Process Attributes
| Numerous data structures associated with each process are typically maintained in the system kernel and exposed to end users with varying degrees of transparency. This section isolates the process attributes and behaviors that are most important when evaluating an application's security. The attack surface available to malicious local users invoking a privileged application is largely defined by those process attributes that they are able to directly control. In particular, attributes that are inherited from the invoking application must be handled with exceptional care by the privileged application, as they are essentially in an undefined state. As such, process attribute retention is the initial focus of this section. You will see what kind of attributes a process inherits from its invoker and what kind of a risk that each attribute class represents. The next step is to consider the security impact of process resource limits. This section will show you how resource limits affect the running of a process, and how careful manipulation of these limits can have interesting security consequences. The semantics of file sharing across multiple processes and program executions is also considered, to give you an idea of how implicit file descriptor passing can result in dangerous exposures of sensitive data. You finish up with a study of the process environment array, which contains a series of key/value pairs that are intended to express user and system preferences for the application to utilize at its discretion. Finally, you examine groups of processes used by UNIX systems to implement job control and an interactive terminal user interface. Process Attribute RetentionThe execve() system call is responsible for loading a new program into process memory and running it. Typically, it involves getting rid of memory mappings and other resources associated with the current program, and then creating a fresh environment in which to run the new program file. From a security standpoint, you need to be aware that the new process inherits certain attributes of the old one, which are as follows:
Many attributes listed here can be the source of potential vulnerabilities when the old and new processes run with different privilegesthat is, when a privileged process is called or when a privileged process drops its permissions and calls an unprivileged application. Bear in mind that the following discussion focuses on the most common scenarios a program might encounter when traversing an execve(). There might be other situations in which privileged applications honor specific attributes in such a way that they're exploitable. Resource LimitsResource limits (abbreviated as "rlimits") are a process-specific set of attributes that enforce restrictions on the system resources that a process may use. The geTRlimit() and setrlimit() functions allow a process to examine and modify (to a certain extent) its own resource limits. There are multiple resources for which each process has defined limits. For each defined system resource a process has two associated resource values: a soft limit and a hard limit. The soft limit value is more of a warning threshold than a limit, in that the process may not exceed it but it is free to change the soft limit up or down as it pleases. In fact, a process is free to move the soft limit so that it's any value between zero and its hard limit. Conversely, a hard limit represents the absolute maximum resource usage that a process is allowed. A normal process can change its hard limit, but it can only lower it, and lowering a hard limit is irreversible. Superuser processes, however, can also raise hard limits. The following list of supported resource limits can be called and set via setrlimit() and getrlimit() in Linux; other UNIX systems support some or all of these values:
Rlimits are useful for developers to curtail potentially risky activities in secure programs, such as dumping memory to a core file or falling prey to denial-of-service attacks. However, rlimits also have a dark side. Users can set fairly tight limits on a process and then run a setuid or setgid program. Rlimits are cleared out when a process does a fork(), but they survive the exec() family of calls, which can be used to force a failure in a predetermined location in the code. The reason that setting limits is so important is that developers often don't expect resources to be exhausted; as a result, even if they do handle the error to some degree, the error-handling code is usually less guarded than more well-traveled code paths. When developers do devote effort to securing error handling code, it is usually focused on dealing with input errors, so they rarely devote much effort to handling resource exhaustion securely. For example, take a look at Listing 10-2 taken from the BSD setenv() implementation. Listing 10-2. Setenv() Vulnerabilty in BSD
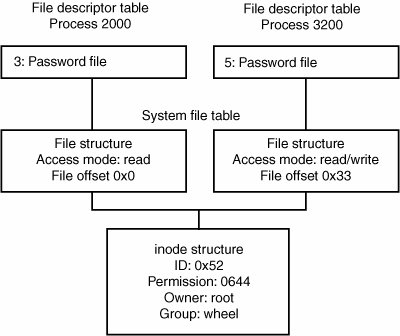
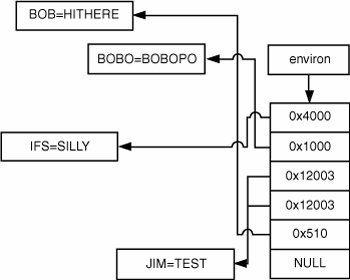
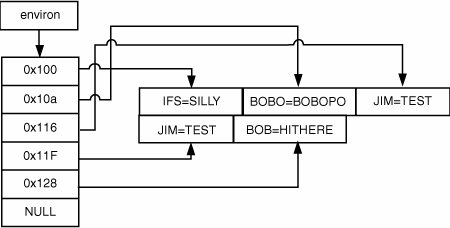
Obviously, it's unlikely for any of these calls to malloc() to fail, and their failure certainly isn't expected. Say alloced is set to 0 and malloc() does fail, however (shown in the bolded code lines). In this case, alloced will be set to 1 to indicate that the environment is allocated dynamically, but environ is never updated because the call to malloc() failed. Therefore, subsequent calls to setenv() cause the original stack buffer that environ still references to be passed as an argument to realloc() as if it is a heap buffer! Although it might be possible for users to exhaust resources naturally, triggering these code paths can often be complicated, and that's where setting resource limits comes in. Say you want a call to malloc() to fail at a certain point in the code; this might not even be possible if the program hasn't dealt with enough input data yet. Even if it has, because malloc() occurs so often, making a specific call fail is difficult. Using setrlimit(), attackers can have some control over the amount of total memory the process can consume, which gives them a chance to trigger the vulnerable code path fairly accurately. Michael Zalewski, a noted security researcher, noticed a similar problem in the way that crontab functions (archived at http://seclists.org/bugtraq/1998/Feb/0018.html). When crontab first starts, it creates a root-owned temporary file in the crontab directory. It reads the user's crontab file and copies it to the temporary file. When the copy is completed, crontab renames this temporary file with the user's name so that the cron daemon parses it. Zalewski noticed that if you submit a file large enough to reach the resource limit for the file size, the soft limit signal kills crontab while it's still writing the file, before it can rename or unlink the temporary file. These temporary files stay lodged in the crontab directory and evade quotas because they are owned by root. Rafal Wojtczuk explained in a bugtraq post how he was able to exploit a problem in old versions of the Linux dynamic loader. Take a look at the following code: int fdprintf(int fd, const char *fmt, ...) { va_list args; int i; char buf[1024]; va_start(args, fmt); i=vsprintf(buf,fmt,args); va_end(args); write(fd, buf, i); return i; } ... static int try_lib(char *argv0, char *buffer, char *dir, char *lib) { int found; strcpy(buffer, dir); if (lib != NULL) { strcat(buffer, "/"); strcat(buffer, lib); } if (!(found = !uselib(buffer))) { if (errno != ENOENT) { fdprintf(2, "%s: can't load library '%s'\n", argv0, buffer); fdprintf(2, "\t%s\n", strerror(errno)); } } return found; }The TRy_lib() function is called by the dynamic loader to see whether a library file is present. It constructs the pathname and then attempts to call uselib(), which is a Linux system call that loads a shared library. uselib() returns errors similar to open(), such as ENFILE. If the shared library file can't be opened, the loader constructs an error message using fdprintf(). This function obviously has a buffer overflow with its use of vsprintf() to print into the 1024-byte stack buffer buf. If users can trigger the error that results in a call to fdprintf() and supply a long argv0 string when loading a setuid binary, they are able to exploit the overflow. To exploit this error, Wojtczuk had to time it so that the system consumed the total limit of file descriptors right before the loader attempted to load the library. He came up with a clever attack: He used file locking and the close-on-exec flag to ensure that his exploit program ran immediately after the exec() system call was completed and before the kernel invoked the dynamic loader. His exploit program then sent a SIGSTOP to the setuid program that ran, consumed all available file descriptors, and then sent a SIGCONT. When processing returned to the dynamic loader, no file descriptors were left to be allocated, causing the error message to be printed and the buffer overflow to occur. In addition, a program that writes data to a sensitive file might be exploitable if rlimits can be used to induce unexpected failure conditions. RLIMIT_FSIZE enforces a maximum limit on how many bytes a file can be that a process writes to. For example, setting this value to 5 means that any write() operation to a file will fail once the file becomes larger than 5 bytes in length. A single write() on a new file, therefore, results in five bytes being written to the file (and write() successfully returns 5). Any subsequent writes to the same file fail, and a SIGXFSZ signal is sent to the process, which will terminate if this signal doesn't have a handler installed. A file being appended to fails when its total size exceeds the value set in RLIMIT_FSIZE. If the file is already larger than the limit when it's opened, the first write() fails. Because signal masks are also inherited over an exec() system call, you can have a privileged program ignore the SIGXFSZ signal and continue processing. With the combination of setting a signal mask and imposing a file resource limit (RLIMIT_FSIZE), you can arbitrarily cause file writes to fail at any place you choose. For example, consider a setuid root program that does the following: struct entry { char name[32]; char password[256]; struct entry *next; }; int write_entries(FILE *fp, struct entry *list) { struct entry *ent; for(ent = list; ent; ent = ent->next) fprintf(fp, "%s:%s\n", ent->name, ent->password); return 1; }This code iterates through a linked list of username/password pairs and prints them to an output file. By using the setrlimit() function to set RLIMIT_FSIZE, you can force fprintf() to print only a certain number of bytes to a file. This technique might be useful for cutting an entry off just after the username: part has been written on a line, thus causing the password to be truncated. Auditing Tip Carefully check for any privileged application that writes to a file without verifying whether writes are successful. Remember that checking for an error when calling write() might not be sufficient; they also need to check whether the amount of bytes they wrote were successfully stored in their entirety. Manipulating this application's rlimits might trigger a security vulnerability by cutting the file short at a strategically advantageous offset. Often code reviewers and developers alike tend to disregard code built to handle an error condition caused by resource exhaustion automatically, because they don't consider the possibility that users can trigger those code paths. In short, they forget about setting resource limits. When you're auditing applications that interact with system resources, make sure you address this question: "If I somehow cause a failure condition, can I leverage that condition to exploit the program?" Auditing Tip Never assume that a condition is unreachable because it seems unlikely to occur. Using rlimits is one way to trigger unlikely conditions by restricting the resources a privileged process is allowed to use and potentially forcing a process to die when a system resource is allocated where it usually wouldn't be. Depending on the circumstances of the error condition you want to trigger, you might be able to use other methods by manipulating the program's environment to force an error. File DescriptorsMany security-related aspects of UNIX are properties of how file descriptors behave across process creation and execution. You know that file descriptors are duplicated when a process is forked, and you've seen how the processes end up sharing their access to an underlying file object through these duplicated file descriptors. A process can also explicitly make a copy of a file descriptor, which results in the same underlying semantics as a file descriptor duplicated through forking. This copying is usually done with the dup(), dup2(), or fcntl() system calls. Processes normally pass file descriptors on to their children via fork(), but UNIX does provide ways for file descriptors to be shared with unrelated processes by using IPC. Interested readers can refer to W.R. Stephen's coverage of UNIX domain sockets in Advanced Programming in the Unix Environment (Addison-Wesley, 1992). File SharingWhether process descriptors are duplicated through fork() or the dup() family of calls, you end up with multiple file descriptors across one or more processes that refer to the same open file object in the kernel. Consequently, all these processes share the same access flags and internal file pointer to that file. If multiple processes in a system open the same file with open(), they have their own open file structures. Therefore, they have their own file position pointers and could have different access modes and flags set on their interface with the file. They are still working with the same file, so changes to file contents and properties kept in the file's inode structure still affect a file's concurrent users. You can see an example in Figure 10-2, which shows two processes that aren't related to each other. Both processes have the password file open. Process 2000 has it open as its third file descriptor, and it opened the password file for read-only access, shown in the associated open file structure. The process on the right, process 3200, has the password file for both read and write access and has advanced its file pointer to the location 0x33. The two processes have different levels of access to the password file, and they have independent file pointers that track their location in the file. Figure 10-2. Independent opens of the same file The access a process has to a file is determined when that file is opened. In Figure 10-2, process 3200 opened the password file with read/write access, so it has a file descriptor and open file pointer representing that information. If someone renames the password file, changes its permissions to octal 0000, changes its owner and group to arbitrary people, and even deletes it from the file system, process 3200 still has an open descriptor to that file that allows it to read and write. Close-on-ExecFile descriptors are retained in a process across the execution of different programs, unless the file descriptors are especially marked for closure. This behavior might not be quite what you'd expect, as UNIX tends to start most other aspects of a process over with a clean slate when a new program runs. UNIX does allow developers to mark certain file descriptors as close-on-exec, which means they are closed automatically if the process runs a new program. Close-on-exec can be a useful precaution for sensitive or critical files that developers don't want to be inherited by a subprogram. The file descriptor is usually marked with the fcntl() system call, and the kernel makes a note of it in the process descriptor table for the process. For applications that spawn new processes at any stage, always check to see whether this step is taken when it opens files. It is also useful to make a note of those persistent files that aren't marked to close when a new program starts. In the next section, you will see that haphazardly leaving these files around can have interesting consequences. File Descriptor LeaksThe possible actions a process can perform on a file descriptor are determined when the file descriptor is first created. To put it another way, security checks are performed only once, when the process initially creates a file descriptor by opening or creating a resource. If you can get access to a file descriptor that was opened with write access to a critical system file, you can write to that file regardless of your effective user ID or other system privileges. Therefore, programs that work with file descriptors to security-sensitive resources should close their descriptors before running any user-malleable code. For example, take a look at a hypothetical computer game that runs with the privileges necessary to open kernel memory: int kfd; pid_t p; char *initprog; kfd = safe_open("/dev/kmem", O_RDWR); init_video_mem(kfd); if ((initprog=getenv("CONTROLLER_INIT_PROGRAM"))) { if ((p=safe_fork())) /* PARENT */ { wait_for_kid(p); g_controller_status=CONTROLLER_READY; } else /* CHILD */ { drop_privs (); execl(initprog, "conf", NULL); exit(0); /* unreached */ } } /* main game loop */ ...This game first opens direct access to the system's memory via the device driver accessible at /dev/kmem. It uses this access to directly modify memory mapped to the video card for the purposes of performance. The game can also run an external program to initialize a game controller, which users specify in the environment variable CONTROLLER_INIT_PROGRAM. The program permanently drops privileges before running this program to prevent users from simply supplying their own program to run with elevated privileges. The problem with this code is that the file descriptor that references the /dev/kmem file, kfd, is never closed before the game runs the external controller initialization program. Even though permissions have been fully dropped, attackers could still take control of the machine by providing a malicious controller initialization program. This attack is possible because the executed program starts with an open, writeable file descriptor to /dev/kmem. Attackers would need to construct a fairly straightforward program that could modify critical kernel data structures and elevate user privileges. This example might seem a bit contrived, but it's quite similar to a vulnerability in recent versions of FreeBSD. FreeBSD's libkvm library provides access to kernel symbols, addresses, and values for programs that need to work with kernel memory. A researcher named badc0ded discovered that this library could leave file descriptors open to critical files, such as /dev/kmem, and because of the library's interface, it was difficult for application authors to prevent a leak. Although no programs in the standard FreeBSD distribution were found to use the library in an nonsecure fashion, badc0ded found several ports that could be exploited to gain root privileges. (The FreeBSD advisory can be found at http://security.freebsd.org/advisories/FreeBSD-SA-02:39.libkvm.asc.) Another classic example of a file descriptor leak vulnerability is OpenBSD 2.3's chpass program, which had a local root vulnerability discovered by Oliver Friedrichs from NAI (archived at http://seclists.org/bugtraq/1998/Aug/0071.html). chpass is a setuid root application that allows nonprivileged users to edit information about their accounts. In OpenBSD, user account information is stored in a database file in /etc/pwd.db. It can be read by everyone and contains public information about user accounts. Sensitive information, such as password hashes, is stored in the root-owned, mode 0600 database /etc/spwd.db. The system administrator works with these databases by editing the text file /etc/master.passwd, which resembles the shadow password file in other UNIX systems. After an administrator edits this file, administrative tools can use the pwd_mkdb program behind the scenes to propagate the master.passwd file's contents into the pwd.db and spwd.db password databases and to a /etc/passwd file in a compatible format for general UNIX applications to use. Chpass is one of these administration tools: It lets users edit their account information, and then it uses pwd_mkdb to propagate the changes. Chpass first creates a writeable, unique file in /etc called /etc/ptmp. When chpass is almost finished, it fills /etc/ptmp with the contents of the current master.passwd file, making any changes it wants. Chpass then has pwd_mkdb turn /etc/ptmp in the master.passwd file and propagates its information to the system password databases. The /etc/ptmp file also serves as a lock file because while it's present on the file system, no other programs will attempt to manipulate the password database. The following code (slightly edited) is taken from the vulnerable version of chpass: tfd = pw_lock(0); if (tfd < 0) { if (errno == EEXIST) errx(1, "the passwd file is busy."); else err(1, "can't open passwd temp file"); } pfd = open(_PATH_MASTERPASSWD, O_RDONLY, 0); if (pfd < 0) pw_error(_PATH_MASTERPASSWD, 1, 1); /* Edit the user passwd information if requested. */ if (op == EDITENTRY) { dfd = mkstemp(tempname); if (dfd < 0) pw_error(tempname, 1, 1); display(tempname, dfd, pw); edit(tempname, pw); (void)unlink(tempname); } /* Copy the passwd file to the lock file, updating pw. */ pw_copy(pfd, tfd, pw); /* Now finish the passwd file update. */ if (pw_mkdb() < 0) pw_error(NULL, 0, 1); exit(0);The program first uses the pw_lock() function to create /etc/ptmp, which is kept in the file descriptor tfd (which stands for "to file descriptor"). Keep in mind that chpass ultimately places its version of the new password file in /etc/ptmp. Chpass then opens a read-only copy of the master.passwd file and stores it in pfd ("password file descriptor"). This copy is used later as the source file when filling in /etc/ptmp. Chpass then creates a temporary file via mkstemp() and places a text description of the user's account information in it with display(). It then spawns an editor program with the edit() function, allowing the user to change the information. The edit() function first forks a new process that drops privileges fully and runs an editor specified by the user. Once that process is completed, the changes that the user has made are evaluated, and if they are okay, the struct passwd *pw is updated to reflect the new changes. After the user edits the file and chpass updates the pw structure, chpass copies the master.passwd file from /etc/master.passwd (via pfd) to /etc/ptmp file (via tfd). The only thing changed in the copy is the information for the account described by pw. After the copy is completed, pw_mkdb() is called, which is responsible for propagating /etc/ptmp to the system's password database and password files. There are a couple of problems related to file descriptors throughout this update process. You can run any program of your choice when chpass calls the edit() function, simply by setting the environment variable EDITOR. Looking at the previous code, you can see that pfd, which has read access to the shadow password file, isn't closed before the editor runs. Also, tfd, which has read and write access to /etc/ptmp, isn't closed. Say attackers write a simple program like this one: #include <stdio.h> #include <fnctl.h> int main(int argc, char **argv) { int i; for (i=0; i<255; i++) if (fcntl(i, F_GETFD)!=-1) printf("fd %d is active!\n", i); }This program uses a simple fcntl() call on each file descriptor to see which ones are currently valid. Attackers could use this program as follows: $ gcc g.c -o g $ export EDITOR=./g $ chpass 0 is active 1 is active 2 is active 3 is active 4 is active chpass: ./g: Undefined error: 0 chpass: /etc/master.passwd: unchanged $ File descriptors 0, 1, and 2 correspond to standard in, standard out, and standard error, respectively. File descriptor 3 is a writeable descriptor for /etc/ptmp, which is stored in the tfd variable in chpass. File descriptor 4 is a readable descriptor for /etc/master.passwd, which is stored in pfd in chpass. Attackers can do a few things to exploit this problem. The most straightforward is to read in the master.passwd file from descriptor 4 and display its contents, as it contains password hashes they might be able to crack with a dictionary password cracker. File descriptor 3, however, offers a better attack vector. Remember that after the editor finishes, chpass copies the current master.passwd file's contents into /etc/ptmp, makes the necessary changes, and then tells pwd_mkdb to propagate that information to the system databases. The editor can't simply write to descriptor 3 because after it exits, pw_copy() causes tfd to be repositioned at the beginning of the file and overwrites the changes. This is a minor obstacle: One approach to exploiting this condition is to write data past the expected end of the file, where attackers could place extra root-level accounts. Another approach is to fork another process and let chpass think the editor has finished. While chpass is performing the copy operation, the grandchild process can make modifications to /etc/ptmp, which gets propagated to the password databases. The OpenBSD developers fixed this problem by marking all file descriptors that chpass opens as close-on-exec with fcntl(). Programs that drop privileges to minimize the impact of running potentially unsafe code should be evaluated from the perspective of file descriptor management. As you saw in the previous examples, if a program unintentionally exposes a file descriptor to users of lesser privileges, the security consequences can be quite serious. Open file descriptors can also be used to subvert security measures that have been put in place to limit the threat of a successful compromise of an application. In setuid programs, a defensive programming technique often used is to drop privileges as early as possible so that a security flaw in the program doesn't result in unfettered access to the machine. However, developers often neglect to ensure that sensitive files are closed (or, depending where the vulnerability is in the program, sensitive files might be required to be open). Network servers also use least privilege designs to try to limit the impact of remote code execution vulnerabilities. Often these servers have a large number of files open that could be of use to attackers, such as configuration files, logs files, and, of course, sockets. Note The discussion on file descriptor leakage isn't limited to files; it applies to any resource that can be represented with a file descriptorsockets, pipes, and so on. These resources can also give attackers some opportunities for exploitation. One example is exploiting a server that has its listening socket open; by accepting connections on this socket, an attacker might be able to discover confidential information, such as passwords, usernames, and other sensitive data specific to the server's tasks. File Descriptor OmissionEvery time a process opens a new file or object that causes the creation of a file descriptor, that descriptor is placed in the process's file descriptor table at the lowest available numerical position. For example, say a process has file descriptors 1, 2, 3, 4, and 5 open. If it closes file descriptors 2 and 4, the next file descriptor that gets created is 2, and the file descriptor created after that is 4. There's a convention in the UNIX library code that the first three file descriptors are special: File descriptor 0 is standard input, file descriptor 1 is standard output, and file descriptor 2 is standard error. As you might expect, there have been security vulnerabilities related to these assumptions. In general, if you open a file that is assigned a file descriptor lower than 3, library code might assume your file is one of the standard I/O descriptors. If it does, it could end up writing program output or error messages into your file or reading program input from your file. From a security perspective, the basic problem is that if attackers start a setuid or setgid program with some or all of these three file descriptors unallocated, the privileged program might end up confusing files it opens with its standard input, output, and error files. Consider a setuid-root application with the following code: /* open the shadow password file */ if ((fd = open("/etc/shadow", O_RDWR))==-1) exit(1); /* try to find the specified user */ user=argv[1]; if ((id = find_user(fd, user))==-1) { fprintf(stderr, "Error: invalid user %s\n", user); exit(1); }This setuid root application opens the shadow password file and modifies a user attribute specified in the program's argument. If the user is not a valid system user, the program prints out a brief error message and aborts processing. Say you go to run this program, but first you close the standard error file descriptor, file descriptor 2. The setuid program first opens /etc/shadow in read/write mode. It's assigned file descriptor 2, as it's the first available position. If you provide an invalid username in argv[1], the setuid program would attempt to write an error message to standard error with fprintf(). In this case, the standard I/O library would actually write to file descriptor 2 and write the error message into the /etc/shadow file! You could then provide a username with newline characters embedded, insert your own entry lines in the shadow password file, and gain root access to the system. Joost Pol and Georgi Guninski, two independent security researchers, were most likely the first researchers to publish an attack for this class of vulnerability(summarized at http://security.freebsd.org/advisories/FreeBSD-SA-02:23.stdio.asc), although the OpenBSD developers addressed it previously in a kernel patch in 1998, and it appears to have been discussed as early as 1987. Pol and Guninski were able to compromise the keyinit program in FreeBSD by letting it open /etc/skeykeys as file descriptor 2 and having it write specially crafted error messages intended for standard error to the skey configuration file. Many modern UNIX distributions have addressed this issue via modifications to the kernel or the C libraries. Typically, they make sure that when a new process runs, all three of its first file descriptors are allocated. If any aren't, the fixes usually open the /dev/null device driver for the missing descriptors. There have been a few vulnerabilities in the implementations of these protections, however. For example, OpenBSD 3.1, 3.0, and 2.9 had a patch that wasn't quite enough to prevent the problem if attackers could starve the system of resources. This issue was discovered by the researcher FozZy, and is documented at http://archives.neohapsis.com/archives/vulnwatch/2002-q2/0066.html. The following code (slightly edited) is from the vulnerable version of the sys_execve() system call in the kernel: /* * For set[ug]id processes, a few caveats apply to * stdin, stdout, and stderr. */ for (i = 0; i < 3; i++) { struct file *fp = NULL; fp = fd_getfile(p->p_fd, i); /* * Ensure that stdin, stdout, and stderr are * already allocated. You do not want * userland to accidentally allocate * descriptors in this range, which has * implied meaning to libc. * * XXX - Shouldn't the exec fail if you can't * allocate resources here? */ if (fp == NULL) { short flags = FREAD | (i == 0 ? 0 : FWRITE); struct vnode *vp; int indx; if ((error = falloc(p, &fp, &indx)) != 0) break; if ((error = cdevvp( getnulldev(), &vp)) != 0) { fdremove(p->p_fd, indx); closef(fp, p); break; } if ((error = VOP_OPEN(vp, flags, p->p_ucred, p)) != 0) { fdremove(p->p_fd, indx); closef(fp, p); vrele(vp); break; } ... } }This code goes through file descriptors 0, 1, and 2 in a new setuid or setgid process to ensure that all the standard file descriptors are allocated. If they aren't present and fd_getfile() returns NULL, the rest of the code opens the null device for each unallocated file descriptor. The null device is a special device that discards everything it reads; it's typically accessed in userland via the device driver /dev/null. This code seems to do the trick for setuid and setgid applications, as any unallocated file descriptor in position 0, 1, or 2 is allocated with a reference to the /dev/null file. The problem with this code is that if any of the three file operations fail, the code breaks out of the loop and continues running the new program. The developers were aware of this potential problem, as evidenced by the comment about exec() failing. The bug ended up being locally exploitable to gain root access. The described attack is this: If attackers fill up the kernel's global file descriptor table by opening many pipes, they can cause the falloc() call (bolded) in the code to fail. The for loop is broken out of, and a setuid program can be spawned with a low-numbered file descriptor closed. The author, FozZy, was able to exploit the /usr/bin/skeyaudit program by running it so that file descriptor 2 was unallocated. skeyaudit opened /etc/skeykeys as file descriptor 2, and then proceeded to write attacker-controllable error messages in the file and consequently allowing attackers to gain root access. Georgi Guninski found a similar problem in FreeBSD's code to prevent this issue. The code was basically the same as the previous example, except in certain conditions, the kernel system call closed a file descriptor later in the processing. Guninski was able to open a file as file descriptor 2 that the kernel would later close if the file that the descriptor references is /proc/curproc/mem. By running /usr/bin/keyinit with this file assigned to descriptor 2, he was able to get a string of his choosing inserted into /etc/skeykeys, which equated to a root compromise. This vulnerability is documented at www.ciac.org/ciac/bulletins/m-072.shtml. From an auditing perspective, you should consider this vulnerability for cross-platform UNIX applications. Arguably, the OS should handle it in the kernel or standard libraries, but a case could definitely be made for cross-platform programs needing a more defensive approach. OpenBSD, FreeBSD, NetBSD, and Linux have patched this issue in recent versions, but the status of older versions of these OSs and commercial UNIX versions is less certain. Environment ArraysA process maintains a set of data known as its environment or environment variables, which is a collection of configuration strings that programs reference to determine how a user wants certain actions to be performed. A process's environment is usually maintained by the standard library, but the UNIX kernel provides special mechanisms for transferring a process environment across the execve() system call. The environment is represented in memory as an array of pointers to C strings. The last element in this array is a NULL pointer that terminates the list. The array is pointed to by the global libc variable environ. Each pointer in the environment array is a pointer to a separate NULL-terminated C string, which is called an environment variable. Figure 10-3 shows a process environment in a program running on a UNIX system. Figure 10-3. Environment of a process When a process calls execve() to run a new program, it provides a pointer to the new program's environment using the envp parameter. If a process passes a pointer to its own array of environment strings, the UNIX kernel takes responsibility for transferring that environment over to the new process image. Environment variables are transferred to the new process in a particular way by the execve() system call. A UNIX kernel goes through the provided environment array and copies each environment string to the new process in a tightly packed format. Then it builds a corresponding array of pointers to these strings by walking through the adjacent strings it placed together. Figure 10-4 shows what the process environment depicted in Figure 10-3 might look like after an execve(). Notice how all the environment variables are adjacent in memory, and they are placed in order of their appearance in the original environment. Don't pay too much attention to the addresses. On a real UNIX system, the environment strings would likely be next to the program argument strings, at the top of the program stack. Figure 10-4. Process environment immediately after an execve() After the kernel has finished setting up the process, it's up to the standard system libraries to manage the environment. These libraries maintain a global variable called environ that always points to the array of strings composing the process's environment. The first piece of runtime glue code that's called when a new program runs immediately sets environ to point to the array of environment variables set up by the kernel at the top of the stack. As a process runs, it can add, modify, and delete its environment variables. When additions are made, the environment manipulation functions (described momentarily) are responsible for finding new memory to store the environment list and the strings when required. They do so by using memory from the heap, allocated with malloc() and resized with realloc(). Different UNIX implementations have different semantics for handling the environment. In general, processes use five main functions to manipulate their environment: getenv(), used to retrieve environment variables; setenv(), used to set environment variables; putenv(), a different interface for setting environment variables; unsetenv(), used for deleting an environment variable; and clearenv(), used to clear out a process's environment. Not all UNIX implementations have all five functions, and the semantics of functions vary across versions. As far as the kernel cares, the environment is simply an array of NULL-terminated strings. The standard C library, however, expects strings to be in a particular format, separating environment variables into a name and a value. The = character is used as the delimiter, so a typical environment variable is expected to follow this format: NAME=VALUE The library functions provided for programs to manipulate their environment generally work with this expectation. These functions are described in the following paragraphs. The getenv() function is used to look up environment variables by name and retrieve their corresponding values: char *getenv(const char *name); It takes a single argument, which is the name of the environment variable to retrieve, and searches through the program's environment for that variable. Say you call it like this: res = getenv("bob");getenv() would go through each string in the environment, starting at the first one in the array pointed to by environ. The first environment string it finds starting with the four characters bob= will be returned to the caller (actually, it returns a pointer to the byte immediately following the = character). So for an environment string defined as bob=test, getenv("bob") would return a pointer to the string test.getenv() is supported across practically all UNIX environments. The setenv() function is used to add or update environment variables: int setenv(const char *name, const char *val, int rewrite); This function takes a name of an environment variable and a potential value. If the name environment variable doesn't exist, the function creates it and sets it to the value indicated in the second argument. If the name environment variable does exist, the behavior depends on the rewrite argument. If it's set, setenv() replaces the existing environment variable, but if it's not, setenv() doesn't do anything to the environment. If setenv() needs to add a new environment variable to the array pointed to by environ, it can run into one of two situations. If the original environ set up by the kernel is still in use, setenv() calls malloc() to get a new location to store the array of environment variables. On the other hand, if environ has already been allocated on the process heap, setenv() uses realloc() to resize it. setenv() usually allocates memory off the heap to store the environment variable string, unless there's room to write over an old value. On the surface, the putenv() function seems similar to setenv(): int putenv(const char *str); However, there's an important difference between the two. putenv() is used for storing an environment variable in the environment, but it expects the user to provide a full environment string in str in the form NAME=VALUE. putenv() replaces any existing environment variable by that name. On many systems, putenv() actually places the user-supplied string in str directly in the environment array. It doesn't allocate a copy of the string as setenv() does, so if you give it a pointer to a string you modify later, you're tampering with the program's environment. Under BSD systems, however, putenv() does allocate a copy of the string; it's implemented as a wrapper around setenv(). Note Linux used to allocate a copy of the environment string in the past, but changed this behavior in recent glibc versions. The man page on a Linux system for putenv() explicitly notes this behavior change in the Notes section:
The unsetenv() function is used to remove an environment variable from the environment array: void unsetenv(const char *name); It searches through the array for any environment variables with the name name. For each one it finds, it removes it from the array by shifting all remaining pointers up one slot. The clearenv() function is used to clear the process environment completely and get rid of all environment variables: int clearenv(void); Binary DataOne interesting feature of the environment is that it can be used to place arbitrary data at the top of the stack of a program you intend to run. While this is more of an interesting topic in the context of writing exploits, it's worth covering here. The kernel reads the environment strings you pass execve() in order and places them adjacent to each other at the top of the new process's stack. It works out so that you can supply mostly arbitrary binary data. Say you have an array like this: env[0]="abcd"; env[1]="test"; env[2]=""; env[3]="hi"; env[4]=""; env[5]=NULL; In memory, you would expect the kernel to create the following sequence of bytes: abcd\0test\0\0hi\0\0 The use of an empty string ("") causes a single NUL byte to be written to the environment. Because environment strings need to be preserved across a call to execve(), the strings need to be manually copied into the new process's address space before the new program can be run. This is logical; because execve() unmaps all memory of the old process, which includes environment strings. If you know where the stack starts for the new process (usually a known location, except when memory randomization mechanisms are used) and what environment variables exist, you know exactly where these environment strings reside in memory in the newly running process. The environment maintenance routines don't impose any limitations on the nature of data that can exist in the environment, so you're free to add binary data containing machine code designed to spawn a shell or another nefarious task. Confusing putenv() and setenv()Because of the slight semantic differences between putenv() and setenv(), these functions could possibly be used in the wrong context. To review, the putenv() function doesn't actually make a copy of the string you're setting in the environment in many systems. Instead, it just takes the pointer you pass and slots it directly into the environment array. This behavior is definitely a problem if you can modify data that is being pointed to later on in the program, or if the pointer is discarded, as shown in the following example: int set_editor(char *editor) { char edstring[1024]; snprintf(edstring, sizeof(edstring), "EDITOR=%s", editor); return putenv(edstring); }This function seems to be doing the right thing, but there's a problem: The edstring variable is directly imported into the environment array (providing that it is not being run on BSD or older Linux versions). In this example, a local stack variable is inserted in the environment. Since stack variables are automatically cleaned up when the function returns, the pointer in the environment then points to undefined stack data! Through careful manipulation of the program, attackers might be able control data placed on the stack where edstring used to be and hence introduce arbitrary variables into the environment. A bug of this nature might also surface when applications are designed to work on a number of platforms. Specifically, if Solaris is one of the target platforms, developers are required to use putenv() because Solaris doesn't implement setenv(). Here's a slightly modified example showing what this code might look like: int set_editor(char *editor) { #ifdef _SOLARIS char edstring[1024]; snprintf(edstring, sizeof(edstring), "EDITOR=%s", editor); return putenv(edstring); #else return setenv("EDITOR", editor, 1); #endif /* _SOLARIS */ }This code seems as though it should be functionally equivalent regardless of the target platform. But, as you already know, the call to putenv() is unsafe in this instance whereas setenv() is not. Another possible vulnerability is one in which the argument passed to putenv() contains an environment value rather than the name followed by the value. Although this type of error might seem unlikely, it has happened in the past. Listing 10-3 is from the Solaris telnetd code. Listing 10-3. Misuse of putenv() in Solaris Telnetd
The SHELL variable is retrieved from the environment and then later reinserted in the environment with putenv() without prepending SHELL=. If users can supply the SHELL variable, they are able make the value of that variable an arbitrary environment name-and-value pair (such as LD_PRELOAD=/tmp/lib) and thus introduce potentially dangerous environment values into the program that might lead to further compromise. Note Upon further examination, it turns out this bug isn't exploitable, because even though environment variables have been read from the user during option negotiation, they haven't been entered in the environment at this point in execution. However, it's worth showing the code in Listing 10-3 because the use of putenv() is incorrect. Extraneous DelimitersYou know that standard library functions expect to see environment variables with the NAME=VALUE format. However, consider the case where you have a variable formatted like this: NAME=LASTNAME=VALUE=ADDEDVALUE Variations in how environment variables are formatted can be important, depending on how the algorithms responsible for fetching and storing values are implemented. Bugs of this nature have surfaced in the past in how the libc functions setenv()/unsetenv() work. The following is a quote from a post made by a security researcher named David Wagner (the post can be read in full at http://archives.neohapsis.com/archives/linux/lsap/2000-q3/0303.html):
As a result of these problems, current setenv() and unsetenv() implementations are selective about allowing names with delimiters (=) in them. That said, it's usually a good idea to err on the side of caution when making assumptions about library support of production systems. Extending on this idea, if an application decides to manually edit the environment without the aid of library APIs, comparing how variables are found and how they are set is a good idea. These functions should be complementary, and if they're not, the opportunity to insert variables that should have been weeded out might be possible. After all, libcs for a number of UNIX variants made these mistakes in the past, and so it's likely that developers writing new code will fall into the same traps. The same possibility exists for simulated environments (such as those generated by scripting languages). If in principle they're attempting to achieve the same effect with a synthesized environment structure, they are liable to make the same sort of mistakes. For example, take a look at these two functions: struct env_ent { char *name, char *value; struct env_ent *next; }; int process_register_variable(struct env_ent *env, char *valuepair) { char *val; int i, name_len; struct env_ent *env0 = env; val = strchr(valuepair, '='); if(!val) return 1; name_len = val valuepair; for(; env; env = env->next){ if(strncmp(env->name, valuepair, name_len) == 0) break; } if(!env) return create_new_entry(env0, valuepair); free(env->value); env->value = strdup(val+1); return 1; } char *process_locate_variable(struct env_ent *env, char *name) { char *n, *d; for(; env; env = env->next){ if(strcmp(env->name, name) == 0) return env->value); } return NULL; }Do you see the problem? The way that variables are located when determining whether to overwrite a value already in the environment differs from the way they are located when just fetching a value. Specifically, the use of strncmp() in process_register_variable() is a little faulty because it returns 0 if a length of 0 is passed to it. If the string =BOB is passed in, the function replaces the first entry in the environment with the value BOB! Another important problem to focus on is code that makes the assumption about input not containing extraneous delimiters when using putenv(). Consider the following example: int set_variable(char *name) { char *newenv; intlength = strlen("APP_") + strlen("=new") + strlen(name) + 1; newenv = (char *)malloc(length); snprintf(newenv, length, "APP_%s=new", name); return putenv(newenv); }The set_variable() function makes the assumption that the name variable doesn't contain a delimiter. However, if it does, the user is free to select an arbitrary environment value for the variable, which obviously isn't what the code intended. Duplicate Environment VariablesAnother potential pitfall in programs that interact with environment variables is having more than one variable with the same name defined in the environment. This error was more of a problem in the past because many libc implementations neglected to remove multiple instances of a variable (because of faulty unsetenv() implementations). Having said that, it's still an issue occasionally, so keep it in mind when you're auditing environment sanitization code for two reasons:
If the function terminates when it finds the requested variable in question, it's likely vulnerable to attackers sneaking values through by setting multiple instances of the same value. This problem existed in the loadmodule program in SunOS 4.1.x. The environment was manually cleaned out before a call to system() to stop attackers from setting the IFS variable (discussed later in "Other Environment Variables") and, therefore, being able to run arbitrary commands with root privileges. Unfortunately, the code neglected to correctly deal with multiple instances of the same variable being set, so the call to system() was still vulnerable to exploitation. This bug is documented at www.osvdb.org/displayvuln.php?osvdb_id=5899. To cite a more recent example, the accomplished researcher Solar Designer noted a problem in the Linux loader supplied with older versions of glibc. The loader checks for the existence of environment variables prefixed with LD_ and uses them to determine behavioral characteristics of how the loader functions. These variables allow loading additional or alternate libraries into the process's address space. Naturally, this behavior isn't desirable for setuid applications, so these variables were filtered out of the environment when loading such a program. However, a bug in the loaders unsetenv() function caused it to neglect filtering out duplicate environment variables correctly, as shown in the following code: static void _dl_unsetenv(const char *var, char **env) { char *ep; while ((ep = *env)) { const char *vp = var; while (*vp && *vp == *ep) { vp++; ep++; } if (*vp == '\0' && *ep++ == '=') { char **P; for (P = env;; ++P) if (!(*P = *(P + 1))) break; } env++; } }When a variable is found that needs to be stripped, this function moves all other environment variables after it back one place in the environment array. However, then it increments the environment variable pointer (env), so if two entries with the same name are in the environment right next to each other, the program misses the second instance of the variable! Note During the process of researching loader behavior for this book, the authors noticed that as of this writing, this bug is also present in the ELF loader shipped with the OpenBSD (3.6) version. So even when code does attempt to deal with multiple instances of the same variable, a program might accidentally expose itself to potential security risks if it doesn't analyze the environment correctly. Common Environment VariablesNow that you're familiar with the details of how a typical UNIX environment is managed, you can begin to examine some common variables used by applications. The variables described in the following sections are just a few of the environment variables you'll encounter regularly in applications you audit, so don't assume that variables not listed here are innocuous. Shell VariablesA number of variables can modify how the typical UNIX shell behaves. Many of these values are always present because they're initialized with default values if a shell is started without them. You have already seen that system shells can play a big part in how applications operate when indirect program invocation is used or privileged shell scripts are running. Many other programs use a number of these variables as well. Note that in contemporary UNIX variants, many of these variables are considered potentially dangerous and are filtered out when a setuid process runs. Still, this is by no means true of all systems. Also, keep in mind that those applications you interact with remotely and supply environment variables to are not automatically subject to the same environment restrictions if the program isn't setuid. PATHThe PATH environment variable is intended to contain a list of directories separated by colons (:). When the shell needs to run a program that's specified without directory path components, it searches through each directory in the PATH variable in the order that they appear. The current directory is checked only if it's specified in the PATH variable. Programs that run with privilege and make use of subshells can run into trouble if they don't use explicit paths for command names. For example, take a look at the following code: snprintf(buf, sizeof(buf), "/opt/ttt/logcat%s | gzcat | /opt/ttt/parse > /opt/ttt/results", logfile); system(buf); This program makes use of the system() function to run the /opt/ttt/logcat program, pipe its output to the gzcat program to decompress the log, pipe the decompressed log to the /opt/ttt/parse program, and then redirect the parsing results to the /opt/ttt/results file. Note that gzcat is called without specifying a directory path, so the shell opened with the system() function searches through the PATH environment variable to find the gzcat binary. If this code was part of a setuid root application, attackers could do something like this: $ cd /tmp $ echo '#!/bin/sh' > gzcat $ echo 'cp /bin/sh /tmp/sh' >> gzcat $ echo 'chown root /tmp/sh' >> gzcat $ echo 'chmod 4755 /bin/sh' >> gzcat $ chmod 755 ./gzcat $ export PATH=.:/usr/bin:/usr/local/bin $ /opt/ttt/start_process $ ./sh # In this code, attackers change the PATH environment variable so that the current directory is the first directory that's searched. This way, the shell script gzcat in the current directory, /tmp/, runs instead of the intended program, /usr/bin/gzcat. Attackers made a simple shell script in the place of gzcat that allowed them to obtain root access by creating a setuid root copy of /bin/sh. HOMEThe HOME environment variable indicates where the user's home directory is placed on the file system. Naturally, users can set this variable to any directory they want, so it's important for privileged programs to actually look up the user's home directory in the system password database. If a privileged program tries to use a subshell to interact with a file that's specified relative to a user's home directory, such as ~/file, most shells use the value of the HOME environment variable. IFSIFS (which stands for "internal field separator") is an environment variable that tells the shell which characters represent whitespace. Normally, it's set to break input on space, tabs, and new lines. On some shells, IFS can be set so that it interprets other characters as whitespace but interprets straightforward commands in odd ways. Consider the following program excerpt: system("/bin/ls");This simple program excerpt makes use of the system() function to run the /bin/ls program. If an attacker sets the IFS variable to / and the shell honors it, the meaning of this command would be changed entirely. With a normal IFS setting, the string /bin/ls is interpreted as one token, /bin/ls. If the attacker set IFS to /, the shell interprets it as two tokens: bin and ls. The shell would first try to run the bin program and pass it an argument of ls. If a program named bin happened to be in the current PATH, the shell would start that program. An attacker could exploit this situation as shown in the following example: $ cd /tmp $ echo 'sh -i' > bin $ chmod 755 ./bin $ export PATH=.:/usr/bin:/usr/local/bin $ export IFS="/" $ run_vuln_program $ ./sh # The attacker changed the IFS variable so that / would be interpreted as whitespace, and the system() function would try to run the program named bin. The attacker created a suitable program named bin that opened a shell as root, and then set PATH so that his bin program was first on the list. IFS attacks don't really work against modern shells, but ENV attacks, described in the next section, are a bit more plausible. ENVWhen a noninteractive shell starts, it often looks to a certain environment variable for a filename to run as a startup script. This environment variable is typically expanded, so one can use a malicious value, as in this example: ENV=``/tmp/evil`` Any subshells that are opened actually run the /tmp/evil file. BASH_ENV is a similar variable honored by bash. Old versions of sliplogin were vulnerable to this issue, as shown in the following code: (void)sprintf(logincmd, "%s %d %ld %s", loginfile, unit, speed, loginargs); ... /* * Run login and logout scripts as root (real and * effective); current route(8) is setuid root and * checks the real uid to see whether changes are * allowed (or just "route get"). */ (void) setuid(0); if (s = system(logincmd)) { syslog(LOG_ERR, "%s login failed: exit status %d from %s", loginname, s, loginfile); exit(6); }This error could be exploited by logging in to a slip-enabled account and having telnet set an environment variable of ENV that the shell opened by system() would expand and run. SHELLSome programs use the SHELL environment variable to determine a user's preferred command shell. Naturally, if privileged programs honor this variable, trouble can ensue. EDITORSome programs use the EDITOR environment variable to determine users' preferred editors. Obviously, this variable is also dangerous for a privileged program to trust. Sebastian Krahmer noted a vulnerability in the setuid program cron on a number of UNIX distributions that resulted in the program pointed to in the EDITOR variable running with elevated privileges (announced by SuSE at http://lists.suse.com/archive/suse-security-announce/2001-May/0001.html). Runtime Linking and Loading VariablesMost current UNIX OSs use make extensive use of shared libraries, so that commonly required functionality doesn't need to be continually re-implemented by each application. The creation of an executable program file involves the use of a special program called a linker, which tries to find program-required symbols in a list of libraries. If the program is being statically compiled, required library code is simply copied from the library into the executable program file, thus the program will be able to run without having to dynamically load that library. Conversely, dynamically linked executables are created by compiling a list of required modules for the various symbols that the application needs, and storing this list within the executable file. When the OS runs a dynamically linked program, startup framework code finds the shared libraries in this list and maps them into the process's memory when they are needed. LD_PRELOADLD_PRELOAD provides a list of libraries that the runtime link editor loads before it loads everything else. This variable gives you an easy way to insert your own code into a process of your choosing. In general, UNIX doesn't honor LD_PRELOAD when running a setuid or setgid program, so this variable isn't likely to be a direct vulnerability. However, if users can influence the environment of a program running with privilege (but isn't setuid), LD_PRELOAD and similar variables can come into play. For example, the telnet daemon allows a network peer to define several environment variables. These environment variables are typically set before the login program runs, and if the telnet daemon doesn't strip out LD_PRELOAD properly, it can lead to an exploitable condition. Several years ago, many telnet daemons honored the LD_PRELOAD environment variable, thus creating an opportunity for attackers to load arbitrary libraries and run code of their choosing. LIBRARY PATHLD_LIBRARY_PATH provides a list of directories containing shared libraries. The runtime link editor searches through this list first when looking for shared libraries. This variable is ignored for setuid/setgid binaries. Again, when users might have influence over the environment of a privileged application, sanitizing linking/loading-related environment variables correctly is important.
Other Environment VariablesThe environment variables you have looked at so far are widely used, but they aren't the only ones that have caused problems in the pastfar from it! Whenever programs run with privileges different from the user interacting with it on a local system or run on a remote system in which users can influence the environment, there's the danger of the program exposing itself to risk when it interprets values from the environment. The values you have seen are standard shell environment variables, but less commonly used or application-specific variables have also been manipulated to compromise an application. This vulnerability is possible especially when libraries are performing actions based on the environment; application developers might not be aware those values are being read and acted on because it's all happening behind the scenes. Indeed, some of the most prevalent environment-related vulnerabilities in UNIX have been a result of libraries using environment variables in an unsafe manner. Take the UNIX locale vulnerability Andreas Hasenak discovered, for example (www1.corest.com/common/showdoc.php?idx=127&idxseccion=10). Many UNIX OSs were vulnerable to local (and sometimes remote) compromise because the formatting of output was dictated according to language files specified by certain environment variables (NLSPATH, LC_MESSAGES, and LANG in this case, although it varies slightly among operating systems). Another notable example was abusing TERM and TERMCAP environment variables via telnetd in a number of UNIX systems (BSD and Linux). Theo De Raadt discovered that these variables, if present, specified a file that ws parsed to determine certain terminal capabilities (more details at www.insecure.org/sploits/bsd.tgetent.overflow.html). Attackers who were able to write an arbitrary file to a target host's file system could upload erroneous TERMCAP files and then connect via telnetd and have them parsed, thus triggering a buffer overflow in the tgetent() function. Performing a thorough application audit of a UNIX program requires identifying variables that an application is using explicitly and having a reasonable idea of the environment variables standard libraries use behind the scenes. Process Groups, Sessions, and TerminalsEach process belongs to a process group, which is a related set of processes. One process in the group is the process group leader, and the process group's numeric ID is the same as its group leader's process ID. Programs that are descendents of the group leader remain in the process group, unless one of them creates their own process group with setpgid() or setsid(). A session is a collection of process groups, usually tied to a terminal device. The session leader has a connection with this device, known as the controlling terminal. Each session with a terminal has a single foreground process group, and the rest of the process groups are background process groups. This organization of processes around the terminal allows for the natural interface that UNIX users are accustomed to. The terminal device takes certain input from the user, and then sends signals to all processes in the foreground process group. Terminal AttacksTerminal emulation software interprets a number of escape sequences to help format data on the screen and perform other tasks, such as taking screen captures, altering terminal parameters, and even setting background images. This flexibility might allow data being displayed via a terminal emulator to perform unintended actions on behalf of users viewing the data. HD Moore published an interesting paper (available at http://archives.neohapsis.com/archives/bugtraq/2003-02/att-0313/01-Termulation.txt) that details a few attacks on popular terminal emulation software, with consequences ranging from simple denial-of-service vulnerabilities to stealing privileges from the victim viewing data that contains embedded escape sequences. From a code-auditing perspective, you can't audit applications for bugs related to program output if the output is viewed by a third party via a terminal emulator program. However, you need to be aware that these bugs exist, and sometimes it makes sense to recommend that an application sanitize output so that nonprintable characters don't appear because of problems such as the ones described in HD Moore's paper. He points out the syslog daemon as an example and describes the behavior of other popular implementations. Session LoginsOccasionally, you encounter code running in a privileged context that determines the user interacting with it by using the getlogin() function. This function exists in BSD-based UNIX implementations, and it returns the current user associated with the session. This value is set at some earlier point with setlogin(). Applications that use these functions have to be careful, particularly with setlogin() because it affects all processes in the process group, not just the current process. To use setlogin() safely, processes need to make themselves the leader of a new session; otherwise, they inadvertently set the login name for the entire process group. (Only processes running with superuser privileges can use the setlogin() function.) As the OpenBSD man page points out, this mistake is easy to make because this behavior is the opposite of traditional models of UNIX inheritance of attributes. A process becomes a process group leader by using setsid() or setpgrp(); however, only setsid() is adequate for use before a call to setlogin() because setpgrp() doesn't put the process as a new session, just a new process group. The following code shows an incorrect use of setlogin(): int initialize_user(char *user) { if(setpgid(0, 0) < 0) return 1; return setlogin(user); }Because this code incorrectly uses setpgid() instead of setsid(), the setlogin() call alters the login name of every process in the session to user. For an incorrect use of setlogin() to be exploited, a program running in the same session must use the getlogin() function in an insecure manner. Because setlogin() can be used inappropriately (as in the preceding example), the getlogin() function could return a username that's not the user whose privileges the process is running with. Any application that assumes the username is correct is potentially making a big mistake. Here's an example of a dangerous use of getlogin(): int exec_editor(char *filename) { char *editor; char *username; struct passwd *pw; username = getlogin(); if((editor = getenv("EDITOR")) == NULL) return 1; if((pw = getpwnam(username)) == NULL) return 1; setuid(pw->pw_uid); execl(editor, editor, filename, NULL); }This (contrived) example sets the user ID inappropriately if the value returned from getlogin() is incorrect. If it returns an inappropriate username, this program sets the user ID to the wrong person! When auditing code that uses setlogin() or getlogin(), you should make the assumption that any insecure use of setlogin() can result in compromise. Even if getlogin() isn't used in the application being audited, it's used plenty of other places on a default system. Similarly, an application shouldn't be putting too much faith in the value returned by getlogin(). It's a good idea to approach the audit under the assumption that you can abuse some other application on the system to incorrectly setlogin(). Any time you encounter getlogin() used in place of more secure alternatives (the getpw* functions based on the UID returned from the getuid() function), carefully trace the username returned under the assumption you can specify an arbitrary value for that username. |
EAN: 2147483647
Pages: 194
- Chapter II Information Search on the Internet: A Causal Model
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XIV Product Catalog and Shopping Cart Effective Design
- Chapter XV Customer Trust in Online Commerce