Data Modification Internals
| We've now seen how SQL Server stores data and index information. Now we'll look at what SQL Server actually does internally when your data is modified. We've seen how clustered indexes control space usage in SQL Server. As a rule of thumb, you should always have a clustered index on a table. There are some cases in which you might be better off with a heap, such as when the most important factor is the speed of INSERT operations, but until you do thorough testing to establish that you have one of these cases, it's better to have a clustered index than to have no organization to your data at all. In Inside Microsoft SQL Server 2005: Query Tuning and Optimization, I'll examine the benefits and tradeoffs of clustered and nonclustered indexes and present some guidelines for their use. For now, we'll look only at how SQL Server deals with the existence of indexes when processing data modification statements. Inserting RowsWhen inserting a new row into a table, SQL Server must determine where to put it. When a table has no clustered indexthat is, when the table is a heapa new row is always inserted wherever room is available in the table. In Chapter 6, I showed you how IAMs and the PFS pages keep track of which extents in a file already belong to a table and which of the pages in those extents have space available. Even without a clustered index, space management is quite efficient. If no pages with space are available, SQL Server tries to find unallocated pages from existing uniform extents that already belong to the object. If none exists, SQL Server must allocate a whole new extent to the table. Chapter 4 discussed how the GAMs and SGAMs were used to find extents available to be allocated to an object. A clustered index directs an insert to a specific page based on the value the new row has for the clustered index key columns. The insert occurs when the new row is the direct result of an INSERT statement or when it's the result of an UPDATE statement executed via a delete-followed-by-insert (delete/insert) strategy. New rows are inserted into their clustered position, splicing in a page via a page split if the current page has no room. You saw earlier in this chapter that if a clustered index isn't declared as unique and duplicate values are inserted for a key, an automatic uniqueifier is generated for all subsequent rows with the same key. Internally, SQL Server treats all clustered index keys as unique. Because the clustered index dictates a particular ordering for the rows in a table, every new row has a specific location where it belongs. If there's no room for the new row on the page where it belongs, you must allocate a new page and link it into the list of pages. If possible, this new page is allocated from the same extent as the other pages to which it will be linked. If the extent is full, a new extent (eight pages, or 64 KB) is allocated to the object. As described in Chapter 4, SQL Server uses the GAM pages to find an available extent. Splitting PagesAfter SQL Server finds the new page, the original page must be split; half the rows are left on the original page, and half are moved to the new page. In some cases, SQL Server finds that even after the split, there's no room for the new row, which, because of variable-length fields, could potentially be much larger than any of the existing rows on the pages. After the split, one or more rows are promoted to the parent page. One row is promoted if only a single split is needed. However, if the new row still won't fit after a single split, there can potentially be multiple new pages and multiple promotions to the parent page. For example, consider a page with 32 rows on it. Suppose that SQL Server tries to insert a new row with 8,000 bytes. It will split the page once, and the new 800-byte row won't fit. Even after a second split, the new row won't fit. Eventually, SQL Server will realize that the new row cannot fit on a page with any other rows, and it will allocate a new page to hold only the new row. Quite a few splits will occur, resulting in many new pages, and many new rows on the parent page. An index tree is always searched from the root down, so during an insert operation it is split on the way down. This means that while the index is being searched on an insert, the index is protected in anticipation of possibly being updated. The protection mechanism is a latch, which you can think of as something like a lock. (Locks will be discussed in detail in Chapter 8.) A latch is acquired while a page is being read from or written to disk and protects the physical integrity of the contents of the page. A parent node (not a leaf node) is latched until the child node is known to be available for its own latch. Then the parent latch can be released safely. Before the latch on a parent node is released, SQL Server determines whether the page will accommodate another two rows; if not, it splits the page. This occurs only if the page is being searched with the objective of adding a row to the index. The goal is to ensure that the parent page always has room for the row or rows that result from a child page splitting. (Occasionally, this results in pages being split that don't need to beat least not yet. In the long run, it's a performance optimization.) The type of split depends on the type of page being split: a root page of an index, an intermediate index page, or a data page. Splitting the Root Page of an IndexIf the root page of an index needs to be split in order for a new index row to be inserted, two new pages are allocated to the index. All the rows from the root are split between these two new pages, and the new index row is inserted into the appropriate place on one of these pages. The original root page is still the root, but now it has only two rows on it, pointing to each of the newly allocated pages. A root page split creates a new level in the index. Because indexes are usually only a few levels deep, this type of split doesn't occur often. Splitting the Intermediate Index PageAn intermediate index page split is accomplished simply by locating the midpoint of the index keys on the page, allocating a new page, and then copying the lower half of the old index page into the new page. Again, this doesn't occur often, although it's more common than splitting the root page. Splitting the Data PageA data page split is the most interesting and potentially common case, and it's probably the only split that you, as a developer, should be concerned with. Data pages split only under insert activity and only when a clustered index exists on the table. If no clustered index exists, the insert goes on any page that has room for the new row, according to the PFS pages. Although splits are caused only by insert activity, that activity can be a result of an UPDATE statement, not just an INSERT statement. As you're about to learn, if the row can't be updated in place or at least on the same page, the update is performed as a delete of the original row followed by an insert of the new version of the row. The insertion of the new row can, of course, cause a page split. Splitting a data page is a complicated operation. Much like an intermediate index page split, it's accomplished by locating the midpoint of the index keys on the data page, allocating a new page, and then copying half of the old page into the new page. It requires that the index manager determine the page on which to locate the new row and then handle large rows that don't fit on either the old page or the new page. When a data page is split, the clustered index key values don't change, so the nonclustered indexes aren't affected. Let's look at what happens to a page when it splits. The following script creates a table with large rowsso large, in fact, that only five rows will fit on a page. Once the table is created and populated with five rows, we'll find its first (and only, in this case) page by inserting the output of DBCC IND in the sp_table_pages table, finding the information for the data page with no previous page, and then using DBCC PAGE to look at the contents of the page. Because we don't need to see all 8,020 bytes of data on the page, we'll look at only the row offset array at the end of the page and then see what happens to those rows when we insert a sixth row. /* First create the table */ USE AdventureWorks; GO DROP TABLE bigrows; GO CREATE TABLE bigrows ( a int primary key, b varchar(1600) ); GO /* Insert five rows into the table */ INSERT INTO bigrows VALUES (5, REPLICATE('a', 1600);) INSERT INTO bigrows VALUES (10, replicate('b', 1600)); INSERT INTO bigrows VALUES (15, replicate('c', 1600)); INSERT INTO bigrows VALUES (20, replicate('d', 1600)); INSERT INTO bigrows VALUES (25, replicate('e', 1600)); GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind ( AdventureWorks, bigrows, -1)' ); SELECT PageFID, PagePID FROM sp_table_pages WHERE PageType = 1; RESULTS: (Yours will vary.) PageFID PagePID ------- ----------- 2252 DBCC TRACEON(3604); GO DBCC PAGE(AdventureWorks, 1, 2252, 1);Here is the row offset array from the DBCC PAGE output: Row - Offset 4 (0x4) - 6556 (0x199c) 3 (0x3) - 4941 (0x134d) 2 (0x2) - 3326 (0xcfe) 1 (0x1) - 1711 (0x6af) 0 (0x0) - 96 (0x60) Now we'll insert one more row and look at the row offset array again: INSERT INTO bigrows VALUES (22, REPLICATE('x', 1600)) ; GO DBCC PAGE(AdventureWorks, 1, 2252, 1); GOWhen you inspect the original page after the split, you might find that it contains either the first half of the rows from the original page or the second half. SQL Server normally moves the rows so the new row to be inserted goes on the new page. Because the rows are moving anyway, it makes more sense to adjust their positions to accommodate the new inserted row. In this example, the new row, with a clustered key value of 22, would have been inserted in the second half of the page. So when the page split occurs, the first three rows stay on the original page, 2252. You can inspect the page header to find the location of the next page, which contains the new row. The page number is indicated by the m_nextPage field. This value is expressed as a file number:page number pair, in decimal, so you can easily use it with the DBCC PAGE command. When I ran this query, I got an m_nextPage of 1:2303, so I ran the following command: DBCC PAGE(AdventureWorks, 1, 2303, 1); Here's the row offset array after the insert for the second page: Row - Offset 2 (0x2) - 1711 (0x6af) 1 (0x1) - 3326 (0xcfe) 0 (0x0) - 96 (0x60) Note that after the page split, three rows are on the page: the last two original rows with keys of 20 and 25, and the new row with a key of 22. If you examine the actual data on the page, you'll notice that the new row is at slot position 1, even though the row itself is physically the last one on the page. Slot 1 (with value 22) starts at offset 3326, and slot 2 (with value 25) starts at offset 1711. The clustered key ordering of the rows is indicated by the slot number of the row, not by the physical position on the page. If a table has a clustered index, the row at slot 1 will always have a key value less than the row at slot 2 and greater than the row at slot 0. Although the typical page split isn't too expensive, you'll want to minimize the frequency of page splits in your production system, at least during peak usage times. One page split is cheap, hundreds or thousands are not. You can avoid system disruption during busy times by reserving some space on pages using the FILLFACTOR clause when you're creating the clustered index on existing data. You can use this clause to your advantage during your least busy operational hours by periodically re-creating the clustered index with the desired FILLFACTOR. That way, the extra space is available during peak usage times, and you'll save the overhead of splitting then. If there are no "slow" times, you can reorganize your index with ALTER INDEX and readjust the FILLFACTOR without having to make the entire table unavailable. Note that ALTER INDEX with REORGANIZE can only adjust the fillfactor by compacting data and removing pages; it will never add new pages to re-establish a fillfactor. Using SQL Server Agent, you can easily schedule the rebuilding or reorganizing of indexes to occur at times when activity is lowest. I'll talk about rebuilding and reorganizing your indexes in the section titled "ALTER INDEX." Note
Deleting RowsWhen you delete rows from a table, you have to consider what happens both to the data pages and the index pages. Remember that the data is actually the leaf level of a clustered index, and deleting rows from a table with a clustered index happens the same way as deleting rows from the leaf level of a nonclustered index. Deleting rows from a heap is managed in a different way, as is deleting from node pages of an index. Deleting Rows from a HeapSQL Server 2005 doesn't automatically compress space on a page when a row is deleted. As a performance optimization, the compaction doesn't occur until a page needs additional contiguous space for inserting a new row. You can see this in the following example, which deletes a row from the middle of a page and then inspects that page using DBCC PAGE. USE AdventureWorks; GO CREATE TABLE smallrows ( a int identity, b char(10) ); GO INSERT INTO smallrows VALUES ('row 1'); INSERT INTO smallrows VALUES ('row 2'); INSERT INTO smallrows VALUES ('row 3'); INSERT INTO smallrows VALUES ('row 4'); INSERT INTO smallrows VALUES ('row 5'); GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind (AdventureWorks, smallrows, -1)' ); SELECT PageFID, PagePID FROM sp_table_pages WHERE PageType = 1; Results: PageFID PagePID ------- ----------- 1 4536 DBCC TRACEON(3604); GO DBCC PAGE(AdventureWorks, 1, 4536,1);Here is the output from DBCC PAGE:
Now we'll delete the middle row (WHERE a = 3) and look at the page again. DELETE FROM smallrows WHERE a = 3; GO DBCC PAGE(AdventureWorks, 1, 4536,1); GO Here is the output from the second execution of DBCC PAGE.
Note that in the heap, the row doesn't show up in the page itself. The row offset array at the bottom of the page shows that the third row (at slot 2) is now at offset 0 (which means there really is no row using slot 2), and the row using slot 3 is at its same offset as before the delete. The data on the page is not compressed. In addition to space on pages not being reclaimed, empty pages in heaps frequently cannot be reclaimed. Even if you delete all the rows from a heap, SQL Server will not mark the empty pages as unallocated, so the space will not be available for other objects to use. The catalog view sys.dm_db_partition_stats will still show the space as belonging to the heap table. Deleting Rows from a B-TreeIn the leaf level of an index, either clustered or nonclustered, when rows are deleted, they're marked as ghost records. This means that the row stays on the page but a bit is changed in the row header to indicate that the row is really a ghost. The page header also reflects the number of ghost records on a page. Ghost records are used for several purposes. They can be used to make rollback much more efficient; if the row hasn't physically been removed, all SQL Server has to do to roll back a delete is to change the bit indicating that the row is a ghost. It is also a concurrency optimization for key-range locking (which I'll discuss in Chapter 8), along with other locking modes. Ghost records are also used to support row-level versioning; that will also be discussed in Chapter 8. Ghost records are cleaned up sooner or later, depending on the load on your system, and sometimes they can be cleaned up before you have a chance to inspect them. In the code shown below, if you perform the DELETE and then wait a minute or two to run DBCC PAGE, the ghost record might really disappear. That is why I look at the page number for the table before I run the DELETE, so I can execute the DELETE and the DBCC page with a single click from my query window. To guarantee that the ghost will not be cleaned up, I can put the DELETE into a user transaction and not commit or roll back the transaction before examining the page. The housekeeping thread will not clean up ghost records that are part of an active transaction. Alternatively, I can use an the undocumented trace flag 661 to disable ghost cleanup to ensure consistent results when running tests such as in this script. As usual, keep in mind that undocumented trace flags are not guaranteed to continue to work in any future release or service pack, and no support is available for them. Also be sure to turn off the trace flag when you're done with your testing. The following example builds the same table used in the previous DELETE example, but this time the table has a primary key declared, which means a clustered index will be built. The data is the leaf level of the clustered index, so when the row is removed, it will be marked as a ghost. USE AdventureWorks; GO DROP TABLE smallrows; GO CREATE TABLE smallrows ( a int IDENTITY PRIMARY KEY, b char(10) ); GO INSERT INTO smallrows VALUES ('row 1'); INSERT INTO smallrows VALUES ('row 2'); INSERT INTO smallrows VALUES ('row 3'); INSERT INTO smallrows VALUES ('row 4'); INSERT INTO smallrows VALUES ('row 5'); GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind (AdventureWorks, smallrows, -1)' ); SELECT PageFID, PagePID FROM sp_table_pages WHERE PageType = 1; Results: PageFID PagePID ------- ----------- 1 4568 DELETE FROM smallrows WHERE a = 3; GO DBCC TRACEON(3604); DBCC PAGE(AdventureWorks, 1, 4544, 1); GOHere is the output from DBCC PAGE:
Note that the row still shows up in the page itself because the table has a clustered index. The header information for the row shows that this is really a ghosted record. The row offset array at the bottom of the page shows that the row at slot 2 is still at the same offset and that all rows are in the same location as before the deletion. In addition, the page header gives us a value (m_ghostRecCnt) for the number of ghosted records in the page. To see the total count of ghost records in a table, you can look at the sys.dm_db_index_physical_stats function, which we'll see in detail later in this chapter. Deleting Rows in the Node Levels of an IndexWhen you delete a row from a table, all nonclustered indexes must be maintained because every nonclustered index has a pointer to the row that's now gone. Rows in index node pages aren't ghosted when deleted, but just as with heap pages, the space isn't compressed until new index rows need space in that page. Reclaiming PagesWhen the last row is deleted from a data page, the entire page is deallocated. The exception is if the table is a heap, as I discussed earlier. (If the page is the only one remaining in the table, it isn't deallocated. A table always contains at least one page, even if it's empty.) Deallocation of a data page results in the deletion of the row in the index page that pointed to the deallocated data page. Index pages are deallocated if an index row is deleted (which, again, might occur as part of a delete/insert update strategy), leaving only one entry in the index page. That entry is moved to its neighboring page, and then the empty page is deallocated. The discussion so far has focused on the page manipulation necessary for deleting a single row. If multiple rows are deleted in a single delete operation, you must be aware of some other issues. Because the issues of modifying multiple rows in a single query are the same for inserts, updates, and deletes, we'll discuss this issue in its own section, later in this chapter. Updating RowsSQL Server updates rows in multiple ways, automatically and invisibly choosing the fastest update strategy for the specific operation. In determining the strategy, SQL Server evaluates the number of rows affected, how the rows will be accessed (via a scan or an index retrieval, and via which index), and whether changes to the index keys will occur. Updates can happen either in place, by just changing one column's value to a new value in the original row, or as a delete followed by an insert. In addition, updates can be managed by the query processor or by the storage engine. In this section, we'll examine only whether the update happens in place or whether SQL Server treats it as two separate operations: delete the old row and insert a new row. The question of whether the update is controlled by the query processor or the storage engine is actually relevant to all data modification operations (not just updates), so we'll look at that in a separate section. Moving RowsWhat happens if a table row has to move to a new location? In SQL Server 2005, this can happen because a row with variable-length columns is updated to a new, larger size so that it no longer fits on the original page. It can also happen when the clustered index column is changing, because rows are logically ordered by the clustering key. For example, if we have a clustered index on lastname, a row with a lastname value of Abbot will be stored near the beginning of the table. If the lastname value is then updated to Zappa, this row will have to move to near the end of the table. Earlier in this chapter, we looked at the structure of indexes and saw that the leaf level of non-clustered indexes contains a row locator, or bookmark, for every single row in the table. If the table has a clustered index, that row locator is the clustering key for that row. So ifand only ifthe clustered index key is being updated, modifications are required in every nonclustered index. Keep this in mind when you decide which columns to build your clustered index on. It's a great idea to cluster on a nonvolatile column. If a row moves because it no longer fits on the original page, it will still have the same row locator (in other words, the clustering key for the row stays the same), and no nonclustered indexes will have to be modified. In our discussion of index internals, you also saw that if a table has no clustered index (in other words, it's a heap), the row locator stored in the nonclustered index is actually the physical location of the row. In SQL Server 2005, if a row in a heap moves to a new page, the row will leave a forwarding pointer in the original location. The nonclustered indexes won't need to be changed; they'll still refer to the original location, and from there they'll be directed to the new location. Let's look at an example. I'll create a table a lot like the one we created for doing inserts, but this table will have a third column of variable length. After I populate the table with five rows, which will fill the page, I'll update one of the rows to make its third column much longer. The row will no longer fit on the original page and will have to move. I can then load the output from DBCC IND into the sp_table_pages table to get the page numbers used by the table. USE AdventureWorks; GO DROP TABLE bigrows; GO CREATE TABLE bigrows ( a int IDENTITY , b varchar(1600), c varchar(1600)); GO INSERT INTO bigrows VALUES (REPLICATE('a', 1600), ''); INSERT INTO bigrows VALUES (REPLICATE('b', 1600), ''); INSERT INTO bigrows VALUES (REPLICATE('c', 1600), ''); INSERT INTO bigrows VALUES (REPLICATE('d', 1600), ''); INSERT INTO bigrows VALUES (REPLICATE('e', 1600), ''); GO UPDATE bigrows SET c = REPLICATE('x', 1600) WHERE a = 3; GO TRUNCATE TABLE sp_table_pages; INSERT INTO sp_table_pages EXEC ('dbcc ind (AdventureWorks, bigrows, -1)' ); SELECT PageFID, PagePID FROM sp_table_pages WHERE PageType = 1; RESULTS: PageFID PagePID ------- ----------- 1 2252 1 4586 DBCC TRACEON(3604); GO DBCC PAGE(AdventureWorks, 1, 2252, 1); GOI won't show you the entire output from the DBCC PAGE command, but I'll show you what appears in the slot where the row with a = 3 formerly appeared: Slot 2, Offset 0x1feb, Length 9, DumpStyle BYTE Record Type = FORWARDING_STUB Record Attributes = Memory Dump @0x61ADDFEB 00000000: 04ea1100 00010000 00 The value of 4 in the first byte means that this is just a forwarding stub. The 0011ea in the next 3 bytes is the page number to which the row has been moved. Because this is a hexadecimal value, we need to convert it to 4586 decimal. The next group of 4 bytes tells us that the page is at slot 0, file 1. If you then use DBCC PAGE to look at that page 4586, you can see what the forwarded record looks like. Managing Forward PointersForward pointers allow you to modify data in a heap without worrying about having to make drastic changes to the nonclustered indexes. If a row that has been forwarded must move again, the original forwarding pointer is updated to point to the new location. You'll never end up with a forwarding pointer pointing to another forwarding pointer. In addition, if the forwarded row shrinks enough to fit in its original place, the record might move back to its original place, if there is still room on that page, and the forward pointer would be eliminated. A future version of SQL Server might include some mechanism for performing a physical reorganization of the data in a heap, which will get rid of forward pointers. Note that forward pointers exist only in heaps, and that the ALTER TABLE option to reorganize a table won't do anything to heaps. You can defragment a nonclustered index on a heap, but not the table itself. Currently, when a forward pointer is created, it stays there foreverwith only a few exceptions. The first exception is the case I already mentioned, in which a row shrinks and returns to its original location. The second exception is when the entire database shrinks. The bookmarks are actually reassigned when a file is shrunk. The shrink process never generates forwarding pointers. For pages that were removed because of the shrink process, any forwarded rows or stubs they contain are effectively "unforwarded." Other cases in which the forwarding pointers will be removed are the obvious ones: if the forwarded row is deleted or if a clustered index is built on the table so that it is no longer a heap. To get a count of forward records in a table, you can look at the output from the sys.dm_db_index_physical_stats function, which I'll discuss shortly. Updating in PlaceIn SQL Server 2005, updating a row in place is the rule rather than the exception. This means that the row stays in exactly the same location on the same page and only the bytes affected are changed. In addition, the log will contain a single record for each such updated row unless the table has an update trigger on it or is marked for replication. In these cases, the update still happens in place, but the log will contain a delete record followed by an insert record. In cases where a row can't be updated in place, the cost of a not-in-place update is minimal because of the way the nonclustered indexes are stored and because of the use of forwarding pointers. In fact, you can have an update not-in-place for which the row stays on the original page. Updates will happen in place if a heap is being updated or if a table with a clustered index is updated without any change to the clustering keys. You can also get an update in place if the clustering key changes but the row does not need to move at all. For example, if you have a clustered index on a last name column containing consecutive key values of Able, Becker, and Charlie, you might want to update Becker to Baker. Because the row will stay in the same location even after the clustered index key changes, SQL Server will perform this as an update in place. On the other hand, if you update Able to Buchner, the update cannot occur in place, but the new row might stay on the same page. Updating Not in PlaceIf your update can't happen in place because you're updating clustering keys, the update will occur as a delete followed by an insert. In some cases, you'll get a hybrid update: some of the rows will be updated in place and some won't. If you're updating index keys, SQL Server builds a list of all the rows that need to change as both a delete and an insert operation. This list is stored in memory, if it's small enough, and is written to tempdb if necessary. This list is then sorted by key value and operator (delete or insert). If the index whose keys are changing isn't unique, the delete and insert steps are then applied to the table. If the index is unique, an additional step is carried out to collapse delete and insert operations on the same key into a single update operation. Let's look at a simple example. The following code builds a table with a unique clustered index on column X and then updates that column in both rows: USE pubs GO DROP TABLE T1 GO CREATE TABLE T1(X int PRIMARY KEY, Y int) INSERT T1 VALUES(1, 10) INSERT T1 VALUES(2, 20) GO UPDATE T1 SET X = 3 - X GO Here are the operations that SQL Server generates internally for the preceding UPDATE statement. This list of operations is called the input stream and consists of both the old and new values of every column and an identifier for each row that is to be changed. I have simplified the representation of the Row ID; SQL Server would use its own internal row identifier.
In this case, the UPDATE statements must be split into DELETE and INSERT operations. If they aren't, the UPDATE to the first row, changing X from 1 to 2, will fail with a duplicate-key violation. A converted input stream is generated, as shown here.
Note that for insert operations, the Row ID isn't relevant in the input stream of operations to be performed. Before a row is inserted, it has no Row ID. This input stream is then sorted by index key and operation, as shown here.
Finally, if the same key value has both a delete and an insert, the two rows in the input stream are collapsed into an update operation. The final input stream looks like this:
Note that although the original query was an update to column X, after the split, sort, and collapse of the input stream, the final set of actions looks like we're updating column Y! This method of actually carrying out the update ensures that no intermediate violations of the index's unique key occur. Part of the graphical query plan for this update (Figure 7-9) shows you the split, sort, and collapse phases. Basic query plans are described in Inside Microsoft SQL Server 2005: T-SQL Querying, and I'll go into much more detail about analyzing plans in Inside Microsoft SQL Server 2005: Tuning and Optimization. Figure 7-9. A graphical query plan for an update operation using split and collapse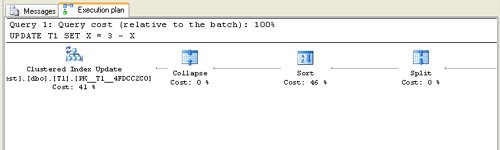 Updates to any nonclustered index keys also affect the leaf level of the index by splitting the operation into deletes and inserts. Think of the leaf level of a nonclustered index as a miniclustered index, so any modification of the key can potentially affect the sequence of values in the leaf level. Just like for the data in a clustered index, the actual type of update is determined by whether the index is unique. If the nonclustered index is not unique, the update is split into delete and insert operations. If the nonclustered index is unique, the split is followed by a sort and an attempt to collapse any deletes and inserts on the same key back into an update operation. Table-Level vs. Index-Level Data ModificationI've been discussing only the placement and index manipulation necessary for modifying either a single row or a few rows with no more than a single index. If you are modifying multiple rows in a single operation (insert, update, or delete) or by using BCP or the BULK INSERT command and the table has multiple indexes, you must be aware of some other issues. SQL Server 2005 offers two strategies for maintaining all the indexes that belong to a table: table-level modification and index-level modification. The query optimizer chooses between them based on its estimate of the anticipated execution costs for each strategy. Table-level modification is sometimes called row-at-a-time, and index-level modification is sometimes called index-at-a-time. In table-level modification, all indexes are maintained for each row as that row is modified. If the update stream isn't sorted in any way, SQL Server has to do a lot of random index accesses, one access per index per update row. If the update stream is sorted, it can't be sorted in more than one order, so nonrandom index accesses can occur for at most one index. In index-level modifications, SQL Server gathers all the rows to be modified and sorts them for each index. In other words, there are as many sort operations as there are indexes. Then, for each index, the updates are merged into the index, and each index page is never accessed more than once, even if multiple updates pertain to a single index leaf page. Clearly, if the update is smallsay, less than a handful of rowsand the table and its indexes are sizable, the query optimizer usually considers table-level modification the best choice. Most OLTP operations use table-level modification. On the other hand, if the update is relatively large, table-level modifications require a lot of random I/O operations and might even read and write each leaf page in each index multiple times. In that case, index-level modification offers much better performance. The amount of logging required is the same for both strategies. Let's look at a specific example with some actual numbers. Suppose that you use BULK INSERT to increase the size of a table by 1 percent (which could correspond to one week in a two-year sales history table). The table is stored in a heap (no clustered index), and the rows are simply appended because there is not much available space on other pages in the table. There's nothing to sort on for insertion into the heap, and the rows (and the required new heap pages and extents) are simply appended to the heap. Assume also that there are two non-clustered indexes on columns a and b. The insert stream is sorted on column a and is merged into the index on column a. If an index entry is 20 bytes long, an 8-KB page filled at 70 percent (which is the natural, self-stabilizing value in a B-tree after lots of random insertions and deletions) would contain 8 KB * 70% / 20 bytes = 280 entries. Eight pages (one extent) would then contain 2,240 entries, assuming that the leaf pages are nicely laid out in extents. Table growth of 1 percent would mean an average of 2.8 new entries per page, or 22.4 new entries per extent. Table-level (row-at-a-time) insertion would touch each page an average of 2.8 times. Unless the buffer pool is large, row-at-a-time insertion reads, updates, and writes each page 2.8 times. That's 5.6 I/O operations per page, or 44.8 I/O operations per extent. Index-level (index-at-a-time) insertion would read, update, and write each page (and extent, again presuming a nice contiguous layout) exactly once. In the best case, about 45 page I/O operations are replaced by 2 extent I/O operations for each extent. Of course, the cost of doing the insert in this way also includes the cost of sorting the inputs for each index. But the cost savings of the index-level insertion strategy can easily offset the cost of sorting. Note
You can determine whether your updates were done at the table level or the index level by inspecting the query execution plan. If SQL Server performs the update at the index level, you'll see a plan produced that contains an update operator for each of the affected indexes. If SQL Server performs the update at the table level, you'll see only a single update operator in the plan. LoggingStandard INSERT, UPDATE, and DELETE statements are always logged to ensure atomicity, and you can't disable logging of these operations. The modification must be known to be safely on disk in the transaction log (write-ahead logging) before the commit of the statement or transaction can be acknowledged to the calling application. Page allocations and deallocations, including those done by TRUNCATE TABLE, are also logged. As we saw in Chapter 5, certain operations can be minimally logged when your database is in the BULK_LOGGED recovery mode, but even then, information about allocations and deallocations is written to the log, along with the fact that a minimally logged operation has been executed. LockingAny data modification must always be protected with some form of exclusive lock. For the most part, SQL Server makes all the locking decisions internally; a user or programmer doesn't need to request a particular kind of lock. Chapter 8 explains the different types of locks and their compatibility. Inside Microsoft SQL Server 2005: Tuning and Optimization will discuss techniques for overriding SQL Server's default locking behavior. However, because locking is closely tied to data modification, you should always be aware of the following:
|
 .
. EAN: 2147483647
Pages: 115