Scheduling: processes and threads
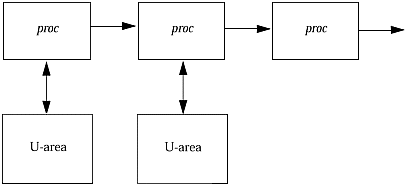
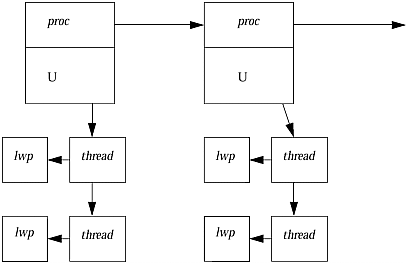
| The kernel scheduler is the section that decides what should be run next and starts it up. This usually involves a context switch ; the complete set of state information for the currently executing code must be saved so it can be continued later, and state information for another process must be loaded to resume its execution. This context data includes the complete set of registers in the CPU, the stacks ( user stack and kernel stack), and the pages that were in use and in memory for that process. One of the major changes between the kernel in SunOS 4.x and in Solaris 2 was the modification to allow multiple threads of control within one user process. A thread of control could be viewed as a place where work is being done. For some programs, it's possible to do some things in parallel: One section of the program can essentially be run independently of another. For "single-threaded" systems like the original UNIX kernel, actually doing this would require you to create a new process to run independently and do the work separately. Modern "multithreaded" kernels do allow several parts of a user program to be active at once, usually because they provide more than one CPU, which could be simultaneously running user code. There is no reason to restrict these processors to working with different user programs, so if the code allows it, more than one thread of control could be active and in execution at one time. This means that in SunOS 4.x, the process is the basic scheduling entity. In Solaris 2, one of the process's threads is what gets scheduled. In either case, the system still needs to keep track of processes and process-specific information, as well as scheduling parameters, state information, and a kernel stack. This is done with several structures; we'll look at each version of the OS separately, although there are many things in common. SunOS 4.xThe main pieces of information needed by the scheduler are contained within the process table. Figure 19-2. SunOS 4.x Process Table The process table is a linked list of proc structures that describe processes and their various states. Those that are actually runnable are normally linked together on a separate list. Each process table entry contains enough information to schedule that process and to find the rest of it in case it's been swapped out to disk. This set of structures is used and updated primarily by the scheduler, but other things may change a process into a "runnable" state. Often device driver interrupt routines will do this when I/O is completed or when data arrives to be read. The information needed to actually run the process is contained in the U-area, or user structure. This area includes pointers to open files, the current working directory, the effective user ID, and the context (register contents, PC value, stack). This may be swapped out to disk if necessary; the kernel maintains a pool of U-areas for active processes and swaps idle structures out to make room. When analyzing a core dump, you may not see any information about what a process is doing if it has been idle for a long period: all the information about that process's state, including the kernel stack, is not in the core file because it was not in memory. Process structures are defined in /usr/include/sys/proc.h ; the definition of a user structure can be found in /usr/include/sys/user.h . Solaris 2In Solaris 2, the information needed to run an individual thread of control is contained in a kernel thread structure rather than in the process's user structure. This makes the U-area significantly shorter (since a lot of information was pulled from it), so the remainder is now attached to the end of the process table structure, and a linked list of threads is attached to each process. Thus, each process table entry contains all the process-wide information, but each possible thread of control has its own structure containing the necessary state information. Along with the thread structure is an lwp structure, one per thread. The lwp structure contains the less commonly used data about a particular thread (accounting, for instance). Just as the U-area in SunOS 4.x contained process information that could be swapped out, the lwp contains thread information that can be swapped to disk if necessary. These structures are defined in various /usr/include/sys header files. Look for thread.h, proc.h , usr.h , and klwp.h . (Note that lwp.h does not refer to kernel lwp structures!) Figure 19-3. Solaris 2 Processes and Threads Here, you can see that the per-process information contained in the U-areas and proc structures includes a pointer to a list of structures containing information about each thread of control. Normally, processes contain only one thread. It takes special coding, libraries, and initial design work to build a multithreaded process. The kernel itself does have multiple internal threads that all link to the process table entry for sched , the scheduler. These "system" threads are scheduled and handled just like user program threads, although with a higher priority. They include NFS handlers, Streams management functions, interrupt service routines, and the page daemon. |
EAN: 2147483647
Pages: 289
- Understanding SQL Basics and Creating Database Files
- Using SQL Data Manipulation Language (DML) to Insert and Manipulate Data Within SQL Tables
- Writing External Applications to Query and Manipulate Database Data
- Repairing and Maintaining MS-SQL Server Database Files
- Exploiting MS-SQL Server Built-in Stored Procedures