Row-Level Locking vs. Page-Level Locking
| The debate over row-level locking versus page-level locking has been one of those near-religious wars and warrants a few comments here. All major vendors now support row-level locking. Although SQL Server 2005 fully supports row-level locking, in some situations the lock manager will decide not to lock individual rows and will instead lock pages or the whole table. In other cases, many smaller locks will be escalated to a table lock, as I'll discuss in the upcoming section about lock escalation. Prior to version 7.0, the smallest unit of data that SQL Server could lock was a page. Even though many people argued that this was unacceptable and it was impossible to maintain good concurrency while locking entire pages, many large and powerful applications were written and deployed using only page-level locking. If they were well designed and tuned, concurrency was not an issue, and some of these applications supported hundreds of active user connections with acceptable response times and throughput. However, with the change in page size from 2 KB to 8 KB for SQL Server 7.0, the issue has become more critical. Locking an entire page means locking four times as much data as in previous versions. Beginning with version 7.0, SQL Server implements full row-level locking, so any potential problems due to lower concurrency with the larger page size should not be an issue. However, locking isn't free. Resources are required to manage locks. Recall that a lock is an in-memory structure of 64 or 128 bytes (for 32-bit or 64-bit machines, respectively) with another 32 or 64 bytes for each process holding or requesting the lock. If you need a lock for every row and you scan a million rows, you need more than 64 megabytes (MB) of RAM just to hold locks for that one process. Beyond memory consumption issues, locking is a fairly processing-intensive operation. Managing locks requires substantial bookkeeping. Recall that, internally, SQL Server uses a lightweight mutex called a spinlock to guard resources, and it uses latchesalso lighter than full-blown locksto protect nonleaf-level index pages. These performance optimizations avoid the overhead of full locking. If a page of data contains 50 rows of data, all of which will be used, it is obviously more efficient to issue and manage one lock on the page than to manage 50. That's the obvious benefit of page lockinga reduction in the number of lock structures that must exist and be managed. Let's say two processes each need to update a few rows of data, and even though the rows are not the same ones, some of them happen to exist on the same page. With page-level locking, one process would have to wait until the page locks of the other process were released. If you use row-level locking instead, the other process does not have to wait. The finer granularity of the locks means that no conflict occurs in the first place because each process is concerned with different rows. That's the obvious benefit of row-level locking. Which of these obvious benefits wins? Well, the decision isn't clear-cut, and it depends on the application and the data. Each type of locking can be shown to be superior for different types of applications and usage. The stored procedure sp_indexoption lets you manually control the unit of locking within an index. It also lets you disallow page locks or row locks within an index. Because these options are available only for indexes, there is no way to control the locking within the data pages of a heap. (But remember that if a table has a clustered index, the data pages are part of the index and are affected by the sp_indexoption setting.) The index options are set for each table or index individually. Two options, AllowRowLocks and AllowPageLocks, are both set to TRUE initially for every table and index. If both of these options are set to FALSE for a table, only full table locks are allowed. As mentioned earlier, SQL Server determines at runtime whether to initially lock rows, pages, or the entire table. The locking of rows (or keys) is heavily favored. The type of locking chosen is based on the number of rows and pages to be scanned, the number of rows on a page, the isolation level in effect, the update activity going on, the number of users on the system needing memory for their own purposes, and so on. Lock EscalationSQL Server automatically escalates row, key, or page locks to coarser table locks as appropriate. This escalation protects system resourcesit prevents the system from using too much memory for keeping track of locksand increases efficiency. For example, after a query acquires many row locks, the lock level can be escalated to a table lock because it probably makes more sense to acquire and hold a single table lock than to hold many row locks. By escalating the lock, SQL Server acquires a single table lock, and the many row locks are released. This escalation to a table lock reduces locking overhead and keeps the system from running out of locks. Because a finite amount of memory is available for the lock structures, escalation is sometimes necessary to make sure the memory for locks stays within reasonable limits. Lock escalation occurs in the following situations:
When the lock escalation is triggered, the attempt might fail if there are conflicting locks. So for example, if an X lock on a RID needs to be escalated to the table level and there are concurrent X locks on the same table held by a different process, the lock escalation attempt will fail. However, SQL Server will continue to attempt to escalate the lock every time the transaction acquires another 1,250 locks on the same object. If the lock escalation succeeds, SQL Server will release all the row and page locks on the index or the heap. Note
Disabling Lock EscalationLock escalation can potentially lead to blocking of future concurrent access to the index or the heap by other transactions needing row or page locks on the object. SQL Server cannot de-escalate the lock when new requests are made. So lock escalation is not always a good idea for all applications. SQL Server 2005 supports disabling lock escalation in two ways, using trace flags.
If both trace flags (1211 and 1224) are set at the same time, trace flag 1211 takes precedence. The trace flags affect the entire instance of SQL Server. In many cases, it is desirable to control the escalation threshold at the object level, perhaps based on the size of the object. The default escalation point of 5,000 locks might be too many locks for a small table and too few locks for a large table. DeadlocksA deadlock occurs when two processes are waiting for a resource and neither process can advance because the other process prevents it from getting the resource. A true deadlock is a catch-22 in which, without intervention, neither process can ever make progress. When a deadlock occurs, SQL Server intervenes automatically. SQL Server 2005 produces more detailed deadlock diagnostics than previous versions. In addition, deadlocks can be detected for more types of resources. In this section, I'll refer mainly to deadlocks acquired due to conflicting locks, although deadlocks can also be detected on worker threads, memory, parallel query resources, and multiple active result sets (MARS) resources. Note
In SQL Server, two main types of deadlocks can occur: a cycle deadlock and a conversion deadlock. Figure 8-5 shows an example of a cycle deadlock. Process A starts a transaction, acquires an exclusive table lock on the Product table, and requests an exclusive table lock on the PurchaseOrderDetail table. Simultaneously, process B starts a transaction, acquires an exclusive lock on the PurchaseOrderDetail table, and requests an exclusive lock on the Product table. The two processes become deadlockedcaught in a "deadly embrace." Each process holds a resource needed by the other process. Neither can progress, and, without intervention, both would be stuck in deadlock forever. You can actually generate the deadlock SQL Server Management Studio, as follows:
Figure 8-5. A cycle deadlock resulting from two processes each holding a resource needed by the other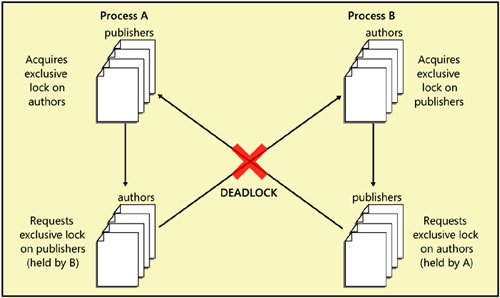 Figure 8-6 shows an example of a conversion deadlock. Process A and process B each hold a shared lock on the same page within a transaction. Each process wants to promote its shared lock to an exclusive lock but cannot do so because of the other process's lock. Again, intervention is required. Figure 8-6. A conversion deadlock resulting from two processes wanting to promote their locks on the same resource within a transaction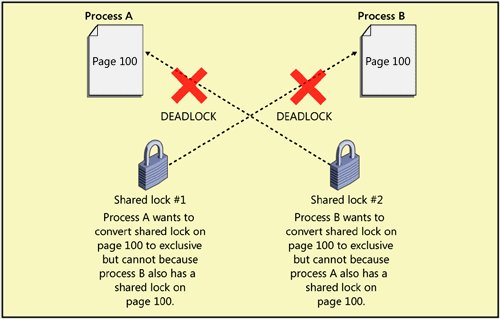 SQL Server automatically detects deadlocks and intervenes through the lock manager, which provides deadlock detection for regular locks. In SQL Server 2005, deadlocks can also involve resources other than locks. For example, if process A is holding a lock on Table1 and is waiting for memory to become available and process B has some memory it can't release until it acquires a lock on Table1, the processes will deadlock. When SQL Server detects a deadlock, it terminates one process's batch, rolling back the active transaction and releasing all that process's locks to resolve the deadlock. In addition to deadlocks on lock resources and memory resources, deadlocks can also occur with resources involving worker threads, parallel query executionrelated resources, and MARS resources. Latches are not involved in deadlock detection because SQL Server uses deadlock-proof algorithms when it acquires latches. In SQL Server, a separate thread called LOCK_MONITOR checks the system for deadlocks every 5 seconds. As deadlocks occur, the deadlock detection interval is reduced and can go as low as 100 milliseconds. In fact, the first few lock requests that cannot be satisfied after a deadlock has been detected will immediately trigger a deadlock search rather than wait for the next deadlock detection interval. If the deadlock frequency declines, the interval can go back to every 5 seconds. This LOCK_MONITOR thread checks for deadlocks by inspecting the list of waiting locks for any cycles, which indicate a circular relationship between processes holding locks and processes waiting for locks. SQL Server attempts to choose as the victim the process that would be least expensive to roll back, considering the amount of work the process has already done. That process is killed and is sent error message 1205. The transaction is rolled back, meaning all its locks are released, so other processes involved in the deadlock can proceed. However, certain operations are marked as golden, or unkillable, and cannot be chosen as the deadlock victim. For example, a process involved in rolling back a transaction cannot be chosen as a deadlock victim because the changes being rolled back could be left in an indeterminate state, causing data corruption. Using the SET DEADLOCK_PRIORITY statement, a process can determine its priority for being chosen as the victim if it is involved in a deadlock. There are 21 different priority levels, from 10 to 10. The value LOW is equivalent to 5, NORMAL is 0, and HIGH is 5. Which session is chosen as the deadlock victim depends on each session's deadlock priority. If the sessions have different deadlock priorities, the session with the lowest deadlock priority is chosen as the deadlock victim. If both sessions have set the same deadlock priority, SQL Server selects as the victim the session that is less expensive to roll back. Note
In the example in Figure 8-5, the cycle deadlock could have been avoided if the processes had decided on a protocol beforehandfor example, if they had decided to always access the Product table first and the PurchaseOrderDetail table second. Then one of the processes would get the initial exclusive lock on the table being accessed first, and the other process would wait for the lock to be released. One process waiting for a lock is normal and natural. Remember, waiting is not a deadlock. You should always try to have a standard protocol for the order in which processes access tables. If you know that the processes might need to update the row after reading it, they should initially request an update lock, not a shared lock. If both processes request an update lock rather than a shared lock, the process that is granted an update lock is assured that the lock can later be promoted to an exclusive lock. The other process requesting an update lock has to wait. The use of an update lock serializes the requests for an exclusive lock. Other processes needing only to read the data can still get their shared locks and read. Because the holder of the update lock is guaranteed an exclusive lock, the deadlock is avoided. In many systems, deadlocks cannot be completely avoided, but if the application handles the deadlock appropriately, the impact on any users involved, and on the rest of the system, should be minimal. (Appropriate handling implies that when an error 1205 occurs, the application resubmits the batch, which will most likely succeed on a second try. Once one process is killed, its transaction is aborted, and its locks are rolled back, the other process involved in the deadlock can finish its work and release its locks, so the environment will not be conducive to another deadlock.) Although you might not be able to completely avoid deadlocks, you can minimize their occurrence. For example, you should write your applications so that your processes hold locks for a minimal amount of time; in that way, other processes won't have to wait too long for locks to be released. Although you don't usually invoke locking directly, you can influence locking by keeping transactions as short as possible. For example, don't ask for user input in the middle of a transaction. Instead, get the input first and then quickly perform the transaction. Most of the techniques for troubleshooting and avoiding deadlocks are similar to the techniques for troubleshooting blocking problems in general. This topic will be discussed in Inside Microsoft SQL Server 2005: Query Tuning and Optimization. |
EAN: 2147483647
Pages: 115