Concepts
Entity Bean Types
We will consider three types of entity beans. In presenting the concept of entity beans we will compare all three types. The following types of entity beans should be distinguished:
-
Container-Managed Persistence 2.0/2.1. These are entity beans with container-managed persistence as defined in the Enterprise JavaBeans 2.0 and 2.1 specifications.
-
Container-Managed Persistence 1.1. These are entity beans with container-managed persistence as defined in the Enterprise JavaBeans 1.1 specification. For backward compatibility these are also a part of the Enterprise JavaBeans 2.0 and 2.1 specifications.
-
Bean-Managed Persistence. These are entity beans that do not use the persistence manager but implement the persistence mechanism themselves. They were defined in version 1.1 of the Enterprise JavaBeans specification and were taken into version 2.0 largely unaltered.
The following considerations compare these three types of beans. In the parallel descriptions of container-managed persistence 1.1 and 2.0 the advantages of the new architecture will be pointed out. We will employ examples to highlight the development aspects of the different concepts.
Attributes and Dependent Objects
The persistent state of an entity bean is stored in its attributes. During development the storage process must be given careful consideration. A significant difference among the three entity bean types is in how the persistent attributes are handled.
Bean-Managed Persistence
If the bean developer takes responsibility for persistent storage in attributes, then it is also his or her responsibility to determine how attributes are dealt with. In a later section we will present programming examples.
Container-Managed Persistence 1.1
Version 1.1 of the Enterprise JavaBeans specification provides for the persistent attributes to be defined as attributes of the bean class and given in the deployment descriptor. The attributes can have the following data types:
-
Primitive data types of the programming language Java (for example, int, float, long);
-
Serializable data types of the programming language Java.
The attributes are defined as public, so that the EJB container has access to them. It is the responsibility of the EJB container to synchronize the persistent attributes of the bean with the underlying database.
Container-Managed Persistence 2.0/2.1
With version 2.0 of the Enterprise JavaBeans specification the manipulation of persistent attributes changed fundamentally. The bean developer works with an abstract bean class. Instead of attributes in the form of member variables of the bean class, he or she defines abstract access methods for reading and writing of attributes (so-called getter/setter methods). During deployment the EJB container generates a derived class that implements all the abstract methods. The concrete implementation is a component of the persistence mechanism.
The attributes are permitted to have the following data types:
-
Primitive data types of the programming language Java (for example, int, float, long);
-
Serializable data types of the programming language Java.
Serializable data types are all classes that implement the interface java.io.Serializable . This includes above all the classes java.lang.String and java.util.Date. Frequently, instead of Java's primitive data types, the relevant wrapper classes of the primitive data types (such as java.lang.Integer, java.lang.Float, java.lang.Long) are used. As a rule, these data types can be mapped without problems to the data types of databases. In the case of individual data types (custom classes that use the Serializable interface) that are declared as a persistent attribute of an entity bean, this is not possible without further ado. These can often be processed only as binary data (so-called BLOBs = Binary Large Objects) by the databases in which they are stored as persistent data. Attributes of this type are called dependent value classes. The use of such individual data types as persistent attributes of an entity bean is rather the exception. The mapping of complex and searchable data structures is accomplished via the use of several entity bean classes whose dependencies are defined by relationships.
Persistent Relationships
A persistent relationship (container-managed relationship) makes it possible to navigate from one instance to a related instance; this is relevant only to entity beans with container-managed persistence 2.0. As an example let us consider two entity bean classes for a project management scenario: project bean and employee bean. A relationship is the correct means to model which workers work on which projects. Given the project (instance of a project bean), all associated employees (instances of the employee bean) can be found using the relationship. The tracking of relationships from one object to a related object is called navigation.
A database is used for storing relationships (for example, a foreign key relationship in a relational database), and thus relationships are searchable using database methods.
Relationships can exist only between entity beans defined in the same deployment descriptor, where the relationship is formally described. Furthermore, relationships between entity beans are possible only in the local client view (for details on the local client view see Chapter 4, "Local vs. Remote Client View"). The EJB container takes care of generating instances during navigation across relationships. Furthermore, the EJB container sees to it that the relationships between instances of entity beans are made persistent.
From the developer of an entity bean's points of view a relationship is represented as a pair of abstract methods: one get<relationshipname> method and one set<relationshipname>. The abstract get method allows navigation via a relationship. The set permits the association of a relationship to a specific instance. As with the abstract methods for storing attributes, during deployment, concrete implementations of the abstract methods for handling relationships are generated by the tools of the EJB container.
For every relationship a cardinality is defined. This represents the numerical type of the relationship between related instances. These are the possible cardinalities:
-
1:1 . An instance of class A joined to one or no instances of class B;
-
1: n. One instance of class A is joined to an arbitrary number of instances of class B.
-
n : m . One instance of class A is joined to an arbitrary number of instances of B, and the elements of class B are joined to an arbitrary number of instances of class A.
Relationships can be navigable in one or both directions. If the relationship is navigable in both directions, then each partner in the relationship recognizes the linked instances. One speaks in this case of a bidirectional relationship. If the relationship is navigable in only one direction, then only one partner in the relationship has access to the linked instances. The other partner has no information about the relationship. In this case one speaks of a unidirectional relationship.
A relationship also offers the possibility to define an existence dependency. When one instance is deleted it is possible to delete instances linked by a relationship. This modus operandi is called cascading deletion.
Primary Key
Every entity bean class requires a primary key, which makes it possible to identify all entity bean identities uniquely. A client uses the primary key to search for entity beans. The EJB container uses the primary key as unique identifier to be able to locate each entity bean identity.
The primary key can come from one or more persistent attributes of the entity bean. It must be seen to that each instance of an entity bean class possesses a different combination of values among the attributes of the primary key.
The customer number in a mail-order company is an example of a primary key with a single attribute. It is unique for each customer. In contrast to this, the registration number of an automobile is not sufficient to serve as a primary key for the set of all registered motor vehicles. In addition there is a number that is increased each time the same registration number is issued. Taken together, the registration number and the increasing number are unique and serve as an example of a primary key that consists of several attributes.
The attributes that constitute the components of the primary key (see Figure 5-2) are collected by the bean developer into a class of their own. In this primary key class the attributes have the same name and data type as in the Enterprise Bean class. The EJB container is notified of the primary key class in the deployment descriptor. The client also uses the primary key to search for particular entity beans.
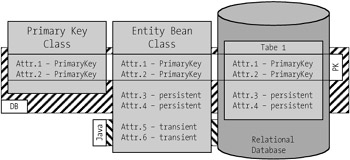
Figure 5-2: Overview of the attributes of an entity bean.
An exception is the case of primary keys that consist of a single attribute. In order to simplify programming one may here do without a special primary key class. Instead, a standard Java class can be used, corresponding to the type of the primary key. Examples are java.lang.String, java.lang.Integer, java.lang.Long. The primary key attribute is given in the deployment descriptor.
Bean Instance and Bean Identity
In working with entity beans it is very important to separate the viewpoint of the developer of the client program from that of the developer of the bean. It is particularly important that the terms bean instance and bean identity be understood.
The home object and the value of the primary key together constitute the entity bean identity. Such an identity could, for example, represent customer number 123 (see Figure 5-3). An object of an entity bean class in active memory is called an entity bean instance. In the case of an entity bean identity in a database without an entity bean instance in active memory one speaks of a passivated bean.
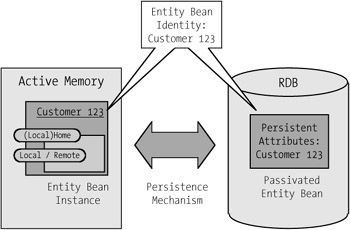
Figure 5-3: Entity bean identity in the customer example.
From the client's point of view the picture is simple: There exist entity bean objects each with an entity bean identity. The bean object offers the client the remote or local interface for access. For managing the bean object the client has available the (local) home interface of the bean class. If the client wishes to work with an entity bean identity, it obtains a reference to the associated bean object via the (local) home interface. In general, the (local) home interface enables the client to create, delete, and find bean objects. The client view is thereby limited precisely to those aspects of the bean that are relevant.
The bean developer requires another viewpoint. He implements the application logic in the bean class. In addition, he writes a (local) home and a remote or local interface for this bean class that publish the functionality of the bean. The methods of this interface are implemented partially by the developer of the bean in the bean class and are partially provided by the EJB container.
When the client works with a bean object, the associated functionality of a bean instance is provided. However, there is an important difference between the viewpoint of the developer of the client program toward the bean object and that of the bean developer toward the bean instance. The bean object always has the same bean identity, while the bean instance can change the bean identity during its life cycle. This fact must, of course, be taken into account by the developer of the entity bean. The following section treats this topic in detail.
Persistence
A typical business application manages very large data sets. In implementing Enterprise JavaBeans these data are normally stored in entity beans. The large number of resulting entity beans cannot remain continuously in active memory, but must be stored somewhere with large storage capacity. As a rule, a database is implemented for this that stores the data on a hard drive and offers mechanisms for data security (such as tape backup).
In order to make an entity bean persistent, all persistent attributes must be stored. If an instance is needed again, then the instance can be recreated in its original state with the saved attributes. By persistence mechanism is understood the process of storing and recreating this state.
In reference to the persistence of entity beans the following two types of persistence are distinguished:
-
Bean-Managed Persistence: An entity bean can itself see to the storage of its attributes.
-
Container-Managed Persistence: The responsibility for the persistent storage of attributes of an entity bean is transferred to the persistence manager of the EJB container.
In the first case it is the task of the bean developer to implement the methods that enable the EJB container to manage the entity beans. With these methods the developer can freely select the strategy by which the attributes are written, loaded, and searched. The possibility of realizing the persistence mechanism in the bean itself gives the bean developer great flexibility. He need not restrict himself to the persistence mechanism of the EJB container and can use application-specific methods.
In the second case the developer of the entity bean is completely freed from programming the access methods. The persistence manager sees to it that the persistent attributes of the entity bean are stored.
The EJB specification defines that the EJB container stores the persistent data by a process that is comparable with Java's serialization. Within the framework of this definition, however, the most diverse imaginable processes are possible. In managing large data sets, as a rule a database is implemented. In addition to the popular relational databases (RDB) one might also consider the deployment of object-oriented databases (OODB) and other persistence systems.
In an existing infrastructure it can be necessary to use the storage mechanisms of existing applications. This is of particular interest in using an existing database in mainframe applications. The advantage of this is that all data of the existing application as well as those of new EJB applications are available. This makes possible a soft migration of legacy systems, avoiding the complete substitution of a particular system by a particular time.
The EJB container has one or more persistence managers, which are responsible for generating the necessary access methods. A persistence manager determines the type of implemented persistence system and the mapping of persistent data to this system. As a rule, the EJB container makes precisely one persistence manager available, which supports storage in relational databases. If there are several persistence managers, then at the time of deployment the persistence mechanism is determined by the choice of persistence manager.
For generating the access methods the persistence manager requires precise information about the entity bean. Therefore, it analyzes the entity bean class, the dependent classes (if any), and the deployment descriptor at deployment time. Depending on the chosen persistence mechanism, additional data may be needed, such as tables and column names for the attributes of an entity bean in a database. The deployment procedure must be repeated for the installation of the bean in another EJB container.
The implementation cost can be minimized by the use of container-managed persistence. In this case the bean relies on the infrastructure of the EJB container and has itself no access to the database. Therefore, the bean remains portable and can be used without additional expenditure with other databases or other EJB containers.
Storage in Relational Databases
With entity beans the EJB architecture uses an object-oriented structure for all data storage. Therefore, it is logical to consider storage in object-oriented databases. However, relational databases are more established in the marketplace and are in wider use in both new and existing applications. For these reasons Enterprise JavaBeans is used mostly with relational databases. The persistence mechanism must thus map an object-oriented data structure onto a relational structure (object-relational mapping). See Figure 5-4.
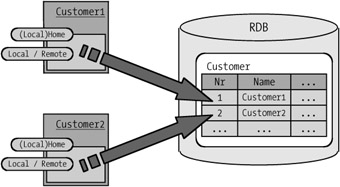
Figure 5-4: Object-relational mapping of entity beans.
The mapping of object-oriented data structures to the tables of a relational database is a complex topic. However, entity beans do not work with inheritance, since component inheritance is not covered by the EJB specification. As a result, the required procedure is relatively simple.
A bean class that possesses only simple attributes can be mapped to individual database tables (called a relation). Each simple persistent attribute of the class thereby obtains an individual column (called an attribute). Each of the instances of the bean is written in a row (called a tuple). In this way the attributes of the primary key are contained in particular columns of the database table. The primary key of the entity bean is also used as primary key of the associated database table. Thus in addition to the required searchability one has ensured more efficient access to particular entity bean identities.
For modeling complex structures the simple data types that can be mapped to a column in a database no longer suffice. Here one may use dependent value classes or several entity bean classes in association with container-managed relationships. In mapping objects to a relational database the difference between the two methods becomes clear:
-
Objects of dependent value classes are serialized and stored in a database column for binary data (BLOB). The database is unable to interpret the stored binary format. Therefore, these columns cannot be searched. In addition, these columns cannot be used for foreign key relations to other tables.
-
In the case of several entity beans that are associated via container-managed relationships each entity bean is stored in its own table. The tables are related via the attributes of the entity beans. The attributes of the entity beans are searchable, and one may navigate via the relationships.
If one chooses modeling with several entity beans and container-managed relationships for the mapping of complex data structures (which is possible only for the container-managed persistence of version 2.0/2.1), then for the mapping of relationships to the database one must choose between two procedures, depending on the cardinality of the entity bean relationship:
-
Simple foreign key relationship: This method is suitable only for the cardinalities 1:1 and 1: n. The table with cardinality n (either table in the 1:1 case) contains in addition the attributes of the primary key of the other table.
-
Relationship table: For the cardinality n : m an additional table is introduced. The attributes of the relationship table are the totality of the primary key attributes of both tables that are linked by the relationship. Each row of the relationship table associates one row of one table with a row of the other table.
The possible navigational directions have no effect on the modeling. In Figure 5-5 we see a comparison between the two methods using the project management example introduced earlier. If an employee is able to work on only one project, then there is a 1: n relationship between the entity Project and the entity Employee. The relationship between the two entities is stored using the foreign key (column Project-ID) in the entity Employee, which refers to the associated project. If an employee can work on several projects, then we are dealing with an n : m relationship between the entity Project and the entity Employee. The relationship between the two entities is stored in this case using the table ProjectEmployee (a relationship table). This table is not modeled as an entity bean. It is used by the EJB container merely for the storage of relationships between the two entities Project and Employee.
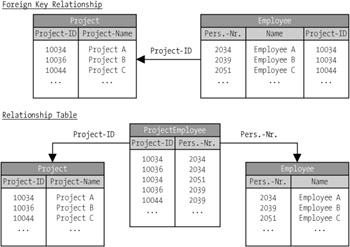
Figure 5-5: Foreign key versus relationship table.
The persistence mechanism is implemented by the persistence manager. In order to carry out this task, precise information is needed about which attribute of the entity bean is to be stored in which database table and in which column.
The same holds for relationships. The persistence manager must know the attributes by which the entity beans stand in relationship to one another, the cardinality of the relationship, and how the relationship is to be stored (via a foreign key relationship or a relationship table). This information is provided by the deployer. Moreover, the organization of the database must be defined in the database. Here one consults a database expert, who defines the optimal scheme with the correct indexes, taking into consideration the effects on performance and memory requirements.
Life Cycle of a Bean Instance
An understanding of the life cycle of an entity bean instance is a prerequisite for developing one. Figure 5-6 shows the various states and state transitions of an entity bean. A distinction is made in the state transitions as to whether the EJB container or the client triggers the state transition.
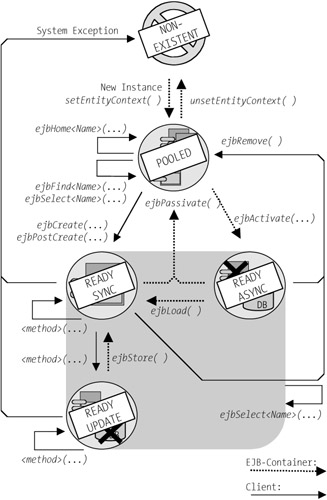
Figure 5-6: State diagram for an entity bean instance.
The EJB specification distinguishes three states of an entity bean instance. To clarify the issues in programming we subdivide the state Ready into three substates:
-
Nonexistent: The instance does not exist.
-
Pooled: The instance exists, but it has not yet been assigned a bean identity. The instance is used to execute client accesses to the home interface, since this does not relate to a particular bean identity.
-
We divide the state Ready into three substates:
-
Ready-Async: The attribute values are possibly not in conformity with the current database contents. Either the attributes have not yet been installed, or the database content has changed on account of a parallel access.
-
Ready-Sync: The attribute values are current.
-
Ready-Update: The bean attributes have been changed by the client. Usually, the bean has been involved in a transaction. The new values have not yet been written, or have been written only partially, to the database.
-
For every entity bean class the EJB container has a pool in which it manages the instances. The pool represents a performance optimization, which above all is achieved by the use of automated memory management (garbage collection). The EJB container avoids the continual generation and deletion of Java objects, using the instances in the pool one after the other for various bean identities. Since one instance can possess only one bean identity at a given time, the pool must contain at least as many instances as there are distinct bean identities that are to be used in parallel.
If the EJB container requires a new instance in the pool, then it generates an instance of the bean class and installs it using setEntityContext. The instance does not yet possess a bean identity. If at some other time the EJB container wishes to reduce the number of bean instances in the pool, then it calls the method unsetEntityContext and then decommissions the instance.
Suppose now that the client is looking for a bean object with the findByPrimaryKey method of the home interface. The EJB container relays the call to an arbitrary bean instance. This is possible because the bean instance does not need a bean identity for the execution of the method.
The corresponding method with the same parameters was implemented in the entity bean class either by the been developer (bean-managed persistence) or provided by the EJB container (container-managed persistence).
As a result, the client obtains the remote or local interface of the found bean object (if the search has more than one result, then a collection or enumeration is used for the return of several remote or local objects). The EJB container must prepare the corresponding bean instance for the method calls. For this it activates an arbitrary bean instance and informs it of the bean identity in the form of the primary key. Then it calls the method ejbActivate. The bean instance is now in the state Ready-Async.
When the client calls a bean method, the EJB container must see to it that the bean instance has the current attribute value. To this end, the persistence mechanism of the EJB container synchronizes the bean instance with the persistence medium (container-managed persistence). Then the method ejbLoad is called to inform the bean about the synchronization that has been achieved. If the persistence mechanism is inherent to the bean (bean-managed persistence), then the synchronization is implemented in the method ejbLoad by the bean provider. After the call to ejbLoad the bean instance is in the state Ready-Sync. All read operations of the client are executed in this state.
If the client executes a write access to the entity bean and changes its attribute values, then the bean instance is temporarily not in sync with the database. The bean instance is now in the state Ready-Update. The EJB container carries out the synchronization at a given time. The persistence mechanism of the EJB container takes over writing the attributes to the database (container-managed persistence). Then the method ejbStore is called to inform the bean instance about the synchronization that has just been accomplished. If the persistence mechanism is provided for within the bean itself (bean-managed persistence), then the synchronization is implemented within the method ejbStore by the bean provider. After a call to ejbStore the bean instance is again in the state Ready-Sync. All write accesses are normally protected by transactions (configured via the deployment descriptor), so that differences between the attribute values and the database contents present no danger to the consistency of the state of the data (see Chapter 7 for details on transactions).
All bean instances that are not currently being used by a client and that are not involved in a transaction can be reused by the EJB container for other bean identities. With a call to the method ejbPassivate the EJB container notifies the bean instance that its state is changing to Pooled. If the old bean identity is needed by the client again, then the EJB container can use and activate an arbitrary bean instance for this purpose.
For the developer of entity beans this means that the bean instance might have to be initialized in the method ejbPassivate. Since under some circumstances a bean instance might languish a long time in the pool, at the time of passivation it should release all of the resources that it commands. Moreover, one should ensure that the bean can be reused for another bean identity.
The generation of a new bean identity functions similarly. The client calls the method create of the home interface. The EJB container relays this call to the corresponding method ejbCreate of a bean instance in the state Pooled. The method evaluates the parameters and sets the attribute values of the bean instance accordingly. Then the EJB container method ejbPostCreate is called with the same parameters. In contrast to ejbCreate, the bean identity in the bean context is available to the method ejbPostCreate. Thus this method can execute further initialization steps. In the case of container-managed persistence the EJB container takes care of the corresponding entry in the database. In the case of bean-managed persistence, the bean provider must program the storage of the new data record in the method ejbCreate of the bean class itself. After the execution of ejbCreate and ejbPostCreate the bean instance is in the state Ready-Sync.
The client has two ways of deleting a bean identity: with the method remove of the (local) home interface using the primary key and by means of a call to the method remove on the local or remote interface of the entity bean. In the first case the EJB container takes over the necessary intermediate steps. It activates a bean instance as required for the bean identity and calls ejbRemove. In the case of container-managed persistence the associated data are deleted by the EJB container (using the persistence manager) from the database. In the case of bean-managed persistence the bean provider must program the deletion of the data set in the method ejbRemove. Upon deletion of the data record in the database, the associated entity bean identity is deleted as well. The bean instance then goes into the state Pooled.
In the life cycle of an entity bean instance system errors can occur. For example, a network error can happen or the database may be unavailable. If a system error occurs in an entity bean instance, then the EJB container deletes this instance, and the instance is not placed again in the pool. For each succeeding access to the associated bean identity the EJB container must activate a new bean instance from the pool. For the bean developer this means that in the case of a system error the bean instance does not need to be initialized for the pool.
After this introduction, which is relevant to all types of entity beans, we shall proceed in the next section to discuss in detail the particular features of the individual entity bean types.
Entity Context
The entity context (interface javax.ejb.EntityContext) is, like the session context in the case of session beans, the interface between the EJB container and the entity bean instance. After it is generated, the entity context is associated with the bean instance via the callback method setEntityContext. The entity bean uses this context during its entire lifetime. The context of an entity bean is frequently changed by the EJB container during its life cycle. Whenever the entity bean changes from the state Pooled to the state Ready, the context of the entity bean changes as well. Through the context the entity bean learns from the EJB container what identity it represents at the moment, the identity of the client that is currently calling a business method, and information about the current transaction.
In the rest of this section we shall introduce the most important methods of the entity context.
EJBHome getEJBHome()
This method gives the bean instance access to its own home interface. The data type of the return value must be transformed (type casting) into the specific home interface of the bean class. The method triggers an exception of type java.lang.IllegalStateException if the entity bean does have a home interface (but rather a local home interface).
EJBLocalHome getEJBLocalHome()
This method gives the bean instance access to its own local home interface. The data type of the return value must be transformed into the specific local home interface of the bean class. The method triggers an exception of type java.lang.IllegalStateException if the entity bean does not have a local home interface (but instead a home interface).
Object getPrimaryKey()
This method gives the bean instance access to the primary key. The primary key reflects the identity that the entity bean currently represents. This method cannot be called in the method ejbCreate. If the method ejbCreate is called, a transition to the Ready state is not yet excluded. The primary key is available to the bean only in the method ejbPostCreate, not in ejbCreate. Later (after the bean has been created), it can obtain the primary key via getPrimaryKey in every method (except unsetEntityContext, of course).
void setRollbackOnly()
This method helps in running transactions (see also Chapter 7). An entity bean instance uses this method in the case of an error in order to ensure that an active transaction ends with a rollback. For example, an error can be a failure in saving persistent attributes of entity beans with bean-managed persistence.
boolean getRollbackOnly()
The method getRollbackOnly is the read counterpart to the method setRollbackOnly. One can check with getRollbackOnly whether it is still possible to terminate the active transaction with commit.
UserTransaction getUserTransaction()
Normally, the EJB container takes over control of transactions. The method getUserTransaction requires an entity bean instance only when it wishes to take over the transaction itself. The return value of the method is an object of the class javax.transaction.UserTransaction, which enables access to the transaction context (see Chapter 7).
Principal getCallerPrincipal()
This method enables an entity bean instance to determine the identity of the client. The return value is an object of the class java.security.Principal (see also Chapter 8).
boolean isCallerInRole(java.lang.String roleName)
With this method a check is made as to whether the declared user has a particular role in the security concept. The possible roles are defined in the deployment descriptor (see also Chapter 8).
EAN: 2147483647
Pages: 103