The Structure of Index Pages
Index pages are structured much like data pages. As with all other types of pages in SQL Server, index pages have a fixed size of 8 KB, or 8192 bytes. Index pages also have a 96-byte header, but just like in data pages, there is an offset array at the end of the page with two bytes for each row to indicate the offset of that row on the page. However, if you use DBCC PAGE with style 1 to print out the individual rows on an index page, the slot array is not shown. If you use style 2, it will only print out all the bytes on a page with no attempt to separate the bytes into individual rows. You can then look at the bottom of the page and notice that each set of two bytes does refer to a byte offset on the page. Each index has a row in the sysindexes table, with an indid value of either 1, for a clustered index, or a number between 2 and 250, indicating a nonclustered index. An indid value of 255 indicates LOB data (text, ntext or image information). The root column value contains a file number and page number where the root of the index can be found. You can then use DBCC PAGE to examine index pages, just as you do for data pages.
The header information for index pages is almost identical to the header information for data pages. The only difference is the value for type, which is 1 for data and 2 for index. The header of an index page also has nonzero values for level and indexId. For data pages, these values are both always 0.
There are basically three different kinds of index pages: leaf level for nonclustered indexes, node (nonleaf) level for clustered indexes, and node level for nonclustered indexes. There isn't really a separate structure for leaf level pages of a clustered index because those are the data pages, which we've already seen in detail. There is, however, one special case for leaf-level clustered index pages.
Clustered Index Rows with a Uniqueifier
If your clustered index was not created with the UNIQUE property, SQL Server adds a 4-byte field when necessary to make each key unique. Since clustered index keys are used as bookmarks to identify the base rows being referenced by nonclustered indexes, there needs to be a unique way to refer to each row in a clustered index. SQL Server adds the uniquifier only when necessary—that is, when duplicate keys are added to the table. As an example, I'll use the same table I initially used in Chapter 6 to illustrate the row structure of a table with all fixed-length columns. I'll create an identical table with a different name, then I'll add a clustered (nonunique) index to the table:
USE pubs GO CREATE TABLE Clustered_Dupes (Col1 char(5) NOT NULL, Col2 int NOT NULL, Col3 char(3) NULL, Col4 char(6) NOT NULL, Col5 float NOT NULL) GO CREATE CLUSTERED INDEX Cl_dupes_col1 ON Clustered_Dupes(col1)
The rows in syscolumns look identical to the ones for the table in Chapter 6, without the clustered index. However, if you look at the sysindexes row for this table, you'll notice something different.
SELECT first, indid, keycnt, name FROM sysindexes WHERE id = object_id ('Clustered_Dupes') RESULT: first indid keycnt name -------------- ------ ------ --------------- 0x000000000000 1 2 Cl_dupes_col1 The column called keycnt, which indicates the number of keys an index has, is 2. If I had created this index using the UNIQUE qualifier, the keycnt value would be 1. If I had looked at the sysindexes row before adding a clustered index, when the table was still a heap, the row for the table would have had a keycnt value of 0. I'll now add the same initial row that I added to the table in Chapter 6, and then I'll look at sysindexes to find the first page of the table:
INSERT Clustered_Dupes VALUES ('ABCDE', 123, null, 'CCCC', 4567.8) GO SELECT first, root, id,indid FROM sysindexes WHERE id = object_id('Clustered_Dupes') RESULT: first root id indid -------------- -------------- ----------- ------ 0xB50500000100 0xB30500000100 1426104121 1 The first column tells me that the first page of the table is 1461 (0x05B5), so I can use DBCC PAGE to examine that page. Remember to turn on trace flag 3604 prior to executing this undocumented DBCC command.
DBCC TRACEON (3604) GO DBCC PAGE (5,1,1461, 1)
The only row on the page looks exactly as it was shown in Figure 6-7, but I'll reproduce it again here, in Figure 8-3. When you read the row output from DBCC PAGE, remember that each two displayed characters represents a byte and that the bytes are displayed from right to left within each group of 4 bytes in the output. For character fields, you can just treat each byte as an ASCII code and convert that to the associated character. Numeric fields are stored with the low-order byte first, so within each numeric field, we must swap bytes to determine what value is being stored. Right now, there are no duplicates of the clustered key, so no extra information has to be provided. However, if I add two additional rows, with duplicate values in col1, the row structure changes:
INSERT Clustered_Dupes VALUES ('ABCDE', 456, null, 'DDDD', 4567.8) INSERT Clustered_Dupes VALUES ('ABCDE', 64, null, 'EEEE', 4567.8) Figure 8-4 shows the three rows that are now on the page.
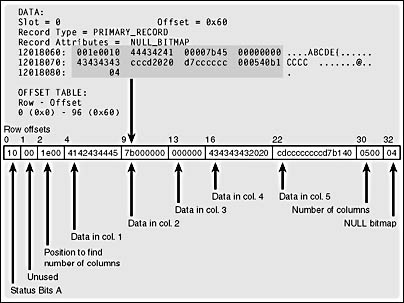
Figure 8-3. A data row containing all fixed-length columns, and a unique value in the clustered key column.
The first difference in the second two rows is that the bits in the first byte (TagA) are different. Bit 5 is on, giving TagA a value of 0x30, which means the variable block is present in the row. Without this bit on, TagA would have a value of 0x10. The "extra" variable-length portions of the second two rows are shaded in the figure. You can see that 8 extra bytes are added when we have a duplicate row. In this case, the first 4 extra bytes are added because the uniqueifier is considered a variable-length column. Since there were no variable-length columns before, SQL Server adds 2 bytes to indicate the number of variable-length columns present. These bytes are at offsets 33-34 in these rows with the duplicate keys and have the value of 1. The next 2 bytes, (offsets 35-36) indicate the position where the first variable length column ends. In both these rows, the value is 0x29, which converts to 41 decimal. The last 4 bytes (offsets 37-40) are the actual uniqueifier. In the second row, which has the first duplicate, the uniquifier is 1. The third row has a uniquifier of 2.
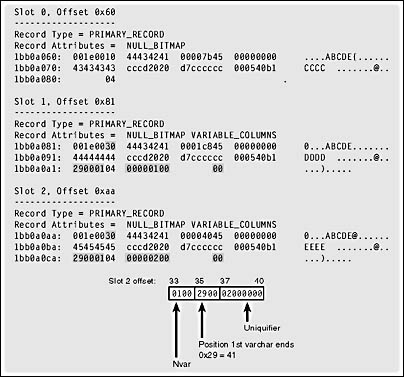
Figure 8-4. Three data rows containing duplicate values in the clustered key column.
Index Row Formats
The row structure of an index entry is very similar to the structure of a data row. An index row does not use the TagB or Fsize row header values. In place of the Fsize field, which indicates where the fixed-length portion of a row ends, the page header pminlen value is used to decode an index row. The pminlen value indicates the offset at which the fixed-length data portion of the row ends. If there are no variable-length or nullable columns in the index row, that is the end of the row. Only if the index row has nullable columns are the field called Ncol and the null bitmap both present. The Ncol field contains a value indicating how many columns are in the index row; this value is needed to determine how many bits are in the null bitmap. Data rows have an Ncol field and null bitmap whether or not any columns allow NULL, but index rows have only a null bitmap and an Ncol field if any NULLs are allowed in an index column. Table 8-1 shows the general format of an index row.
Table 8-1. Information stored in an index row.
| Information | Mnemonic | Size |
|---|---|---|
| Status Bits A | TagA Some of the relevant bits are:
| 1 byte |
| Fixed-length data | Fdata | pminlen - 1 |
| Number of columns | Ncol | 2 bytes |
| NULL bitmap (1 bit for each column in the table; a 1 indicates that the corresponding column is NULL) | Nullbits | Ceiling (Ncol / 8) |
| Number of variable-length columns; only present if >0 | VarCount | 2 bytes |
| Variable column offset array; only present if VarCount > 0 | VarOffset | 2 * VarCount |
| Variable-length data, if any | VarData |
The data contents of an index row depend on the level of the index. All rows except those in the leaf level contain a 6-byte down-page pointer in addition to the key values and bookmarks. The down-page pointer is the last column in the fixed-data portion of the row. In nonclustered indexes, the nonclustered keys and bookmarks are treated as normal columns. They can reside in either the fixed or variable portion of the row, depending on how each of the key columns was defined. A bookmark that is a RID, however, is always part of the fixed-length data.
If the bookmark is a clustered key value and the clustered and nonclustered indexes share columns, the actual data is stored only once. For example, if your clustered index key is lastname and you have a nonclustered index on (firstname, lastname), the index rows will not store the value of lastname twice. I'll show you an example of this shortly.
Clustered Index Node Rows
The node levels of a clustered index contain pointers to pages at the next level down in the index, along with the first key value on each page pointed to. Page pointers are 6 bytes: 2 bytes for the file number and 4 bytes for the page number in the file. The following code creates and populates a table that I'll use to show you the structure of clustered index node rows.
CREATE TABLE clustered_nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (600) NULL ) GO CREATE CLUSTERED INDEX idxCL ON clustered_nodupes(str1) GO SET NOCOUNT ON GO DECLARE @i int SET @i = 1240 WHILE @i < 13000 BEGIN INSERT INTO clustered_nodupes SELECT @i, cast(@i AS char), cast(@i AS char) SET @i = @i + 1 END GO SELECT first, root, id, indid FROM sysindexes WHERE id = object_id('clustered_nodupes') RESULT: first root id indid -------------- -------------- ----------- ------ 0xB80500000100 0xB60500000100 1458104235 1 DBCC TRACEON (3604) GO DBCC PAGE (5,1,1462, 1) The root of this index is at 0x05B6, which is 1462 decimal. Using DBCC PAGE to look at the root, we can see two index entries, as shown in Figure 8-5. When you examine index pages, you need to be aware that the first index key entry on each page is frequently either meaningless or empty. The down-page pointer is valid, but the data for the index key might not be a valid value. When SQL Server traverses the index, it starts looking for a value by comparing the search key with the second key value on the page. If the value being sought is less than the second entry on the page, SQL Server follows the page pointer indicated in the first index entry. In this example, the down-page pointer is at byte offsets 6-9, with a hex value of 0x0839. In decimal, this is 2105.
We can then use DBCC PAGE again to look at page 2105, part of which is shown in Figure 8-6. The row structure is identical to the rows on page 1462, the root page.
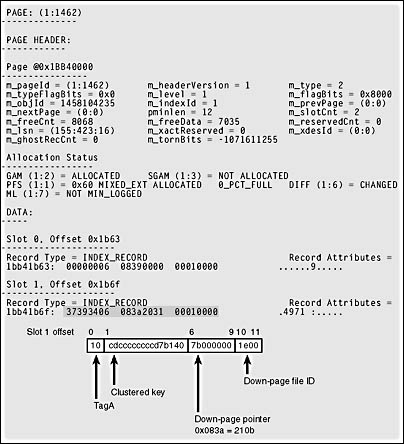
Figure 8-5. The root page of a clustered index.

Figure 8-6. An intermediate index-level page for a clustered index.
The first row has a meaningless key value, but the page-down pointer should be the first page in clustered index order. The hex value for the page-down pointer is 0x07dd, which is 2013 decimal. That page is the leaf level page, and has a structure of a normal data page. If we use DBCC PAGE to look at that page, we'll see that the first row has the value of '10000', which is the minimum value of the str1 column in the table. We can verify this with the following query:
SELECT min(str1) FROM clustered_nodupes
Remember that the clustered index column is a char(5) column. Although the first number I entered was 1240, when converted to a char(5), that's '1240 '. When sorted alphabetically, '10000' comes well before '1240 '.
Nonclustered Index Leaf Rows
Index node rows in a clustered index contain only the first key value of the page they are pointing to in the next level and page-down pointers to guide SQL Server in traversing the index. Nonclustered index rows can contain much more information. The rows in the leaf level of a nonclustered index contain every key value and a bookmark. I'll show you three different examples of nonclustered index leaf rows. First, we'll look at the leaf level of a nonclustered index built on a heap. I'll use the same code I used to build the clustered index with no duplicates in the previous example, but the index I build on the str1 column will be nonclustered. I'll also put only a few rows in the table so that the root page will be the entire index.
CREATE TABLE nc_heap_nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (600) NULL ) GO CREATE UNIQUE INDEX idxNC_heap ON nc_heap_nodupes (str1) GO SET NOCOUNT ON GO DECLARE @i int SET @i = 1240 WHILE @i < 1300 BEGIN INSERT INTO nc_heap_nodupes SELECT @i, cast(@i AS char), cast(@i AS char) SET @i = @i + 1 END GO SELECT first, root, id, indid FROM sysindexes WHERE id = object_id('nc_heap_nodupes') AND indid > 1 RESULT: first root id indid -------------- -------------- ----------- ------ 0xC10500000100 0xC10500000100 1506104406 2 DBCC TRACEON (3604) GO DBCC PAGE (5,1,1473, 1) Since this index is built on a heap, the bookmark is an 8-byte RID. As you can see in Figure 8-7, this RID is fixed-length and is located in the index row immediately after the index key value of '1240 '. The first 4 bytes are the page address, the next 2 bytes are the file ID, and the last 2 bytes are the slot number.
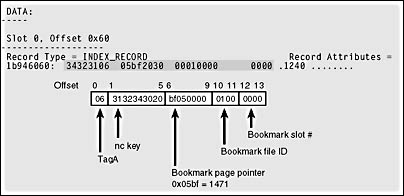
Figure 8-7. An index row on a leaf-level page from a nonclustered index on a heap.
I'll now build a nonclustered index on a similar table, but before building the nonclustered index, I'll build a clustered index on a varchar column so we can see what an index looks like when a bookmark is a clustered index key.. Also, in order not to have the same values in the same sequence in both the str1 and str2 columns, I'll introduce a bit of randomness into the generation of the values for str2. If you run this script, the randomness might end up generating some duplicate values for the unique clustered index column str2. Since each row is inserted in its own INSERT statement, a violation of uniqueness will cause only that one row to be rejected. If you get error messages about PRIMARY KEY violation, just ignore them. You'll still end up with enough rows.
CREATE TABLE nc_nodupes ( id int NOT NULL , str1 char (5) NOT NULL , str2 varchar (10) NULL ) GO CREATE UNIQUE CLUSTERED INDEX idxcl_str2 on nc_nodupes (str2) CREATE UNIQUE INDEX idxNC ON nc_nodupes (str1) GO SET NOCOUNT ON GO DECLARE @i int SET @i = 1240 WHILE @i < 1300 BEGIN INSERT INTO nc_nodupes SELECT @i, cast(@i AS char), cast(cast(@i * rand() AS int) as char) SET @i = @i + 1 END GO SELECT first, root, id, indid FROM sysindexes WHERE id = object_id('nc_nodupes') AND indid > 1 RESULT: first root id indid -------------- -------------- ----------- ------ 0xD00500000100 0xD00500000100 1586104691 2 DBCC TRACEON (3604) GO DBCC PAGE (5,1,1488, 1)
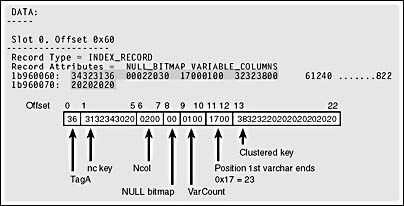
Figure 8-8. An index row on a leaf-level page from a nonclustered index built on a clustered table.
The index row contains the nonclustered key value of '1240 ', and the bookmark is the clustered key '822'. Because the clustered key is variable length, it comes at the end of the row after the Ncol value and null bitmap. A variable-length key column in an index uses only the number of bytes needed to store the value inserted. In the script to create this table, an int is converted to a char to get the value for the field. Since no length is supplied for the char, SQL Server by default allows 30 characters. However, since the table was defined to allow a maximum of 10 characters in that column, that is all that was stored in the row. If the script to create the table had actually converted to char(3), the clustered key bookmark in the index row would use only 3 bytes.
The third example will show a composite nonclustered index on str1 and str2 and an overlapping clustered index on str2. I'll just show you the code to create the table and indexes; the code to populate the table and to find the root of the index is identical to the code in the previous example.
CREATE TABLE nc_overlap ( id int NOT NULL , str1 char (5) NOT NULL , str2 char (10) NULL ) GO CREATE UNIQUE CLUSTERED INDEX idxCL_overlap ON nc_overlap(str2) CREATE UNIQUE INDEX idxNC_overlap ON nc_overlap (str1, str2) GO
Figure 8-9 shows a leaf-level index row from the nonclustered composite index on the table nc_overlap.
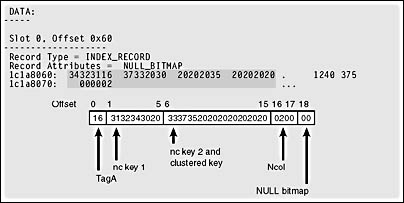
Figure 8-9. An index row on a leaf-level page from a composite nonclustered index with an overlapping clustered key.
Note that the value in column str2 ('375' in this row) is part of the index key for the nonclustered index as well as the bookmark because it is the clustered index key. Although it serves two purposes in the row, its value is not duplicated. The value '375' occurs only once, taking the maximum allowed space of 10 bytes. Because this is a leaf-level row, there is no page-down pointer, and because the index is built on a clustered table, there is no RID, only the clustered key to be used as a bookmark.
Nonclustered Index Node Rows
You now know that the leaf level of a nonclustered index must have a bookmark because from the leaf level you want to be able to find the actual row of data. The nonleaf levels of a nonclustered index only need to help us traverse down to pages at the lower levels. If the nonclustered index is unique, the node rows need to have only the nonclustered key and the page-down pointer. If the index is not unique, the row contains key values, a down-page pointer, and a bookmark.
Let's say I need to create a table that will have enough rows for more than a single nonclustered index level. I can use a script similar to the ones shown previously and change the upper limit of the WHILE loop to 13000. I'll do this twice: I'll create one table with a nonunique nonclustered index on str1 and a clustered index on str2 and another table with a unique nonclustered index on str1 and a clustered index on str2. For the purposes of creating the index rows, SQL Server doesn't care whether the keys in the nonunique index actually contain duplicates. If the index is not defined to be unique, even if all the values are unique, the nonleaf index rows will contain bookmarks. You can see this is in the index row in Figure 8-10. Figure 8-11 shows an index row for a nonclustered index row for a unique index.
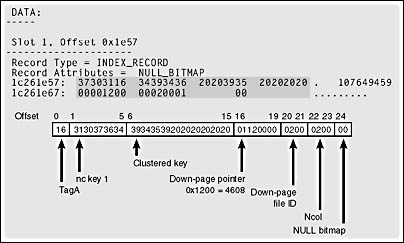
Figure 8-10. A nonleaf index row for a nonunique, nonclustered index.
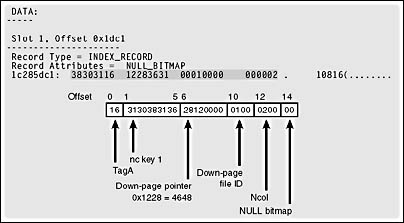
Figure 8-11. A nonleaf index row for a unique, nonclustered index.
As you've seen, once you've found the root page of an index in the sysindexes table, you can decode down-page pointers in every row to find all the pages that belong to the index. The header information of an index page also has level, prevPage, and nextPage values, so you can ascertain the order of pages at a particular level of the index. As much as I enjoy decoding strings of bytes and converting hex values to decimal, I don't mind an occasional shortcut. You can use an undocumented DBCC command that lists all the pages that belong to a particular index. Keep in mind that Microsoft does not support this command and that it is not guaranteed to maintain the same behavior from release to release. The command DBCC IND has three parameters:
DBCC IND ({'dbname' | dbid }, { 'objname' | objid }, { indid | 0 | -1 | -2 }) The first parameter is the database name or the database ID. The second parameter is an object name or object ID within the database. The third parameter is a specific index ID or one of the values 0, -1, or -2. The values for this parameter have the following meanings:
| 0 | Displays the page numbers for all IAMs and data pages. |
| -1 | Displays the page numbers for all IAMs, data pages, and index pages. |
| -2 | Displays the page numbers for all IAMs. |
| Index ID | Displays the page numbers for all IAMs and index pages for this index. If the index ID is 1 (meaning the clustered index), the data pages are also displayed. |
If we run this command on the table I created for Figure 8-10, which is called nc_nonunique_big, with a third parameter of 2 (for the nonclustered index), we get the following results:
DBCC IND(5, nc_nonunique_big, 2) RESULTS: NextPageFID Next Prev Prev Page Page Page Page PageFID PagePID IAMFID IAMPID IndexLevel FID PID FID PID ------- ------- ------ ------ ---------- ----------- ---- ---- ---- 1 1594 NULL NULL 0 0 0 0 0 1 1593 1 1594 1 0 0 0 0 1 1596 1 1594 0 1 4608 0 0 1 1597 1 1594 0 1 1599 1 4611 1 1599 1 1594 0 1 1602 1 1597 1 1602 1 1594 0 1 1604 1 1599 1 1604 1 1594 0 1 1606 1 1602 1 1606 1 1594 0 1 1607 1 1604 1 1607 1 1594 0 1 4584 1 1606 1 4584 1 1594 0 1 4585 1 1607 1 4585 1 1594 0 1 4586 1 4584 1 4586 1 1594 0 1 4587 1 4585 1 4587 1 1594 0 1 4588 1 4586 1 4588 1 1594 0 1 4589 1 4587 1 4589 1 1594 0 1 4590 1 4588 1 4590 1 1594 0 0 0 1 4589 1 4591 1 1594 0 1 4611 1 4610 1 4608 1 1594 0 1 4609 1 1596 1 4609 1 1594 0 1 4610 1 4608 1 4610 1 1594 0 1 4591 1 4609 1 4611 1 1594 0 1 1597 1 4591
The columns in the result set are described in Table 8-2. Note that all page references have the file and page component conveniently split between two columns, so you don't have to do any conversion.
Table 8-2. Column descriptions for DBCC IND output.
| Column | Meaning |
|---|---|
| PageFID | Index file ID |
| PagePID | Index page ID |
| IAMFID | File ID of the IAM managing this page |
| IAMPID | Page ID of the IAM managing this page |
| ObjectID (Not shown in output) | Object ID |
| IndexID (Not shown in output) | Index ID |
| PageType (Not shown in output) | Page type: 1 = Data page, 2 = Index page, 10 = IAM page |
| IndexLevel | Level of index; 0 is leaf |
| NextPageFID | File ID for next page at this level |
| NextPagePID | Page ID for next page at this level |
| PrevPageFID | File ID for previous page at this level |
| PrevPagePID | Page ID for previous page at this level |
EAN: 2147483647
Pages: 179