", $today_match, "day\n\n"; while(<>){ print if /$today_match/ o ; } -
Today happens to be Sunday, so let's find out what we'll be doing later by executing the program on the appointments file: Appointments for Sunday Sun: Meet President Sun: Change Oil on Car This leaves us with an interesting clothing choice! It's often tempting to spice up many Perl programs via a liberal use of the /o suffix, but beware. Many Perl programmers have spent many long hours tracking down impossible "I-must-be-going-mad" bugs , finally realizing that they should have removed the /o suffixes. No matter what value $today_match goes to in the previous example, the regular expression will continue to search for Sun until the cows come home in the twenty-third century. /e ” Evaluations Often overlooked, /e is a rough diamond of a suffix and is especially useful for mathematical and scientific munge purposes. Basically it takes the right side of a substitution and evaluates it as a code expression, as if embedded in a do{...} code block. Let's run through a quick example: -
We have a file containing two columns of numbers for working out gravitational firing points for the Mars Lander project: 34.5 87.33 99300.3002 459020 17777.3 2 32.880993 999999999999.3314 13.4 26.42140 -
We need to add all these figures together to work out our analysis, and the buttons on our calculator are getting a bit wobbly. We need to make sure that our results are right, so we write the following Perl snippet: while(<>){ s/([\d.]+)\s+([\d.]+)/ + /e; printf("-> %20s + %20s = %20s", , , $_); } -
The crucial regex is: s/ ([\d.]+) \s+ ([\d.]+) / + /e Breaking this down, the first thing we do is to pick out one or more digits or decimal points, and save these into $1 via the use of backreference brackets: [4] [4] Remember that . (dot) characters within class ranges lose their specialness, and become mere full-stops or decimal points. ([\d.]+) We then look for one or more spaces, so we can throw them away: \s+ We now look for a second number, which may contain a decimal point. We save this into $2 : ([\d.]+) The /e suffix then wraps a do{...} block around the $1 + $2 expression. Logically, the expression now looks like this: s/([\d.]+)\s+([\d.]+)/ do { + } /e -
The expression can now be evaluated. We substitute the sum into the $_ variable, which previously consisted of the two numbers separated by spaces. Running the code snippet over the file, we get the following results. -> 34.5 + 87.33 = 121.83 -> 99300.3002 + 459020 = 558320.3002 -> 17777.3 + 2 = 17779.3 -> 32.880993 + 999999999999.3314 = 1000000000032.21 -> 13.4 + 26.42140 = 39.8214 We can now begin our Mars Lander rocket firing pattern analysis with confidence. You may think /e is pretty clever, but it gets better. You can wrap unending amounts of eval{...} commands around the original do{...} code block by adding an extra evaluation command to the suffix, /ee . This will take whatever the first expression evaluation gives you, and then evaluate it, so that the following two lines are equivalent: s/PATTERN/CODE/ee s/PATTERN/eval(CODE)/e Let's work through another example to cover it: -
This time we have the following three-column file: 134.5 + 87.33 99.3 - 45.3 17.3 + 2 100.03 - 4.12 100 + 9 -
Notice that the mathematical operation we wish to use on the two numbers is the second column within the file. Unfortunately, we only find out what each one is when we're actually processing the line. We therefore have to select this operator out from the file, build up the code string, and then evaluate its outcome before printing the formatted results. We do this via the following code snippet: while(<>){ s/([\d.]+)\s+([+-])\s+([\d.]+)/"$result = "/ ee ; printf("-> %8s %1s %-8s = %9s\n", , , , $result); } -
Let's break down the regular expression: s/( [\d.]+ )\s+( [+-] )\s+( [\d.]+ )/"$result = "/ ee On the left side, we once again store the first number into $1 : ( [\d.]+ ) We then throw away some spaces on either side of the mathematical operation we wish to perform. [5] The calculation will either be an addition or a subtraction, and will be stored in $2 : [5] Notice how we have the hyphen, indicating the minus sign, as the second character inside the class range [+-] . This prevents Perl from marking it as some kind of a class range. \s+( [+-] )\s+ We then pick up the second number and store it into $3 : ( [\d.]+ ) -
On the right-hand side of the regex, we build up a string that will perform the required operation upon our two numbers, and then store the calculated number into the $result variable. We've backslashed $result to prevent it from being interpreted as an empty string, within the string evaluation: "$result = " This code is then evaluated via the eval{...} double-e suffix: / ee -
The results can now be printed out: -> 134.5 + 87.33 = 221.83 -> 99.3 - 45.3 = 54 -> 17.3 + 2 = 19.3 -> 100.03 - 4.12 = 95.91 -> 100 + 9 = 109 /x ” The Expressive Modifier You may have noticed that some of the regexes we've talked about were starting to get rather long and trickier to follow until we broke them down across several lines. This is where /x steps out from behind the curtain. Some years ago, Jeffrey Friedl, author of Mastering Regular Expressions , was replying to a regex question on comp.lang.perl.misc when he pretty-printed a very large regular expression to make it easier to read. Larry Wall saw the post and liked it so much that he immediately added the /x suffix to Perl. This made it possible for everyone to create indented regexes containing embedded comments. Essentially, within /x regexes you can use any amount of whitespace, and the regex will ignore it. You can also put comments within the regex, prefixed by the usual Perl # hash comment character. If you do want to include spaces or # hashes within the actual regex, you merely backslash them, or use the \s escape for spaces. Let's work through a regex problem and see how we can help solve it more clearly with the assistance of /x : We have an Oracle PL/SQL program file, mars_rocket.sql , which has some C-style comments within it which we wish to remove. There is a reason for this, but it's classified : /* Create this procedure to fire the positioning rockets when we approach the Martian surface. */ CREATE OR REPLACE PROCEDURE mars_rocket (v_thrust_in IN NUMBER) AS v_momentum NUMBER; /* Adjustment factor */ v_twist NUMBER; /* Rotational factor */ BEGIN /* Loop and then fire. */ LOOP EXIT WHEN v_thrust_in = 0; v_twist := v_thrust_in + mars_env.gravi_bind; /* Newton :-) */ v_momentum := v_thrust_in + mars_env.mass_emc; /* Einstein :-) */ mars_env.fire_retros(v_twist, v_momentum); /* Fire in the hole */ END LOOP; /* Fired and forgotten. */ END mars_rocket; / Example C-5 shows our program to remove these comments, making use of the /x suffix. Removing C-style comments with the /x suffix ” xErase.pl #!perl -w # Open the target file, and the target. open(MARS_IN, $ARGV[0]) or die "Could not read $ARGV[0]"; open(MARS_OUT, ">$ARGV[1]") or die "Could not open $ARGV[1], to write to"; # Slurp the entire file $/ = undef; # Houston, - Undefining the input record separator. $_ = <MARS_IN>; # Entire file slurped into # the single default $_ variable. # The main substitution begins : s{ # The search pattern brackets are {} , # and the replacement brackets are [] . # We're removing all C-style comments, so # the replacement is completely empty . /\* # We're looking for the C-style comment # start marker. We have to escape the # Kleene Star, to make it a normal asterisk . .*? # We're then looking for any character , # including the \n newline, though we're # doing this minimally, to avoid stripping # out everything between the first comment # and the last . \*/ # We then find the first C-style comment # terminator. Once again, we've had to # backslash the asterisk . } []gsx; # The gsx suffixes mean: # # g: We're replacing every match we find within the file. # s: Because we've slurped the entire file into a single variable, # including \n newlines, we need to treat the entire thing as a # single line, so . dot will match \n newlines, and catch comments # which spread over more than one line. # x: The "expressive" syntax means we can break down a potentially # confusing regex, over many lines, and use comments :-) # Now print out the new file without C-style comments and close down. print MARS_OUT $_; close(MARS_IN); close(MARS_OUT); Because of the /x suffix within the program, we can now fully expand the match pattern with white space, and pepper it with plenty of comments. This will help our Marsonauts figure out what our regex is trying to do when they come to maintain the script halfway through on the trip out. Now we test run the program, to create the mars_bar.sql output file: $ perl xErase.pl mars_rocket.sql mars_bar.sql The mars.bar.sql output file has now had all of its C-style comments removed: CREATE OR REPLACE PROCEDURE mars_rocket (v_thrust_in IN NUMBER) AS v_momentum NUMBER; v_twist NUMBER; BEGIN LOOP EXIT WHEN v_thrust_in = 0; v_twist := v_thrust_in + mars_env.gravi_bind; v_momentum := v_thrust_in + mars_env.mass_emc; mars_env.fire_retros(v_twist, v_momentum); END LOOP; END mars_rocket; / We can almost see Tom Hanks, getting excited about this in the follow-up movie. Splitting Up is Easy To Do As promised , we need to dissect the split operator, which basically splits up strings into array lists with the following differing input patterns: split /PATTERN/, EXPRESSION, LIMIT split /PATTERN/, EXPRESSION split /PATTERN/ split The operator takes a regex /PATTERN/ , and then splits the EXPRESSION string value by it into a list (usually an array). If LIMIT is specified, the maximum size of the list will be this value; otherwise , the list will be as long as it needs to be. For instance: @a = split /:/, "andyd:banana:/bin/ksh:dba"; print scalar @a, "\n"; # Size of array print "@a", "\n"; # Prints interpolated array Notice how the LIMIT value of 3 above changes the output below, retaining the : colon within the third and last element: 3 andyd banana /bin/ksh:dba If EXPRESSION is omitted, the current value contained within $_ is used. If /PATTERN/ itself is omitted, the regex split pattern assumed is /\s+/, for a split on any amount of white space. This is particularly useful for splitting up columnar output: $_ = "-rw-r--r-- 1 jkstill 766 22:49 sqlnet.log"; @a = split; # => split /\s+/, $_; print scalar @a, "\n"; # Size of array print "@a", "\n"; # Prints interpolated array This produces the following interpolated output, showing the size of the new @a array and then its six discrete elements: 6 -rw-r--r-- 1 jkstill 766 22:49 sqlnet.log | This appendix barely touches upon Perl's regular expression capabilities. There is much more to discover. (The Camel and Owl books are good places to start, as is the online perldoc perlre command.) Nobody ever stops learning about regexes. Just when you think you possess a complete knowledge, another little wrinkle turns up. This is especially true today with the growing use of Unicode. But hey, where would life be if every day were utterly predictable? As Mithrandir said to Sam, Merry, and Pippin at the Grey Havens, on the last day of Middle-Earth's Third Age: Well, here at last, dear friends , on the shores of the Sea comes the end of our fellowship in Middle-Earth. Go in peace ! I will not say: do not weep; for not all regexes are an evil. |