Section 1.5. Routing in the ARPANET
1.5. Routing in the ARPANETBy the time of the NCP-to-TCP/IP transition at the beginning of 1983, two communities were using the ARPANET: military operations and university/corporate researchers. Particularly in the second community, a tremendous number of graduate students was learning to appreciate and use the network in ways that would quickly influence the business community. They were also using the network for some distinctly nonresearch activities such as gaming. As a result of this large and growing user population, the Department of Defense became concerned about security, and decided to move their nodes to a separate network called the MILNET. But they wanted to continue to have access to the ARPANET nodes, so the two networks remained connected through a gateway. The separation was really just one that provided separate administrative control; the users on both networks didn't notice the difference. The transition to TCP/IP made such a split possible. Other networks also began cropping up and interconnecting, both in the United States and in Europe. The one with the most important long-range impact was the NSFNET, begun by the National Science Foundation in 1985. Originally intended to interconnect five supercomputer sites over 56kbps links, the network links were upgraded to T1 in 1988 and then T3 (45Mbps) beginning in 1990. NSFNET connected universities and corporations all around the country; more important, it offered free connectivity to the regional networks cropping up around the country. ARPANET's slow links and its old IMPs and TIPs, plus its restrictive access polices, meant that by the late 1980s most users were connected to other networks. DARPA decided it was time to decommission the 20-year-old network. One by one, its sites were transferred to one of the regional networks or to the MILNET, so that by 1990 the ARPANET ceased to exist. But as this short historical overview has shown, almost all of the internetworking technologies we use to this day had their start with the ARPANET. That includes the topic of this book, routing. By the mid-1980s, a number of companies had sprung up to sell commercial versions of gateways, called routers: 3Com, ACC, Bridge, Cisco, Proteon, Wellfleet, and others. They all used routing algorithms first explored in the ARPANET. Interestingly, engineers at BBN had tried to encourage the company to get into commercial routers, but their marketing department decided that there was no future in it. The first routing protocol used in the ARPANET was designed in 1969 by Will Crowther, a member of the original IMP team at BBN. Like all routing protocols, it was based on mathematical graph theoryin this case, the algorithms of Richard Bellman and Lester Randolph Ford. The Bellman-Ford algorithm forms the basis of most of a class of routing protocols over the years called distance vector protocols. Crowther's protocol was a distributed adaptive protocolthat is, it was designed to adapt to quickly changing network characteristics by adjusting the link metrics it used (adaptive), and the routers cooperate in calculating optimal paths to a destination (distributed). Crowther's routing protocol used delay as its metric. The delay was estimated at each IMP by counting, every 128 milliseconds, the number of packets queued for each attached link. A constant, representing a minimum cost, was added to the counts to avoid an idle link being given a metric of zero.[21] The more often the queue length was measured, the more quickly each IMP could detect and adapt to changing link delays. The result, it was theorized, was that traffic distribution should be fairly balanced on all outgoing trunks to a given destination.
At each new count, the IMP's routing table was updated, and then the routing table was advertised to its neighbors. Neighbors, on receiving the table, estimated the delay to the advertising IMP, added the results to the information in the received table, and used the sums to update the information in their own tables about destinations reachable via the advertising IMP. Once updated, the neighbors advertised their own tables to their neighbors. The distributed nature of the routing calculation, then, came from the iterative advertising and updating of tables across the network. This original protocol served the ARPANET well for its first decade of life. Under light traffic loads, the routing decisions were determined mainly by the constant added to the estimated delay. Under moderate loads, congestion might arise in isolated areas of the network; the measured queue lengths in these areas became a factor, and traffic was shifted away from the congestion. But the protocol began showing increasing problems as the ARPANET grew larger and traffic loads grew heavier. Some of the problems had to do with the way the metric was determined:
Additionally, problems with the distance vector approach itself began arising:
In 1979, BBN deployed a new ARPANET routing protocol, developed by John McQuillan, Ira Richer, and Eric Rosen.[22] The new protocol introduced three significant changes from the original:
The improved metric determination meant less thrashing of routes. Rather than counting queued packets, the IMP timestamped each arriving packet with an arrival time. Then when the first bit of the packet was transmitted, the packet was stamped with its transmit time. When an acknowledgement of the packet was received, the arrival time was subtracted from the transmit time. Then a constant (called a bias)[23] representing the propagation delay of the line on which the packet was transmitted and a variable representing the transmission delay (based on packet length and line speed) were added to the difference between the arrival and transmit times. The resulting value was a more accurate measure of true delay. Every 10 seconds, the average of these measured delays for each attached link was taken, and this average became the metric for the link. By taking an average, the problems associated with using an instantaneous measurement were avoided.
The second change, reduced update frequency, was accomplished by setting a threshold that began at 64 milliseconds. When the 10-second average delay was calculated, the result was compared with the previous result. If the difference did not exceed the threshold, no update was sent, and the threshold was reduced by 12.8ms for the next comparison. If the threshold was exceeded, an update was sent, and the threshold was reset to 64ms. This decaying threshold ensured that big metric changes were advertised quickly and small changes were advertised slower. If no metric change occurred, the threshold would decay to 0 in 50 seconds causing an update to be sent even if no metric change had occurred. As a result of this new algorithm, the frequency of updates and the associated bandwidth consumption was sharply reduced. Also important was what was in the update. Rather than sending the routing table to neighbors, each IMP sent only the metrics of its local links; the update would be sent throughout the network (the designers called the procedure "flooding"), and each IMP would keep a copy in a database. An IMP did not have to perform its local calculation before forwarding the update. This had two beneficial effects: The updates themselves were smallaveraging 176 bitsfurther reducing bandwidth consumption; and because the updates were flooded to all IMPs quicklywithin 100msthe network could react to changes more quickly. Using sequence numbers, ages, and acknowledgments ensured accuracy and reliability of the flooded metrics.[24]
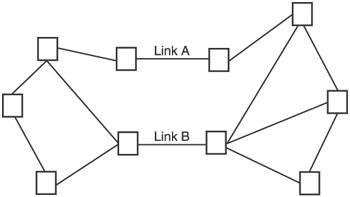
The third significant change, and the one most important to this book, is that instead of the Bellman-Ford algorithm the protocol calculated routes based on an algorithm created by graph theorist Edsger Dijkstra. Each IMP used its database of metrics flooded from all IMPs to calculate locally the shortest path to all other IMPs. This procedure sharply reduced the looping that had begun plaguing the ARPANET under the previous routing protocol. McQuillan, Richer, and Rosen called their Dijkstra-based algorithm a shortest-path-first (SPF) algorithm. It was the first link state protocol widely used in a packet switching network. The second routing protocol was used in the ARPANET for eight years, until once again problems arose due to the inability of the algorithms to scale to the continued network growth. But this time, the SPF algorithms were unchanged; it was only the adaptive metric calculation that was problematic. The three factors that the previous protocol used to calculate delay were queuing delay (represented by the difference between transmit time and arrival time), link propagation delay (based on the constant), and link transmission delay (based on packet length and line speed). Under low traffic loads, the effect of the queuing delay was negligible. Under medium loads, the queuing delay becomes a more significant factor but results in reasonable shifts in the traffic flows. Under heavy loads, however, the queuing delay becomes the major factor in the computation of the metric. At this point, the queuing delay could cause route oscillations. Take, for example, the network of Figure 1.2. Two links, A and B, connect two regions of the network; all traffic between the "east" and "west" regions must use one of these two links. If most routes use link A and the load across the link is heavy, the queuing delay for that link becomes high, and a high delay value will be advertised to all the other nodes. Because the other nodes run their SPF calculations more or less simultaneously, they will simultaneously come to the same conclusion: that A is overloaded and B is a better path. All traffic then shifts to B, causing B to have a high delay; at the next measurement, B's high delay is advertised and all routes shift back to the now underutilized A. A is now seen as overloaded, traffic switches again to B, and so on; the oscillations could go on indefinitely. At each shift, the load causes a large change in the link metrics and as a result as soon as the shift occurs the metrics that caused the shift become obsolete. Figure 1.2. The original adaptive metric calculation of the second ARPANET routing protocol could cause route oscillations between parallel links such as A and B shown here. To address the problem, in 1987 a new metric calculation algorithm designed by Atul Khanna, John Zinky, and Frederick Serr of BBN was deployed.[25] The new algorithm was still adaptive, and still used a 10-second average delay measurement. Under light to medium loads, its behavior was not very different from the previous metric algorithm. The improvement was seen in how the algorithm operated under heavy loads. The metric is no longer delay but a function of delay, and the range of metric variation is confined so that in a homogeneous network the relative metrics between two otherwise equal paths cannot vary by more than two hopsthat is, traffic cannot be routed around a congested link over more than two hops. All this is a function of link utilization; when utilization is light, the algorithm behaves as if the metric is delay based, and as utilization increases it behaves as if the metric is capacity based.
While the metric calculation algorithm for the ARPANET was changed, the SPF algorithm underwent only a minor change: Calculations were performed in such a way that routes were moved off of an overutilized link gradually rather than all at once, reducing the potential for heavy route oscillations. A description of the metric calculation algorithm itself is impractical for the needs of this book, and that says something about adaptive routing algorithms in general: Distributed adaptive algorithms involve significant complexity to be effective. As a result, most adaptive algorithms used in modern packet switching networks for functions such as traffic engineering are centralized rather than distributed. The link state routing protocols that grew out of the early ARPANET experiences have used fixed rather than adaptive metrics.
|
EAN: 2147483647
Pages: 111